 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Transthoracic super-resolution ultrasound localisation microscopy of myocardial vasculature in patients
Mar 28, 2023
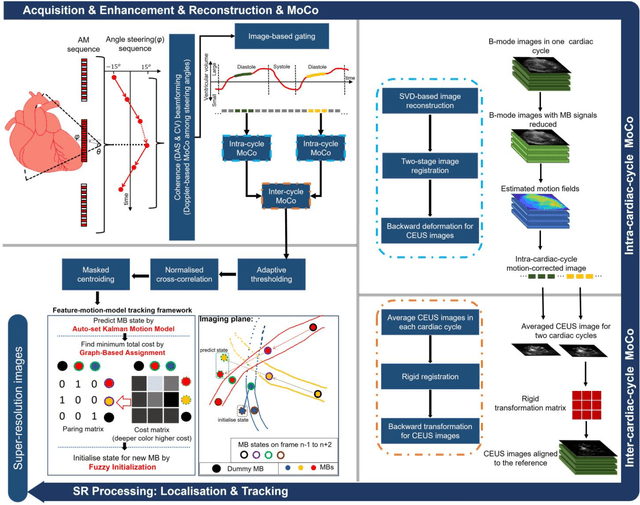
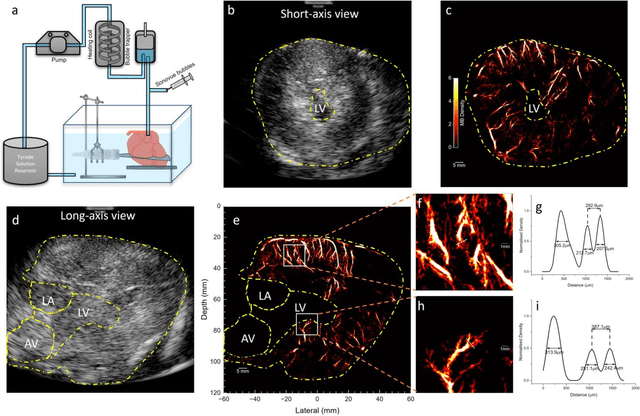
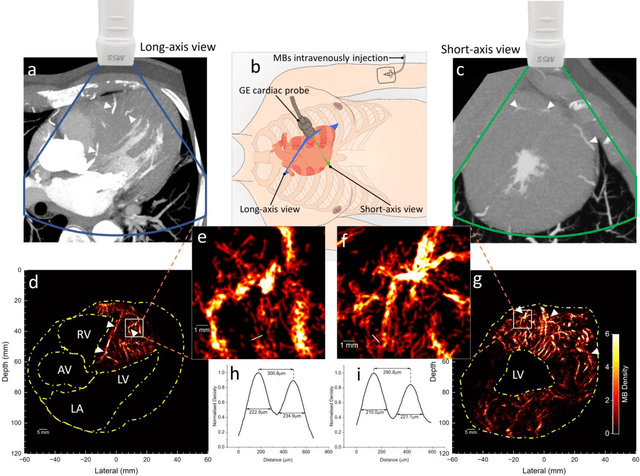
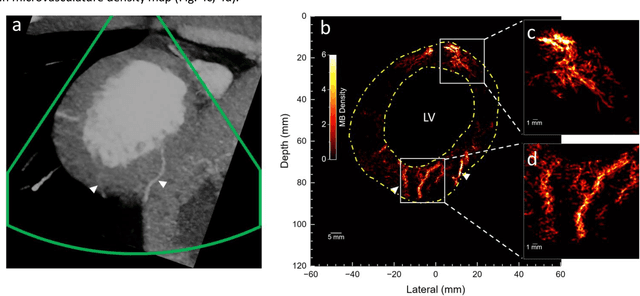
Micro-vascular flow in the myocardium is of significant importance clinically but remains poorly understood. Up to 25% of patients with symptoms of coronary heart diseases have no obstructive coronary arteries and have suspected microvascular diseases. However, such microvasculature is difficult to image in vivo with existing modalities due to the lack of resolution and sensitivity. Here, we demonstrate the feasibility of transthoracic super-resolution ultrasound localisation microscopy (SRUS/ULM) of myocardial microvasculature and hemodynamics in a large animal model and in patients, using a cardiac phased array probe with a customised data acquisition and processing pipeline. A multi-level motion correction strategy was proposed. A tracking framework incorporating multiple features and automatic parameter initialisations was developed to reconstruct microcirculation. In two patients with impaired myocardial function, we have generated SRUS images of myocardial vascular structure and flow with a resolution that is beyond the wave-diffraction limit (half a wavelength), using data acquired within a breath hold. Myocardial SRUS/ULM has potential to improve the understanding of myocardial microcirculation and the management of patients with cardiac microvascular diseases.
A Comparative Study of Federated Learning Models for COVID-19 Detection
Mar 28, 2023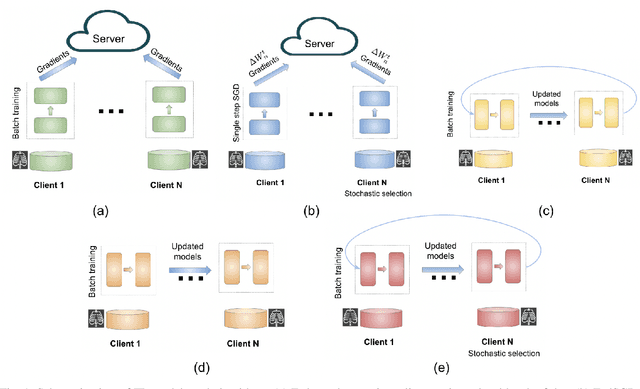
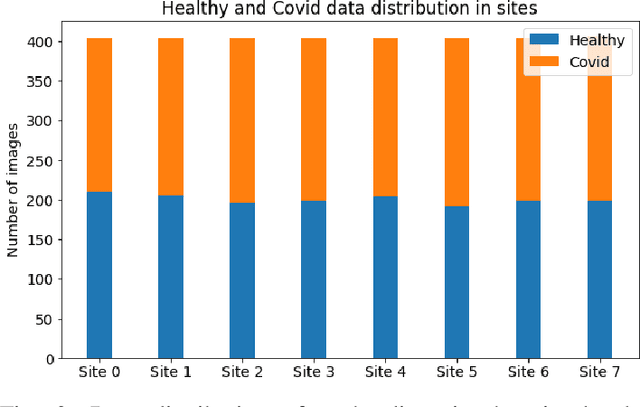
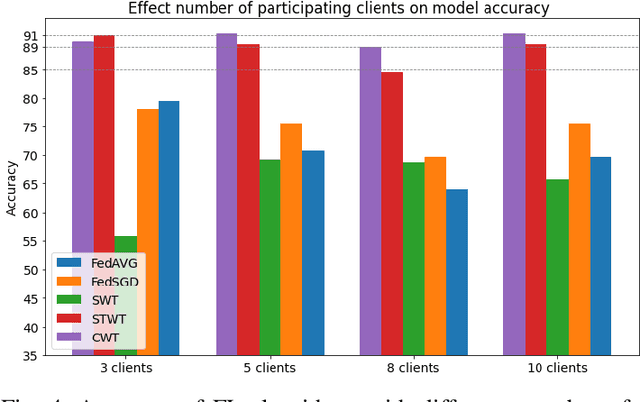
Deep learning is effective in diagnosing COVID-19 and requires a large amount of data to be effectively trained. Due to data and privacy regulations, hospitals generally have no access to data from other hospitals. Federated learning (FL) has been used to solve this problem, where it utilizes a distributed setting to train models in hospitals in a privacy-preserving manner. Deploying FL is not always feasible as it requires high computation and network communication resources. This paper evaluates five FL algorithms' performance and resource efficiency for Covid-19 detection. A decentralized setting with CNN networks is set up, and the performance of FL algorithms is compared with a centralized environment. We examined the algorithms with varying numbers of participants, federated rounds, and selection algorithms. Our results show that cyclic weight transfer can have better overall performance, and results are better with fewer participating hospitals. Our results demonstrate good performance for detecting COVID-19 patients and might be useful in deploying FL algorithms for covid-19 detection and medical image analysis in general.
Projected Latent Distillation for Data-Agnostic Consolidation in Distributed Continual Learning
Mar 28, 2023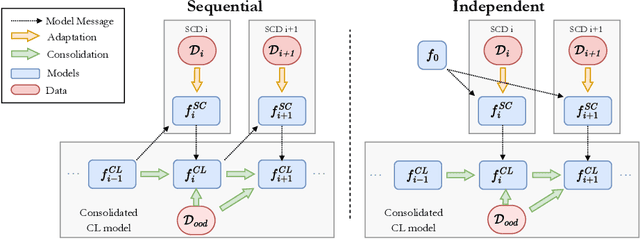
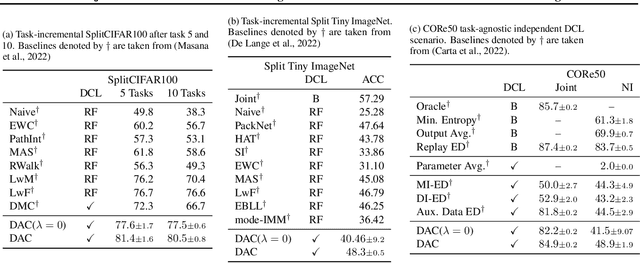
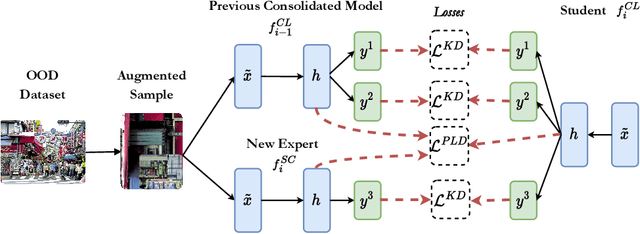

Distributed learning on the edge often comprises self-centered devices (SCD) which learn local tasks independently and are unwilling to contribute to the performance of other SDCs. How do we achieve forward transfer at zero cost for the single SCDs? We formalize this problem as a Distributed Continual Learning scenario, where SCD adapt to local tasks and a CL model consolidates the knowledge from the resulting stream of models without looking at the SCD's private data. Unfortunately, current CL methods are not directly applicable to this scenario. We propose Data-Agnostic Consolidation (DAC), a novel double knowledge distillation method that consolidates the stream of SC models without using the original data. DAC performs distillation in the latent space via a novel Projected Latent Distillation loss. Experimental results show that DAC enables forward transfer between SCDs and reaches state-of-the-art accuracy on Split CIFAR100, CORe50 and Split TinyImageNet, both in reharsal-free and distributed CL scenarios. Somewhat surprisingly, even a single out-of-distribution image is sufficient as the only source of data during consolidation.
DiffULD: Diffusive Universal Lesion Detection
Mar 28, 2023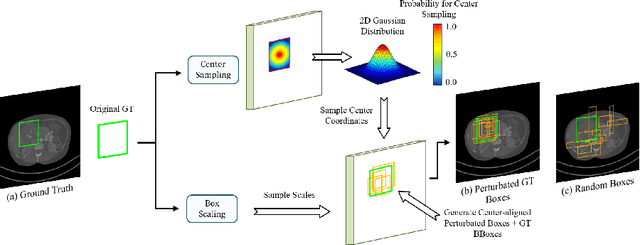
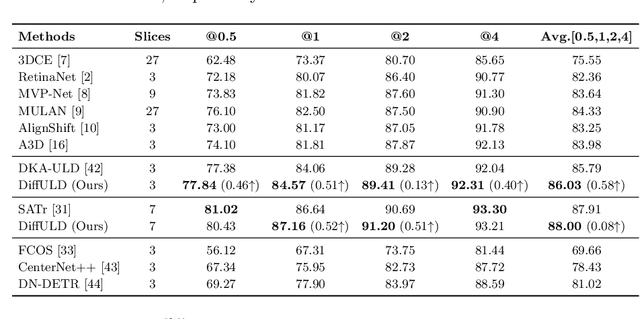
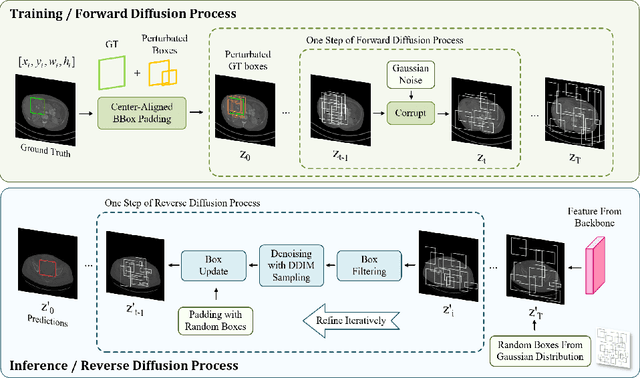

Universal Lesion Detection (ULD) in computed tomography (CT) plays an essential role in computer-aided diagnosis. Promising ULD results have been reported by anchor-based detection designs, but they have inherent drawbacks due to the use of anchors: i) Insufficient training targets and ii) Difficulties in anchor design. Diffusion probability models (DPM) have demonstrated outstanding capabilities in many vision tasks. Many DPM-based approaches achieve great success in natural image object detection without using anchors. But they are still ineffective for ULD due to the insufficient training targets. In this paper, we propose a novel ULD method, DiffULD, which utilizes DPM for lesion detection. To tackle the negative effect triggered by insufficient targets, we introduce a novel center-aligned bounding box padding strategy that provides additional high-quality training targets yet avoids significant performance deterioration. DiffULD is inherently advanced in locating lesions with diverse sizes and shapes since it can predict with arbitrary boxes. Experiments on the benchmark dataset DeepLesion show the superiority of DiffULD when compared to state-of-the-art ULD approaches.
mHealth hyperspectral learning for instantaneous spatiospectral imaging of hemodynamics
Apr 05, 2023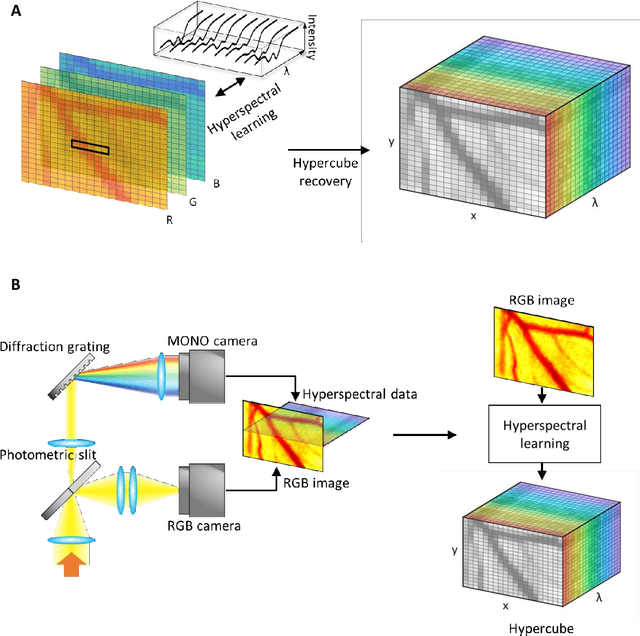
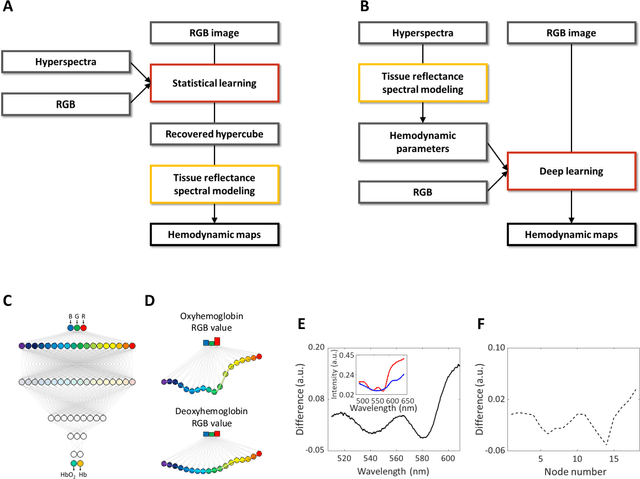
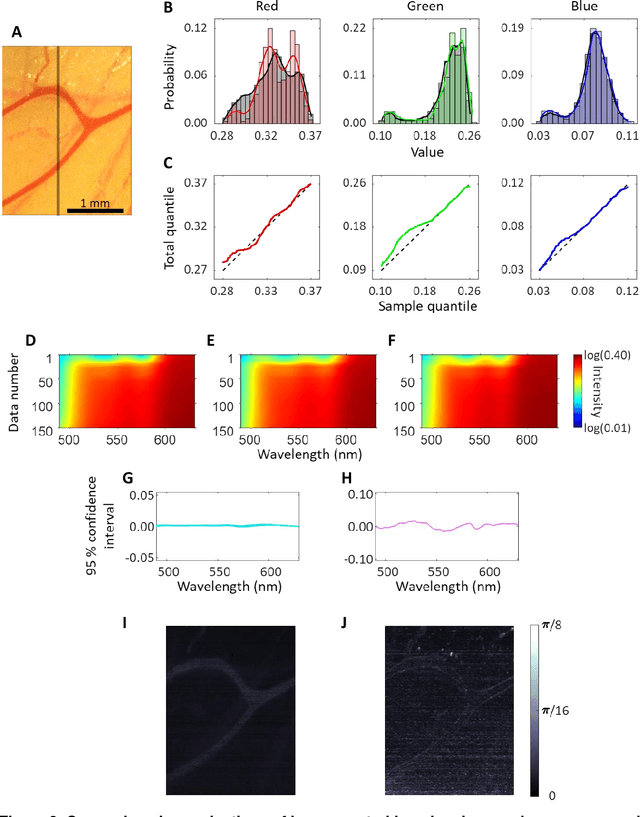
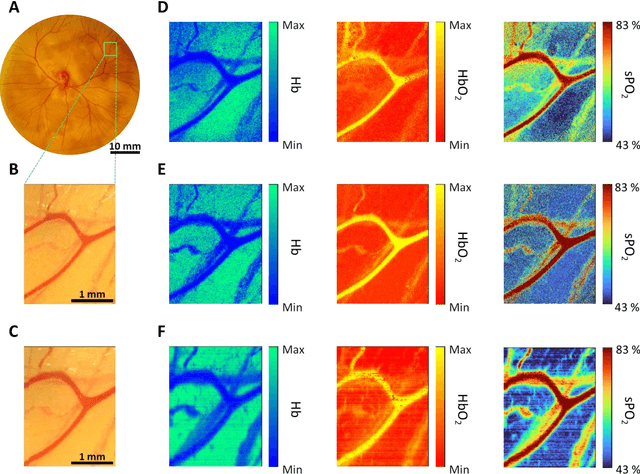
Hyperspectral imaging acquires data in both the spatial and frequency domains to offer abundant physical or biological information. However, conventional hyperspectral imaging has intrinsic limitations of bulky instruments, slow data acquisition rate, and spatiospectral tradeoff. Here we introduce hyperspectral learning for snapshot hyperspectral imaging in which sampled hyperspectral data in a small subarea are incorporated into a learning algorithm to recover the hypercube. Hyperspectral learning exploits the idea that a photograph is more than merely a picture and contains detailed spectral information. A small sampling of hyperspectral data enables spectrally informed learning to recover a hypercube from an RGB image. Hyperspectral learning is capable of recovering full spectroscopic resolution in the hypercube, comparable to high spectral resolutions of scientific spectrometers. Hyperspectral learning also enables ultrafast dynamic imaging, leveraging ultraslow video recording in an off-the-shelf smartphone, given that a video comprises a time series of multiple RGB images. To demonstrate its versatility, an experimental model of vascular development is used to extract hemodynamic parameters via statistical and deep-learning approaches. Subsequently, the hemodynamics of peripheral microcirculation is assessed at an ultrafast temporal resolution up to a millisecond, using a conventional smartphone camera. This spectrally informed learning method is analogous to compressed sensing; however, it further allows for reliable hypercube recovery and key feature extractions with a transparent learning algorithm. This learning-powered snapshot hyperspectral imaging method yields high spectral and temporal resolutions and eliminates the spatiospectral tradeoff, offering simple hardware requirements and potential applications of various machine-learning techniques.
FACE-AUDITOR: Data Auditing in Facial Recognition Systems
Apr 05, 2023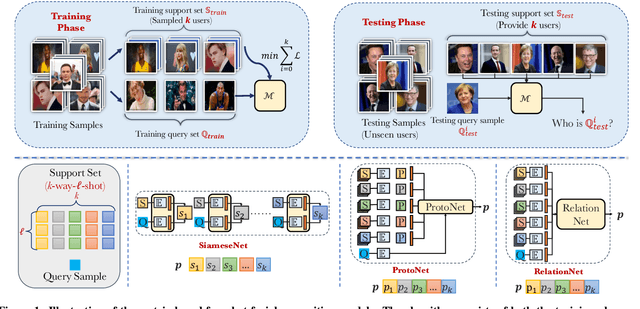

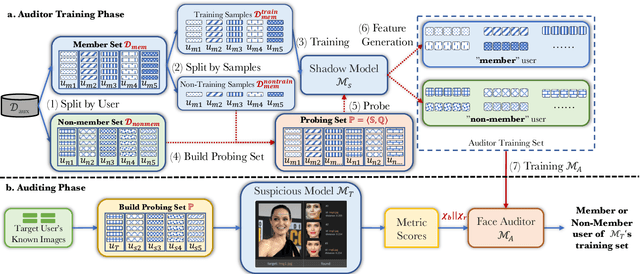
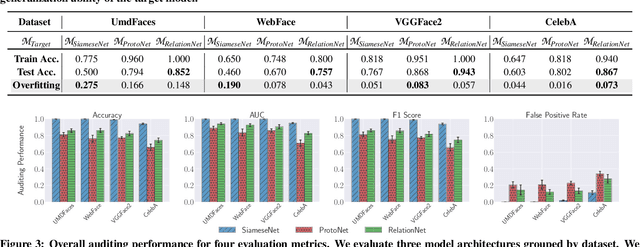
Few-shot-based facial recognition systems have gained increasing attention due to their scalability and ability to work with a few face images during the model deployment phase. However, the power of facial recognition systems enables entities with moderate resources to canvas the Internet and build well-performed facial recognition models without people's awareness and consent. To prevent the face images from being misused, one straightforward approach is to modify the raw face images before sharing them, which inevitably destroys the semantic information, increases the difficulty of retroactivity, and is still prone to adaptive attacks. Therefore, an auditing method that does not interfere with the facial recognition model's utility and cannot be quickly bypassed is urgently needed. In this paper, we formulate the auditing process as a user-level membership inference problem and propose a complete toolkit FACE-AUDITOR that can carefully choose the probing set to query the few-shot-based facial recognition model and determine whether any of a user's face images is used in training the model. We further propose to use the similarity scores between the original face images as reference information to improve the auditing performance. Extensive experiments on multiple real-world face image datasets show that FACE-AUDITOR can achieve auditing accuracy of up to $99\%$. Finally, we show that FACE-AUDITOR is robust in the presence of several perturbation mechanisms to the training images or the target models. The source code of our experiments can be found at \url{https://github.com/MinChen00/Face-Auditor}.
Efficient CNNs via Passive Filter Pruning
Apr 05, 2023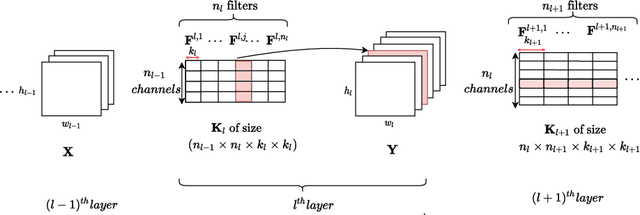
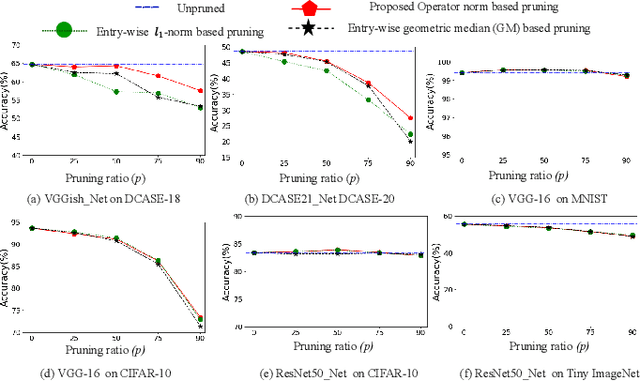
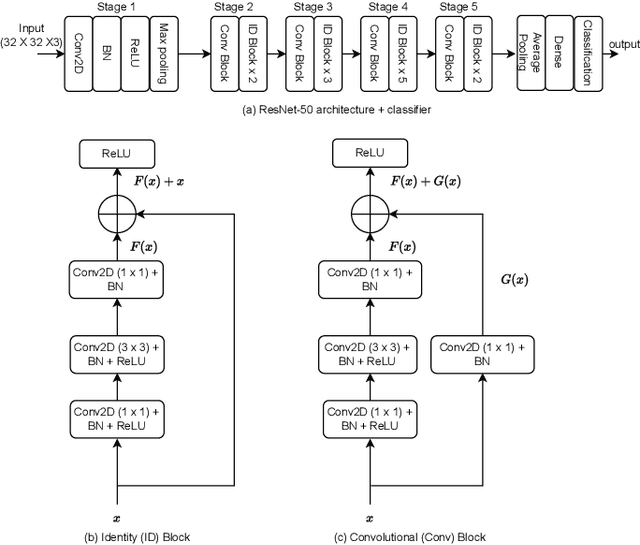
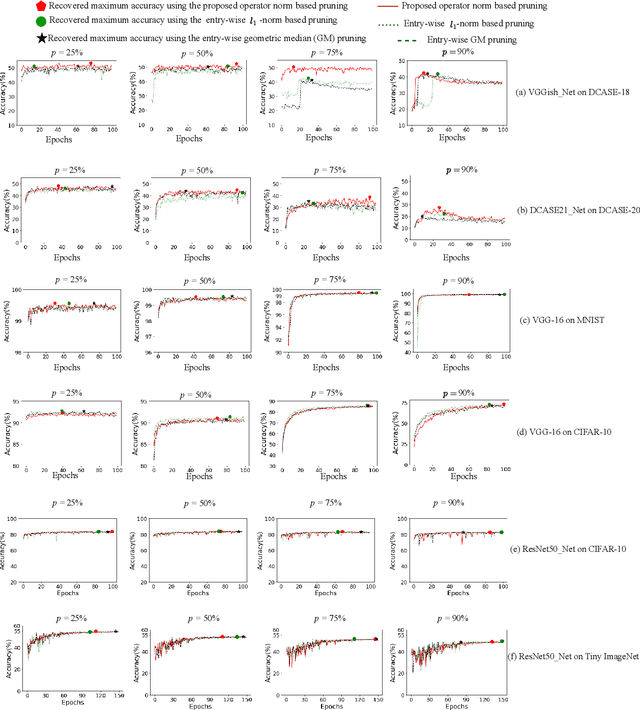
Convolutional neural networks (CNNs) have shown state-of-the-art performance in various applications. However, CNNs are resource-hungry due to their requirement of high computational complexity and memory storage. Recent efforts toward achieving computational efficiency in CNNs involve filter pruning methods that eliminate some of the filters in CNNs based on the \enquote{importance} of the filters. The majority of existing filter pruning methods are either "active", which use a dataset and generate feature maps to quantify filter importance, or "passive", which compute filter importance using entry-wise norm of the filters without involving data. Under a high pruning ratio where large number of filters are to be pruned from the network, the entry-wise norm methods eliminate relatively smaller norm filters without considering the significance of the filters in producing the node output, resulting in degradation in the performance. To address this, we present a passive filter pruning method where the filters are pruned based on their contribution in producing output by considering the operator norm of the filters. The proposed pruning method generalizes better across various CNNs compared to that of the entry-wise norm-based pruning methods. In comparison to the existing active filter pruning methods, the proposed pruning method is at least 4.5 times faster in computing filter importance and is able to achieve similar performance compared to that of the active filter pruning methods. The efficacy of the proposed pruning method is evaluated on audio scene classification and image classification using various CNNs architecture such as VGGish, DCASE21_Net, VGG-16 and ResNet-50.
Few-shot Image Generation via Masked Discrimination
Oct 27, 2022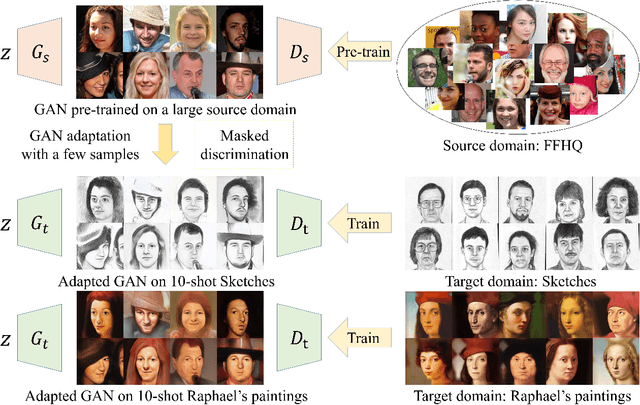
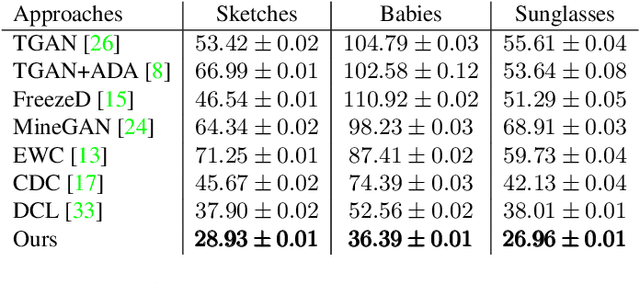
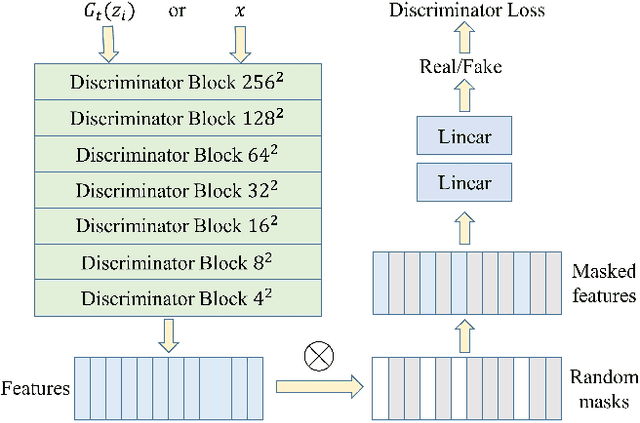

Few-shot image generation aims to generate images of high quality and great diversity with limited data. However, it is difficult for modern GANs to avoid overfitting when trained on only a few images. The discriminator can easily remember all the training samples and guide the generator to replicate them, leading to severe diversity degradation. Several methods have been proposed to relieve overfitting by adapting GANs pre-trained on large source domains to target domains with limited real samples. In this work, we present a novel approach to realize few-shot GAN adaptation via masked discrimination. Random masks are applied to features extracted by the discriminator from input images. We aim to encourage the discriminator to judge more diverse images which share partially common features with training samples as realistic images. Correspondingly, the generator is guided to generate more diverse images instead of replicating training samples. In addition, we employ cross-domain consistency loss for the discriminator to keep relative distances between samples in its feature space. The discriminator cross-domain consistency loss serves as another optimization target in addition to adversarial loss and guides adapted GANs to preserve more information learned from source domains for higher image quality. The effectiveness of our approach is demonstrated both qualitatively and quantitatively with higher quality and greater diversity on a series of few-shot image generation tasks than prior methods.
SLMT-Net: A Self-supervised Learning based Multi-scale Transformer Network for Cross-Modality MR Image Synthesis
Dec 02, 2022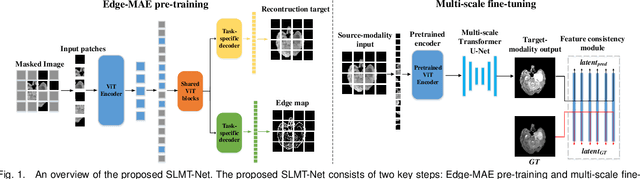
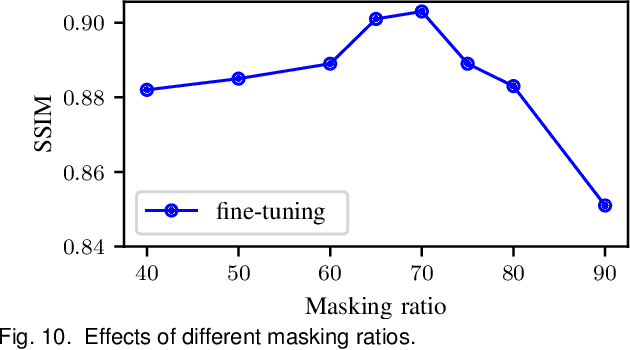
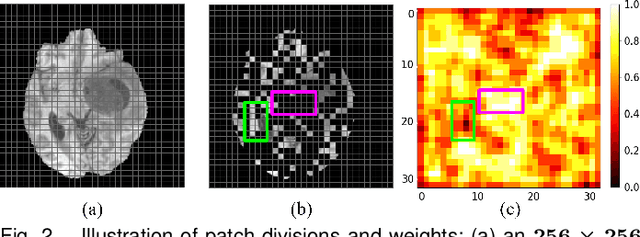
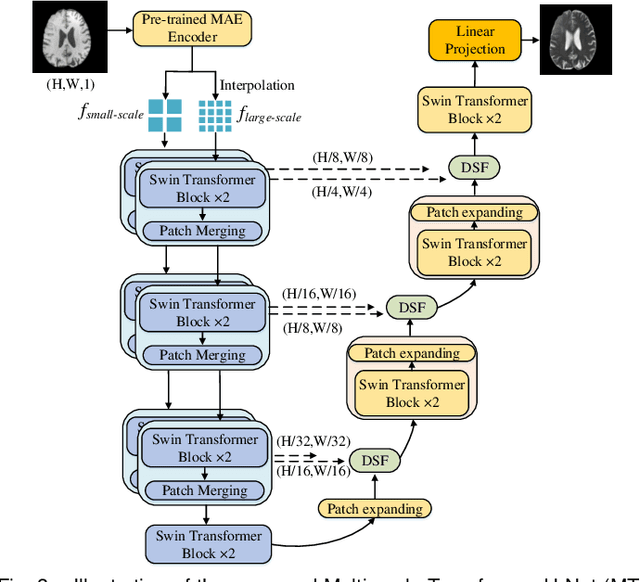
Cross-modality magnetic resonance (MR) image synthesis aims to produce missing modalities from existing ones. Currently, several methods based on deep neural networks have been developed using both source- and target-modalities in a supervised learning manner. However, it remains challenging to obtain a large amount of completely paired multi-modal training data, which inhibits the effectiveness of existing methods. In this paper, we propose a novel Self-supervised Learning-based Multi-scale Transformer Network (SLMT-Net) for cross-modality MR image synthesis, consisting of two stages, \ie, a pre-training stage and a fine-tuning stage. During the pre-training stage, we propose an Edge-preserving Masked AutoEncoder (Edge-MAE), which preserves the contextual and edge information by simultaneously conducting the image reconstruction and the edge generation. Besides, a patch-wise loss is proposed to treat the input patches differently regarding their reconstruction difficulty, by measuring the difference between the reconstructed image and the ground-truth. In this case, our Edge-MAE can fully leverage a large amount of unpaired multi-modal data to learn effective feature representations. During the fine-tuning stage, we present a Multi-scale Transformer U-Net (MT-UNet) to synthesize the target-modality images, in which a Dual-scale Selective Fusion (DSF) module is proposed to fully integrate multi-scale features extracted from the encoder of the pre-trained Edge-MAE. Moreover, we use the pre-trained encoder as a feature consistency module to measure the difference between high-level features of the synthesized image and the ground truth one. Experimental results show the effectiveness of the proposed SLMT-Net, and our model can reliably synthesize high-quality images when the training set is partially unpaired. Our code will be publicly available at https://github.com/lyhkevin/SLMT-Net.
Image Completion with Heterogeneously Filtered Spectral Hints
Nov 07, 2022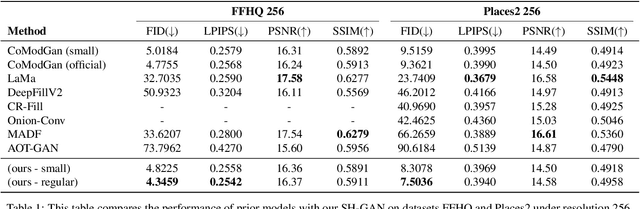
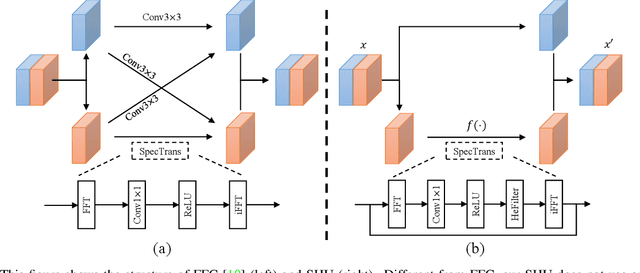
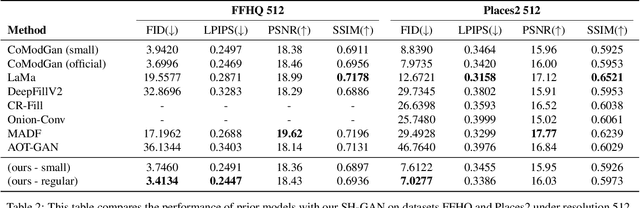
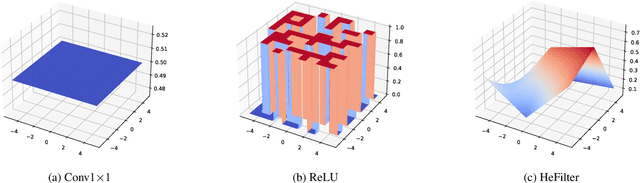
Image completion with large-scale free-form missing regions is one of the most challenging tasks for the computer vision community. While researchers pursue better solutions, drawbacks such as pattern unawareness, blurry textures, and structure distortion remain noticeable, and thus leave space for improvement. To overcome these challenges, we propose a new StyleGAN-based image completion network, Spectral Hint GAN (SH-GAN), inside which a carefully designed spectral processing module, Spectral Hint Unit, is introduced. We also propose two novel 2D spectral processing strategies, Heterogeneous Filtering and Gaussian Split that well-fit modern deep learning models and may further be extended to other tasks. From our inclusive experiments, we demonstrate that our model can reach FID scores of 3.4134 and 7.0277 on the benchmark datasets FFHQ and Places2, and therefore outperforms prior works and reaches a new state-of-the-art. We also prove the effectiveness of our design via ablation studies, from which one may notice that the aforementioned challenges, i.e. pattern unawareness, blurry textures, and structure distortion, can be noticeably resolved. Our code will be open-sourced at: https://github.com/SHI-Labs/SH-GAN.