 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
BinImg2Vec: Augmenting Malware Binary Image Classification with Data2Vec
Sep 02, 2022
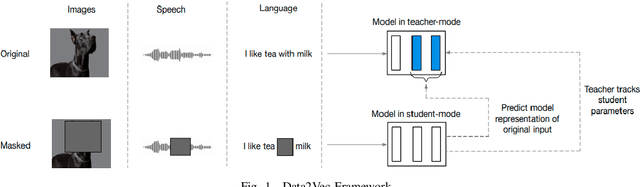

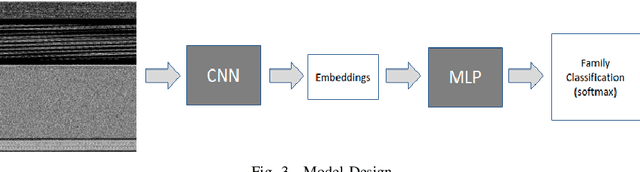
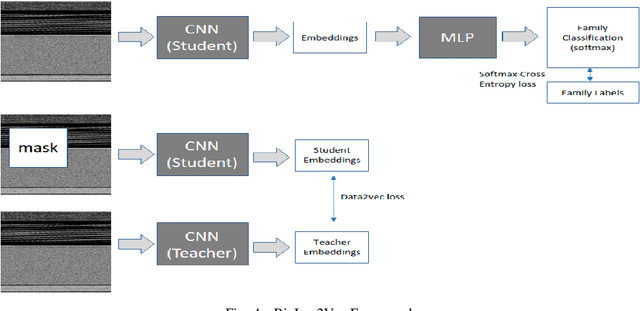
Rapid digitalisation spurred by the Covid-19 pandemic has resulted in more cyber crime. Malware-as-a-service is now a booming business for cyber criminals. With the surge in malware activities, it is vital for cyber defenders to understand more about the malware samples they have at hand as such information can greatly influence their next course of actions during a breach. Recently, researchers have shown how malware family classification can be done by first converting malware binaries into grayscale images and then passing them through neural networks for classification. However, most work focus on studying the impact of different neural network architectures on classification performance. In the last year, researchers have shown that augmenting supervised learning with self-supervised learning can improve performance. Even more recently, Data2Vec was proposed as a modality agnostic self-supervised framework to train neural networks. In this paper, we present BinImg2Vec, a framework of training malware binary image classifiers that incorporates both self-supervised learning and supervised learning to produce a model that consistently outperforms one trained only via supervised learning. We were able to achieve a 4% improvement in classification performance and a 0.5% reduction in performance variance over multiple runs. We also show how our framework produces embeddings that can be well clustered, facilitating model explanability.
Deep Diversity-Enhanced Feature Representation of Hyperspectral Images
Jan 15, 2023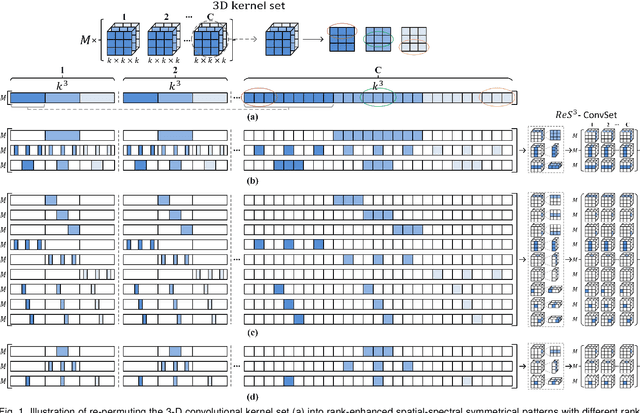
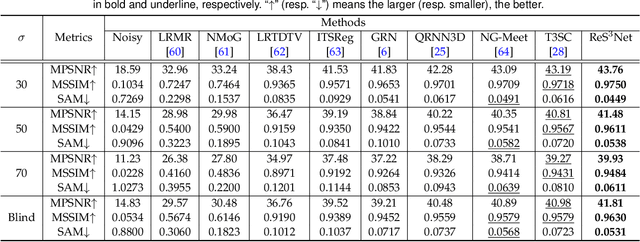
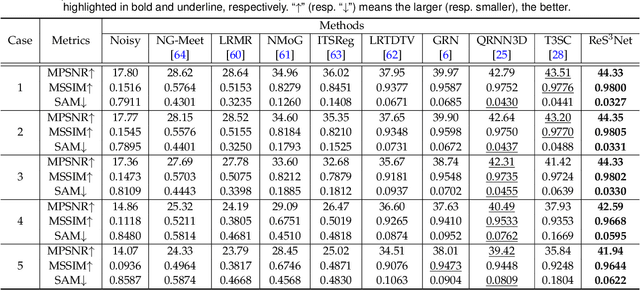
In this paper, we study the problem of embedding the high-dimensional spatio-spectral information of hyperspectral (HS) images efficiently and effectively, oriented by feature diversity. To be specific, based on the theoretical formulation that feature diversity is correlated with the rank of the unfolded kernel matrix, we rectify 3D convolution by modifying its topology to boost the rank upper-bound, yielding a rank-enhanced spatial-spectral symmetrical convolution set (ReS$^3$-ConvSet), which is able to not only learn diverse and powerful feature representations but also save network parameters. In addition, we also propose a novel diversity-aware regularization (DA-Reg) term, which acts directly on the feature maps to maximize the independence among elements. To demonstrate the superiority of the proposed ReS$^3$-ConvSet and DA-Reg, we apply them to various HS image processing and analysis tasks, including denoising, spatial super-resolution, and classification. Extensive experiments demonstrate that the proposed approaches outperform state-of-the-art methods to a significant extent both quantitatively and qualitatively. The code is publicly available at \url{https://github.com/jinnh/ReSSS-ConvSet}.
MIRNF: Medical Image Registration via Neural Fields
Jun 07, 2022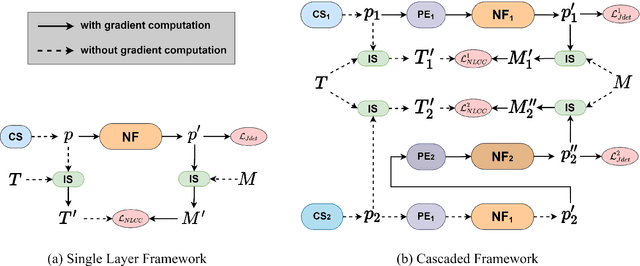
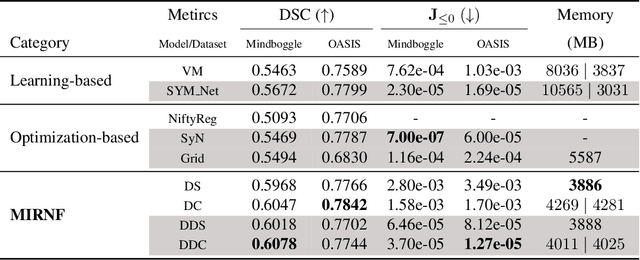
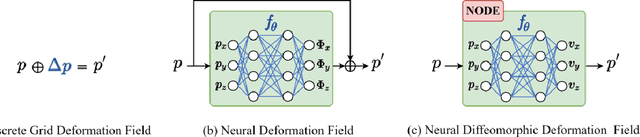
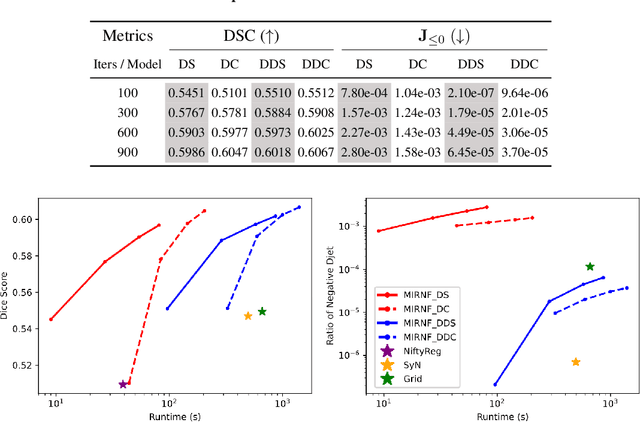
Image registration is widely used in medical image analysis to provide spatial correspondences between two images. Recently learning-based methods utilizing convolutional neural networks (CNNs) have been proposed for solving image registration problems. The learning-based methods tend to be much faster than traditional optimization-based methods, but the accuracy improvements gained from the complex CNN-based methods are modest. Here we introduce a new deep-neural net-based image registration framework, named \textbf{MIRNF}, which represents the correspondence mapping with a continuous function implemented via Neural Fields. MIRNF outputs either a deformation vector or velocity vector given a 3D coordinate as input. To ensure the mapping is diffeomorphic, the velocity vector output from MIRNF is integrated using the Neural ODE solver to derive the correspondences between two images. Furthermore, we propose a hybrid coordinate sampler along with a cascaded architecture to achieve the high-similarity mapping performance and low-distortion deformation fields. We conduct experiments on two 3D MR brain scan datasets, showing that our proposed framework provides state-of-art registration performance while maintaining comparable optimization time.
A Baseline for Detecting Out-of-Distribution Examples in Image Captioning
Jul 12, 2022
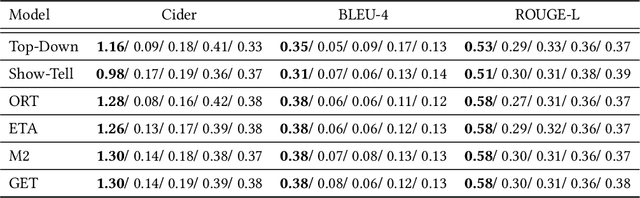

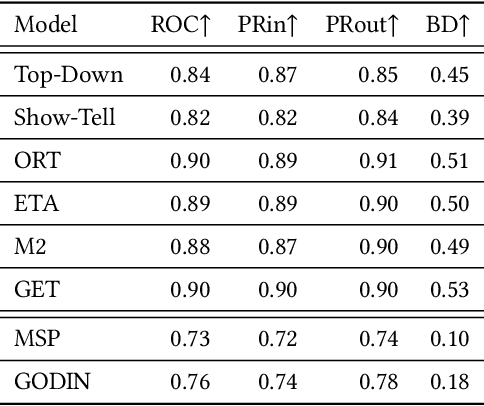
Image captioning research achieved breakthroughs in recent years by developing neural models that can generate diverse and high-quality descriptions for images drawn from the same distribution as training images. However, when facing out-of-distribution (OOD) images, such as corrupted images, or images containing unknown objects, the models fail in generating relevant captions. In this paper, we consider the problem of OOD detection in image captioning. We formulate the problem and suggest an evaluation setup for assessing the model's performance on the task. Then, we analyze and show the effectiveness of the caption's likelihood score at detecting and rejecting OOD images, which implies that the relatedness between the input image and the generated caption is encapsulated within the score.
Implicit Shape Model Trees: Recognition of 3-D Indoor Scenes and Prediction of Object Poses for Mobile Robots
Jan 25, 2023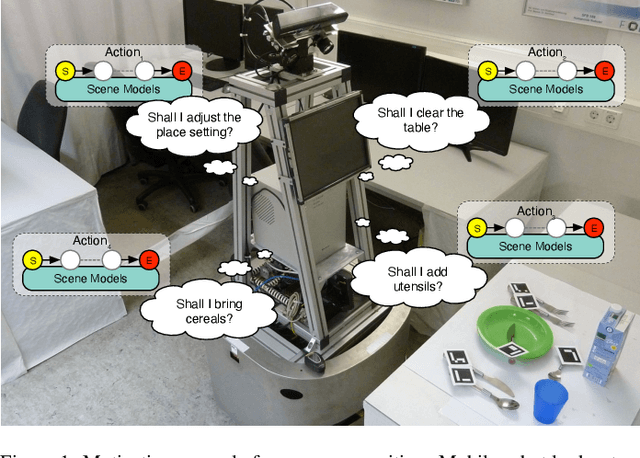
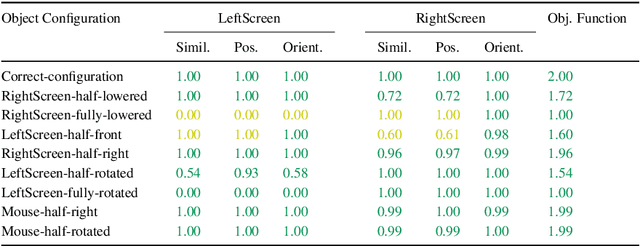
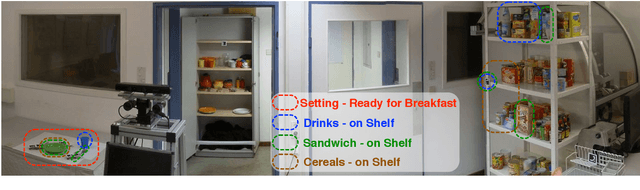
For a mobile robot, we present an approach to recognize scenes in arrangements of objects distributed over cluttered environments. Recognition is made possible by letting the robot alternately search for objects and assign found objects to scenes. Our scene model "Implicit Shape Model (ISM) trees" allows us to solve these two tasks together. For the ISM trees, this article presents novel algorithms for recognizing scenes and predicting the poses of searched objects. We define scenes as sets of objects, where some objects are connected by 3-D spatial relations. In previous work, we recognized scenes using single ISMs. However, these ISMs were prone to false positives. To address this problem, we introduced ISM trees, a hierarchical model that includes multiple ISMs. Through the recognition algorithm it contributes, this article ultimately enables the use of ISM trees in scene recognition. We intend to enable users to generate ISM trees from object arrangements demonstrated by humans. The lack of a suitable algorithm is overcome by the introduction of an ISM tree generation algorithm. In scene recognition, it is usually assumed that image data is already available. However, this is not always the case for robots. For this reason, we combined scene recognition and object search in previous work. However, we did not provide an efficient algorithm to link the two tasks. This article introduces such an algorithm that predicts the poses of searched objects with relations. Experiments show that our overall approach enables robots to find and recognize object arrangements that cannot be perceived from a single viewpoint.
HumanGen: Generating Human Radiance Fields with Explicit Priors
Dec 10, 2022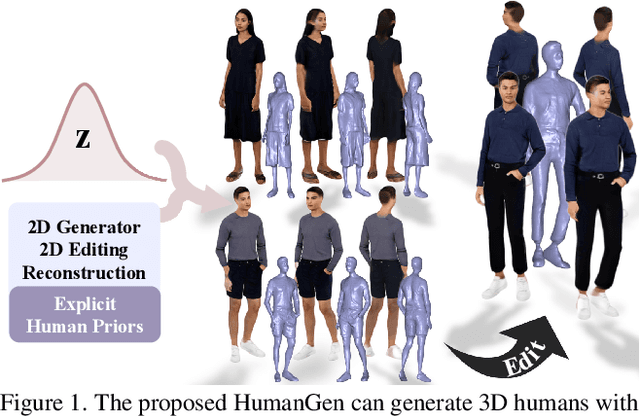
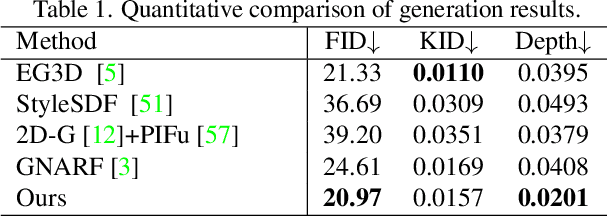
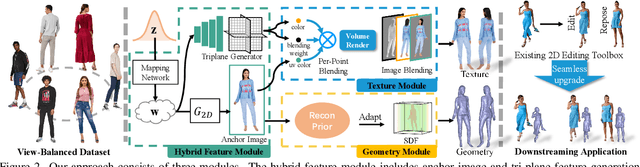
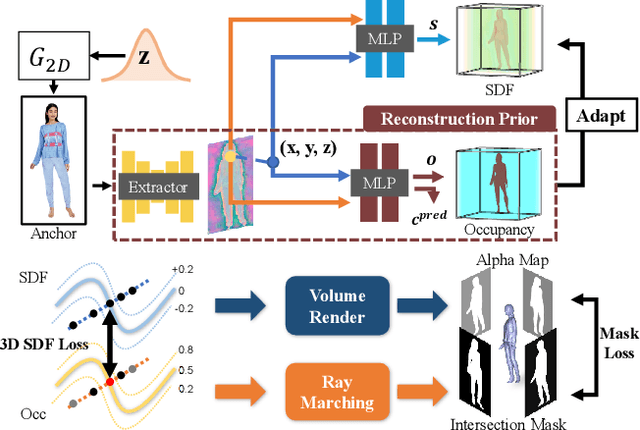
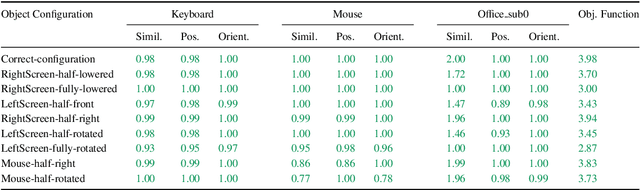
Recent years have witnessed the tremendous progress of 3D GANs for generating view-consistent radiance fields with photo-realism. Yet, high-quality generation of human radiance fields remains challenging, partially due to the limited human-related priors adopted in existing methods. We present HumanGen, a novel 3D human generation scheme with detailed geometry and $\text{360}^{\circ}$ realistic free-view rendering. It explicitly marries the 3D human generation with various priors from the 2D generator and 3D reconstructor of humans through the design of "anchor image". We introduce a hybrid feature representation using the anchor image to bridge the latent space of HumanGen with the existing 2D generator. We then adopt a pronged design to disentangle the generation of geometry and appearance. With the aid of the anchor image, we adapt a 3D reconstructor for fine-grained details synthesis and propose a two-stage blending scheme to boost appearance generation. Extensive experiments demonstrate our effectiveness for state-of-the-art 3D human generation regarding geometry details, texture quality, and free-view performance. Notably, HumanGen can also incorporate various off-the-shelf 2D latent editing methods, seamlessly lifting them into 3D.
Saliency-Augmented Memory Completion for Continual Learning
Dec 26, 2022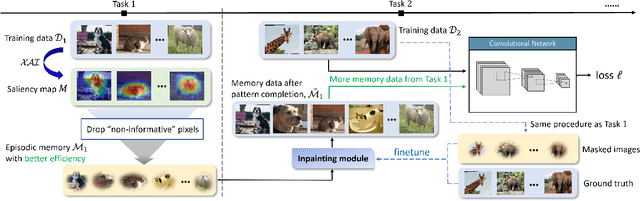
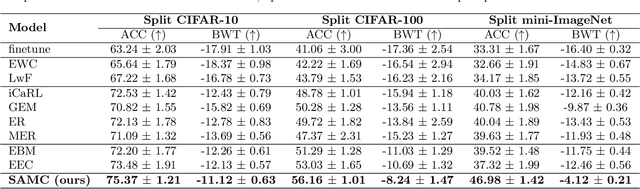


Continual Learning is considered a key step toward next-generation Artificial Intelligence. Among various methods, replay-based approaches that maintain and replay a small episodic memory of previous samples are one of the most successful strategies against catastrophic forgetting. However, since forgetting is inevitable given bounded memory and unbounded tasks, how to forget is a problem continual learning must address. Therefore, beyond simply avoiding catastrophic forgetting, an under-explored issue is how to reasonably forget while ensuring the merits of human memory, including 1. storage efficiency, 2. generalizability, and 3. some interpretability. To achieve these simultaneously, our paper proposes a new saliency-augmented memory completion framework for continual learning, inspired by recent discoveries in memory completion separation in cognitive neuroscience. Specifically, we innovatively propose to store the part of the image most important to the tasks in episodic memory by saliency map extraction and memory encoding. When learning new tasks, previous data from memory are inpainted by an adaptive data generation module, which is inspired by how humans complete episodic memory. The module's parameters are shared across all tasks and it can be jointly trained with a continual learning classifier as bilevel optimization. Extensive experiments on several continual learning and image classification benchmarks demonstrate the proposed method's effectiveness and efficiency.
DeepCut: Unsupervised Segmentation using Graph Neural Networks Clustering
Dec 12, 2022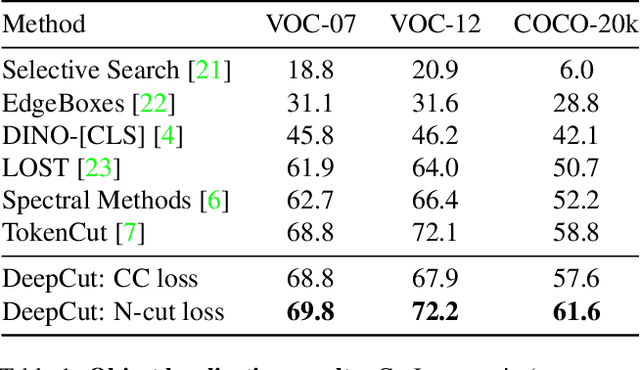
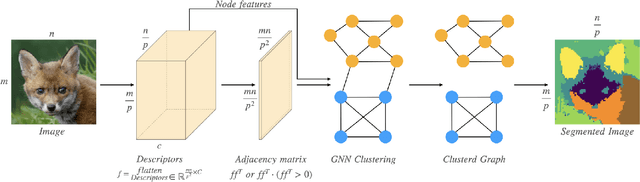
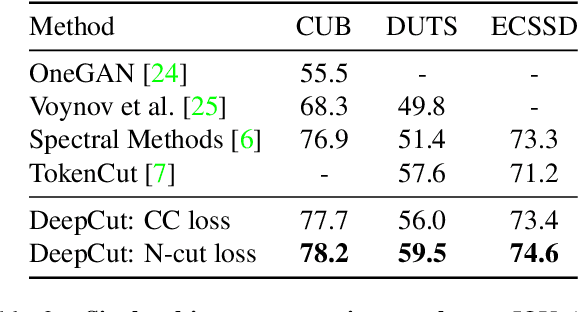

Image segmentation is a fundamental task in computer vision. Data annotation for training supervised methods can be labor-intensive, motivating unsupervised methods. Some existing approaches extract deep features from pre-trained networks and build a graph to apply classical clustering methods (e.g., $k$-means and normalized-cuts) as a post-processing stage. These techniques reduce the high-dimensional information encoded in the features to pair-wise scalar affinities. In this work, we replace classical clustering algorithms with a lightweight Graph Neural Network (GNN) trained to achieve the same clustering objective function. However, in contrast to existing approaches, we feed the GNN not only the pair-wise affinities between local image features but also the raw features themselves. Maintaining this connection between the raw feature and the clustering goal allows to perform part semantic segmentation implicitly, without requiring additional post-processing steps. We demonstrate how classical clustering objectives can be formulated as self-supervised loss functions for training our image segmentation GNN. Additionally, we use the Correlation-Clustering (CC) objective to perform clustering without defining the number of clusters ($k$-less clustering). We apply the proposed method for object localization, segmentation, and semantic part segmentation tasks, surpassing state-of-the-art performance on multiple benchmarks.
Structural Prior Guided Generative Adversarial Transformers for Low-Light Image Enhancement
Jul 19, 2022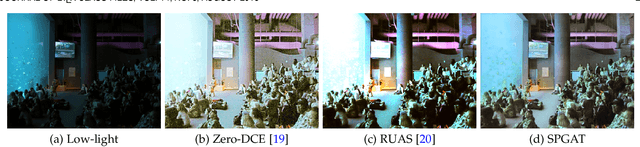
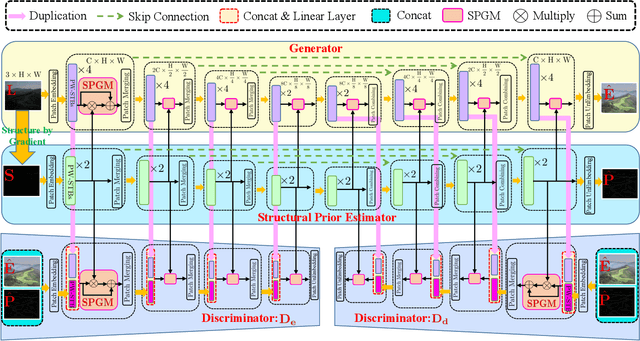


We propose an effective Structural Prior guided Generative Adversarial Transformer (SPGAT) to solve low-light image enhancement. Our SPGAT mainly contains a generator with two discriminators and a structural prior estimator (SPE). The generator is based on a U-shaped Transformer which is used to explore non-local information for better clear image restoration. The SPE is used to explore useful structures from images to guide the generator for better structural detail estimation. To generate more realistic images, we develop a new structural prior guided adversarial learning method by building the skip connections between the generator and discriminators so that the discriminators can better discriminate between real and fake features. Finally, we propose a parallel windows-based Swin Transformer block to aggregate different level hierarchical features for high-quality image restoration. Experimental results demonstrate that the proposed SPGAT performs favorably against recent state-of-the-art methods on both synthetic and real-world datasets.
Privacy-Preserving Image Classification Using Vision Transformer
May 24, 2022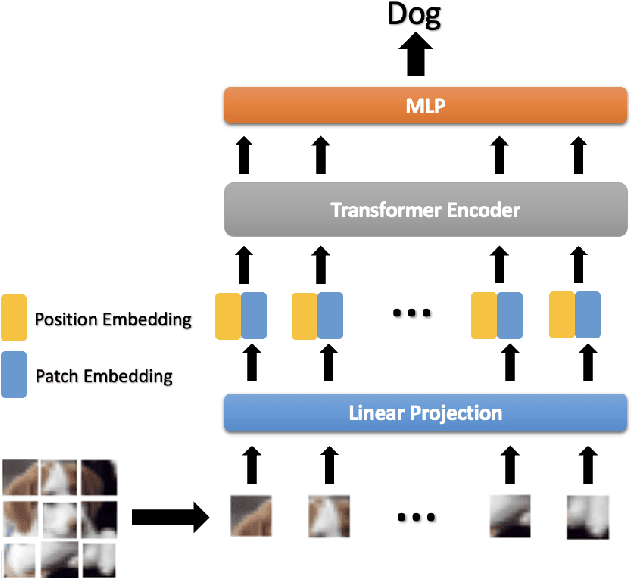
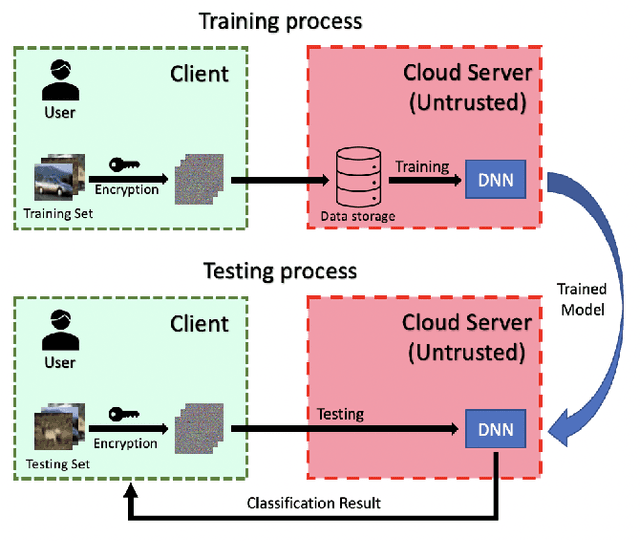


In this paper, we propose a privacy-preserving image classification method that is based on the combined use of encrypted images and the vision transformer (ViT). The proposed method allows us not only to apply images without visual information to ViT models for both training and testing but to also maintain a high classification accuracy. ViT utilizes patch embedding and position embedding for image patches, so this architecture is shown to reduce the influence of block-wise image transformation. In an experiment, the proposed method for privacy-preserving image classification is demonstrated to outperform state-of-the-art methods in terms of classification accuracy and robustness against various attacks.