 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Star-Shaped Denoising Diffusion Probabilistic Models
Feb 10, 2023
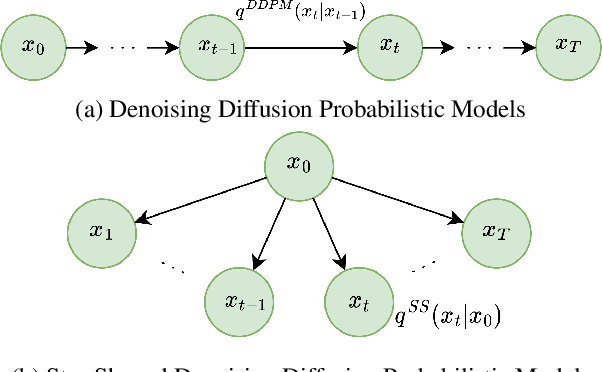
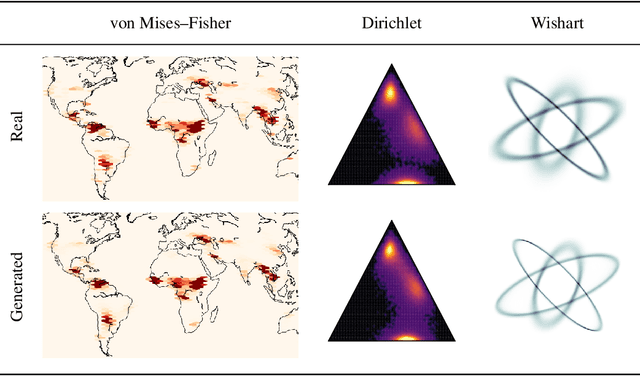
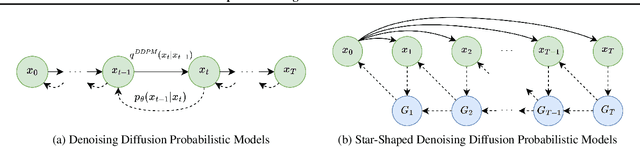
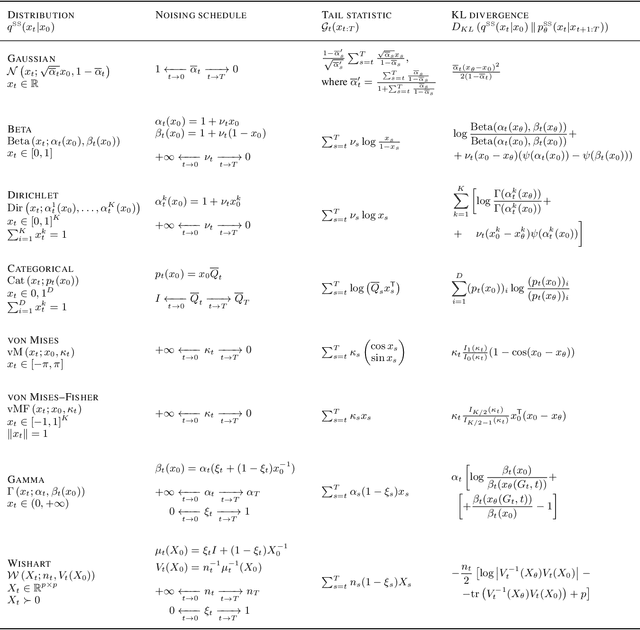
Methods based on Denoising Diffusion Probabilistic Models (DDPM) became a ubiquitous tool in generative modeling. However, they are mostly limited to Gaussian and discrete diffusion processes. We propose Star-Shaped Denoising Diffusion Probabilistic Models (SS-DDPM), a model with a non-Markovian diffusion-like noising process. In the case of Gaussian distributions, this model is equivalent to Markovian DDPMs. However, it can be defined and applied with arbitrary noising distributions, and admits efficient training and sampling algorithms for a wide range of distributions that lie in the exponential family. We provide a simple recipe for designing diffusion-like models with distributions like Beta, von Mises--Fisher, Dirichlet, Wishart and others, which can be especially useful when data lies on a constrained manifold such as the unit sphere, the space of positive semi-definite matrices, the probabilistic simplex, etc. We evaluate the model in different settings and find it competitive even on image data, where Beta SS-DDPM achieves results comparable to a Gaussian DDPM.
Artistic Arbitrary Style Transfer
Dec 21, 2022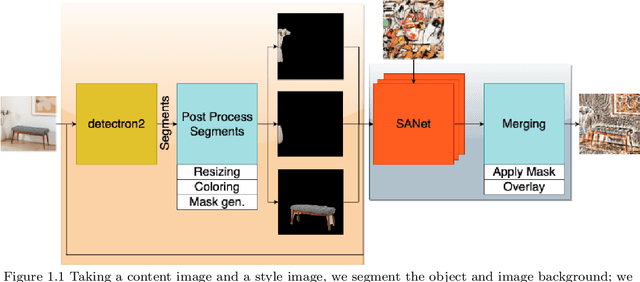

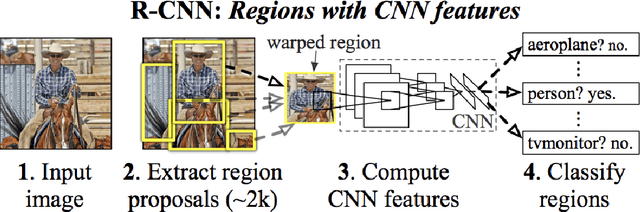

Arbitrary Style Transfer is a technique used to produce a new image from two images: a content image, and a style image. The newly produced image is unseen and is generated from the algorithm itself. Balancing the structure and style components has been the major challenge that other state-of-the-art algorithms have tried to solve. Despite all the efforts, it's still a major challenge to apply the artistic style that was originally created on top of the structure of the content image while maintaining consistency. In this work, we solved these problems by using a Deep Learning approach using Convolutional Neural Networks. Our implementation will first extract foreground from the background using the pre-trained Detectron 2 model from the content image, and then apply the Arbitrary Style Transfer technique that is used in SANet. Once we have the two styled images, we will stitch the two chunks of images after the process of style transfer for the complete end piece.
PLMCL: Partial-Label Momentum Curriculum Learning for Multi-Label Image Classification
Aug 22, 2022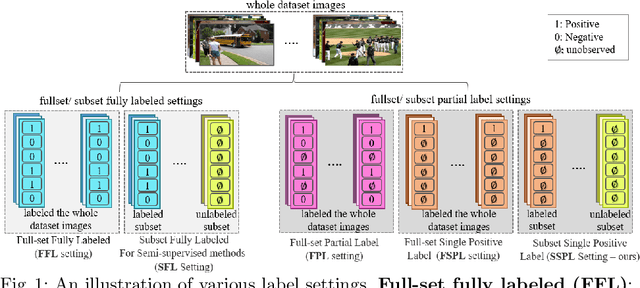
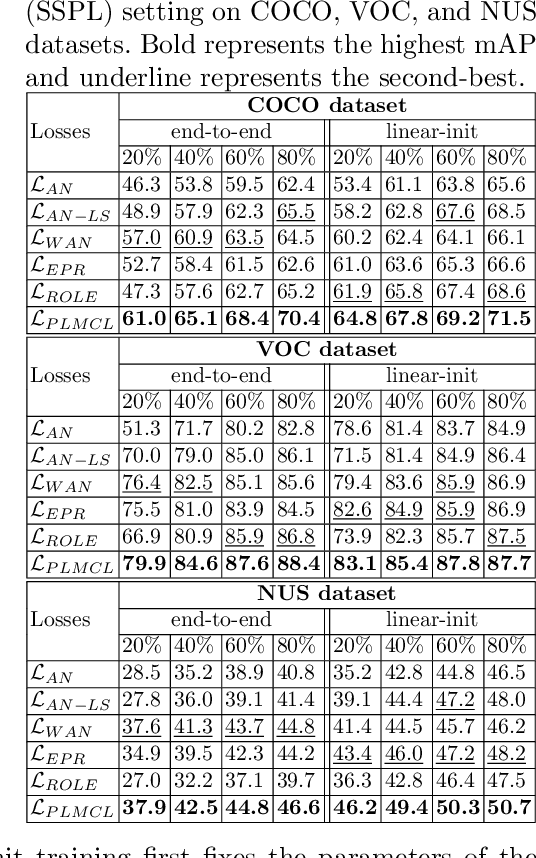
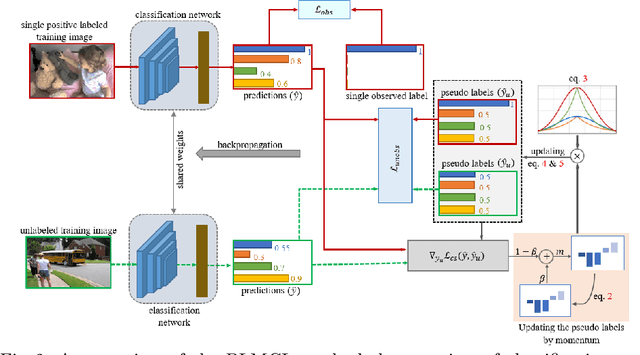

Multi-label image classification aims to predict all possible labels in an image. It is usually formulated as a partial-label learning problem, given the fact that it could be expensive in practice to annotate all labels in every training image. Existing works on partial-label learning focus on the case where each training image is annotated with only a subset of its labels. A special case is to annotate only one positive label in each training image. To further relieve the annotation burden and enhance the performance of the classifier, this paper proposes a new partial-label setting in which only a subset of the training images are labeled, each with only one positive label, while the rest of the training images remain unlabeled. To handle this new setting, we propose an end-to-end deep network, PLMCL (Partial Label Momentum Curriculum Learning), that can learn to produce confident pseudo labels for both partially-labeled and unlabeled training images. The novel momentum-based law updates soft pseudo labels on each training image with the consideration of the updating velocity of pseudo labels, which help avoid trapping to low-confidence local minimum, especially at the early stage of training in lack of both observed labels and confidence on pseudo labels. In addition, we present a confidence-aware scheduler to adaptively perform easy-to-hard learning for different labels. Extensive experiments demonstrate that our proposed PLMCL outperforms many state-of-the-art multi-label classification methods under various partial-label settings on three different datasets.
Pseudo Label-Guided Model Inversion Attack via Conditional Generative Adversarial Network
Feb 20, 2023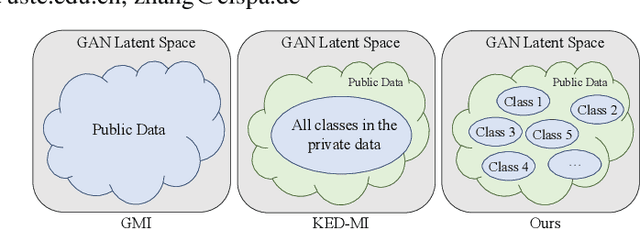

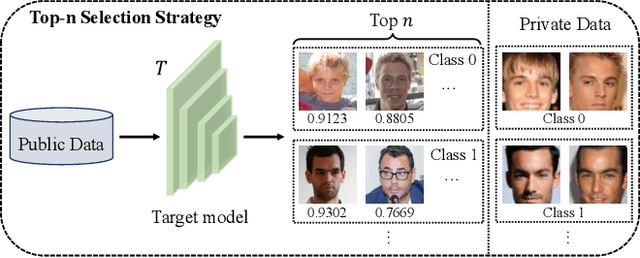
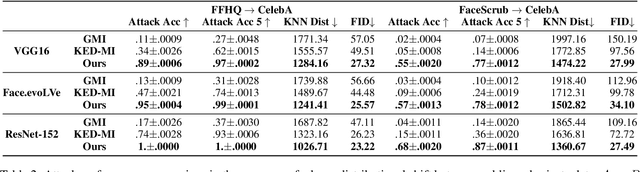
Model inversion (MI) attacks have raised increasing concerns about privacy, which can reconstruct training data from public models. Indeed, MI attacks can be formalized as an optimization problem that seeks private data in a certain space. Recent MI attacks leverage a generative adversarial network (GAN) as an image prior to narrow the search space, and can successfully reconstruct even the high-dimensional data (e.g., face images). However, these generative MI attacks do not fully exploit the potential capabilities of the target model, still leading to a vague and coupled search space, i.e., different classes of images are coupled in the search space. Besides, the widely used cross-entropy loss in these attacks suffers from gradient vanishing. To address these problems, we propose Pseudo Label-Guided MI (PLG-MI) attack via conditional GAN (cGAN). At first, a top-n selection strategy is proposed to provide pseudo-labels for public data, and use pseudo-labels to guide the training of the cGAN. In this way, the search space is decoupled for different classes of images. Then a max-margin loss is introduced to improve the search process on the subspace of a target class. Extensive experiments demonstrate that our PLG-MI attack significantly improves the attack success rate and visual quality for various datasets and models, notably, 2~3 $\times$ better than state-of-the-art attacks under large distributional shifts. Our code is available at: https://github.com/LetheSec/PLG-MI-Attack.
UAVStereo: A Multiple Resolution Dataset for Stereo Matching in UAV Scenarios
Feb 20, 2023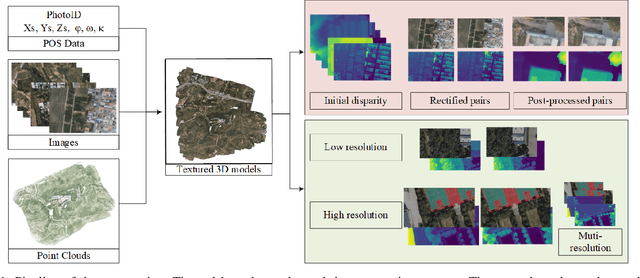

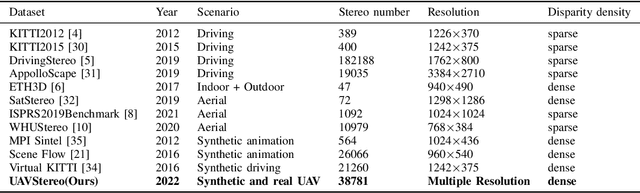
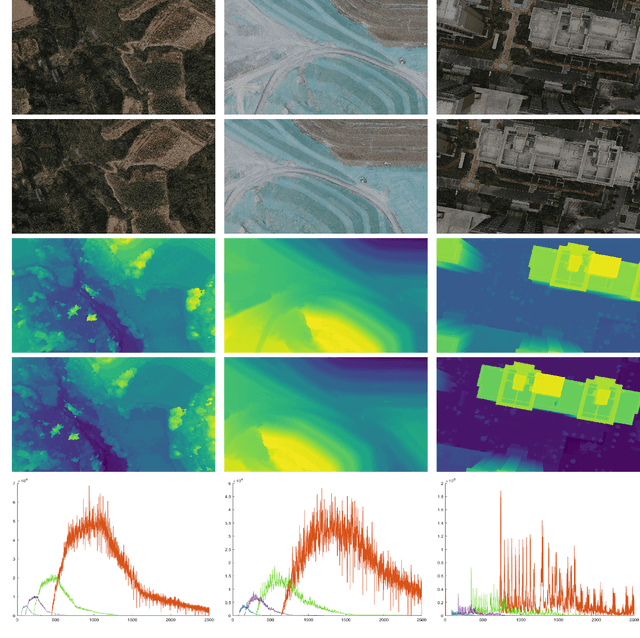
Stereo matching is a fundamental task for 3D scene reconstruction. Recently, deep learning based methods have proven effective on some benchmark datasets, such as KITTI and Scene Flow. UAVs (Unmanned Aerial Vehicles) are commonly utilized for surface observation, and their captured images are frequently used for detailed 3D reconstruction due to high resolution and low-altitude acquisition. At present, the mainstream supervised learning network requires a significant amount of training data with ground-truth labels to learn model parameters. However, due to the scarcity of UAV stereo matching datasets, the learning-based network cannot be applied to UAV images. To facilitate further research, this paper proposes a novel pipeline to generate accurate and dense disparity maps using detailed meshes reconstructed by UAV images and LiDAR point clouds. Through the proposed pipeline, this paper constructs a multi-resolution UAV scenario dataset, called UAVStereo, with over 34k stereo image pairs covering 3 typical scenes. As far as we know, UAVStereo is the first stereo matching dataset of UAV low-altitude scenarios. The dataset includes synthetic and real stereo pairs to enable generalization from the synthetic domain to the real domain. Furthermore, our UAVStereo dataset provides multi-resolution and multi-scene images pairs to accommodate a variety of sensors and environments. In this paper, we evaluate traditional and state-of-the-art deep learning methods, highlighting their limitations in addressing challenges in UAV scenarios and offering suggestions for future research. The dataset is available at https://github.com/rebecca0011/UAVStereo.git
Spatial Functa: Scaling Functa to ImageNet Classification and Generation
Feb 06, 2023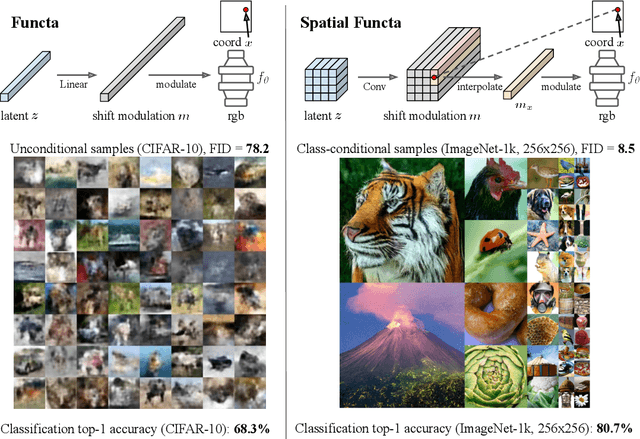
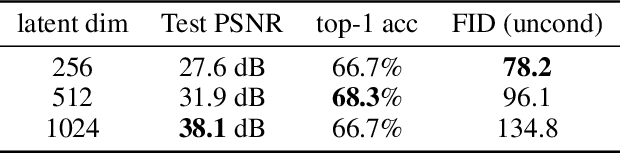


Neural fields, also known as implicit neural representations, have emerged as a powerful means to represent complex signals of various modalities. Based on this Dupont et al. (2022) introduce a framework that views neural fields as data, termed *functa*, and proposes to do deep learning directly on this dataset of neural fields. In this work, we show that the proposed framework faces limitations when scaling up to even moderately complex datasets such as CIFAR-10. We then propose *spatial functa*, which overcome these limitations by using spatially arranged latent representations of neural fields, thereby allowing us to scale up the approach to ImageNet-1k at 256x256 resolution. We demonstrate competitive performance to Vision Transformers (Steiner et al., 2022) on classification and Latent Diffusion (Rombach et al., 2022) on image generation respectively.
Deep Learning Computer Vision Algorithms for Real-time UAVs On-board Camera Image Processing
Nov 02, 2022



This paper describes how advanced deep learning based computer vision algorithms are applied to enable real-time on-board sensor processing for small UAVs. Four use cases are considered: target detection, classification and localization, road segmentation for autonomous navigation in GNSS-denied zones, human body segmentation, and human action recognition. All algorithms have been developed using state-of-the-art image processing methods based on deep neural networks. Acquisition campaigns have been carried out to collect custom datasets reflecting typical operational scenarios, where the peculiar point of view of a multi-rotor UAV is replicated. Algorithms architectures and trained models performances are reported, showing high levels of both accuracy and inference speed. Output examples and on-field videos are presented, demonstrating models operation when deployed on a GPU-powered commercial embedded device (NVIDIA Jetson Xavier) mounted on board of a custom quad-rotor, paving the way to enabling high level autonomy.
Efficient Flow-Guided Multi-frame De-fencing
Jan 25, 2023
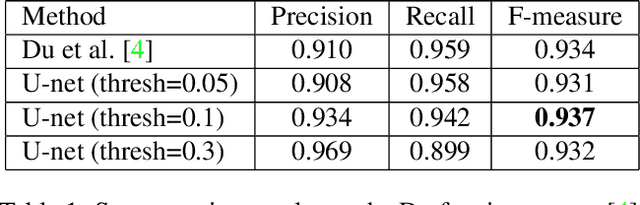

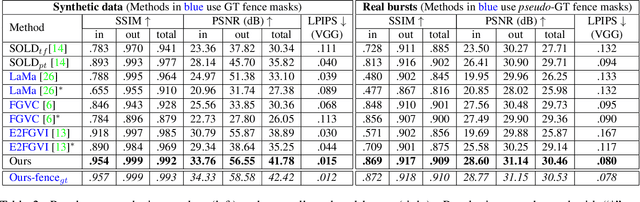
Taking photographs ''in-the-wild'' is often hindered by fence obstructions that stand between the camera user and the scene of interest, and which are hard or impossible to avoid. De-fencing is the algorithmic process of automatically removing such obstructions from images, revealing the invisible parts of the scene. While this problem can be formulated as a combination of fence segmentation and image inpainting, this often leads to implausible hallucinations of the occluded regions. Existing multi-frame approaches rely on propagating information to a selected keyframe from its temporal neighbors, but they are often inefficient and struggle with alignment of severely obstructed images. In this work we draw inspiration from the video completion literature and develop a simplified framework for multi-frame de-fencing that computes high quality flow maps directly from obstructed frames and uses them to accurately align frames. Our primary focus is efficiency and practicality in a real-world setting: the input to our algorithm is a short image burst (5 frames) - a data modality commonly available in modern smartphones - and the output is a single reconstructed keyframe, with the fence removed. Our approach leverages simple yet effective CNN modules, trained on carefully generated synthetic data, and outperforms more complicated alternatives real bursts, both quantitatively and qualitatively, while running real-time.
* 16 pages, 12 figures. Published at the Winter Conference on Application of Computer Vision (WACV) 2023
A Lightweight Reconstruction Network for Surface Defect Inspection
Dec 25, 2022

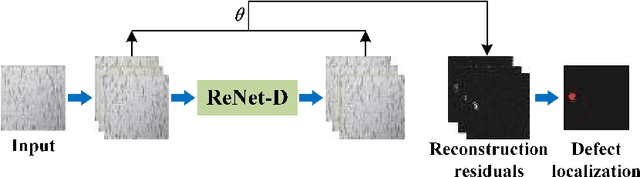

Currently, most deep learning methods cannot solve the problem of scarcity of industrial product defect samples and significant differences in characteristics. This paper proposes an unsupervised defect detection algorithm based on a reconstruction network, which is realized using only a large number of easily obtained defect-free sample data. The network includes two parts: image reconstruction and surface defect area detection. The reconstruction network is designed through a fully convolutional autoencoder with a lightweight structure. Only a small number of normal samples are used for training so that the reconstruction network can be A defect-free reconstructed image is generated. A function combining structural loss and $\mathit{L}1$ loss is proposed as the loss function of the reconstruction network to solve the problem of poor detection of irregular texture surface defects. Further, the residual of the reconstructed image and the image to be tested is used as the possible region of the defect, and conventional image operations can realize the location of the fault. The unsupervised defect detection algorithm of the proposed reconstruction network is used on multiple defect image sample sets. Compared with other similar algorithms, the results show that the unsupervised defect detection algorithm of the reconstructed network has strong robustness and accuracy.
* Journal of Mathematical Imaging and Vision(JMIV)
Image sensing with multilayer, nonlinear optical neural networks
Jul 27, 2022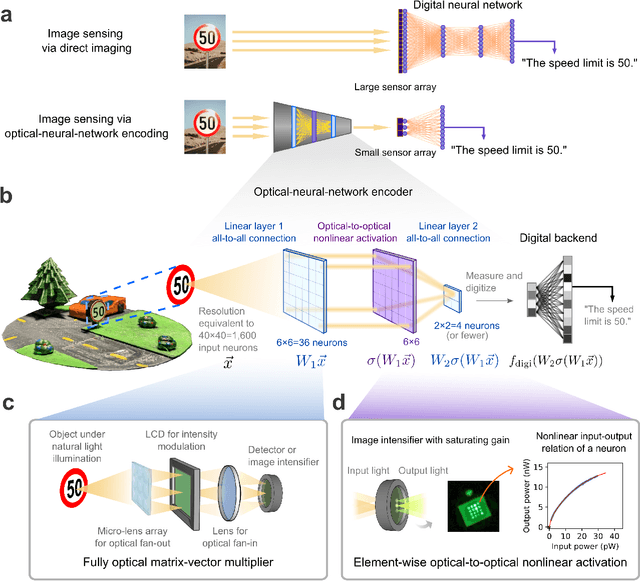
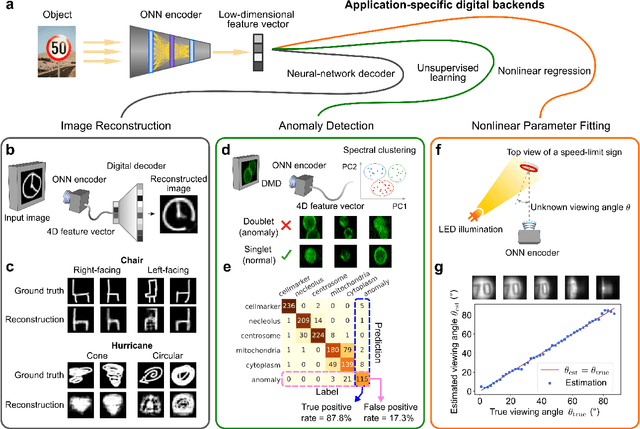
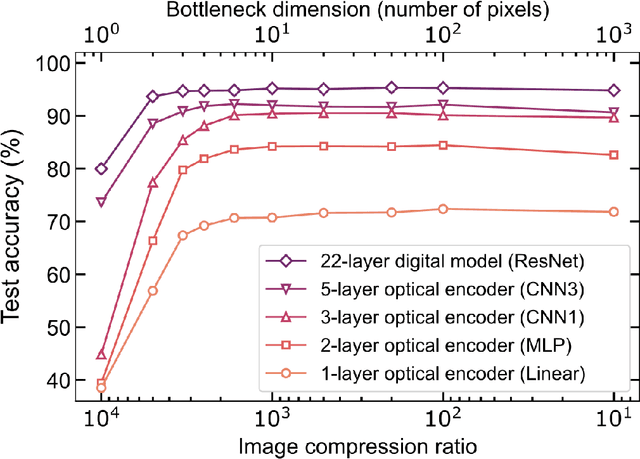

Optical imaging is commonly used for both scientific and technological applications across industry and academia. In image sensing, a measurement, such as of an object's position, is performed by computational analysis of a digitized image. An emerging image-sensing paradigm breaks this delineation between data collection and analysis by designing optical components to perform not imaging, but encoding. By optically encoding images into a compressed, low-dimensional latent space suitable for efficient post-analysis, these image sensors can operate with fewer pixels and fewer photons, allowing higher-throughput, lower-latency operation. Optical neural networks (ONNs) offer a platform for processing data in the analog, optical domain. ONN-based sensors have however been limited to linear processing, but nonlinearity is a prerequisite for depth, and multilayer NNs significantly outperform shallow NNs on many tasks. Here, we realize a multilayer ONN pre-processor for image sensing, using a commercial image intensifier as a parallel optoelectronic, optical-to-optical nonlinear activation function. We demonstrate that the nonlinear ONN pre-processor can achieve compression ratios of up to 800:1 while still enabling high accuracy across several representative computer-vision tasks, including machine-vision benchmarks, flow-cytometry image classification, and identification of objects in real scenes. In all cases we find that the ONN's nonlinearity and depth allowed it to outperform a purely linear ONN encoder. Although our experiments are specialized to ONN sensors for incoherent-light images, alternative ONN platforms should facilitate a range of ONN sensors. These ONN sensors may surpass conventional sensors by pre-processing optical information in spatial, temporal, and/or spectral dimensions, potentially with coherent and quantum qualities, all natively in the optical domain.