 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Knowing Your Nonlinearities: Shapley Interactions Reveal the Underlying Structure of Data
Mar 19, 2024
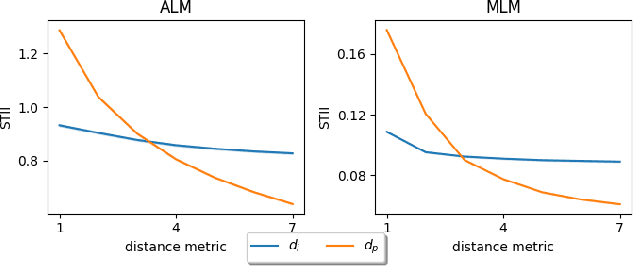
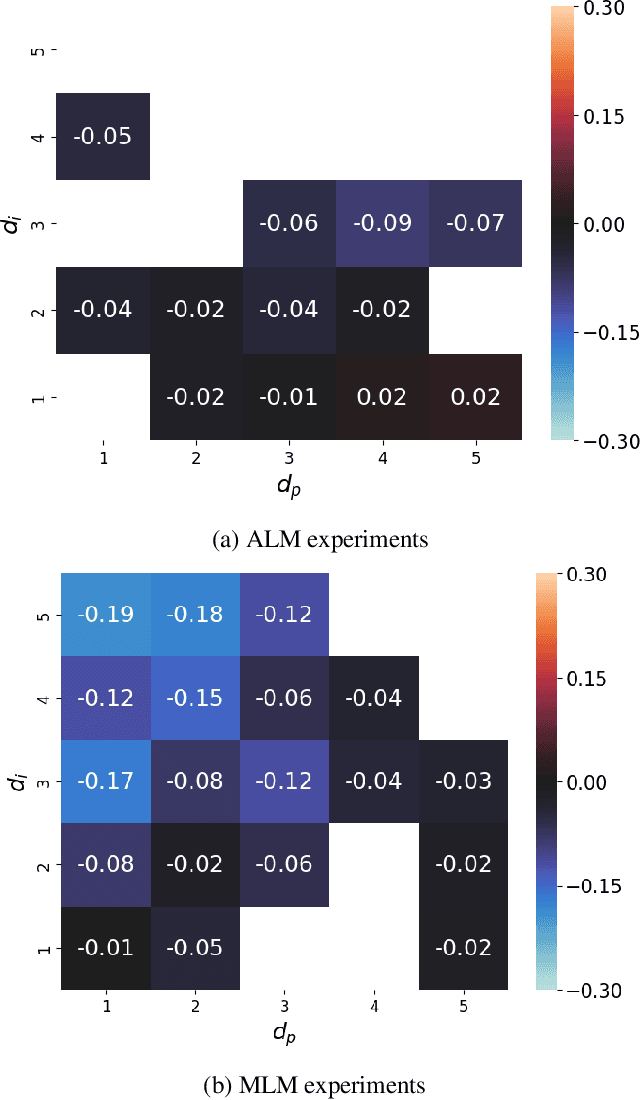
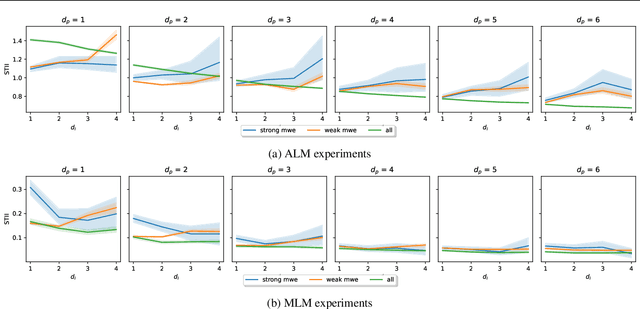
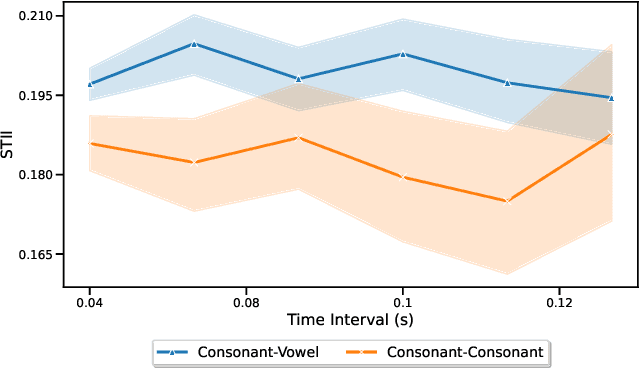
Measuring nonlinear feature interaction is an established approach to understanding complex patterns of attribution in many models. In this paper, we use Shapley Taylor interaction indices (STII) to analyze the impact of underlying data structure on model representations in a variety of modalities, tasks, and architectures. Considering linguistic structure in masked and auto-regressive language models (MLMs and ALMs), we find that STII increases within idiomatic expressions and that MLMs scale STII with syntactic distance, relying more on syntax in their nonlinear structure than ALMs do. Our speech model findings reflect the phonetic principal that the openness of the oral cavity determines how much a phoneme varies based on its context. Finally, we study image classifiers and illustrate that feature interactions intuitively reflect object boundaries. Our wide range of results illustrates the benefits of interdisciplinary work and domain expertise in interpretability research.
Few-shot Object Localization
Mar 19, 2024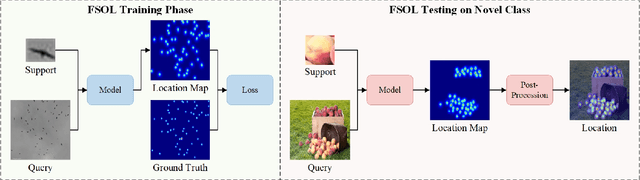
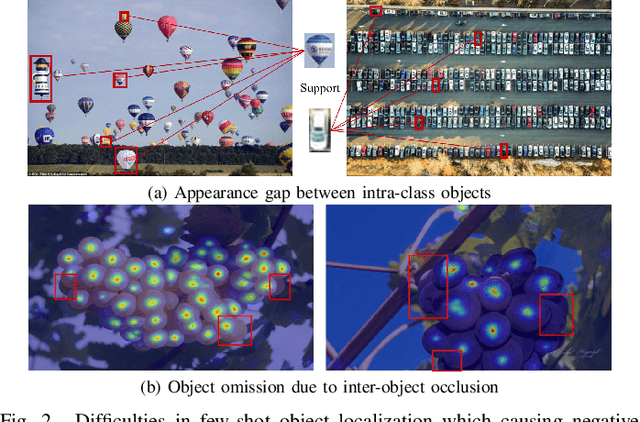
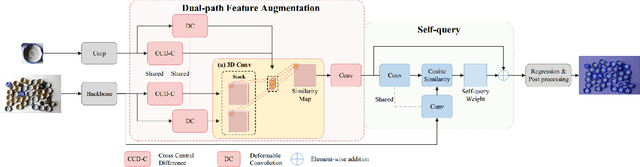

Existing few-shot object counting tasks primarily focus on quantifying the number of objects in an image, neglecting precise positional information. To bridge this research gap, this paper introduces the novel task of Few-Shot Object Localization (FSOL), which aims to provide accurate object positional information. This task achieves generalized object localization by leveraging a small number of labeled support samples to query the positional information of objects within corresponding images. To advance this research field, we propose an innovative high-performance baseline model. Our model integrates a dual-path feature augmentation module to enhance shape association and gradient differences between supports and query images, alongside a self-query module designed to explore the association between feature maps and query images. Experimental results demonstrate a significant performance improvement of our approach in the FSOL task, establishing an efficient benchmark for further research.
TT-BLIP: Enhancing Fake News Detection Using BLIP and Tri-Transformer
Mar 19, 2024
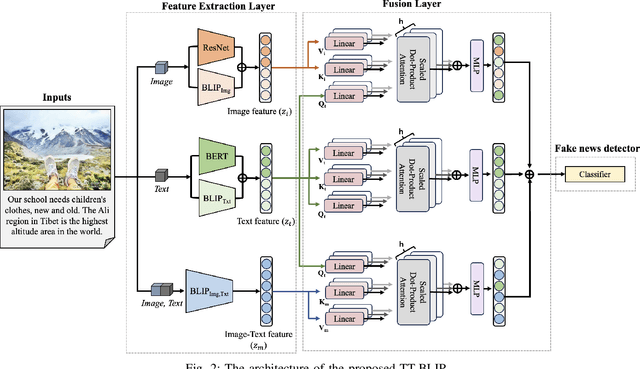
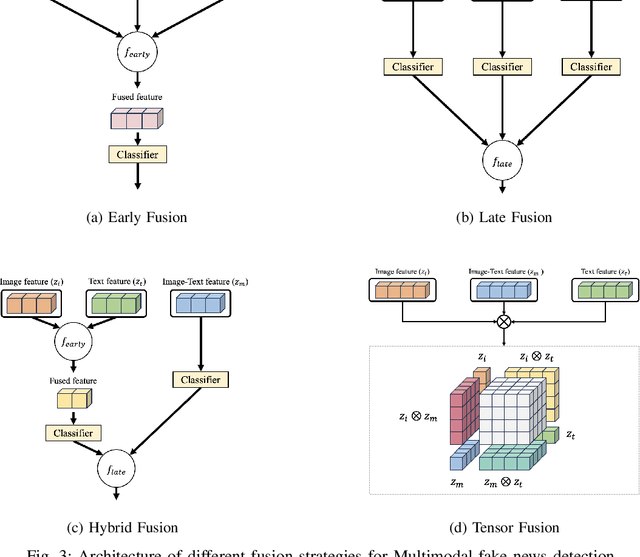

Detecting fake news has received a lot of attention. Many previous methods concatenate independently encoded unimodal data, ignoring the benefits of integrated multimodal information. Also, the absence of specialized feature extraction for text and images further limits these methods. This paper introduces an end-to-end model called TT-BLIP that applies the bootstrapping language-image pretraining for unified vision-language understanding and generation (BLIP) for three types of information: BERT and BLIP\textsubscript{Txt} for text, ResNet and BLIP\textsubscript{Img} for images, and bidirectional BLIP encoders for multimodal information. The Multimodal Tri-Transformer fuses tri-modal features using three types of multi-head attention mechanisms, ensuring integrated modalities for enhanced representations and improved multimodal data analysis. The experiments are performed using two fake news datasets, Weibo and Gossipcop. The results indicate TT-BLIP outperforms the state-of-the-art models.
StreamMultiDiffusion: Real-Time Interactive Generation with Region-Based Semantic Control
Mar 14, 2024



The enormous success of diffusion models in text-to-image synthesis has made them promising candidates for the next generation of end-user applications for image generation and editing. Previous works have focused on improving the usability of diffusion models by reducing the inference time or increasing user interactivity by allowing new, fine-grained controls such as region-based text prompts. However, we empirically find that integrating both branches of works is nontrivial, limiting the potential of diffusion models. To solve this incompatibility, we present StreamMultiDiffusion, the first real-time region-based text-to-image generation framework. By stabilizing fast inference techniques and restructuring the model into a newly proposed multi-prompt stream batch architecture, we achieve $\times 10$ faster panorama generation than existing solutions, and the generation speed of 1.57 FPS in region-based text-to-image synthesis on a single RTX 2080 Ti GPU. Our solution opens up a new paradigm for interactive image generation named semantic palette, where high-quality images are generated in real-time from given multiple hand-drawn regions, encoding prescribed semantic meanings (e.g., eagle, girl). Our code and demo application are available at https://github.com/ironjr/StreamMultiDiffusion.
A survey of synthetic data augmentation methods in computer vision
Mar 18, 2024The standard approach to tackling computer vision problems is to train deep convolutional neural network (CNN) models using large-scale image datasets which are representative of the target task. However, in many scenarios, it is often challenging to obtain sufficient image data for the target task. Data augmentation is a way to mitigate this challenge. A common practice is to explicitly transform existing images in desired ways so as to create the required volume and variability of training data necessary to achieve good generalization performance. In situations where data for the target domain is not accessible, a viable workaround is to synthesize training data from scratch--i.e., synthetic data augmentation. This paper presents an extensive review of synthetic data augmentation techniques. It covers data synthesis approaches based on realistic 3D graphics modeling, neural style transfer (NST), differential neural rendering, and generative artificial intelligence (AI) techniques such as generative adversarial networks (GANs) and variational autoencoders (VAEs). For each of these classes of methods, we focus on the important data generation and augmentation techniques, general scope of application and specific use-cases, as well as existing limitations and possible workarounds. Additionally, we provide a summary of common synthetic datasets for training computer vision models, highlighting the main features, application domains and supported tasks. Finally, we discuss the effectiveness of synthetic data augmentation methods. Since this is the first paper to explore synthetic data augmentation methods in great detail, we are hoping to equip readers with the necessary background information and in-depth knowledge of existing methods and their attendant issues.
AI-Assisted Cervical Cancer Screening
Mar 18, 2024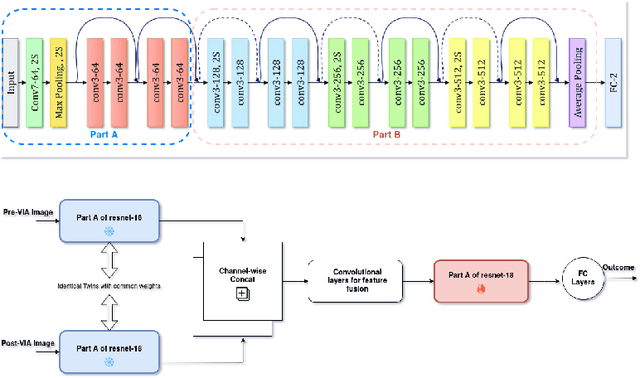

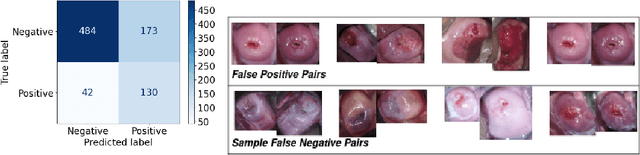
Visual Inspection with Acetic Acid (VIA) remains the most feasible cervical cancer screening test in resource-constrained settings of low- and middle-income countries (LMICs), which are often performed screening camps or primary/community health centers by nurses instead of the preferred but unavailable expert Gynecologist. To address the highly subjective nature of the test, various handheld devices integrating cameras or smartphones have been recently explored to capture cervical images during VIA and aid decision-making via telemedicine or AI models. Most studies proposing AI models retrospectively use a relatively small number of already collected images from specific devices, digital cameras, or smartphones; the challenges and protocol for quality image acquisition during VIA in resource-constrained camp settings, challenges in getting gold standard, data imbalance, etc. are often overlooked. We present a novel approach and describe the end-to-end design process to build a robust smartphone-based AI-assisted system that does not require buying a separate integrated device: the proposed protocol for quality image acquisition in resource-constrained settings, dataset collected from 1,430 women during VIA performed by nurses in screening camps, preprocessing pipeline, and training and evaluation of a deep-learning-based classification model aimed to identify (pre)cancerous lesions. Our work shows that the readily available smartphones and a suitable protocol can capture the cervix images with the required details for the VIA test well; the deep-learning-based classification model provides promising results to assist nurses in VIA screening; and provides a direction for large-scale data collection and validation in resource-constrained settings.
IDF-CR: Iterative Diffusion Process for Divide-and-Conquer Cloud Removal in Remote-sensing Images
Mar 18, 2024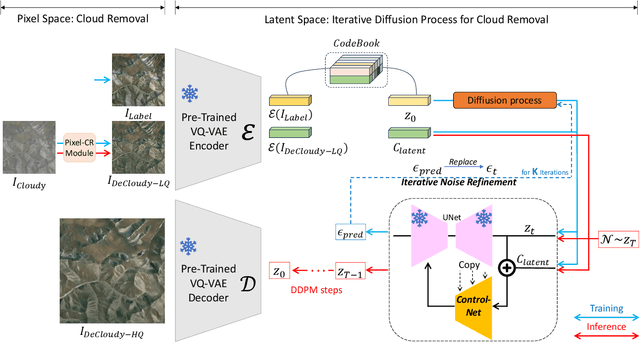
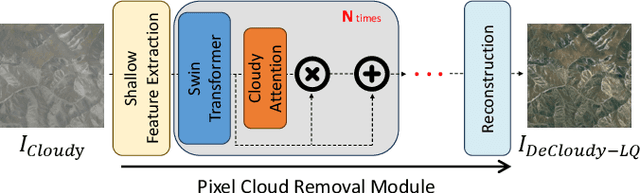
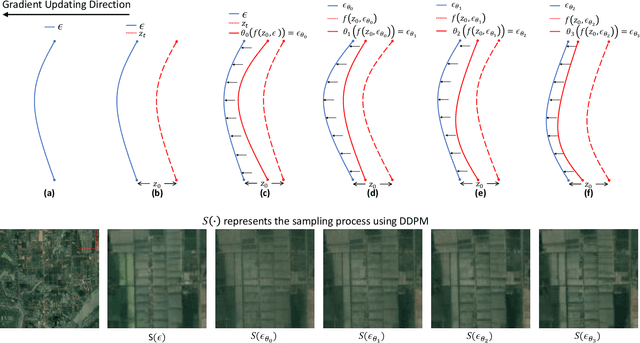

Deep learning technologies have demonstrated their effectiveness in removing cloud cover from optical remote-sensing images. Convolutional Neural Networks (CNNs) exert dominance in the cloud removal tasks. However, constrained by the inherent limitations of convolutional operations, CNNs can address only a modest fraction of cloud occlusion. In recent years, diffusion models have achieved state-of-the-art (SOTA) proficiency in image generation and reconstruction due to their formidable generative capabilities. Inspired by the rapid development of diffusion models, we first present an iterative diffusion process for cloud removal (IDF-CR), which exhibits a strong generative capabilities to achieve component divide-and-conquer cloud removal. IDF-CR consists of a pixel space cloud removal module (Pixel-CR) and a latent space iterative noise diffusion network (IND). Specifically, IDF-CR is divided into two-stage models that address pixel space and latent space. The two-stage model facilitates a strategic transition from preliminary cloud reduction to meticulous detail refinement. In the pixel space stage, Pixel-CR initiates the processing of cloudy images, yielding a suboptimal cloud removal prior to providing the diffusion model with prior cloud removal knowledge. In the latent space stage, the diffusion model transforms low-quality cloud removal into high-quality clean output. We refine the Stable Diffusion by implementing ControlNet. In addition, an unsupervised iterative noise refinement (INR) module is introduced for diffusion model to optimize the distribution of the predicted noise, thereby enhancing advanced detail recovery. Our model performs best with other SOTA methods, including image reconstruction and optical remote-sensing cloud removal on the optical remote-sensing datasets.
Controllable Generation with Text-to-Image Diffusion Models: A Survey
Mar 07, 2024
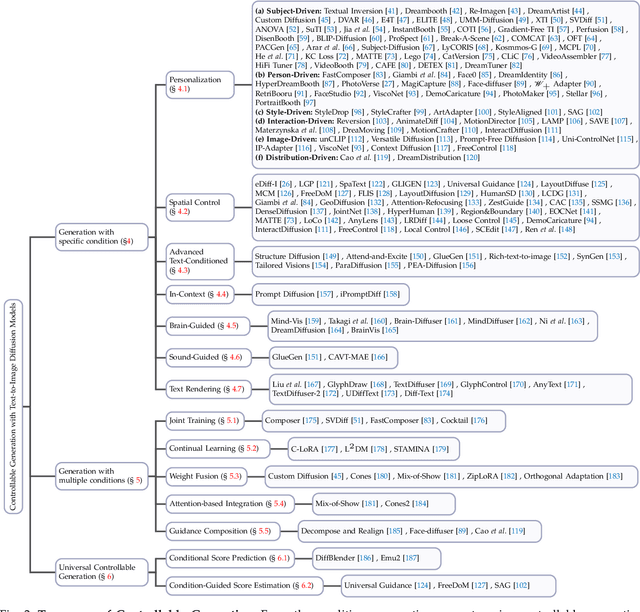
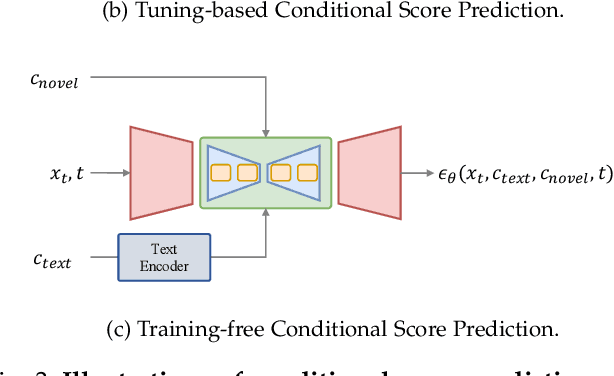
In the rapidly advancing realm of visual generation, diffusion models have revolutionized the landscape, marking a significant shift in capabilities with their impressive text-guided generative functions. However, relying solely on text for conditioning these models does not fully cater to the varied and complex requirements of different applications and scenarios. Acknowledging this shortfall, a variety of studies aim to control pre-trained text-to-image (T2I) models to support novel conditions. In this survey, we undertake a thorough review of the literature on controllable generation with T2I diffusion models, covering both the theoretical foundations and practical advancements in this domain. Our review begins with a brief introduction to the basics of denoising diffusion probabilistic models (DDPMs) and widely used T2I diffusion models. We then reveal the controlling mechanisms of diffusion models, theoretically analyzing how novel conditions are introduced into the denoising process for conditional generation. Additionally, we offer a detailed overview of research in this area, organizing it into distinct categories from the condition perspective: generation with specific conditions, generation with multiple conditions, and universal controllable generation. For an exhaustive list of the controllable generation literature surveyed, please refer to our curated repository at \url{https://github.com/PRIV-Creation/Awesome-Controllable-T2I-Diffusion-Models}.
PromptIQA: Boosting the Performance and Generalization for No-Reference Image Quality Assessment via Prompts
Mar 08, 2024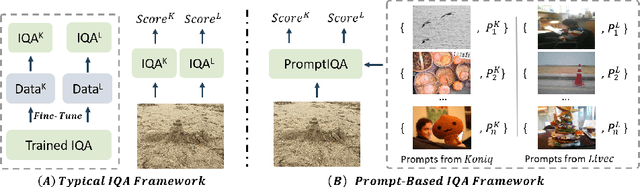
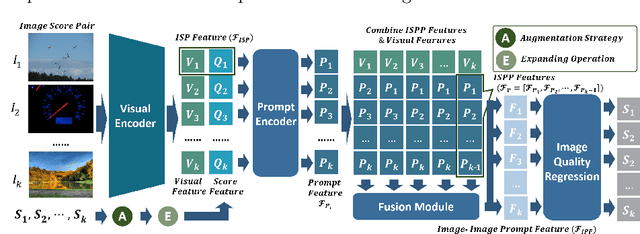
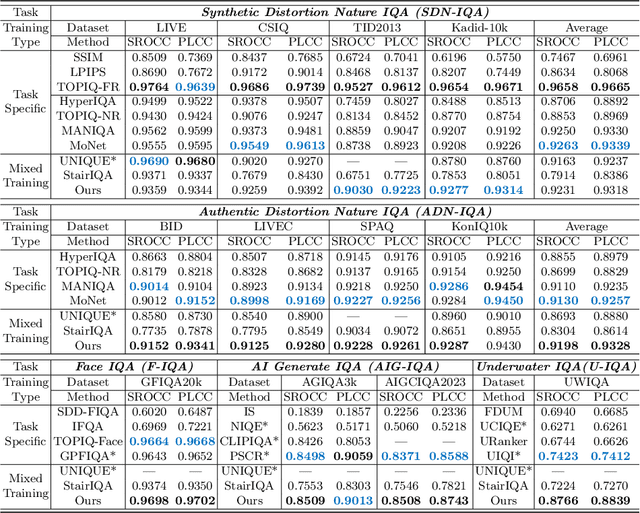
Due to the diversity of assessment requirements in various application scenarios for the IQA task, existing IQA methods struggle to directly adapt to these varied requirements after training. Thus, when facing new requirements, a typical approach is fine-tuning these models on datasets specifically created for those requirements. However, it is time-consuming to establish IQA datasets. In this work, we propose a Prompt-based IQA (PromptIQA) that can directly adapt to new requirements without fine-tuning after training. On one hand, it utilizes a short sequence of Image-Score Pairs (ISP) as prompts for targeted predictions, which significantly reduces the dependency on the data requirements. On the other hand, PromptIQA is trained on a mixed dataset with two proposed data augmentation strategies to learn diverse requirements, thus enabling it to effectively adapt to new requirements. Experiments indicate that the PromptIQA outperforms SOTA methods with higher performance and better generalization. The code will be available.
Ensembling and Test Augmentation for Covid-19 Detection and Covid-19 Domain Adaptation from 3D CT-Scans
Mar 17, 2024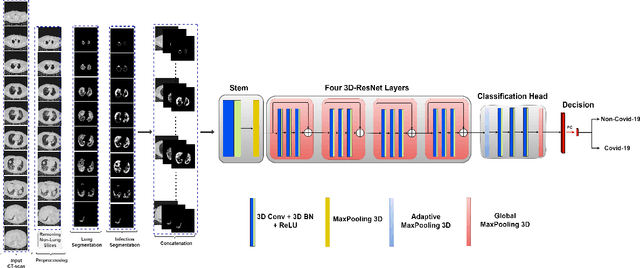



Since the emergence of Covid-19 in late 2019, medical image analysis using artificial intelligence (AI) has emerged as a crucial research area, particularly with the utility of CT-scan imaging for disease diagnosis. This paper contributes to the 4th COV19D competition, focusing on Covid-19 Detection and Covid-19 Domain Adaptation Challenges. Our approach centers on lung segmentation and Covid-19 infection segmentation employing the recent CNN-based segmentation architecture PDAtt-Unet, which simultaneously segments lung regions and infections. Departing from traditional methods, we concatenate the input slice (grayscale) with segmented lung and infection, generating three input channels akin to color channels. Additionally, we employ three 3D CNN backbones Customized Hybrid-DeCoVNet, along with pretrained 3D-Resnet-18 and 3D-Resnet-50 models to train Covid-19 recognition for both challenges. Furthermore, we explore ensemble approaches and testing augmentation to enhance performance. Comparison with baseline results underscores the substantial efficiency of our approach, with a significant margin in terms of F1-score (14 %). This study advances the field by presenting a comprehensive methodology for accurate Covid-19 detection and adaptation, leveraging cutting-edge AI techniques in medical image analysis.