 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
MEW-UNet: Multi-axis representation learning in frequency domain for medical image segmentation
Oct 25, 2022
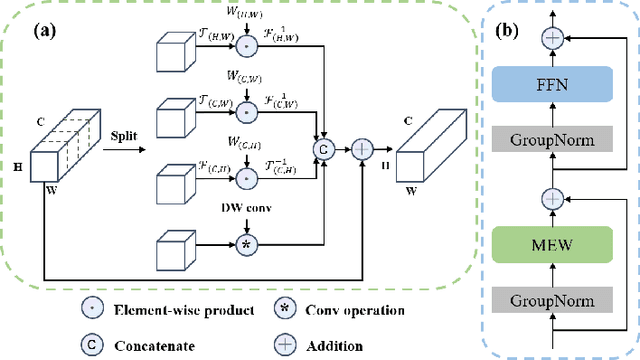
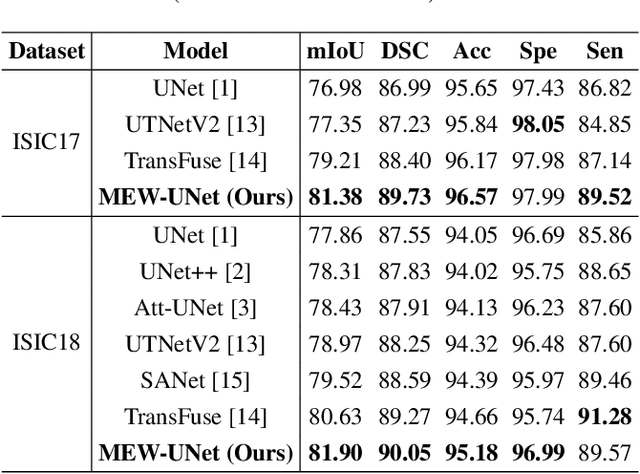
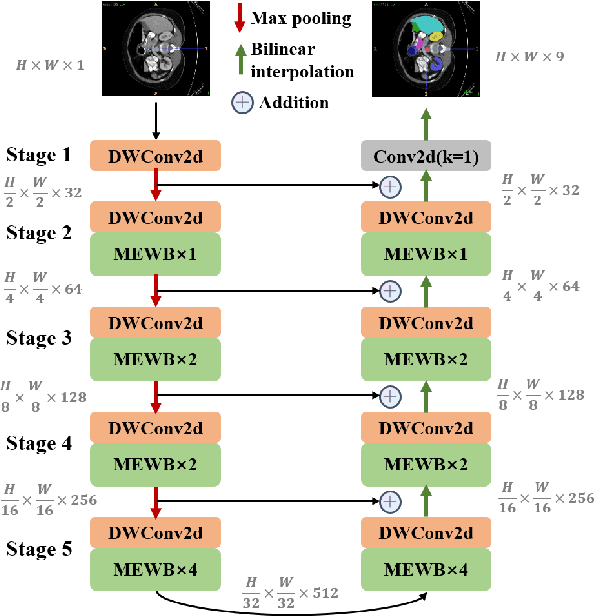
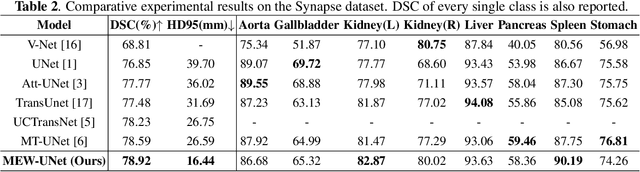
Recently, Visual Transformer (ViT) has been widely used in various fields of computer vision due to applying self-attention mechanism in the spatial domain to modeling global knowledge. Especially in medical image segmentation (MIS), many works are devoted to combining ViT and CNN, and even some works directly utilize pure ViT-based models. However, recent works improved models in the aspect of spatial domain while ignoring the importance of frequency domain information. Therefore, we propose Multi-axis External Weights UNet (MEW-UNet) for MIS based on the U-shape architecture by replacing self-attention in ViT with our Multi-axis External Weights block. Specifically, our block performs a Fourier transform on the three axes of the input feature and assigns the external weight in the frequency domain, which is generated by our Weights Generator. Then, an inverse Fourier transform is performed to change the features back to the spatial domain. We evaluate our model on four datasets and achieve state-of-the-art performances. In particular, on the Synapse dataset, our method outperforms MT-UNet by 10.15mm in terms of HD95. Code is available at https://github.com/JCruan519/MEW-UNet.
EMV-LIO: An Efficient Multiple Vision aided LiDAR-Inertial Odometry
Feb 01, 2023
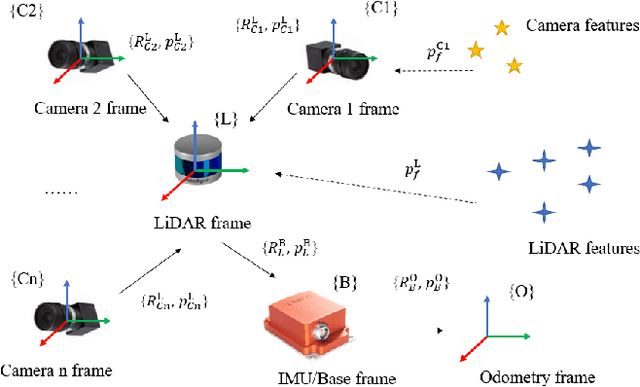
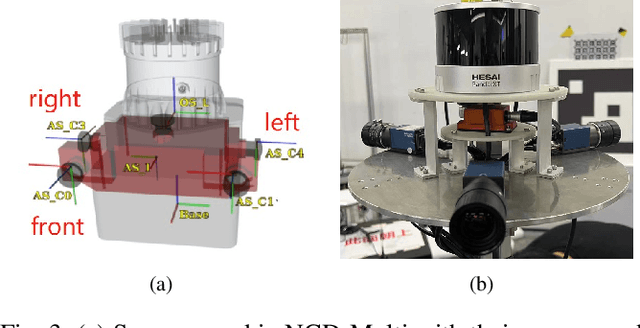

To deal with the degeneration caused by the incomplete constraints of single sensor, multi-sensor fusion strategies especially in LiDAR-vision-inertial fusion area have attracted much interest from both the industry and the research community in recent years. Considering that a monocular camera is vulnerable to the influence of ambient light from a certain direction and fails, which makes the system degrade into a LiDAR-inertial system, multiple cameras are introduced to expand the visual observation so as to improve the accuracy and robustness of the system. Besides, removing LiDAR's noise via range image, setting condition for nearest neighbor search, and replacing kd-Tree with ikd-Tree are also introduced to enhance the efficiency. Based on the above, we propose an Efficient Multiple vision aided LiDAR-inertial odometry system (EMV-LIO), and evaluate its performance on both open datasets and our custom datasets. Experiments show that the algorithm is helpful to improve the accuracy, robustness and efficiency of the whole system compared with LVI-SAM
Normalizing Flow based Feature Synthesis for Outlier-Aware Object Detection
Feb 01, 2023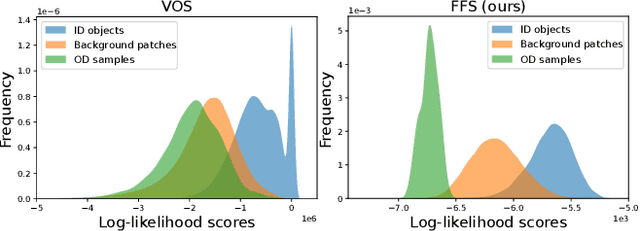
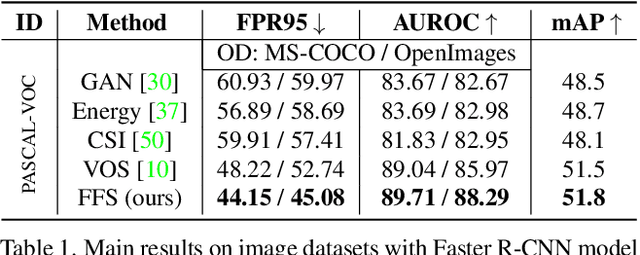
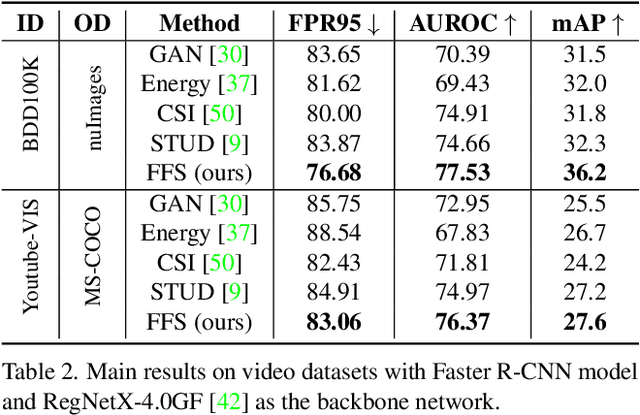
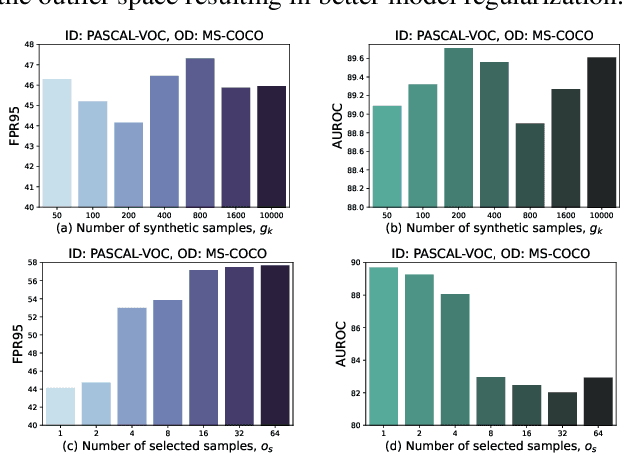
Real-world deployment of reliable object detectors is crucial for applications such as autonomous driving. However, general-purpose object detectors like Faster R-CNN are prone to providing overconfident predictions for outlier objects. Recent outlier-aware object detection approaches estimate the density of instance-wide features with class-conditional Gaussians and train on synthesized outlier features from their low-likelihood regions. However, this strategy does not guarantee that the synthesized outlier features will have a low likelihood according to the other class-conditional Gaussians. We propose a novel outlier-aware object detection framework that learns to distinguish outliers from inlier objects by learning the joint data distribution of all inlier classes with an invertible normalizing flow. The flow model ensures that the synthesized outliers have a lower likelihood than inliers of all object classes, thereby modeling a better decision boundary between inlier and outlier objects. Our approach significantly outperforms the state-of-the-art for outlier-aware object detection on both image and video datasets.
Self-Supervised 2D/3D Registration for X-Ray to CT Image Fusion
Oct 14, 2022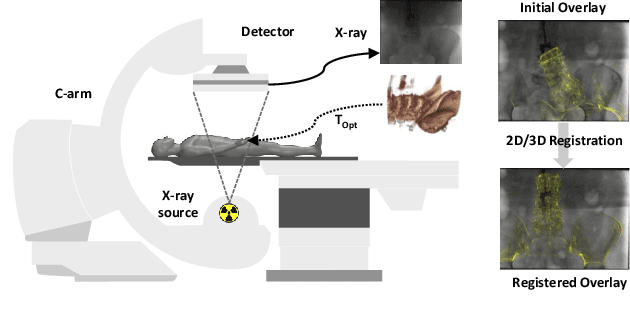

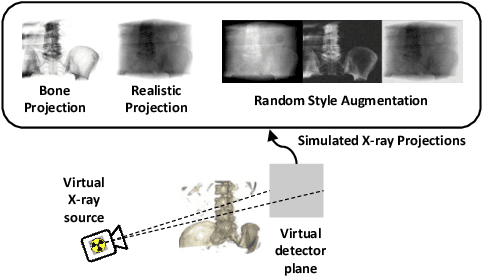

Deep Learning-based 2D/3D registration enables fast, robust, and accurate X-ray to CT image fusion when large annotated paired datasets are available for training. However, the need for paired CT volume and X-ray images with ground truth registration limits the applicability in interventional scenarios. An alternative is to use simulated X-ray projections from CT volumes, thus removing the need for paired annotated datasets. Deep Neural Networks trained exclusively on simulated X-ray projections can perform significantly worse on real X-ray images due to the domain gap. We propose a self-supervised 2D/3D registration framework combining simulated training with unsupervised feature and pixel space domain adaptation to overcome the domain gap and eliminate the need for paired annotated datasets. Our framework achieves a registration accuracy of 1.83$\pm$1.16 mm with a high success ratio of 90.1% on real X-ray images showing a 23.9% increase in success ratio compared to reference annotation-free algorithms.
What does a platypus look like? Generating customized prompts for zero-shot image classification
Sep 07, 2022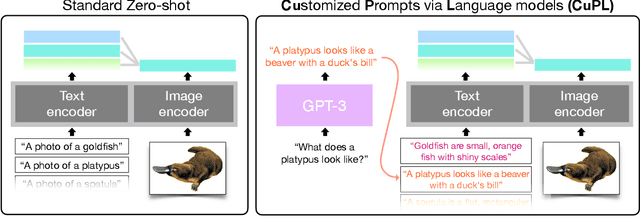
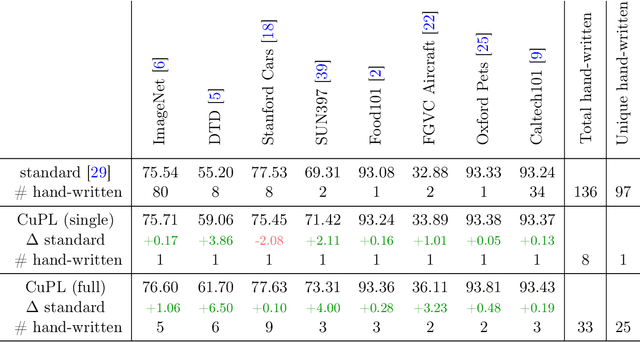
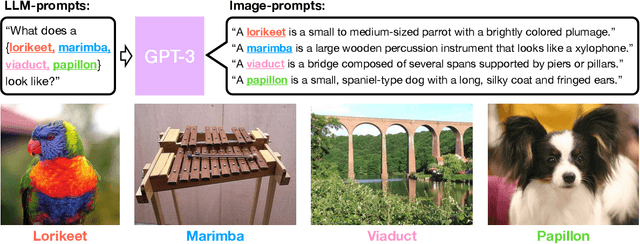
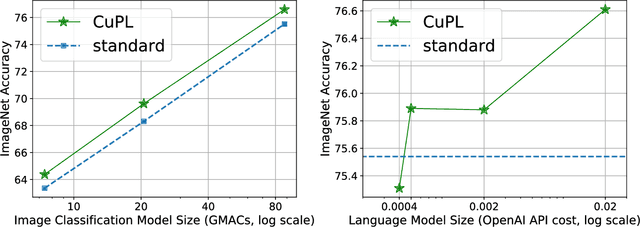
Open vocabulary models are a promising new paradigm for image classification. Unlike traditional classification models, open vocabulary models classify among any arbitrary set of categories specified with natural language during inference. This natural language, called "prompts", typically consists of a set of hand-written templates (e.g., "a photo of a {}") which are completed with each of the category names. This work introduces a simple method to generate higher accuracy prompts, without using explicit knowledge of the image domain and with far fewer hand-constructed sentences. To achieve this, we combine open vocabulary models with large language models (LLMs) to create Customized Prompts via Language models (CuPL, pronounced "couple"). In particular, we leverage the knowledge contained in LLMs in order to generate many descriptive sentences that are customized for each object category. We find that this straightforward and general approach improves accuracy on a range of zero-shot image classification benchmarks, including over one percentage point gain on ImageNet. Finally, this method requires no additional training and remains completely zero-shot. Code is available at https://github.com/sarahpratt/CuPL.
Detection of Malfunctioning Modules in Photovoltaic Power Plants using Unsupervised Feature Clustering Segmentation Algorithm
Dec 30, 2022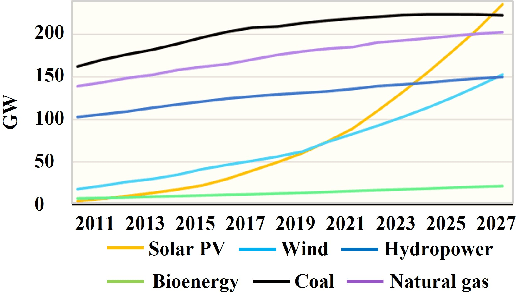

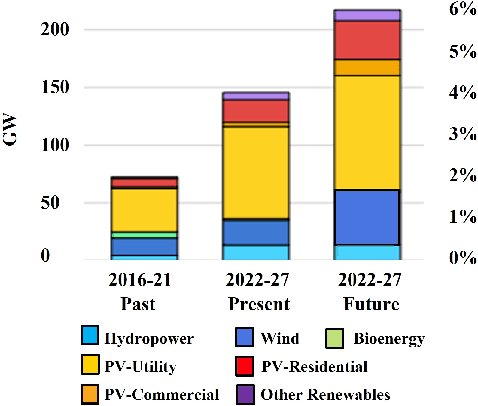

The energy transition towards photovoltaic solar energy has evolved to be a viable and sustainable source for the generation of electricity. It has effectively emerged as an alternative to the conventional mode of electricity generation for developing countries to meet their energy requirement. Thus, many solar power plants have been set up across the globe. However, in these large-scale or remote solar power plants, monitoring and maintenance persist as challenging tasks, mainly identifying faulty or malfunctioning cells in photovoltaic (PV) panels. In this paper, we use an unsupervised deep-learning image segmentation model for the detection of internal faults such as hot spots and snail trails in PV panels. Generally, training or ground truth labels are not available for large solar power plants, thus the proposed model is highly recommended as it does not require any prior learning or training. It extracts the features from the input image and segments out the faults in the image. Here we use infrared thermal images of the PV panel as input, passed to a convolutional neural network which assigns cluster labels to the pixels. Further, optimize the pixel labels, features and model parameters using backpropagation based on iterative stochastic gradient descent. Then, we compute similarity loss and spatial continuity loss to assign the same label to the pixel with similar features and spatial continuity to reduce noises in the image segmentation process. The effectiveness of the proposed approach was examined on an online available dataset for the recognition of snail trails and hot spot failures in monocrystalline solar panels.
WaGI : Wavelet-based GAN Inversion for Preserving High-frequency Image Details
Oct 18, 2022
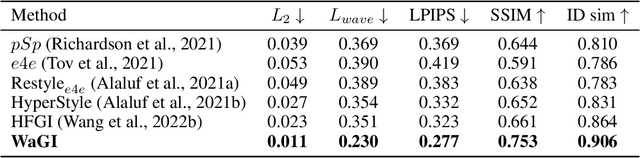
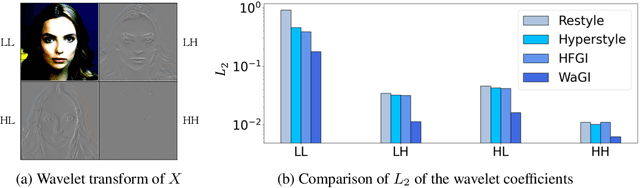

Recent GAN inversion models focus on preserving image-specific details through various methods, e.g., generator tuning or feature mixing. While those are helpful for preserving details compared to a naiive low-rate latent inversion, they still fail to maintain high-frequency features precisely. In this paper, we point out that the existing GAN inversion models have inherent limitations in both structural and training aspects, which preclude the delicate reconstruction of high-frequency features. Especially, we prove that the widely-used loss term in GAN inversion, i.e., L2, is biased to reconstruct low-frequency features mainly. To overcome this problem, we propose a novel GAN inversion model, coined WaGI, which enables to handle high-frequency features explicitly, by using a novel wavelet-based loss term and a newly proposed wavelet fusion scheme. To the best of our knowledge, WaGI is the first attempt to interpret GAN inversion in the frequency domain. We demonstrate that WaGI shows outstanding results on both inversion and editing, compared to the existing state-of-the-art GAN inversion models. Especially, WaGI robustly preserves high-frequency features of images even in the editing scenario. We will release our code with the pre-trained model after the review.
SAR-to-EO Image Translation with Multi-Conditional Adversarial Networks
Jul 26, 2022



This paper explores the use of multi-conditional adversarial networks for SAR-to-EO image translation. Previous methods condition adversarial networks only on the input SAR. We show that incorporating multiple complementary modalities such as Google maps and IR can further improve SAR-to-EO image translation especially on preserving sharp edges of manmade objects. We demonstrate effectiveness of our approach on a diverse set of datasets including SEN12MS, DFC2020, and SpaceNet6. Our experimental results suggest that additional information provided by complementary modalities improves the performance of SAR-to-EO image translation compared to the models trained on paired SAR and EO data only. To best of our knowledge, our approach is the first to leverage multiple modalities for improving SAR-to-EO image translation performance.
Learning End-to-End Channel Coding with Diffusion Models
Feb 03, 2023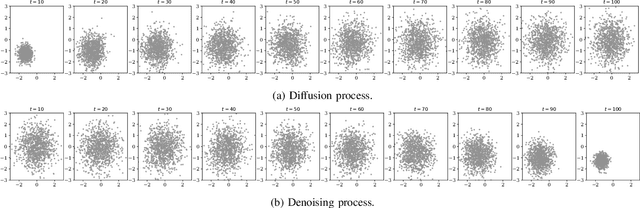
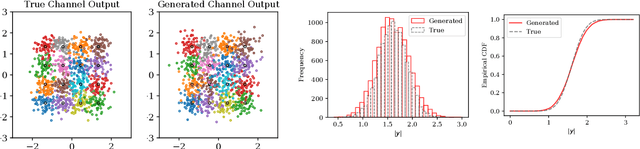
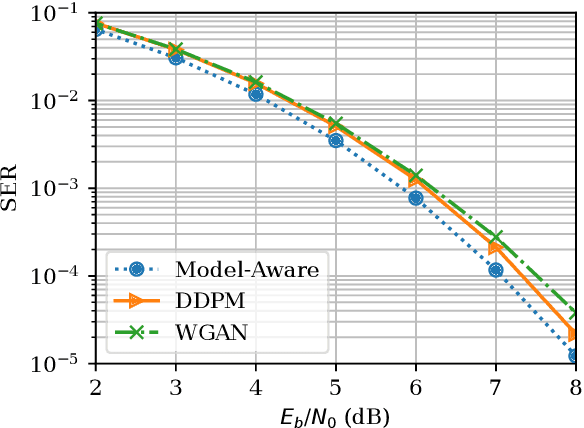
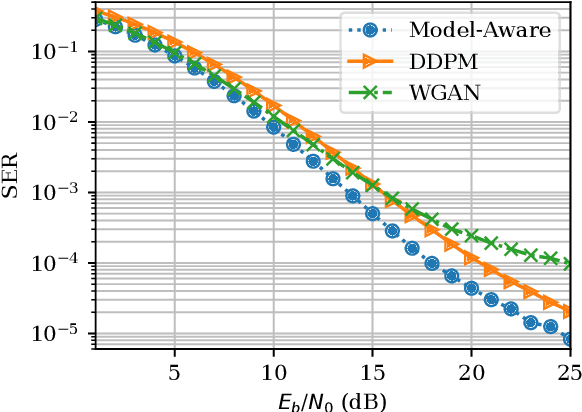
It is a known problem that deep-learning-based end-to-end (E2E) channel coding systems depend on a known and differentiable channel model, due to the learning process and based on the gradient-descent optimization methods. This places the challenge to approximate or generate the channel or its derivative from samples generated by pilot signaling in real-world scenarios. Currently, there are two prevalent methods to solve this problem. One is to generate the channel via a generative adversarial network (GAN), and the other is to, in essence, approximate the gradient via reinforcement learning methods. Other methods include using score-based methods, variational autoencoders, or mutual-information-based methods. In this paper, we focus on generative models and, in particular, on a new promising method called diffusion models, which have shown a higher quality of generation in image-based tasks. We will show that diffusion models can be used in wireless E2E scenarios and that they work as good as Wasserstein GANs while having a more stable training procedure and a better generalization ability in testing.
Zero-Shot Robot Manipulation from Passive Human Videos
Feb 03, 2023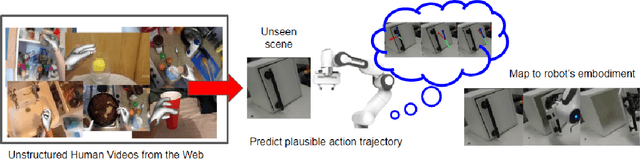

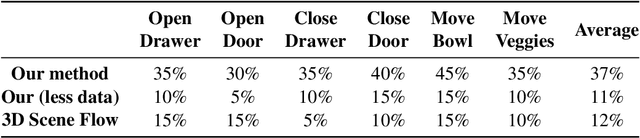

Can we learn robot manipulation for everyday tasks, only by watching videos of humans doing arbitrary tasks in different unstructured settings? Unlike widely adopted strategies of learning task-specific behaviors or direct imitation of a human video, we develop a a framework for extracting agent-agnostic action representations from human videos, and then map it to the agent's embodiment during deployment. Our framework is based on predicting plausible human hand trajectories given an initial image of a scene. After training this prediction model on a diverse set of human videos from the internet, we deploy the trained model zero-shot for physical robot manipulation tasks, after appropriate transformations to the robot's embodiment. This simple strategy lets us solve coarse manipulation tasks like opening and closing drawers, pushing, and tool use, without access to any in-domain robot manipulation trajectories. Our real-world deployment results establish a strong baseline for action prediction information that can be acquired from diverse arbitrary videos of human activities, and be useful for zero-shot robotic manipulation in unseen scenes.