 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChuLo: Chunk-Level Key Information Representation for Long Document Processing
Oct 14, 2024



Transformer-based models have achieved remarkable success in various Natural Language Processing (NLP) tasks, yet their ability to handle long documents is constrained by computational limitations. Traditional approaches, such as truncating inputs, sparse self-attention, and chunking, attempt to mitigate these issues, but they often lead to information loss and hinder the model's ability to capture long-range dependencies. In this paper, we introduce ChuLo, a novel chunk representation method for long document classification that addresses these limitations. Our ChuLo groups input tokens using unsupervised keyphrase extraction, emphasizing semantically important keyphrase based chunk to retain core document content while reducing input length. This approach minimizes information loss and improves the efficiency of Transformer-based models. Preserving all tokens in long document understanding, especially token classification tasks, is especially important to ensure that fine-grained annotations, which depend on the entire sequence context, are not lost. We evaluate our method on multiple long document classification tasks and long document token classification tasks, demonstrating its effectiveness through comprehensive qualitative and quantitative analyses.
Multimodal Large Language Models and Tunings: Vision, Language, Sensors, Audio, and Beyond
Oct 08, 2024This tutorial explores recent advancements in multimodal pretrained and large models, capable of integrating and processing diverse data forms such as text, images, audio, and video. Participants will gain an understanding of the foundational concepts of multimodality, the evolution of multimodal research, and the key technical challenges addressed by these models. We will cover the latest multimodal datasets and pretrained models, including those beyond vision and language. Additionally, the tutorial will delve into the intricacies of multimodal large models and instruction tuning strategies to optimise performance for specific tasks. Hands-on laboratories will offer practical experience with state-of-the-art multimodal models, demonstrating real-world applications like visual storytelling and visual question answering. This tutorial aims to equip researchers, practitioners, and newcomers with the knowledge and skills to leverage multimodal AI. ACM Multimedia 2024 is the ideal venue for this tutorial, aligning perfectly with our goal of understanding multimodal pretrained and large language models, and their tuning mechanisms.
3M: Multi-modal Multi-task Multi-teacher Learning for Game Event Detection
Jun 13, 2024



Esports has rapidly emerged as a global phenomenon with an ever-expanding audience via platforms, like YouTube. Due to the inherent complexity nature of the game, it is challenging for newcomers to comprehend what the event entails. The chaotic nature of online chat, the fast-paced speech of the game commentator, and the game-specific user interface further compound the difficulty for users in comprehending the gameplay. To overcome these challenges, it is crucial to integrate the Multi-Modal (MM) information from the platform and understand the event. The paper introduces a new MM multi-teacher-based game event detection framework, with the ultimate goal of constructing a comprehensive framework that enhances the comprehension of the ongoing game situation. While conventional MM models typically prioritise aligning MM data through concurrent training towards a unified objective, our framework leverages multiple teachers trained independently on different tasks to accomplish the Game Event Detection. The experiment clearly shows the effectiveness of the proposed MM multi-teacher framework.
Game-MUG: Multimodal Oriented Game Situation Understanding and Commentary Generation Dataset
Apr 30, 2024



The dynamic nature of esports makes the situation relatively complicated for average viewers. Esports broadcasting involves game expert casters, but the caster-dependent game commentary is not enough to fully understand the game situation. It will be richer by including diverse multimodal esports information, including audiences' talks/emotions, game audio, and game match event information. This paper introduces GAME-MUG, a new multimodal game situation understanding and audience-engaged commentary generation dataset and its strong baseline. Our dataset is collected from 2020-2022 LOL game live streams from YouTube and Twitch, and includes multimodal esports game information, including text, audio, and time-series event logs, for detecting the game situation. In addition, we also propose a new audience conversation augmented commentary dataset by covering the game situation and audience conversation understanding, and introducing a robust joint multimodal dual learning model as a baseline. We examine the model's game situation/event understanding ability and commentary generation capability to show the effectiveness of the multimodal aspects coverage and the joint integration learning approach.
PEACH: Pretrained-embedding Explanation Across Contextual and Hierarchical Structure
Apr 21, 2024



In this work, we propose a novel tree-based explanation technique, PEACH (Pretrained-embedding Explanation Across Contextual and Hierarchical Structure), that can explain how text-based documents are classified by using any pretrained contextual embeddings in a tree-based human-interpretable manner. Note that PEACH can adopt any contextual embeddings of the PLMs as a training input for the decision tree. Using the proposed PEACH, we perform a comprehensive analysis of several contextual embeddings on nine different NLP text classification benchmarks. This analysis demonstrates the flexibility of the model by applying several PLM contextual embeddings, its attribute selections, scaling, and clustering methods. Furthermore, we show the utility of explanations by visualising the feature selection and important trend of text classification via human-interpretable word-cloud-based trees, which clearly identify model mistakes and assist in dataset debugging. Besides interpretability, PEACH outperforms or is similar to those from pretrained models.
SceneGATE: Scene-Graph based co-Attention networks for TExt visual question answering
Dec 16, 2022



Most TextVQA approaches focus on the integration of objects, scene texts and question words by a simple transformer encoder. But this fails to capture the semantic relations between different modalities. The paper proposes a Scene Graph based co-Attention Network (SceneGATE) for TextVQA, which reveals the semantic relations among the objects, Optical Character Recognition (OCR) tokens and the question words. It is achieved by a TextVQA-based scene graph that discovers the underlying semantics of an image. We created a guided-attention module to capture the intra-modal interplay between the language and the vision as a guidance for inter-modal interactions. To make explicit teaching of the relations between the two modalities, we proposed and integrated two attention modules, namely a scene graph-based semantic relation-aware attention and a positional relation-aware attention. We conducted extensive experiments on two benchmark datasets, Text-VQA and ST-VQA. It is shown that our SceneGATE method outperformed existing ones because of the scene graph and its attention modules.
In-game Toxic Language Detection: Shared Task and Attention Residuals
Nov 19, 2022


In-game toxic language becomes the hot potato in the gaming industry and community. There have been several online game toxicity analysis frameworks and models proposed. However, it is still challenging to detect toxicity due to the nature of in-game chat, which has extremely short length. In this paper, we describe how the in-game toxic language shared task has been established using the real-world in-game chat data. In addition, we propose and introduce the model/framework for toxic language token tagging (slot filling) from the in-game chat. The data and code will be released.
Understanding Attention for Vision-and-Language Tasks
Aug 17, 2022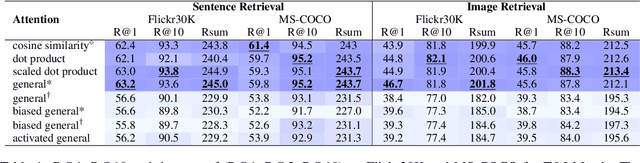
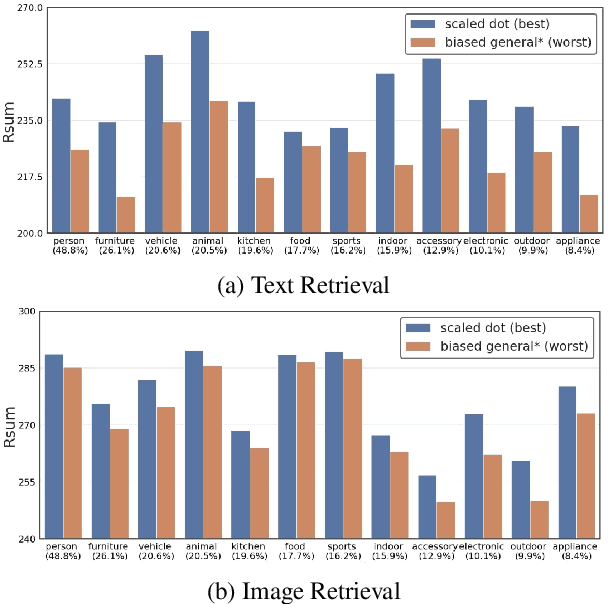
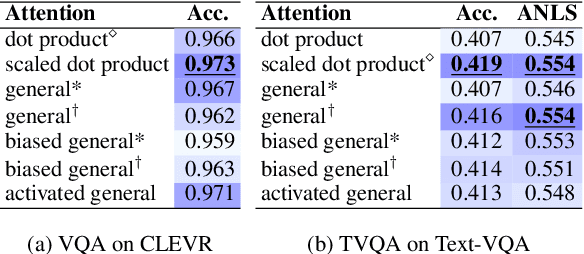
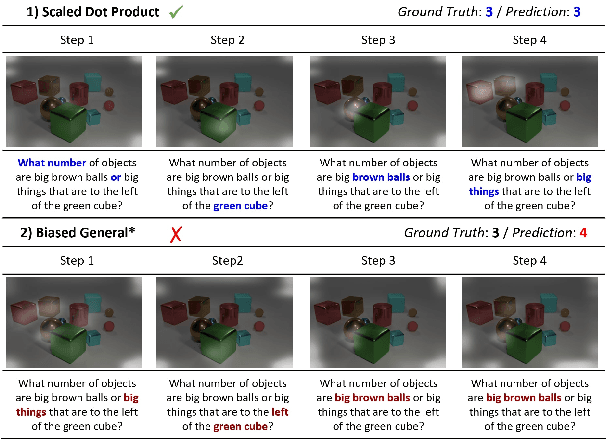
Attention mechanism has been used as an important component across Vision-and-Language(VL) tasks in order to bridge the semantic gap between visual and textual features. While attention has been widely used in VL tasks, it has not been examined the capability of different attention alignment calculation in bridging the semantic gap between visual and textual clues. In this research, we conduct a comprehensive analysis on understanding the role of attention alignment by looking into the attention score calculation methods and check how it actually represents the visual region's and textual token's significance for the global assessment. We also analyse the conditions which attention score calculation mechanism would be more (or less) interpretable, and which may impact the model performance on three different VL tasks, including visual question answering, text-to-image generation, text-and-image matching (both sentence and image retrieval). Our analysis is the first of its kind and provides useful insights of the importance of each attention alignment score calculation when applied at the training phase of VL tasks, commonly ignored in attention-based cross modal models, and/or pretrained models.
Vision-and-Language Pretrained Models: A Survey
Apr 28, 2022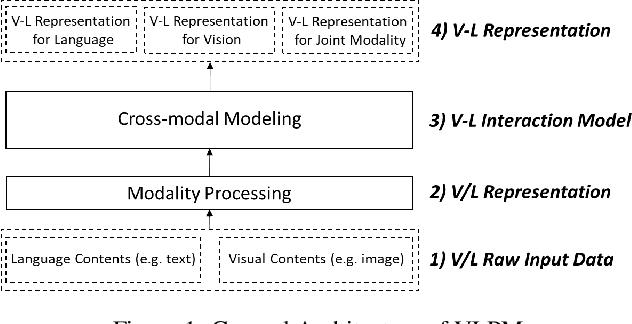
Pretrained models have produced great success in both Computer Vision (CV) and Natural Language Processing (NLP). This progress leads to learning joint representations of vision and language pretraining by feeding visual and linguistic contents into a multi-layer transformer, Visual-Language Pretrained Models (VLPMs). In this paper, we present an overview of the major advances achieved in VLPMs for producing joint representations of vision and language. As the preliminaries, we briefly describe the general task definition and genetic architecture of VLPMs. We first discuss the language and vision data encoding methods and then present the mainstream VLPM structure as the core content. We further summarise several essential pretraining and fine-tuning strategies. Finally, we highlight three future directions for both CV and NLP researchers to provide insightful guidance.