 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
End-to-End Image-Based Fashion Recommendation
May 05, 2022
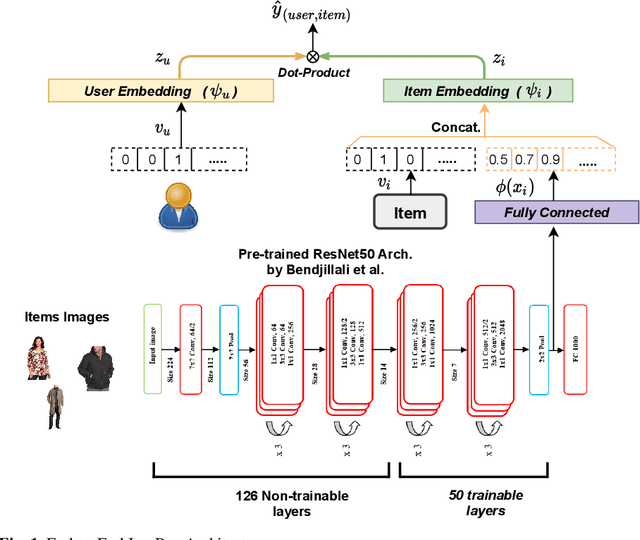

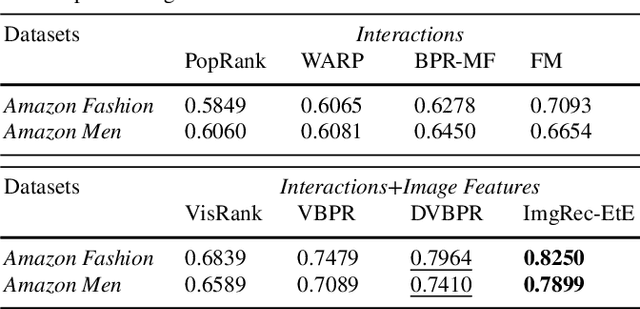

In fashion-based recommendation settings, incorporating the item image features is considered a crucial factor, and it has shown significant improvements to many traditional models, including but not limited to matrix factorization, auto-encoders, and nearest neighbor models. While there are numerous image-based recommender approaches that utilize dedicated deep neural networks, comparisons to attribute-aware models are often disregarded despite their ability to be easily extended to leverage items' image features. In this paper, we propose a simple yet effective attribute-aware model that incorporates image features for better item representation learning in item recommendation tasks. The proposed model utilizes items' image features extracted by a calibrated ResNet50 component. We present an ablation study to compare incorporating the image features using three different techniques into the recommender system component that can seamlessly leverage any available items' attributes. Experiments on two image-based real-world recommender systems datasets show that the proposed model significantly outperforms all state-of-the-art image-based models.
LRIP-Net: Low-Resolution Image Prior based Network for Limited-Angle CT Reconstruction
Jul 30, 2022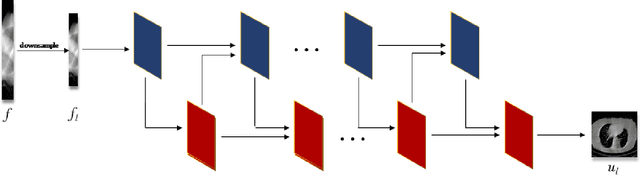
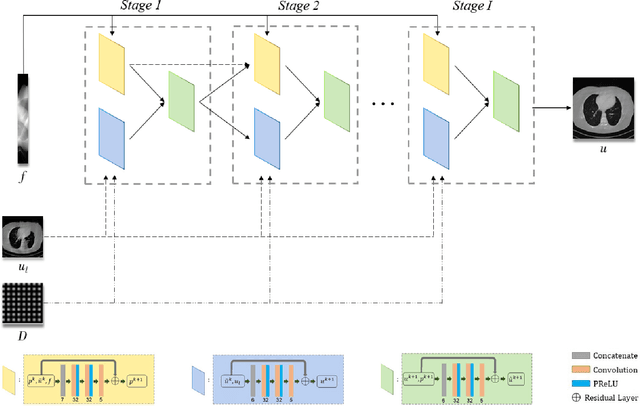
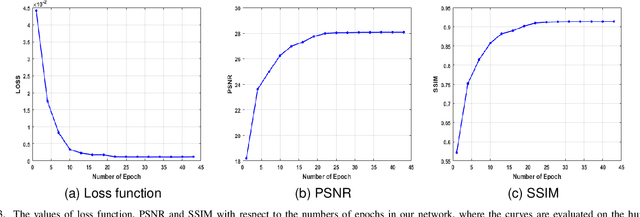
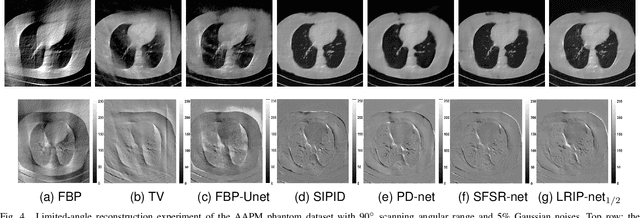
In the practical applications of computed tomography imaging, the projection data may be acquired within a limited-angle range and corrupted by noises due to the limitation of scanning conditions. The noisy incomplete projection data results in the ill-posedness of the inverse problems. In this work, we theoretically verify that the low-resolution reconstruction problem has better numerical stability than the high-resolution problem. In what follows, a novel low-resolution image prior based CT reconstruction model is proposed to make use of the low-resolution image to improve the reconstruction quality. More specifically, we build up a low-resolution reconstruction problem on the down-sampled projection data, and use the reconstructed low-resolution image as prior knowledge for the original limited-angle CT problem. We solve the constrained minimization problem by the alternating direction method with all subproblems approximated by the convolutional neural networks. Numerical experiments demonstrate that our double-resolution network outperforms both the variational method and popular learning-based reconstruction methods on noisy limited-angle reconstruction problems.
WaveGAN: Frequency-aware GAN for High-Fidelity Few-shot Image Generation
Jul 15, 2022

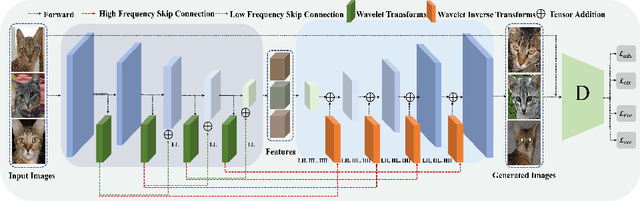
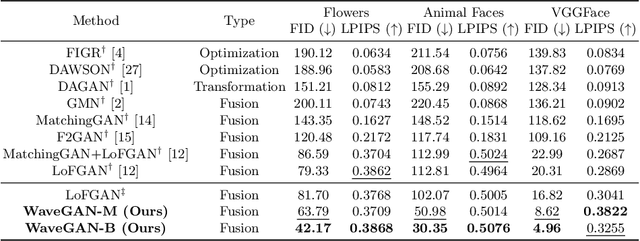
Existing few-shot image generation approaches typically employ fusion-based strategies, either on the image or the feature level, to produce new images. However, previous approaches struggle to synthesize high-frequency signals with fine details, deteriorating the synthesis quality. To address this, we propose WaveGAN, a frequency-aware model for few-shot image generation. Concretely, we disentangle encoded features into multiple frequency components and perform low-frequency skip connections to preserve outline and structural information. Then we alleviate the generator's struggles of synthesizing fine details by employing high-frequency skip connections, thus providing informative frequency information to the generator. Moreover, we utilize a frequency L1-loss on the generated and real images to further impede frequency information loss. Extensive experiments demonstrate the effectiveness and advancement of our method on three datasets. Noticeably, we achieve new state-of-the-art with FID 42.17, LPIPS 0.3868, FID 30.35, LPIPS 0.5076, and FID 4.96, LPIPS 0.3822 respectively on Flower, Animal Faces, and VGGFace. GitHub: https://github.com/kobeshegu/ECCV2022_WaveGAN
Sparse Visual Counterfactual Explanations in Image Space
May 16, 2022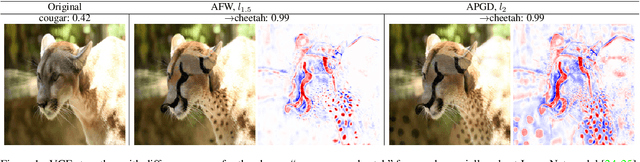
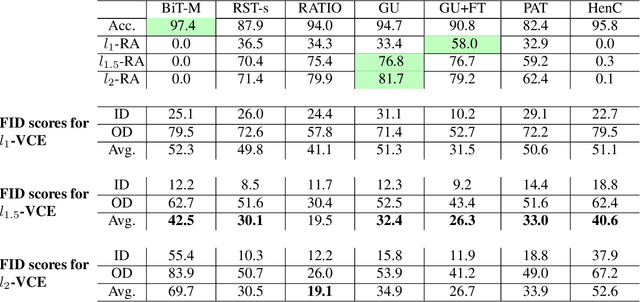


Visual counterfactual explanations (VCEs) in image space are an important tool to understand decisions of image classifiers as they show under which changes of the image the decision of the classifier would change. Their generation in image space is challenging and requires robust models due to the problem of adversarial examples. Existing techniques to generate VCEs in image space suffer from spurious changes in the background. Our novel perturbation model for VCEs together with its efficient optimization via our novel Auto-Frank-Wolfe scheme yields sparse VCEs which are significantly more object-centric. Moreover, we show that VCEs can be used to detect undesired behavior of ImageNet classifiers due to spurious features in the ImageNet dataset and discuss how estimates of the data-generating distribution can be used for VCEs.
Prompt Tuning for Parameter-efficient Medical Image Segmentation
Nov 16, 2022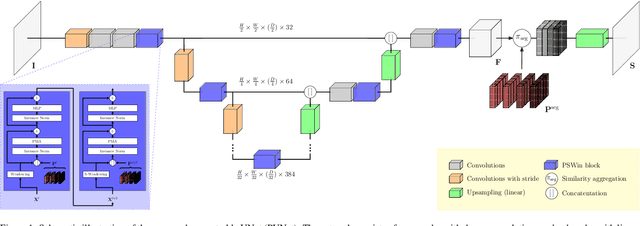
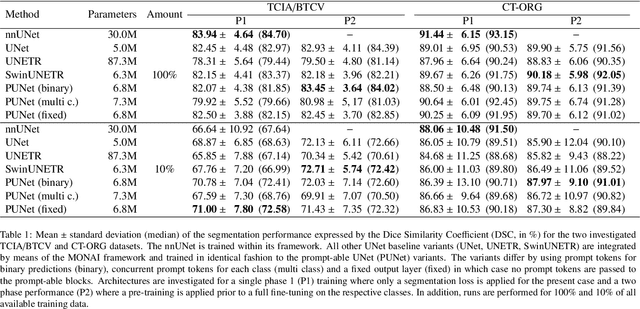
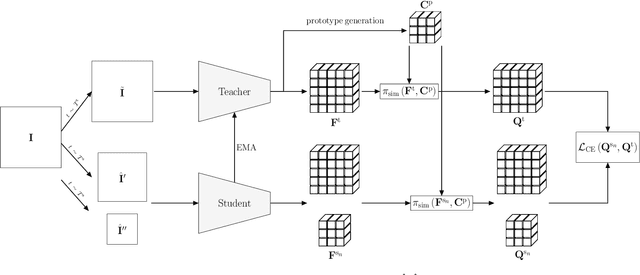
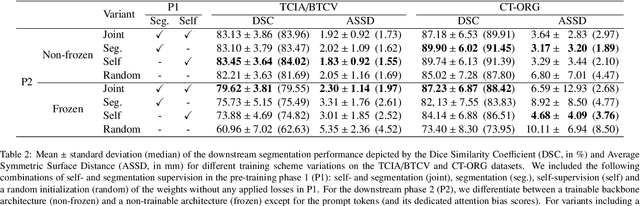
Neural networks pre-trained on a self-supervision scheme have become the standard when operating in data rich environments with scarce annotations. As such, fine-tuning a model to a downstream task in a parameter-efficient but effective way, e.g. for a new set of classes in the case of semantic segmentation, is of increasing importance. In this work, we propose and investigate several contributions to achieve a parameter-efficient but effective adaptation for semantic segmentation on two medical imaging datasets. Relying on the recently popularized prompt tuning approach, we provide a prompt-able UNet (PUNet) architecture, that is frozen after pre-training, but adaptable throughout the network by class-dependent learnable prompt tokens. We pre-train this architecture with a dedicated dense self-supervision scheme based on assignments to online generated prototypes (contrastive prototype assignment, CPA) of a student teacher combination alongside a concurrent segmentation loss on a subset of classes. We demonstrate that the resulting neural network model is able to attenuate the gap between fully fine-tuned and parameter-efficiently adapted models on CT imaging datasets. As such, the difference between fully fine-tuned and prompt-tuned variants amounts to only 3.83 pp for the TCIA/BTCV dataset and 2.67 pp for the CT-ORG dataset in the mean Dice Similarity Coefficient (DSC, in %) while only prompt tokens, corresponding to 0.85% of the pre-trained backbone model with 6.8M frozen parameters, are adjusted. The code for this work is available on https://github.com/marcdcfischer/PUNet .
SwinDepth: Unsupervised Depth Estimation using Monocular Sequences via Swin Transformer and Densely Cascaded Network
Jan 17, 2023
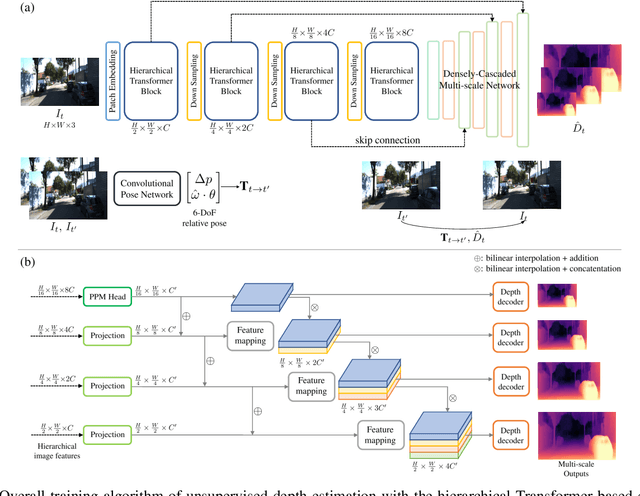
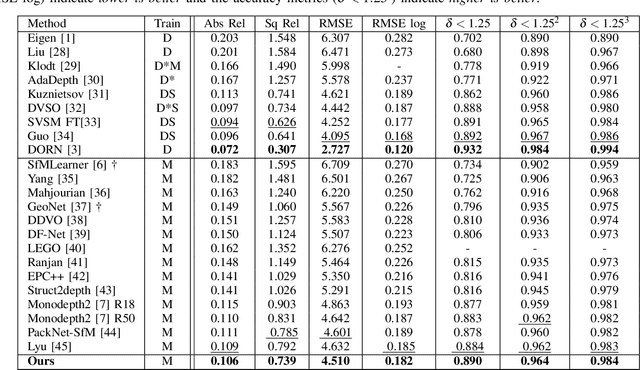
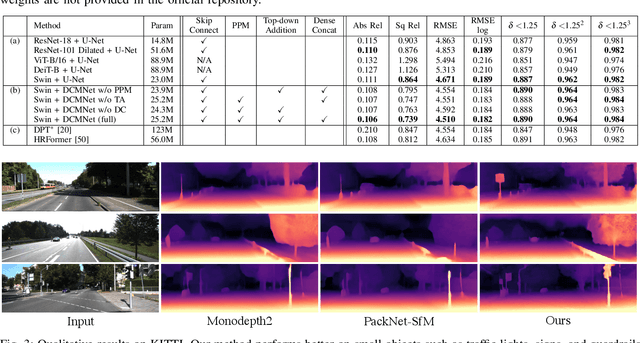
Monocular depth estimation plays a critical role in various computer vision and robotics applications such as localization, mapping, and 3D object detection. Recently, learning-based algorithms achieve huge success in depth estimation by training models with a large amount of data in a supervised manner. However, it is challenging to acquire dense ground truth depth labels for supervised training, and the unsupervised depth estimation using monocular sequences emerges as a promising alternative. Unfortunately, most studies on unsupervised depth estimation explore loss functions or occlusion masks, and there is little change in model architecture in that ConvNet-based encoder-decoder structure becomes a de-facto standard for depth estimation. In this paper, we employ a convolution-free Swin Transformer as an image feature extractor so that the network can capture both local geometric features and global semantic features for depth estimation. Also, we propose a Densely Cascaded Multi-scale Network (DCMNet) that connects every feature map directly with another from different scales via a top-down cascade pathway. This densely cascaded connectivity reinforces the interconnection between decoding layers and produces high-quality multi-scale depth outputs. The experiments on two different datasets, KITTI and Make3D, demonstrate that our proposed method outperforms existing state-of-the-art unsupervised algorithms.
Embodied Agents for Efficient Exploration and Smart Scene Description
Jan 17, 2023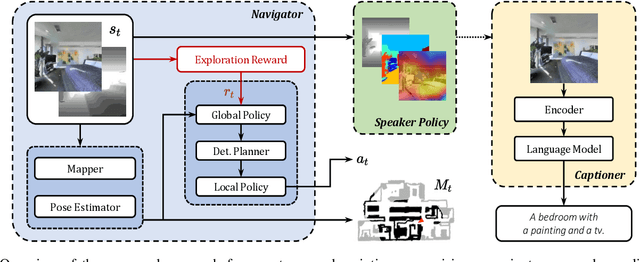



The development of embodied agents that can communicate with humans in natural language has gained increasing interest over the last years, as it facilitates the diffusion of robotic platforms in human-populated environments. As a step towards this objective, in this work, we tackle a setting for visual navigation in which an autonomous agent needs to explore and map an unseen indoor environment while portraying interesting scenes with natural language descriptions. To this end, we propose and evaluate an approach that combines recent advances in visual robotic exploration and image captioning on images generated through agent-environment interaction. Our approach can generate smart scene descriptions that maximize semantic knowledge of the environment and avoid repetitions. Further, such descriptions offer user-understandable insights into the robot's representation of the environment by highlighting the prominent objects and the correlation between them as encountered during the exploration. To quantitatively assess the performance of the proposed approach, we also devise a specific score that takes into account both exploration and description skills. The experiments carried out on both photorealistic simulated environments and real-world ones demonstrate that our approach can effectively describe the robot's point of view during exploration, improving the human-friendly interpretability of its observations.
Multimodal Video Adapter for Parameter Efficient Video Text Retrieval
Jan 19, 2023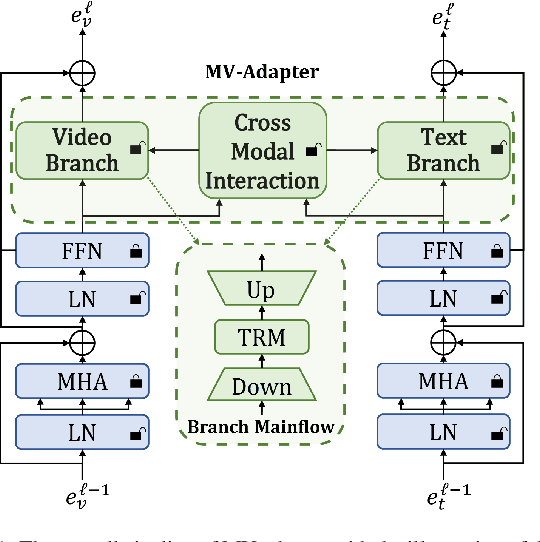
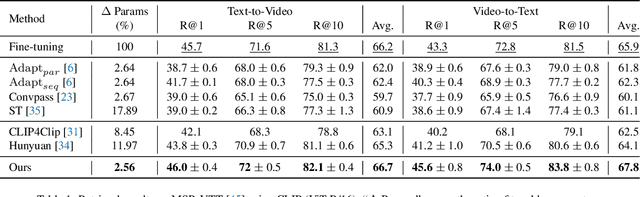
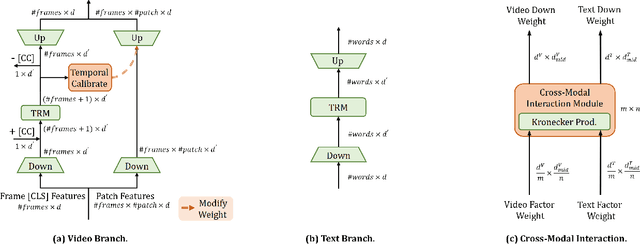
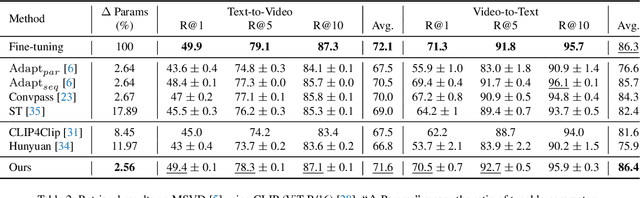
State-of-the-art video-text retrieval (VTR) methods usually fully fine-tune the pre-trained model (e.g. CLIP) on specific datasets, which may suffer from substantial storage costs in practical applications since a separate model per task needs to be stored. To overcome this issue, we present the premier work on performing parameter-efficient VTR from the pre-trained model, i.e., only a small number of parameters are tunable while freezing the backbone. Towards this goal, we propose a new method dubbed Multimodal Video Adapter (MV-Adapter) for efficiently transferring the knowledge in the pre-trained CLIP from image-text to video-text. Specifically, MV-Adapter adopts bottleneck structures in both video and text branches and introduces two novel components. The first is a Temporal Adaptation Module employed in the video branch to inject global and local temporal contexts. We also learn weights calibrations to adapt to the dynamic variations across frames. The second is a Cross-Modal Interaction Module that generates weights for video/text branches through a shared parameter space, for better aligning between modalities. Thanks to above innovations, MV-Adapter can achieve on-par or better performance than standard fine-tuning with negligible parameters overhead. Notably, on five widely used VTR benchmarks (MSR-VTT, MSVD, LSMDC, DiDemo, and ActivityNet), MV-Adapter consistently outperforms various competing methods in V2T/T2V tasks with large margins. Codes will be released.
Performance degradation of ImageNet trained models by simple image transformations
Jul 17, 2022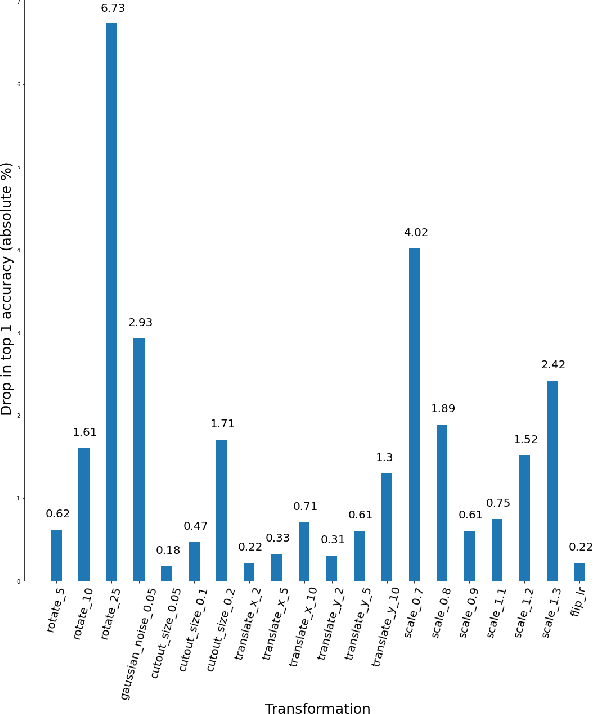

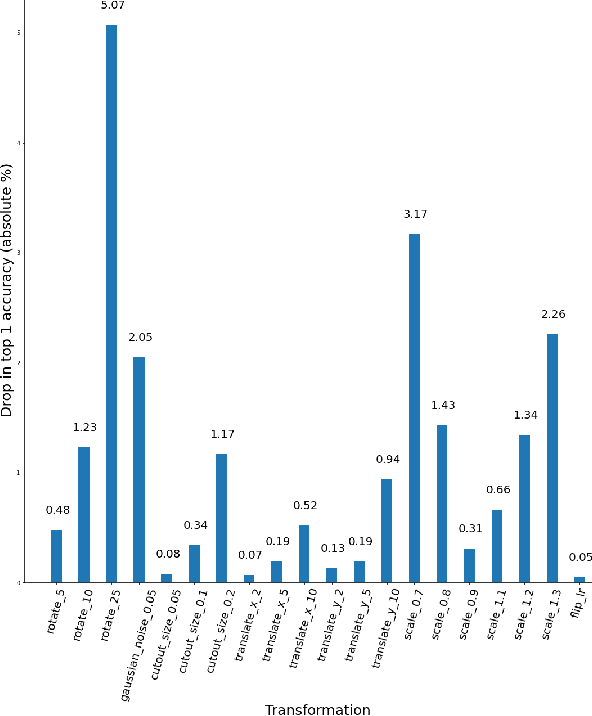
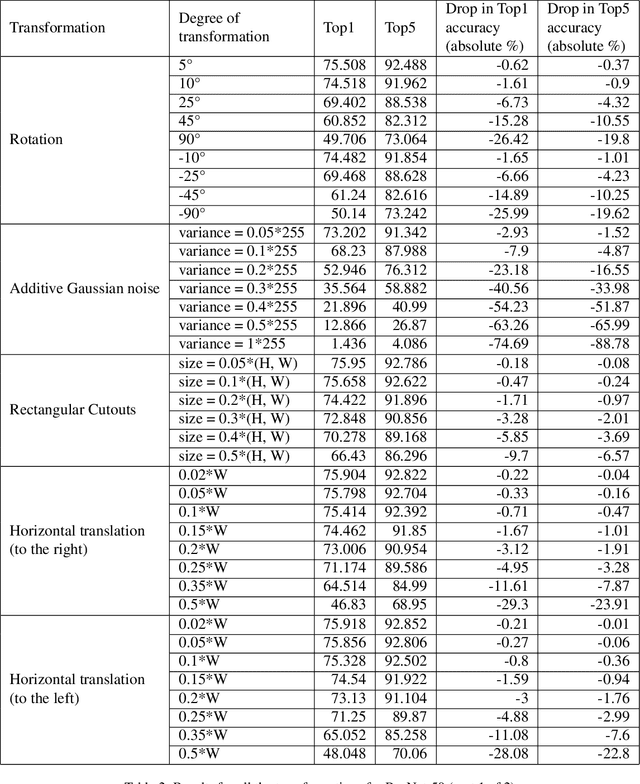
ImageNet trained PyTorch models are generally preferred as the off-the-shelf models for direct use or for initialisation in most computer vision tasks. In this paper, we simply test a representative set of these convolution and transformer based models under many simple image transformations like horizontal shifting, vertical shifting, scaling, rotation, presence of Gaussian noise, cutout, horizontal flip and vertical flip and report the performance drop caused by such transformations. We find that even simple transformations like rotating the image by 10{\deg} or zooming in by 20% can reduce the top-1 accuracy of models like ResNet152 by 1%+. The code is available at https://github.com/harshm121/imagenet-transformation-degradation.
POLCOVID: a multicenter multiclass chest X-ray database (Poland, 2020-2021)
Dec 05, 2022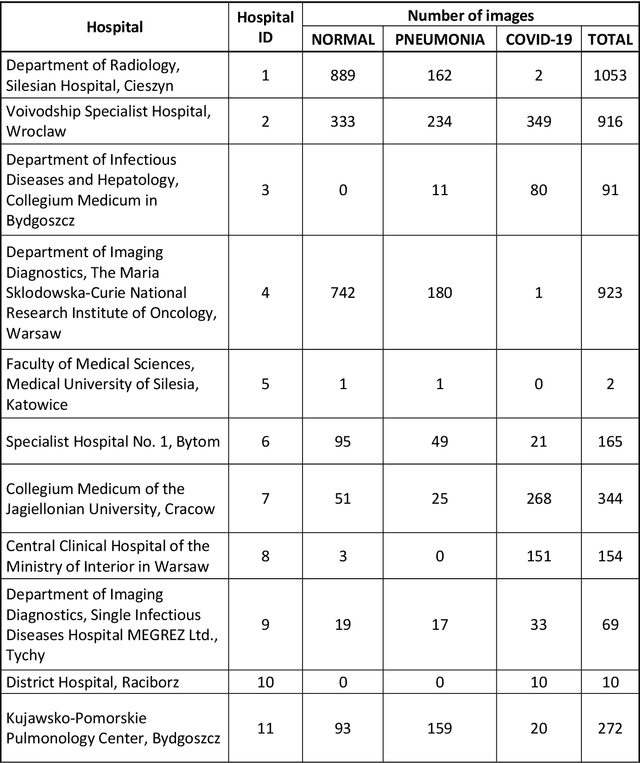
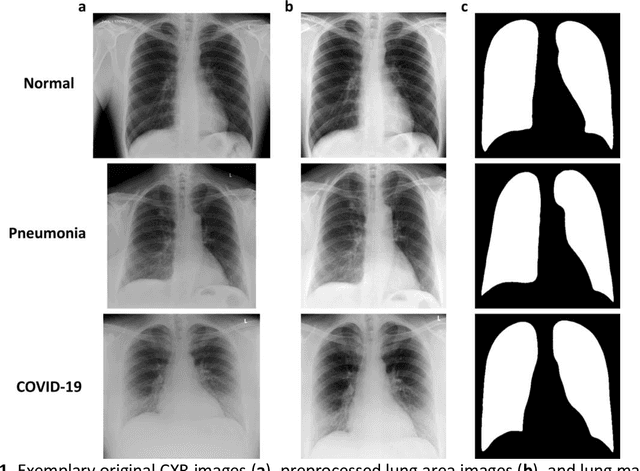
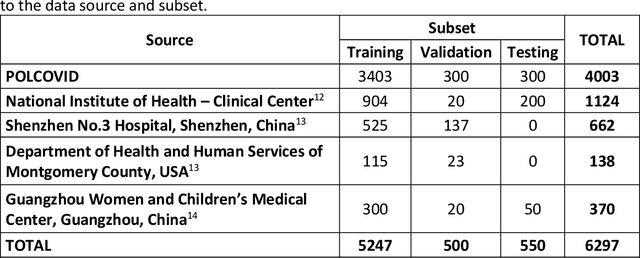
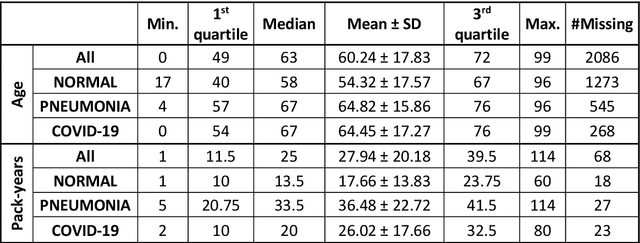
The outbreak of the SARS-CoV-2 pandemic has put healthcare systems worldwide to their limits, resulting in increased waiting time for diagnosis and required medical assistance. With chest radiographs (CXR) being one of the most common COVID-19 diagnosis methods, many artificial intelligence tools for image-based COVID-19 detection have been developed, often trained on a small number of images from COVID-19-positive patients. Thus, the need for high-quality and well-annotated CXR image databases increased. This paper introduces POLCOVID dataset, containing chest X-ray (CXR) images of patients with COVID-19 or other-type pneumonia, and healthy individuals gathered from 15 Polish hospitals. The original radiographs are accompanied by the preprocessed images limited to the lung area and the corresponding lung masks obtained with the segmentation model. Moreover, the manually created lung masks are provided for a part of POLCOVID dataset and the other four publicly available CXR image collections. POLCOVID dataset can help in pneumonia or COVID-19 diagnosis, while the set of matched images and lung masks may serve for the development of lung segmentation solutions.