 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
YOLOV: Making Still Image Object Detectors Great at Video Object Detection
Aug 20, 2022

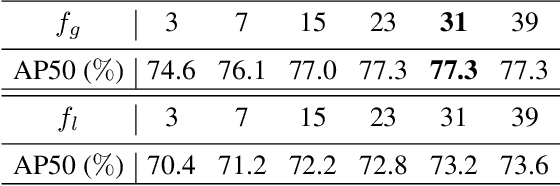
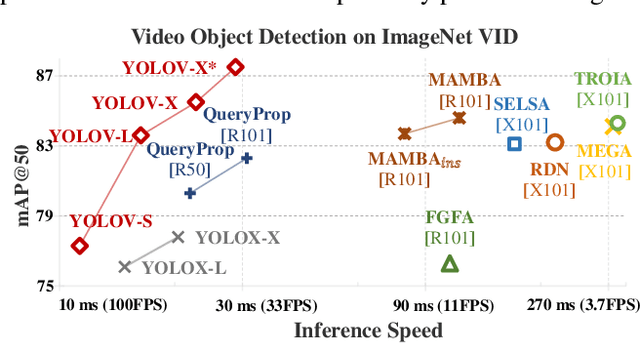

Video object detection (VID) is challenging because of the high variation of object appearance as well as the diverse deterioration in some frames. On the positive side, the detection in a certain frame of a video, compared with in a still image, can draw support from other frames. Hence, how to aggregate features across different frames is pivotal to the VID problem. Most of existing aggregation algorithms are customized for two-stage detectors. But, the detectors in this category are usually computationally expensive due to the two-stage nature. This work proposes a simple yet effective strategy to address the above concerns, which spends marginal overheads with significant gains in accuracy. Concretely, different from the traditional two-stage pipeline, we advocate putting the region-level selection after the one-stage detection to avoid processing massive low-quality candidates. Besides, a novel module is constructed to evaluate the relationship between a target frame and its reference ones, and guide the aggregation. Extensive experiments and ablation studies are conducted to verify the efficacy of our design, and reveal its superiority over other state-of-the-art VID approaches in both effectiveness and efficiency. Our YOLOX-based model can achieve promising performance (e.g., 87.5\% AP50 at over 30 FPS on the ImageNet VID dataset on a single 2080Ti GPU), making it attractive for large-scale or real-time applications. The implementation is simple, the demo code and models have been made available at https://github.com/YuHengsss/YOLOV .
Diffusion Art or Digital Forgery? Investigating Data Replication in Diffusion Models
Dec 08, 2022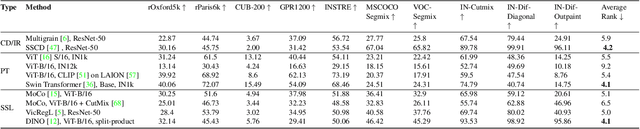


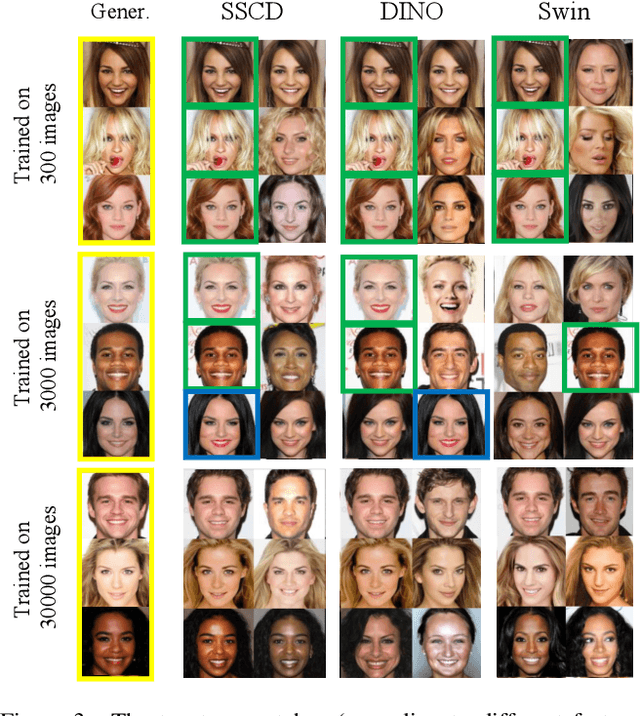
Cutting-edge diffusion models produce images with high quality and customizability, enabling them to be used for commercial art and graphic design purposes. But do diffusion models create unique works of art, or are they stealing content directly from their training sets? In this work, we study image retrieval frameworks that enable us to compare generated images with training samples and detect when content has been replicated. Applying our frameworks to diffusion models trained on multiple datasets including Oxford flowers, Celeb-A, ImageNet, and LAION, we discuss how factors such as training set size impact rates of content replication. We also identify cases where diffusion models, including the popular Stable Diffusion model, blatantly copy from their training data.
MaxStyle: Adversarial Style Composition for Robust Medical Image Segmentation
Jun 02, 2022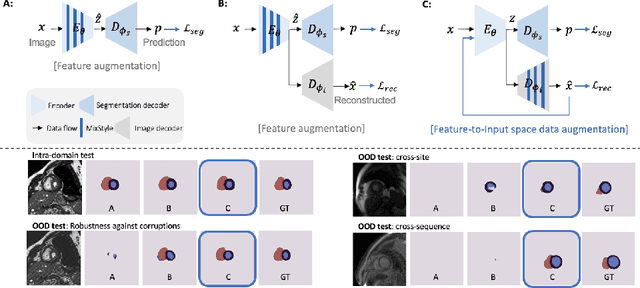

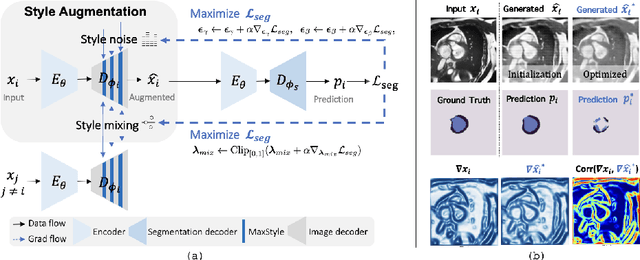
Convolutional neural networks (CNNs) have achieved remarkable segmentation accuracy on benchmark datasets where training and test sets are from the same domain, yet their performance can degrade significantly on unseen domains, which hinders the deployment of CNNs in many clinical scenarios. Most existing works improve model out-of-domain (OOD) robustness by collecting multi-domain datasets for training, which is expensive and may not always be feasible due to privacy and logistical issues. In this work, we focus on improving model robustness using a single-domain dataset only. We propose a novel data augmentation framework called MaxStyle, which maximizes the effectiveness of style augmentation for model OOD performance. It attaches an auxiliary style-augmented image decoder to a segmentation network for robust feature learning and data augmentation. Importantly, MaxStyle augments data with improved image style diversity and hardness, by expanding the style space with noise and searching for the worst-case style composition of latent features via adversarial training. With extensive experiments on multiple public cardiac and prostate MR datasets, we demonstrate that MaxStyle leads to significantly improved out-of-distribution robustness against unseen corruptions as well as common distribution shifts across multiple, different, unseen sites and unknown image sequences under both low- and high-training data settings. The code can be found at https://github.com/cherise215/MaxStyle.
VIINTER: View Interpolation with Implicit Neural Representations of Images
Nov 01, 2022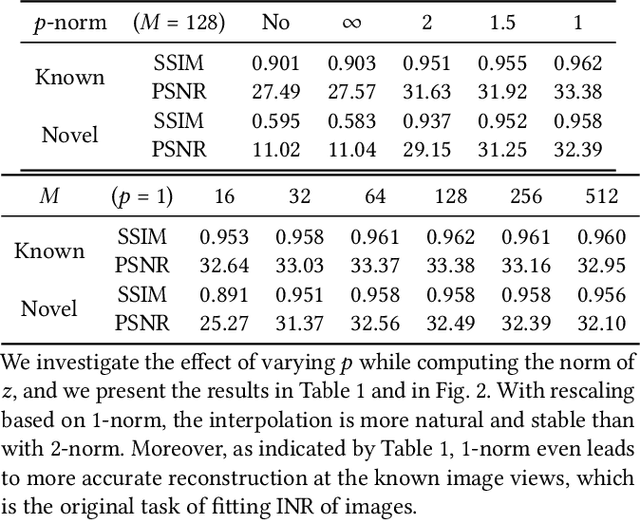

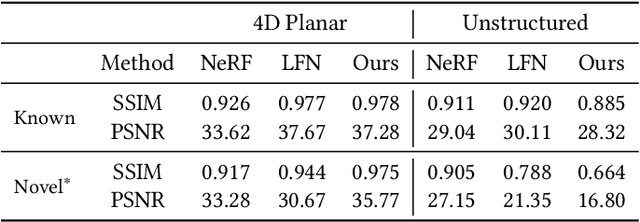
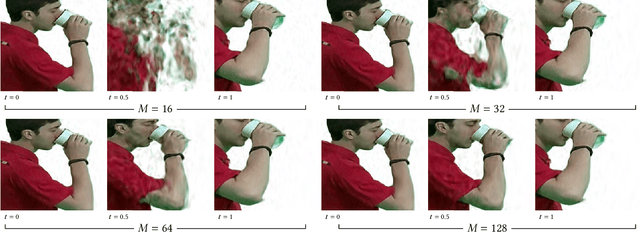
We present VIINTER, a method for view interpolation by interpolating the implicit neural representation (INR) of the captured images. We leverage the learned code vector associated with each image and interpolate between these codes to achieve viewpoint transitions. We propose several techniques that significantly enhance the interpolation quality. VIINTER signifies a new way to achieve view interpolation without constructing 3D structure, estimating camera poses, or computing pixel correspondence. We validate the effectiveness of VIINTER on several multi-view scenes with different types of camera layout and scene composition. As the development of INR of images (as opposed to surface or volume) has centered around tasks like image fitting and super-resolution, with VIINTER, we show its capability for view interpolation and offer a promising outlook on using INR for image manipulation tasks.
SceneGATE: Scene-Graph based co-Attention networks for TExt visual question answering
Dec 16, 2022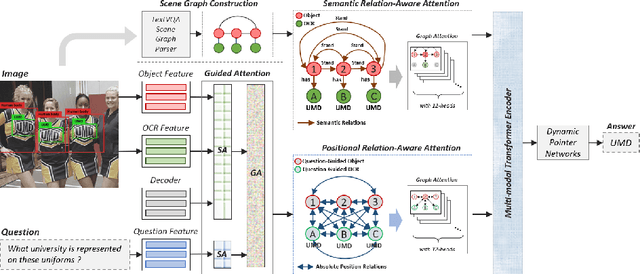
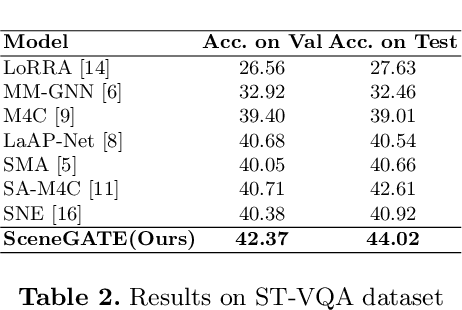
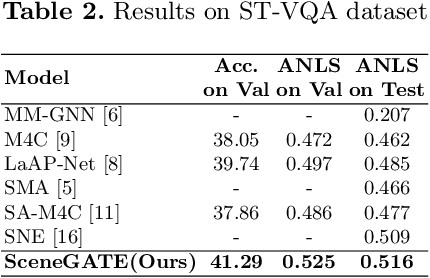

Most TextVQA approaches focus on the integration of objects, scene texts and question words by a simple transformer encoder. But this fails to capture the semantic relations between different modalities. The paper proposes a Scene Graph based co-Attention Network (SceneGATE) for TextVQA, which reveals the semantic relations among the objects, Optical Character Recognition (OCR) tokens and the question words. It is achieved by a TextVQA-based scene graph that discovers the underlying semantics of an image. We created a guided-attention module to capture the intra-modal interplay between the language and the vision as a guidance for inter-modal interactions. To make explicit teaching of the relations between the two modalities, we proposed and integrated two attention modules, namely a scene graph-based semantic relation-aware attention and a positional relation-aware attention. We conducted extensive experiments on two benchmark datasets, Text-VQA and ST-VQA. It is shown that our SceneGATE method outperformed existing ones because of the scene graph and its attention modules.
A Sieve Quasi-likelihood Ratio Test for Neural Networks with Applications to Genetic Association Studies
Dec 16, 2022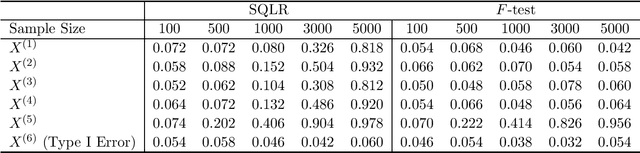
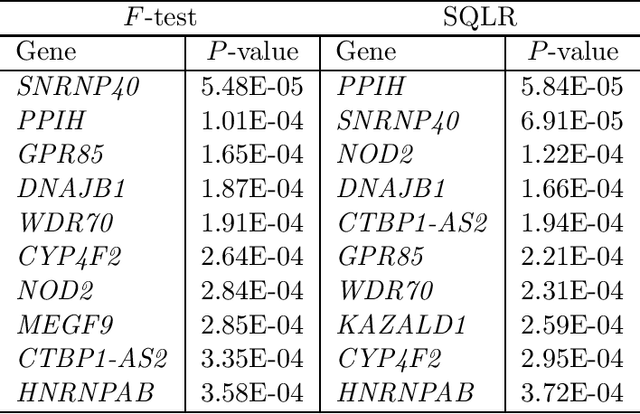
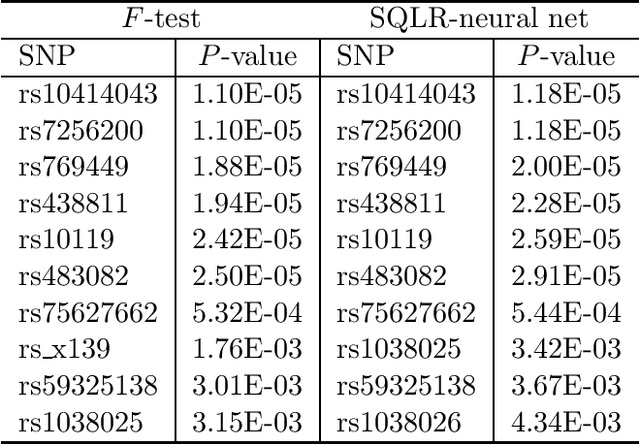
Neural networks (NN) play a central role in modern Artificial intelligence (AI) technology and has been successfully used in areas such as natural language processing and image recognition. While majority of NN applications focus on prediction and classification, there are increasing interests in studying statistical inference of neural networks. The study of NN statistical inference can enhance our understanding of NN statistical proprieties. Moreover, it can facilitate the NN-based hypothesis testing that can be applied to hypothesis-driven clinical and biomedical research. In this paper, we propose a sieve quasi-likelihood ratio test based on NN with one hidden layer for testing complex associations. The test statistic has asymptotic chi-squared distribution, and therefore it is computationally efficient and easy for implementation in real data analysis. The validity of the asymptotic distribution is investigated via simulations. Finally, we demonstrate the use of the proposed test by performing a genetic association analysis of the sequencing data from Alzheimer's Disease Neuroimaging Initiative (ADNI).
A Strategy Optimized Pix2pix Approach for SAR-to-Optical Image Translation Task
Jun 28, 2022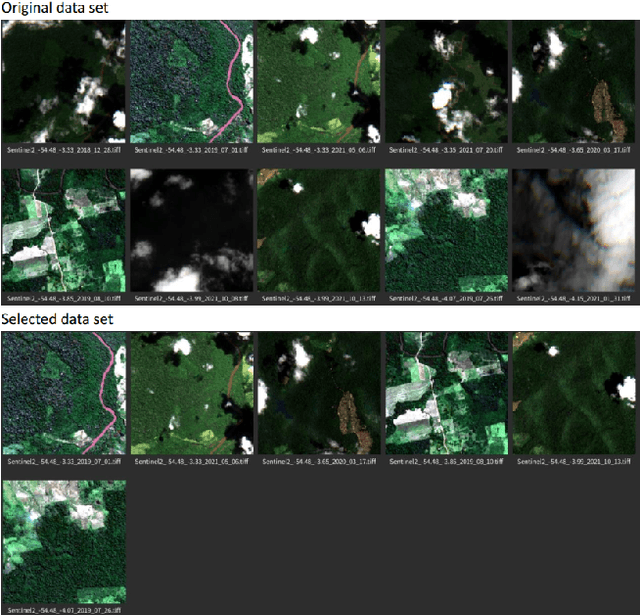
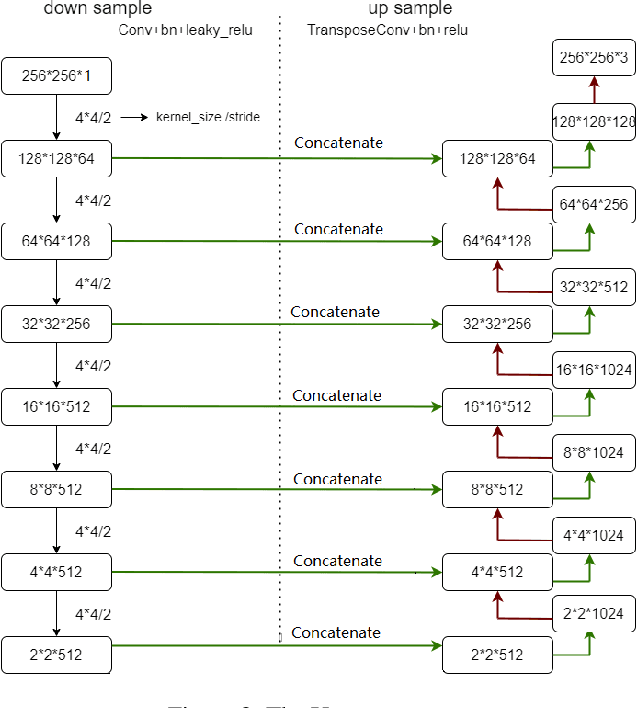


This technical report summarizes the analysis and approach on the image-to-image translation task in the Multimodal Learning for Earth and Environment Challenge (MultiEarth 2022). In terms of strategy optimization, cloud classification is utilized to filter optical images with dense cloud coverage to aid the supervised learning alike approach. The commonly used pix2pix framework with a few optimizations is applied to build the model. A weighted combination of mean squared error and mean absolute error is incorporated in the loss function. As for evaluation, peak to signal ratio and structural similarity were both considered in our preliminary analysis. Lastly, our method achieved the second place with a final error score of 0.0412. The results indicate great potential towards SAR-to-optical translation in remote sensing tasks, specifically for the support of long-term environmental monitoring and protection.
DOLCE: A Model-Based Probabilistic Diffusion Framework for Limited-Angle CT Reconstruction
Nov 22, 2022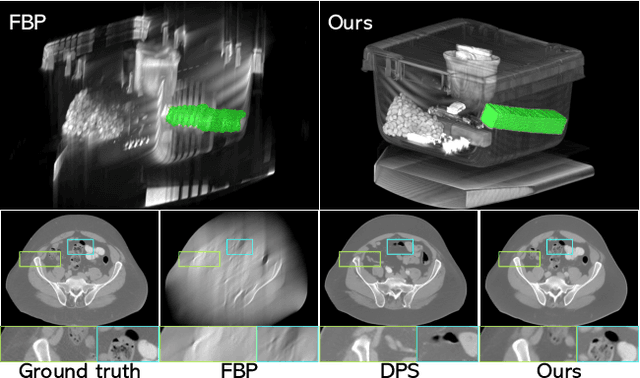
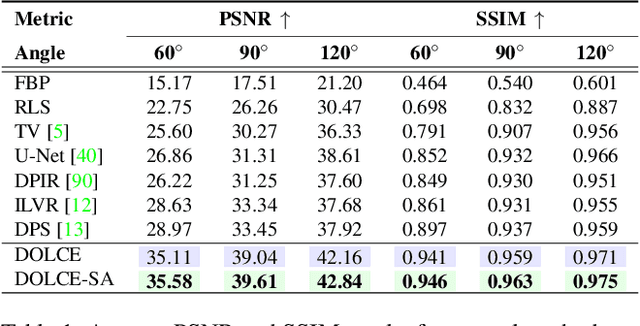
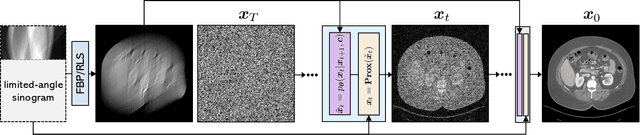
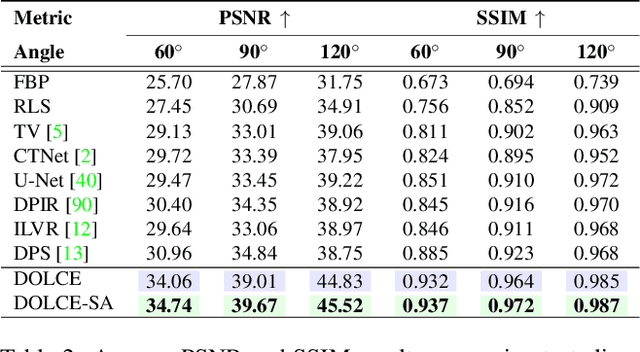
Limited-Angle Computed Tomography (LACT) is a non-destructive evaluation technique used in a variety of applications ranging from security to medicine. The limited angle coverage in LACT is often a dominant source of severe artifacts in the reconstructed images, making it a challenging inverse problem. We present DOLCE, a new deep model-based framework for LACT that uses a conditional diffusion model as an image prior. Diffusion models are a recent class of deep generative models that are relatively easy to train due to their implementation as image denoisers. DOLCE can form high-quality images from severely under-sampled data by integrating data-consistency updates with the sampling updates of a diffusion model, which is conditioned on the transformed limited-angle data. We show through extensive experimentation on several challenging real LACT datasets that, the same pre-trained DOLCE model achieves the SOTA performance on drastically different types of images. Additionally, we show that, unlike standard LACT reconstruction methods, DOLCE naturally enables the quantification of the reconstruction uncertainty by generating multiple samples consistent with the measured data.
Predictive Display with Perspective Projection of Surroundings in Vehicle Teleoperation to Account Time-delays
Nov 22, 2022
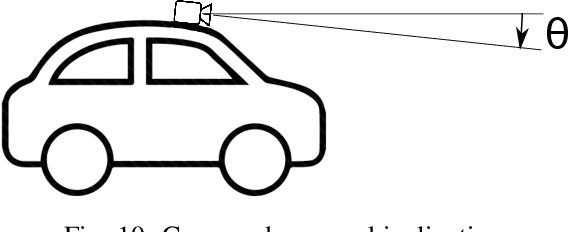

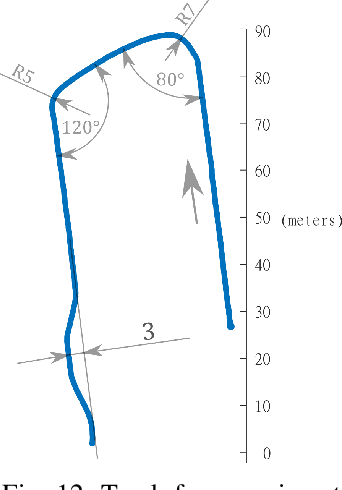
Teleoperation provides human operator sophisticated perceptual and cognitive skills into an over the network control loop. It gives hope of addressing some challenges related to vehicular autonomy which is based on artificial intelligence by providing a backup plan. Variable network time delays in data transmission is the major problem in teleoperating a vehicle. On 4G network, variability of these delays is high. Due to this, both video streaming and driving commands encounter variable time delay. This paper presents an approach of providing the human operator a forecast video stream which replicates future perspective of vehicle field of view accounting the delay present in the network. Regarding the image transformation, perspective projection technique is combined with correction given by smith predictor in the control loop. This image transformation accounts current time delay and tries to address both issues, time delays as well as its variability. For experiment sake, only frontward field of view is forecast. Performance is evaluated by performing online vehicle teleoperation on street edge case maneuvers and later comparing the path deviation with and without perspective projection.
Contextual Learning in Fourier Complex Field for VHR Remote Sensing Images
Oct 28, 2022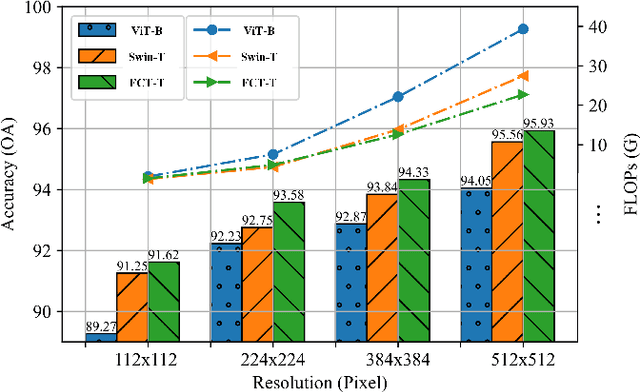
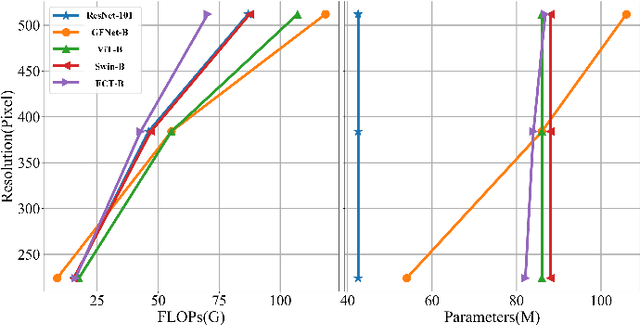
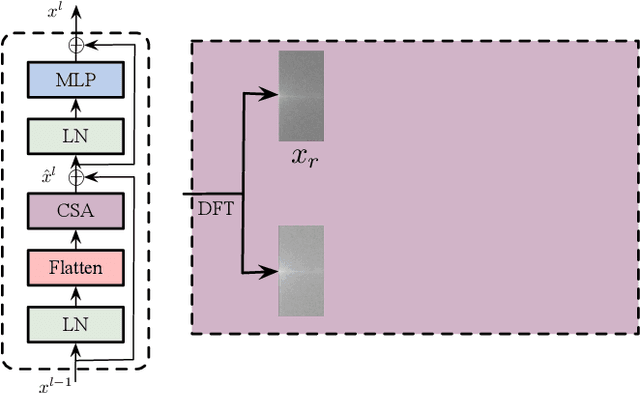
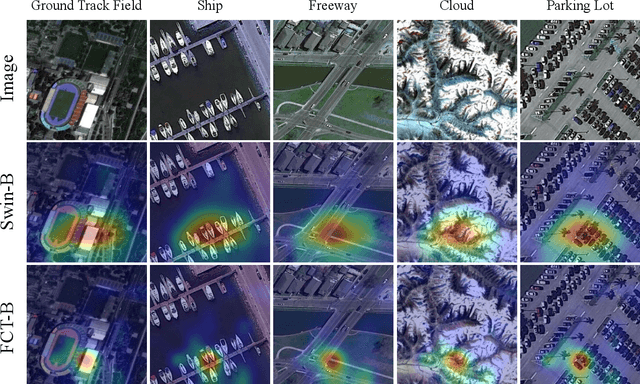
Very high-resolution (VHR) remote sensing (RS) image classification is the fundamental task for RS image analysis and understanding. Recently, transformer-based models demonstrated outstanding potential for learning high-order contextual relationships from natural images with general resolution (224x224 pixels) and achieved remarkable results on general image classification tasks. However, the complexity of the naive transformer grows quadratically with the increase in image size, which prevents transformer-based models from VHR RS image (500x500 pixels) classification and other computationally expensive downstream tasks. To this end, we propose to decompose the expensive self-attention (SA) into real and imaginary parts via discrete Fourier transform (DFT) and therefore propose an efficient complex self-attention (CSA) mechanism. Benefiting from the conjugated symmetric property of DFT, CSA is capable to model the high-order contextual information with less than half computations of naive SA. To overcome the gradient explosion in Fourier complex field, we replace the Softmax function with the carefully designed Logmax function to normalize the attention map of CSA and stabilize the gradient propagation. By stacking various layers of CSA blocks, we propose the Fourier Complex Transformer (FCT) model to learn global contextual information from VHR aerial images following the hierarchical manners. Universal experiments conducted on commonly used RS classification data sets demonstrate the effectiveness and efficiency of FCT, especially on very high-resolution RS images.