 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Road Detection in Snowy Forest Environment using RGB Camera
Dec 16, 2022

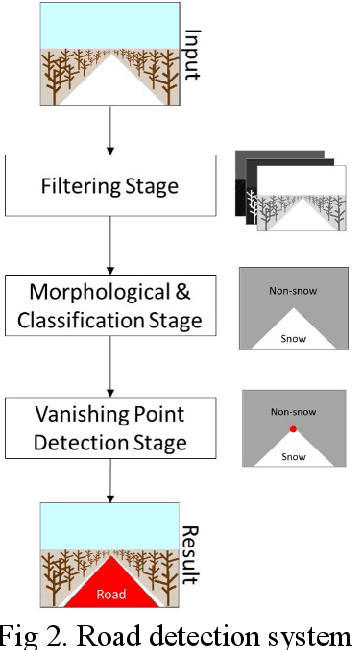


Automated driving technology has gained a lot of momentum in the last few years. For the exploration field, navigation is the important key for autonomous operation. In difficult scenarios such as snowy environment, the road is covered with snow and road detection is impossible in this situation using only basic techniques. This paper introduces detection of snowy road in forest environment using RGB camera. The method combines noise filtering technique with morphological operation to classify the image component. By using the assumption that all road is covered by snow and the snow part is defined as road area. From the perspective image of road, the vanishing point of road is one of factor to scope the region of road. This vanishing point is found with fitting triangle technique. The performance of algorithm is evaluated by two error value: False Negative Rate and False Positive Rate. The error shows that the method has high efficiency for detect road with straight road but low performance for curved road. This road region will be applied with depth information from camera to detect for obstacle in the future work.
* 5 pages, 9 figures, conference proceeding
3D-Aware Encoding for Style-based Neural Radiance Fields
Nov 12, 2022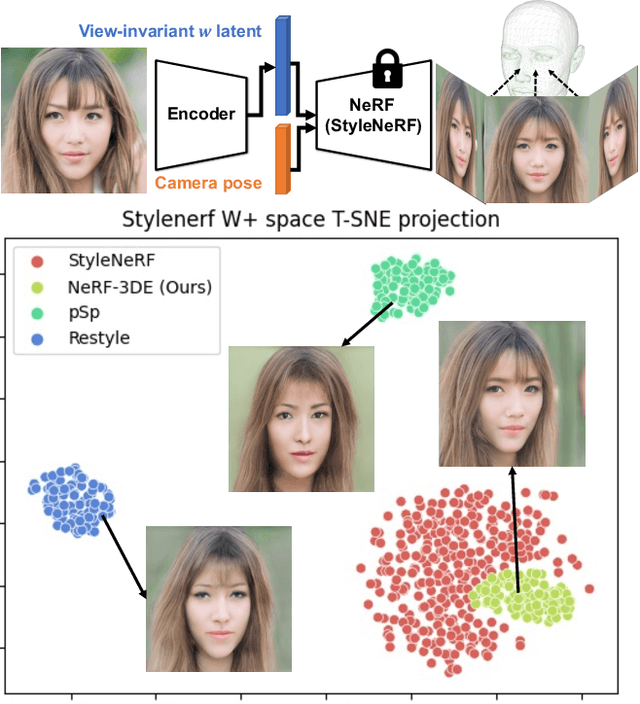
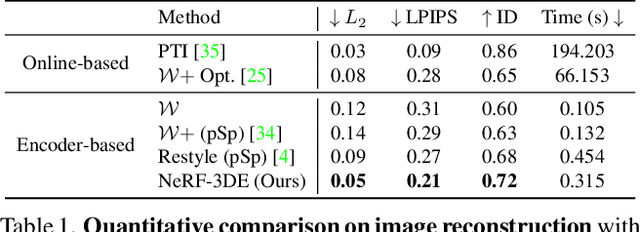
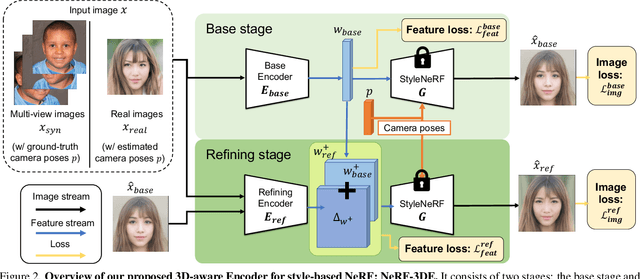
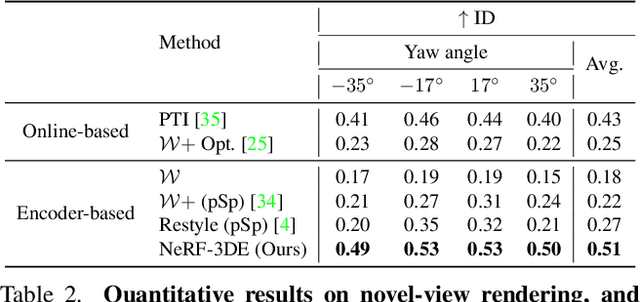
We tackle the task of NeRF inversion for style-based neural radiance fields, (e.g., StyleNeRF). In the task, we aim to learn an inversion function to project an input image to the latent space of a NeRF generator and then synthesize novel views of the original image based on the latent code. Compared with GAN inversion for 2D generative models, NeRF inversion not only needs to 1) preserve the identity of the input image, but also 2) ensure 3D consistency in generated novel views. This requires the latent code obtained from the single-view image to be invariant across multiple views. To address this new challenge, we propose a two-stage encoder for style-based NeRF inversion. In the first stage, we introduce a base encoder that converts the input image to a latent code. To ensure the latent code is view-invariant and is able to synthesize 3D consistent novel view images, we utilize identity contrastive learning to train the base encoder. Second, to better preserve the identity of the input image, we introduce a refining encoder to refine the latent code and add finer details to the output image. Importantly note that the novelty of this model lies in the design of its first-stage encoder which produces the closest latent code lying on the latent manifold and thus the refinement in the second stage would be close to the NeRF manifold. Through extensive experiments, we demonstrate that our proposed two-stage encoder qualitatively and quantitatively exhibits superiority over the existing encoders for inversion in both image reconstruction and novel-view rendering.
Attention-Aware Anime Line Drawing Colorization
Jan 05, 2023
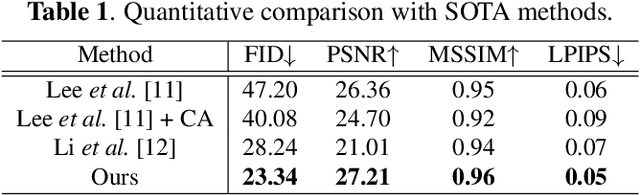

Automatic colorization of anime line drawing has attracted much attention in recent years since it can substantially benefit the animation industry. User-hint based methods are the mainstream approach for line drawing colorization, while reference-based methods offer a more intuitive approach. Nevertheless, although reference-based methods can improve feature aggregation of the reference image and the line drawing, the colorization results are not compelling in terms of color consistency or semantic correspondence. In this paper, we introduce an attention-based model for anime line drawing colorization, in which a channel-wise and spatial-wise Convolutional Attention module is used to improve the ability of the encoder for feature extraction and key area perception, and a Stop-Gradient Attention module with cross-attention and self-attention is used to tackle the cross-domain long-range dependency problem. Extensive experiments show that our method outperforms other SOTA methods, with more accurate line structure and semantic color information.
C2FTrans: Coarse-to-Fine Transformers for Medical Image Segmentation
Jun 29, 2022
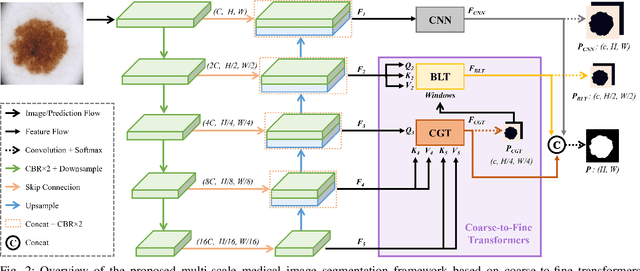
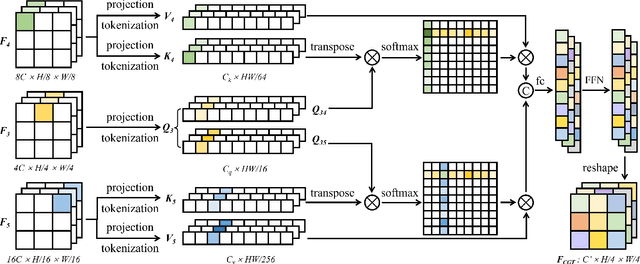
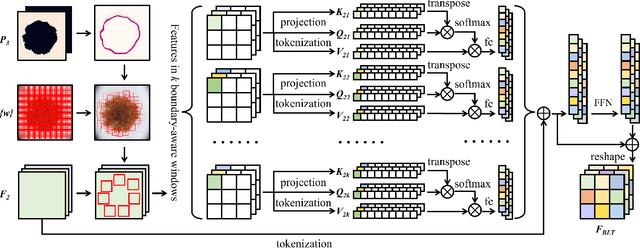
Convolutional neural networks (CNN), the most prevailing architecture for deep-learning based medical image analysis, are still functionally limited by their intrinsic inductive biases and inadequate receptive fields. Transformer, born to address this issue, has drawn explosive attention in natural language processing and computer vision due to its remarkable ability in capturing long-range dependency. However, most recent transformer-based methods for medical image segmentation directly apply vanilla transformers as an auxiliary module in CNN-based methods, resulting in severe detail loss due to the rigid patch partitioning scheme in transformers. To address this problem, we propose C2FTrans, a novel multi-scale architecture that formulates medical image segmentation as a coarse-to-fine procedure. C2FTrans mainly consists of a cross-scale global transformer (CGT) which addresses local contextual similarity in CNN and a boundary-aware local transformer (BLT) which overcomes boundary uncertainty brought by rigid patch partitioning in transformers. Specifically, CGT builds global dependency across three different small-scale feature maps to obtain rich global semantic features with an acceptable computational cost, while BLT captures mid-range dependency by adaptively generating windows around boundaries under the guidance of entropy to reduce computational complexity and minimize detail loss based on large-scale feature maps. Extensive experimental results on three public datasets demonstrate the superior performance of C2FTrans against state-of-the-art CNN-based and transformer-based methods with fewer parameters and lower FLOPs. We believe the design of C2FTrans would further inspire future work on developing efficient and lightweight transformers for medical image segmentation. The source code of this paper is publicly available at https://github.com/xianlin7/C2FTrans.
Synthesize Boundaries: A Boundary-aware Self-consistent Framework for Weakly Supervised Salient Object Detection
Dec 04, 2022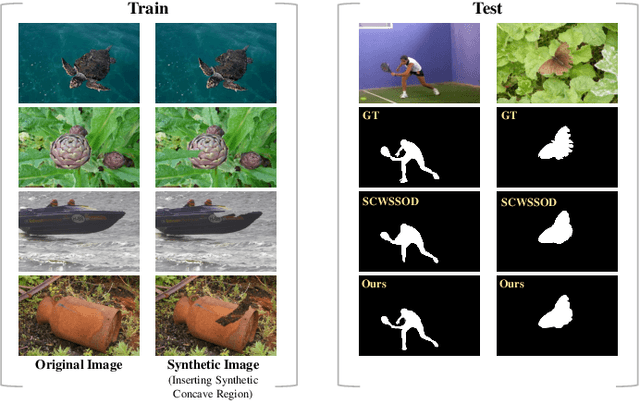
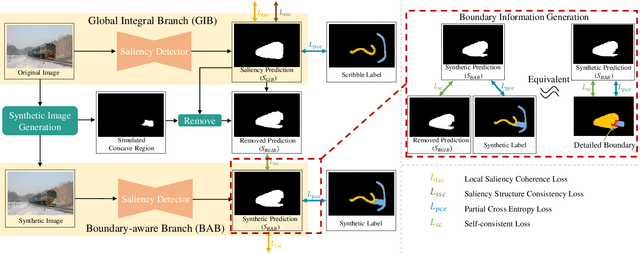
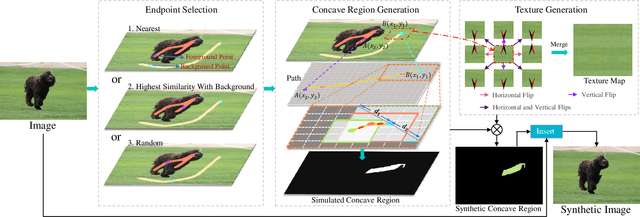
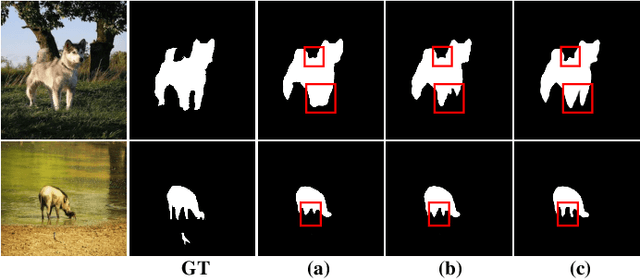
Fully supervised salient object detection (SOD) has made considerable progress based on expensive and time-consuming data with pixel-wise annotations. Recently, to relieve the labeling burden while maintaining performance, some scribble-based SOD methods have been proposed. However, learning precise boundary details from scribble annotations that lack edge information is still difficult. In this paper, we propose to learn precise boundaries from our designed synthetic images and labels without introducing any extra auxiliary data. The synthetic image creates boundary information by inserting synthetic concave regions that simulate the real concave regions of salient objects. Furthermore, we propose a novel self-consistent framework that consists of a global integral branch (GIB) and a boundary-aware branch (BAB) to train a saliency detector. GIB aims to identify integral salient objects, whose input is the original image. BAB aims to help predict accurate boundaries, whose input is the synthetic image. These two branches are connected through a self-consistent loss to guide the saliency detector to predict precise boundaries while identifying salient objects. Experimental results on five benchmarks demonstrate that our method outperforms the state-of-the-art weakly supervised SOD methods and further narrows the gap with the fully supervised methods.
Coarse-to-fine Task-driven Inpainting for Geoscience Images
Nov 20, 2022

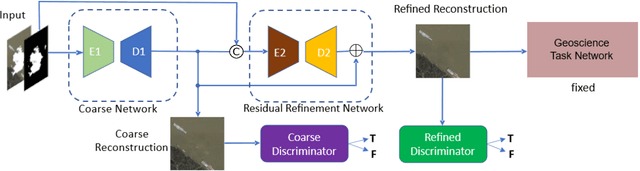
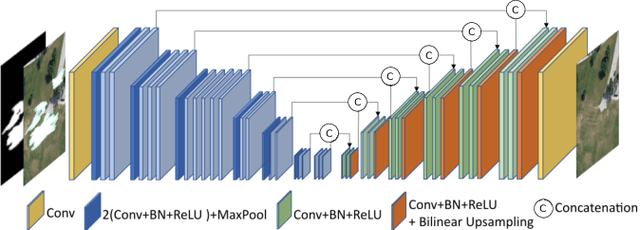
The processing and recognition of geoscience images have wide applications. Most of existing researches focus on understanding the high-quality geoscience images by assuming that all the images are clear. However, in many real-world cases, the geoscience images might contain occlusions during the image acquisition. This problem actually implies the image inpainting problem in computer vision and multimedia. To the best of our knowledge, all the existing image inpainting algorithms learn to repair the occluded regions for a better visualization quality, they are excellent for natural images but not good enough for geoscience images by ignoring the geoscience related tasks. This paper aims to repair the occluded regions for a better geoscience task performance with the advanced visualization quality simultaneously, without changing the current deployed deep learning based geoscience models. Because of the complex context of geoscience images, we propose a coarse-to-fine encoder-decoder network with coarse-to-fine adversarial context discriminators to reconstruct the occluded image regions. Due to the limited data of geoscience images, we use a MaskMix based data augmentation method to exploit more information from limited geoscience image data. The experimental results on three public geoscience datasets for remote sensing scene recognition, cross-view geolocation and semantic segmentation tasks respectively show the effectiveness and accuracy of the proposed method.
A Sketch Is Worth a Thousand Words: Image Retrieval with Text and Sketch
Aug 05, 2022


We address the problem of retrieving images with both a sketch and a text query. We present TASK-former (Text And SKetch transformer), an end-to-end trainable model for image retrieval using a text description and a sketch as input. We argue that both input modalities complement each other in a manner that cannot be achieved easily by either one alone. TASK-former follows the late-fusion dual-encoder approach, similar to CLIP, which allows efficient and scalable retrieval since the retrieval set can be indexed independently of the queries. We empirically demonstrate that using an input sketch (even a poorly drawn one) in addition to text considerably increases retrieval recall compared to traditional text-based image retrieval. To evaluate our approach, we collect 5,000 hand-drawn sketches for images in the test set of the COCO dataset. The collected sketches are available a https://janesjanes.github.io/tsbir/.
GazeNeRF: 3D-Aware Gaze Redirection with Neural Radiance Fields
Dec 08, 2022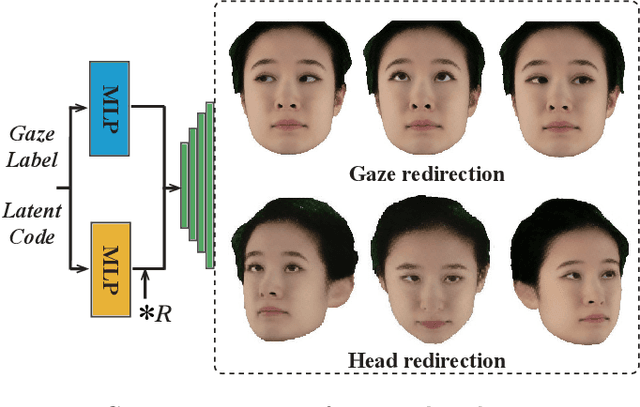

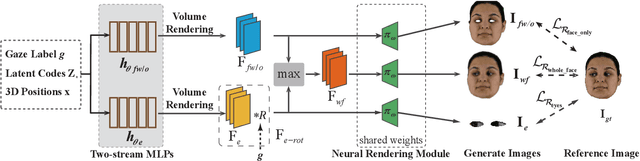

We propose GazeNeRF, a 3D-aware method for the task of gaze redirection. Existing gaze redirection methods operate on 2D images and struggle to generate 3D consistent results. Instead, we build on the intuition that the face region and eyeballs are separate 3D structures that move in a coordinated yet independent fashion. Our method leverages recent advancements in conditional image-based neural radiance fields and proposes a two-stream architecture that predicts volumetric features for the face and eye regions separately. Rigidly transforming the eye features via a 3D rotation matrix provides fine-grained control over the desired gaze angle. The final, redirected image is then attained via differentiable volume compositing. Our experiments show that this architecture outperforms naively conditioned NeRF baselines as well as previous state-of-the-art 2D gaze redirection methods in terms of redirection accuracy and identity preservation.
Modeling Uncertain Feature Representation for Domain Generalization
Jan 16, 2023Though deep neural networks have achieved impressive success on various vision tasks, obvious performance degradation still exists when models are tested in out-of-distribution scenarios. In addressing this limitation, we ponder that the feature statistics (mean and standard deviation), which carry the domain characteristics of the training data, can be properly manipulated to improve the generalization ability of deep learning models. Existing methods commonly consider feature statistics as deterministic values measured from the learned features and do not explicitly model the uncertain statistics discrepancy caused by potential domain shifts during testing. In this paper, we improve the network generalization ability by modeling domain shifts with uncertainty (DSU), i.e., characterizing the feature statistics as uncertain distributions during training. Specifically, we hypothesize that the feature statistic, after considering the potential uncertainties, follows a multivariate Gaussian distribution. During inference, we propose an instance-wise adaptation strategy that can adaptively deal with the unforeseeable shift and further enhance the generalization ability of the trained model with negligible additional cost. We also conduct theoretical analysis on the aspects of generalization error bound and the implicit regularization effect, showing the efficacy of our method. Extensive experiments demonstrate that our method consistently improves the network generalization ability on multiple vision tasks, including image classification, semantic segmentation, instance retrieval, and pose estimation. Our methods are simple yet effective and can be readily integrated into networks without additional trainable parameters or loss constraints. Code will be released in https://github.com/lixiaotong97/DSU.
Intrinsic Gaussian Process on Unknown Manifolds with Probabilistic Metrics
Jan 16, 2023

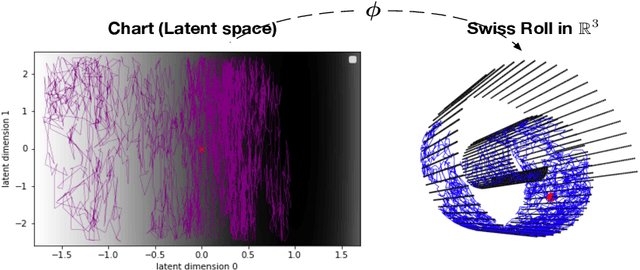
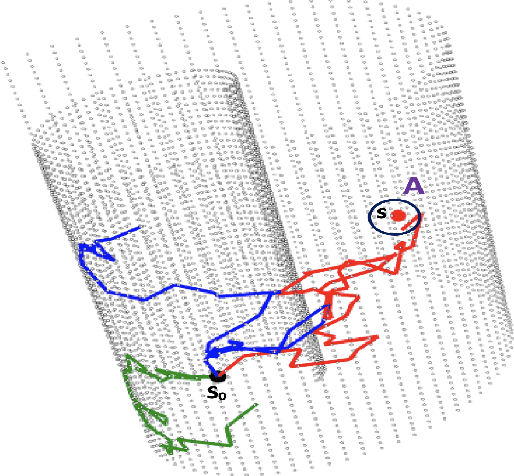
This article presents a novel approach to construct Intrinsic Gaussian Processes for regression on unknown manifolds with probabilistic metrics (GPUM) in point clouds. In many real world applications, one often encounters high dimensional data (e.g. point cloud data) centred around some lower dimensional unknown manifolds. The geometry of manifold is in general different from the usual Euclidean geometry. Naively applying traditional smoothing methods such as Euclidean Gaussian Processes (GPs) to manifold valued data and so ignoring the geometry of the space can potentially lead to highly misleading predictions and inferences. A manifold embedded in a high dimensional Euclidean space can be well described by a probabilistic mapping function and the corresponding latent space. We investigate the geometrical structure of the unknown manifolds using the Bayesian Gaussian Processes latent variable models(BGPLVM) and Riemannian geometry. The distribution of the metric tensor is learned using BGPLVM. The boundary of the resulting manifold is defined based on the uncertainty quantification of the mapping. We use the the probabilistic metric tensor to simulate Brownian Motion paths on the unknown manifold. The heat kernel is estimated as the transition density of Brownian Motion and used as the covariance functions of GPUM. The applications of GPUM are illustrated in the simulation studies on the Swiss roll, high dimensional real datasets of WiFi signals and image data examples. Its performance is compared with the Graph Laplacian GP, Graph Matern GP and Euclidean GP.