 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeR-HTN: Rebellious Online HTN Planning for Safety and Game AI
Feb 01, 2026We introduce online Hierarchical Task Network (HTN) agents whose behaviors are governed by a set of built-in directives \D. Like other agents that are capable of rebellion (i.e., {\it intelligent disobedience}), our agents will, under some conditions, not perform a user-assigned task and instead act in ways that do not meet a user's expectations. Our work combines three concepts: HTN planning, online planning, and the directives \D, which must be considered when performing user-assigned tasks. We investigate two agent variants: (1) a Nonadaptive agent that stops execution if it finds itself in violation of \D~ and (2) an Adaptive agent that, in the same situation, instead modifies its HTN plan to search for alternative ways to achieve its given task. We present R-HTN (for: Rebellious-HTN), a general algorithm for online HTN planning under directives \D. We evaluate R-HTN in two task domains where the agent must not violate some directives for safety reasons or as dictated by their personality traits. We found that R-HTN agents never violate directives, and aim to achieve the user-given goals if feasible though not necessarily as the user expected.
ChatHTN: Interleaving Approximate (LLM) and Symbolic HTN Planning
May 17, 2025We introduce ChatHTN, a Hierarchical Task Network (HTN) planner that combines symbolic HTN planning techniques with queries to ChatGPT to approximate solutions in the form of task decompositions. The resulting hierarchies interleave task decompositions generated by symbolic HTN planning with those generated by ChatGPT. Despite the approximate nature of the results generates by ChatGPT, ChatHTN is provably sound; any plan it generates correctly achieves the input tasks. We demonstrate this property with an open-source implementation of our system.
Interpretable ML for Imbalanced Data
Dec 15, 2022



Deep learning models are being increasingly applied to imbalanced data in high stakes fields such as medicine, autonomous driving, and intelligence analysis. Imbalanced data compounds the black-box nature of deep networks because the relationships between classes may be highly skewed and unclear. This can reduce trust by model users and hamper the progress of developers of imbalanced learning algorithms. Existing methods that investigate imbalanced data complexity are geared toward binary classification, shallow learning models and low dimensional data. In addition, current eXplainable Artificial Intelligence (XAI) techniques mainly focus on converting opaque deep learning models into simpler models (e.g., decision trees) or mapping predictions for specific instances to inputs, instead of examining global data properties and complexities. Therefore, there is a need for a framework that is tailored to modern deep networks, that incorporates large, high dimensional, multi-class datasets, and uncovers data complexities commonly found in imbalanced data (e.g., class overlap, sub-concepts, and outlier instances). We propose a set of techniques that can be used by both deep learning model users to identify, visualize and understand class prototypes, sub-concepts and outlier instances; and by imbalanced learning algorithm developers to detect features and class exemplars that are key to model performance. Our framework also identifies instances that reside on the border of class decision boundaries, which can carry highly discriminative information. Unlike many existing XAI techniques which map model decisions to gray-scale pixel locations, we use saliency through back-propagation to identify and aggregate image color bands across entire classes. Our framework is publicly available at \url{https://github.com/dd1github/XAI_for_Imbalanced_Learning}
Self-directed Learning of Action Models using Exploratory Planning
Mar 07, 2022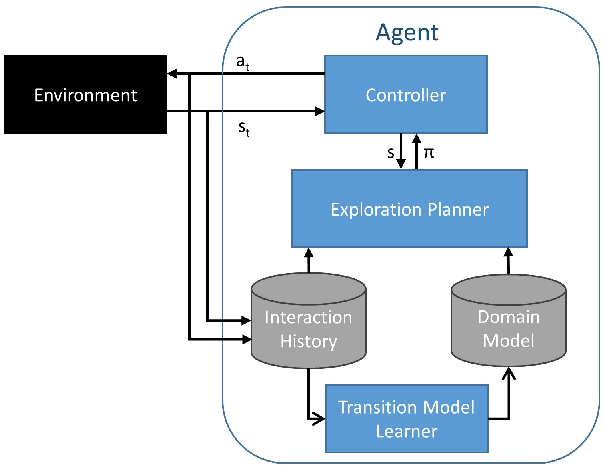
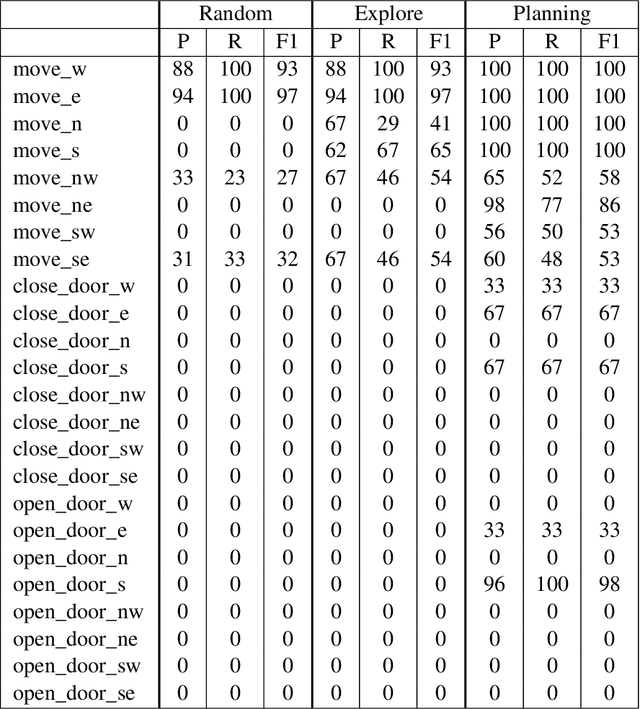

Complex, real-world domains may not be fully modeled for an agent, especially if the agent has never operated in the domain before. The agent's ability to effectively plan and act in such a domain is influenced by its knowledge of when it can perform specific actions and the effects of those actions. We describe a novel exploratory planning agent that is capable of learning action preconditions and effects without expert traces or a given goal. The agent's architecture allows it to perform both exploratory actions as well as goal-directed actions, which opens up important considerations for how exploratory planning and goal planning should be controlled, as well as how the agent's behavior should be explained to any teammates it may have. The contributions of this work include a new representation for contexts called Lifted Linked Clauses, a novel exploration action selection approach using these clauses, an exploration planner that uses lifted linked clauses as goals in order to reach new states, and an empirical evaluation in a scenario from an exploration-focused video game demonstrating that lifted linked clauses improve exploration and action model learning against non-planning baseline agents.
Dungeon Crawl Stone Soup as an Evaluation Domain for Artificial Intelligence
Feb 05, 2019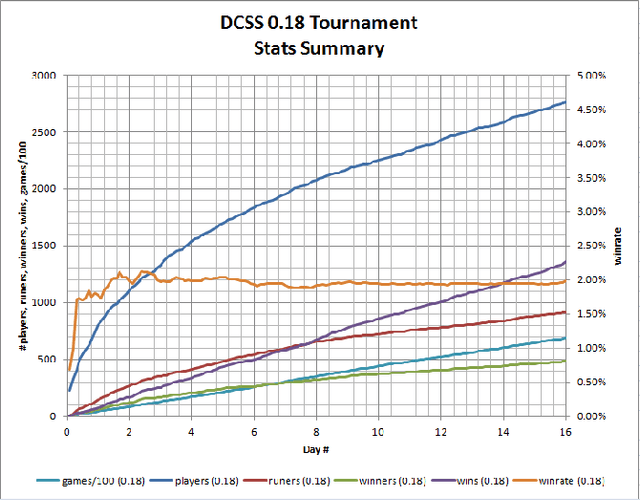
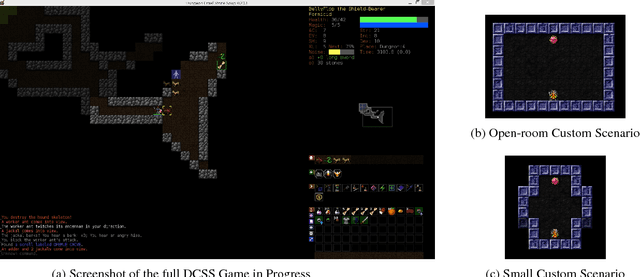
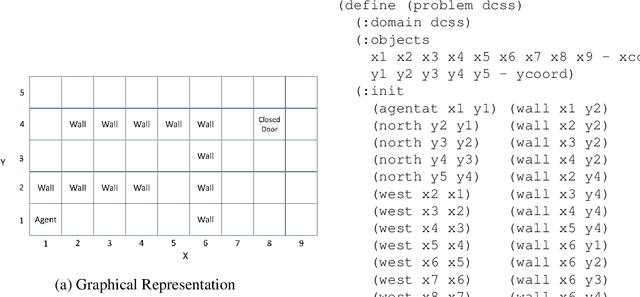
Dungeon Crawl Stone Soup is a popular, single-player, free and open-source rogue-like video game with a sufficiently complex decision space that makes it an ideal testbed for research in cognitive systems and, more generally, artificial intelligence. This paper describes the properties of Dungeon Crawl Stone Soup that are conducive to evaluating new approaches of AI systems. We also highlight an ongoing effort to build an API for AI researchers in the spirit of recent game APIs such as MALMO, ELF, and the Starcraft II API. Dungeon Crawl Stone Soup's complexity offers significant opportunities for evaluating AI and cognitive systems, including human user studies. In this paper we provide (1) a description of the state space of Dungeon Crawl Stone Soup, (2) a description of the components for our API, and (3) the potential benefits of evaluating AI agents in the Dungeon Crawl Stone Soup video game.
Cost-Optimal Algorithms for Planning with Procedural Control Knowledge
Jul 07, 2016
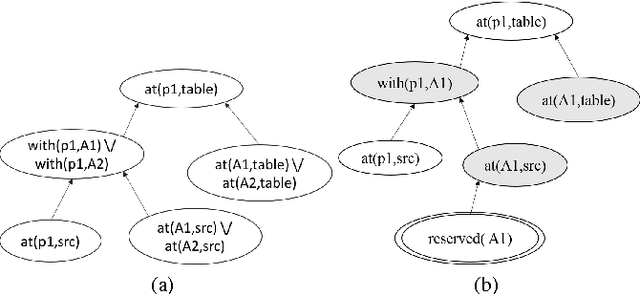
There is an impressive body of work on developing heuristics and other reasoning algorithms to guide search in optimal and anytime planning algorithms for classical planning. However, very little effort has been directed towards developing analogous techniques to guide search towards high-quality solutions in hierarchical planning formalisms like HTN planning, which allows using additional domain-specific procedural control knowledge. In lieu of such techniques, this control knowledge often needs to provide the necessary search guidance to the planning algorithm, which imposes a substantial burden on the domain author and can yield brittle or error-prone domain models. We address this gap by extending recent work on a new hierarchical goal-based planning formalism called Hierarchical Goal Network (HGN) Planning to develop the Hierarchically-Optimal Goal Decomposition Planner (HOpGDP), an HGN planning algorithm that computes hierarchically-optimal plans. HOpGDP is guided by $h_{HL}$, a new HGN planning heuristic that extends existing admissible landmark-based heuristics from classical planning to compute admissible cost estimates for HGN planning problems. Our experimental evaluation across three benchmark planning domains shows that HOpGDP compares favorably to both optimal classical planners due to its ability to use domain-specific procedural knowledge, and a blind-search version of HOpGDP due to the search guidance provided by $h_{HL}$.
Keypoint Density-based Region Proposal for Fine-Grained Object Detection and Classification using Regions with Convolutional Neural Network Features
Mar 01, 2016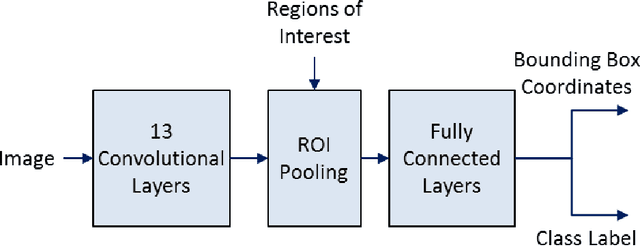


Although recent advances in regional Convolutional Neural Networks (CNNs) enable them to outperform conventional techniques on standard object detection and classification tasks, their response time is still slow for real-time performance. To address this issue, we propose a method for region proposal as an alternative to selective search, which is used in current state-of-the art object detection algorithms. We evaluate our Keypoint Density-based Region Proposal (KDRP) approach and show that it speeds up detection and classification on fine-grained tasks by 100% versus the existing selective search region proposal technique without compromising classification accuracy. KDRP makes the application of CNNs to real-time detection and classification feasible.
Spontaneous Analogy by Piggybacking on a Perceptual System
Oct 10, 2013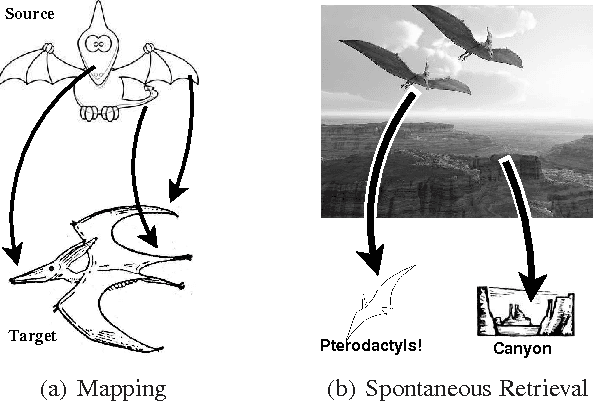

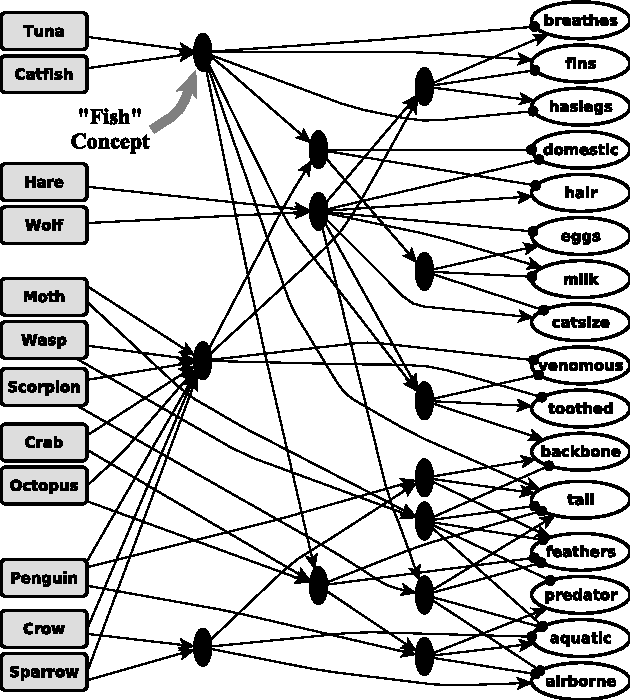

Most computational models of analogy assume they are given a delineated source domain and often a specified target domain. These systems do not address how analogs can be isolated from large domains and spontaneously retrieved from long-term memory, a process we call spontaneous analogy. We present a system that represents relational structures as feature bags. Using this representation, our system leverages perceptual algorithms to automatically create an ontology of relational structures and to efficiently retrieve analogs for new relational structures from long-term memory. We provide a demonstration of our approach that takes a set of unsegmented stories, constructs an ontology of analogical schemas (corresponding to plot devices), and uses this ontology to efficiently find analogs within new stories, yielding significant time-savings over linear analog retrieval at a small accuracy cost.
Transforming Graph Representations for Statistical Relational Learning
Mar 30, 2012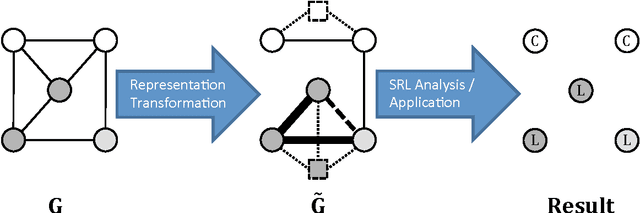
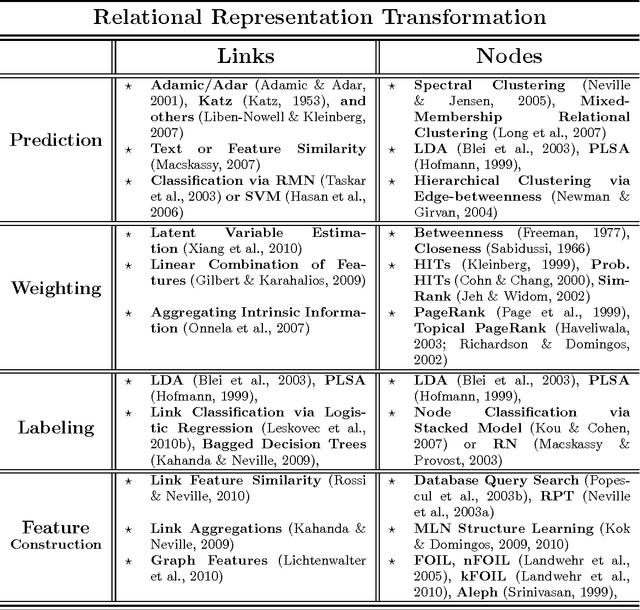


Relational data representations have become an increasingly important topic due to the recent proliferation of network datasets (e.g., social, biological, information networks) and a corresponding increase in the application of statistical relational learning (SRL) algorithms to these domains. In this article, we examine a range of representation issues for graph-based relational data. Since the choice of relational data representation for the nodes, links, and features can dramatically affect the capabilities of SRL algorithms, we survey approaches and opportunities for relational representation transformation designed to improve the performance of these algorithms. This leads us to introduce an intuitive taxonomy for data representation transformations in relational domains that incorporates link transformation and node transformation as symmetric representation tasks. In particular, the transformation tasks for both nodes and links include (i) predicting their existence, (ii) predicting their label or type, (iii) estimating their weight or importance, and (iv) systematically constructing their relevant features. We motivate our taxonomy through detailed examples and use it to survey and compare competing approaches for each of these tasks. We also discuss general conditions for transforming links, nodes, and features. Finally, we highlight challenges that remain to be addressed.