 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
NeurEPDiff: Neural Operators to Predict Geodesics in Deformation Spaces
Mar 13, 2023
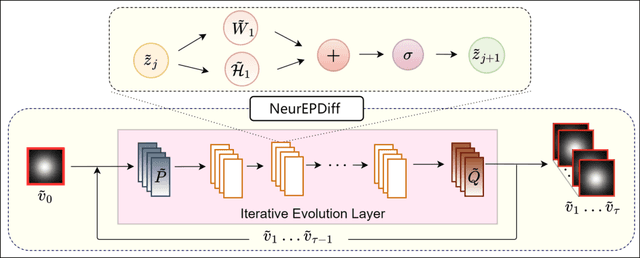
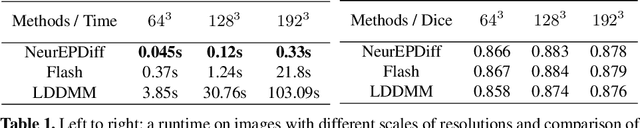
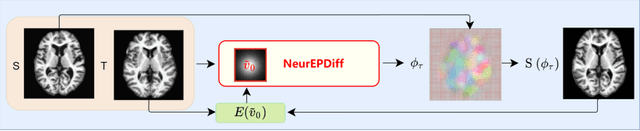

This paper presents NeurEPDiff, a novel network to fast predict the geodesics in deformation spaces generated by a well known Euler-Poincar\'e differential equation (EPDiff). To achieve this, we develop a neural operator that for the first time learns the evolving trajectory of geodesic deformations parameterized in the tangent space of diffeomorphisms(a.k.a velocity fields). In contrast to previous methods that purely fit the training images, our proposed NeurEPDiff learns a nonlinear mapping function between the time-dependent velocity fields. A composition of integral operators and smooth activation functions is formulated in each layer of NeurEPDiff to effectively approximate such mappings. The fact that NeurEPDiff is able to rapidly provide the numerical solution of EPDiff (given any initial condition) results in a significantly reduced computational cost of geodesic shooting of diffeomorphisms in a high-dimensional image space. Additionally, the properties of discretiztion/resolution-invariant of NeurEPDiff make its performance generalizable to multiple image resolutions after being trained offline. We demonstrate the effectiveness of NeurEPDiff in registering two image datasets: 2D synthetic data and 3D brain resonance imaging (MRI). The registration accuracy and computational efficiency are compared with the state-of-the-art diffeomophic registration algorithms with geodesic shooting.
Distribution Aligned Diffusion and Prototype-guided network for Unsupervised Domain Adaptive Segmentation
Mar 25, 2023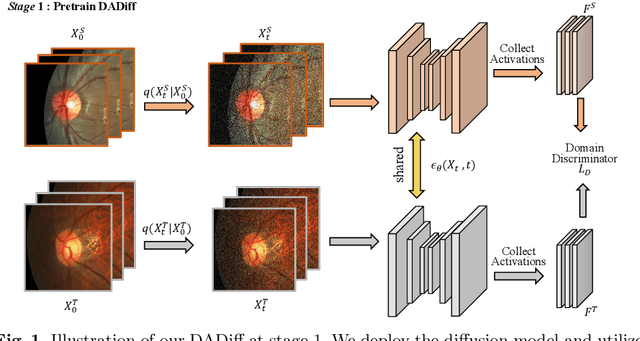
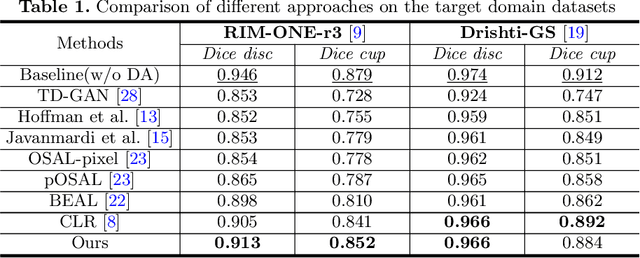
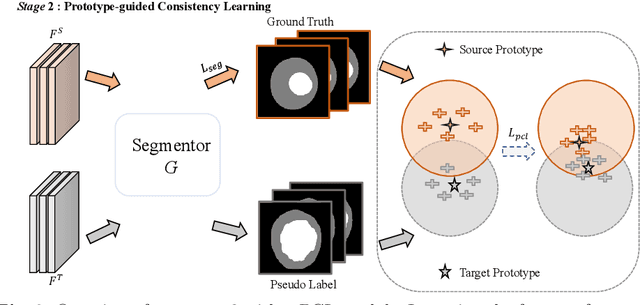
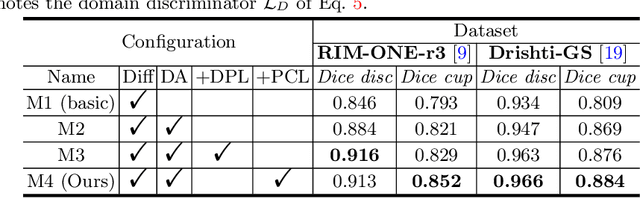
The Diffusion Probabilistic Model (DPM) has emerged as a highly effective generative model in the field of computer vision. Its intermediate latent vectors offer rich semantic information, making it an attractive option for various downstream tasks such as segmentation and detection. In order to explore its potential further, we have taken a step forward and considered a more complex scenario in the medical image domain, specifically, under an unsupervised adaptation condition. To this end, we propose a Diffusion-based and Prototype-guided network (DP-Net) for unsupervised domain adaptive segmentation. Concretely, our DP-Net consists of two stages: 1) Distribution Aligned Diffusion (DADiff), which involves training a domain discriminator to minimize the difference between the intermediate features generated by the DPM, thereby aligning the inter-domain distribution; and 2) Prototype-guided Consistency Learning (PCL), which utilizes feature centroids as prototypes and applies a prototype-guided loss to ensure that the segmentor learns consistent content from both source and target domains. Our approach is evaluated on fundus datasets through a series of experiments, which demonstrate that the performance of the proposed method is reliable and outperforms state-of-the-art methods. Our work presents a promising direction for using DPM in complex medical image scenarios, opening up new possibilities for further research in medical imaging.
Self-Supervised Visual Representation Learning on Food Images
Mar 16, 2023
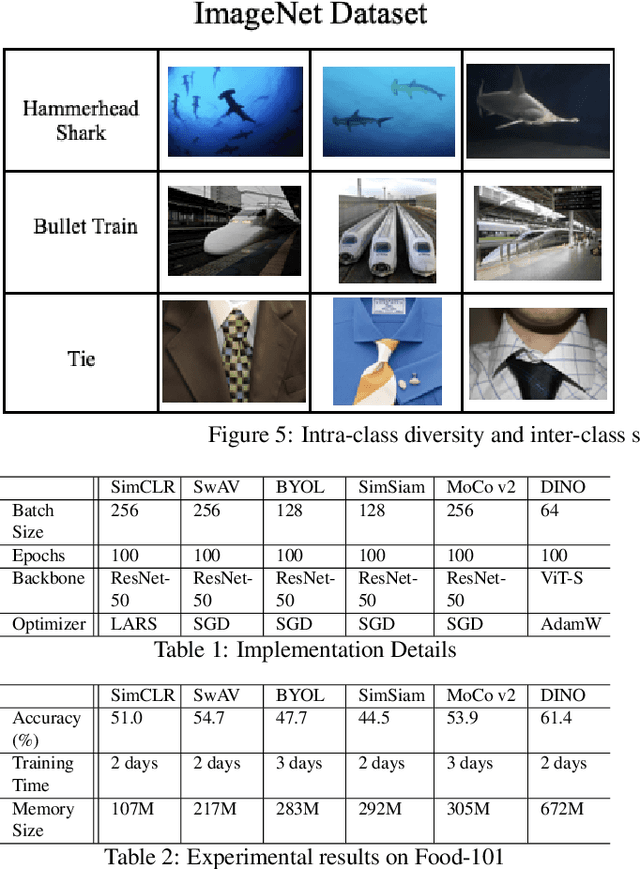
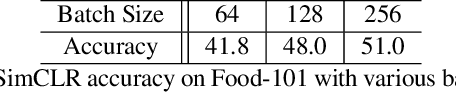

Food image analysis is the groundwork for image-based dietary assessment, which is the process of monitoring what kinds of food and how much energy is consumed using captured food or eating scene images. Existing deep learning-based methods learn the visual representation for downstream tasks based on human annotation of each food image. However, most food images in real life are obtained without labels, and data annotation requires plenty of time and human effort, which is not feasible for real-world applications. To make use of the vast amount of unlabeled images, many existing works focus on unsupervised or self-supervised learning of visual representations directly from unlabeled data. However, none of these existing works focus on food images, which is more challenging than general objects due to its high inter-class similarity and intra-class variance. In this paper, we focus on the implementation and analysis of existing representative self-supervised learning methods on food images. Specifically, we first compare the performance of six selected self-supervised learning models on the Food-101 dataset. Then we analyze the pros and cons of each selected model when training on food data to identify the key factors that can help improve the performance. Finally, we propose several ideas for future work on self-supervised visual representation learning for food images.
Learning Physical-Spatio-Temporal Features for Video Shadow Removal
Mar 16, 2023
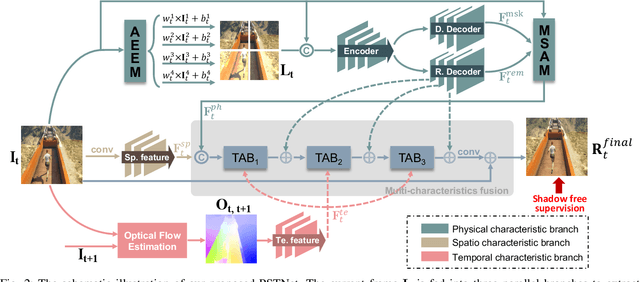
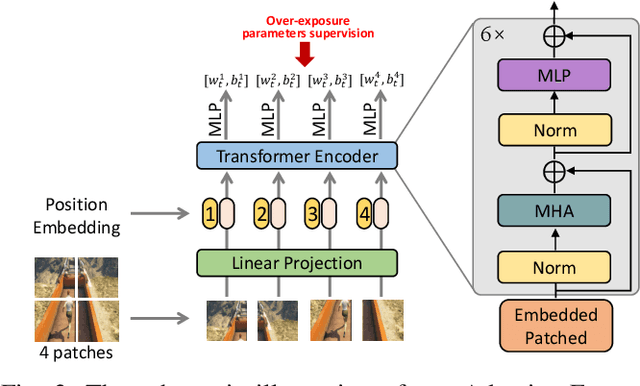
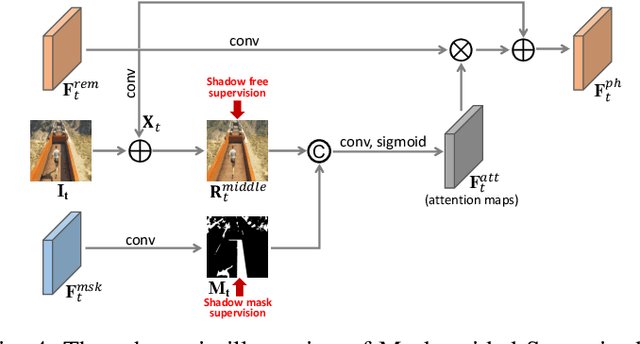
Shadow removal in a single image has received increasing attention in recent years. However, removing shadows over dynamic scenes remains largely under-explored. In this paper, we propose the first data-driven video shadow removal model, termed PSTNet, by exploiting three essential characteristics of video shadows, i.e., physical property, spatio relation, and temporal coherence. Specifically, a dedicated physical branch was established to conduct local illumination estimation, which is more applicable for scenes with complex lighting and textures, and then enhance the physical features via a mask-guided attention strategy. Then, we develop a progressive aggregation module to enhance the spatio and temporal characteristics of features maps, and effectively integrate the three kinds of features. Furthermore, to tackle the lack of datasets of paired shadow videos, we synthesize a dataset (SVSRD-85) with aid of the popular game GTAV by controlling the switch of the shadow renderer. Experiments against 9 state-of-the-art models, including image shadow removers and image/video restoration methods, show that our method improves the best SOTA in terms of RMSE error for the shadow area by 14.7. In addition, we develop a lightweight model adaptation strategy to make our synthetic-driven model effective in real world scenes. The visual comparison on the public SBU-TimeLapse dataset verifies the generalization ability of our model in real scenes.
MedSegDiff: Medical Image Segmentation with Diffusion Probabilistic Model
Nov 01, 2022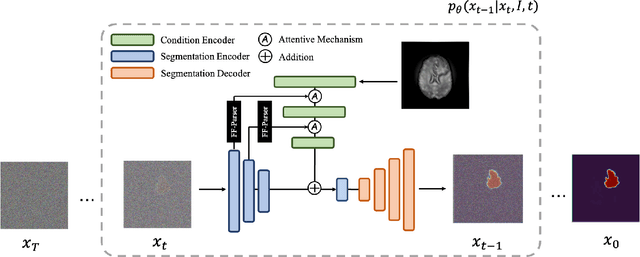
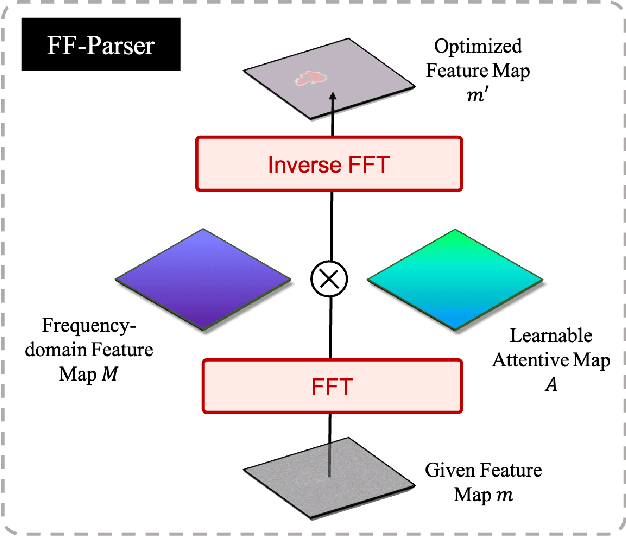
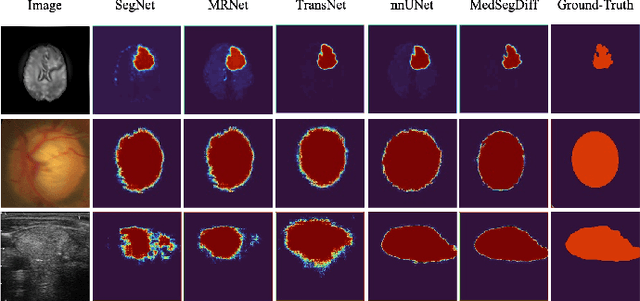
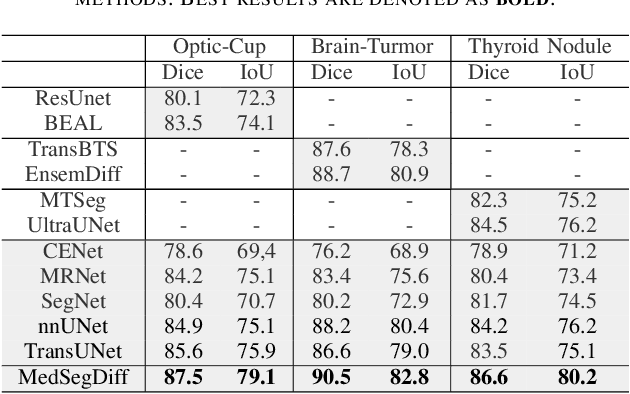
Diffusion probabilistic model (DPM) recently becomes one of the hottest topic in computer vision. Its image generation application such as Imagen, Latent Diffusion Models and Stable Diffusion have shown impressive generation capabilities, which aroused extensive discussion in the community. Many recent studies also found it useful in many other vision tasks, like image deblurring, super-resolution and anomaly detection. Inspired by the success of DPM, we propose the first DPM based model toward general medical image segmentation tasks, which we named MedSegDiff. In order to enhance the step-wise regional attention in DPM for the medical image segmentation, we propose dynamic conditional encoding, which establishes the state-adaptive conditions for each sampling step. We further propose Feature Frequency Parser (FF-Parser), to eliminate the negative effect of high-frequency noise component in this process. We verify MedSegDiff on three medical segmentation tasks with different image modalities, which are optic cup segmentation over fundus images, brain tumor segmentation over MRI images and thyroid nodule segmentation over ultrasound images. The experimental results show that MedSegDiff outperforms state-of-the-art (SOTA) methods with considerable performance gap, indicating the generalization and effectiveness of the proposed model.
Real Time Incremental Image Mosaicking Without Use of Any Camera Parameter
Dec 05, 2022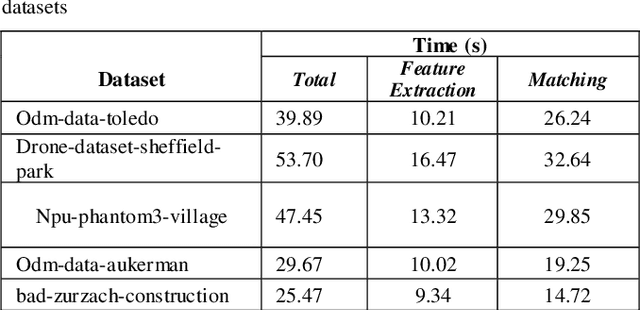

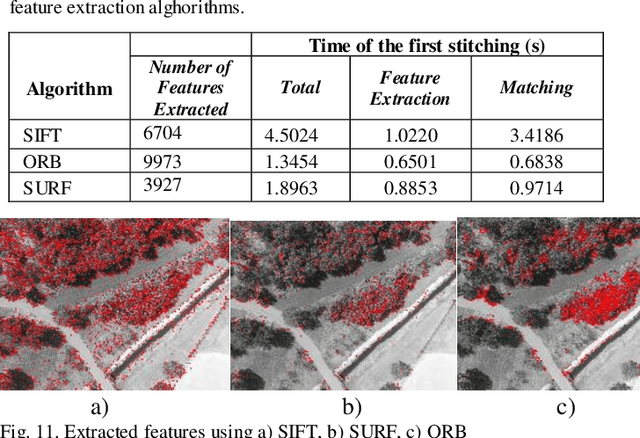

Over the past decade, there has been a significant increase in the use of Unmanned Aerial Vehicles (UAVs) to support a wide variety of missions, such as remote surveillance, vehicle tracking, and object detection. For problems involving processing of areas larger than a single image, the mosaicking of UAV imagery is a necessary step. Real-time image mosaicking is used for missions that requires fast response like search and rescue missions. It typically requires information from additional sensors, such as Global Position System (GPS) and Inertial Measurement Unit (IMU), to facilitate direct orientation, or 3D reconstruction approaches to recover the camera poses. This paper proposes a UAV-based system for real-time creation of incremental mosaics which does not require either direct or indirect camera parameters such as orientation information. Inspired by previous approaches, in the mosaicking process, feature extraction from images, matching of similar key points between images, finding homography matrix to warp and align images, and blending images to obtain mosaics better looking, plays important roles in the achievement of the high quality result. Edge detection is used in the blending step as a novel approach. Experimental results show that real-time incremental image mosaicking process can be completed satisfactorily and without need for any additional camera parameters.
ContextCLIP: Contextual Alignment of Image-Text pairs on CLIP visual representations
Nov 14, 2022
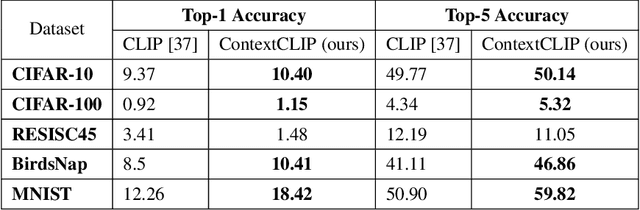
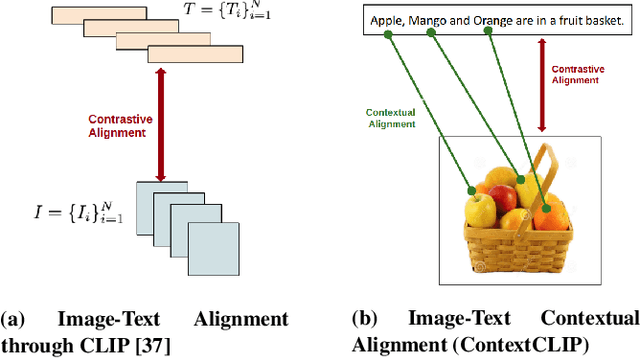
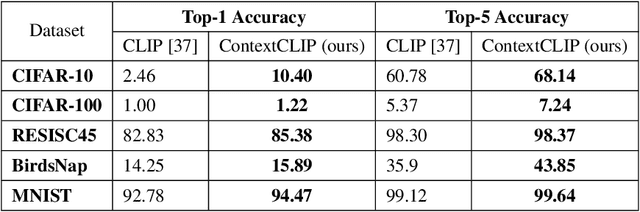
State-of-the-art empirical work has shown that visual representations learned by deep neural networks are robust in nature and capable of performing classification tasks on diverse datasets. For example, CLIP demonstrated zero-shot transfer performance on multiple datasets for classification tasks in a joint embedding space of image and text pairs. However, it showed negative transfer performance on standard datasets, e.g., BirdsNAP, RESISC45, and MNIST. In this paper, we propose ContextCLIP, a contextual and contrastive learning framework for the contextual alignment of image-text pairs by learning robust visual representations on Conceptual Captions dataset. Our framework was observed to improve the image-text alignment by aligning text and image representations contextually in the joint embedding space. ContextCLIP showed good qualitative performance for text-to-image retrieval tasks and enhanced classification accuracy. We evaluated our model quantitatively with zero-shot transfer and fine-tuning experiments on CIFAR-10, CIFAR-100, Birdsnap, RESISC45, and MNIST datasets for classification task.
Adjustable Privacy using Autoencoder-based Learning Structure
Apr 07, 2023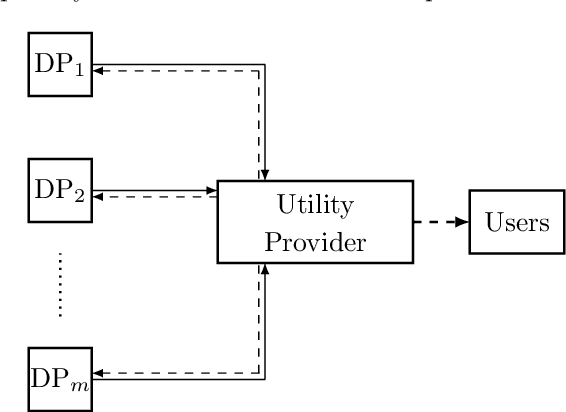
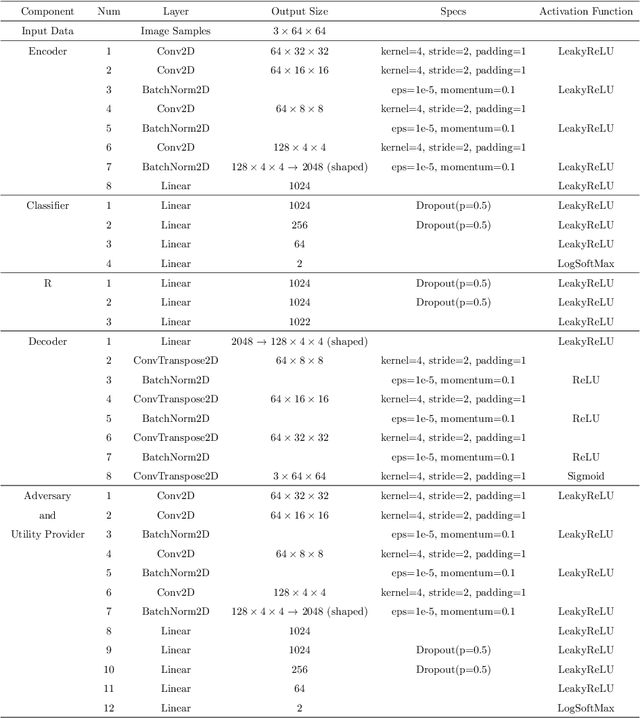
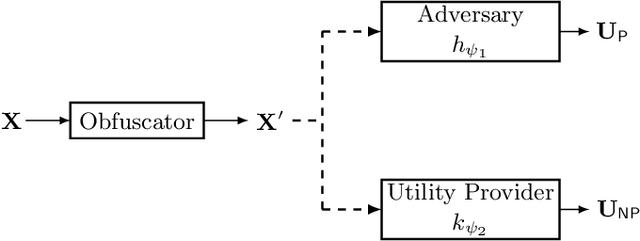
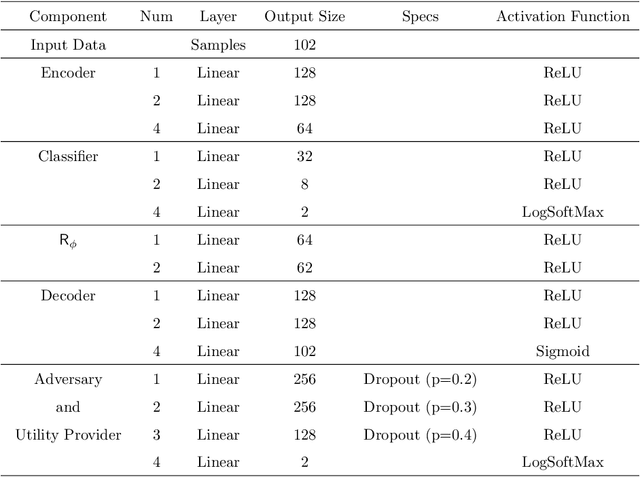
Inference centers need more data to have a more comprehensive and beneficial learning model, and for this purpose, they need to collect data from data providers. On the other hand, data providers are cautious about delivering their datasets to inference centers in terms of privacy considerations. In this paper, by modifying the structure of the autoencoder, we present a method that manages the utility-privacy trade-off well. To be more precise, the data is first compressed using the encoder, then confidential and non-confidential features are separated and uncorrelated using the classifier. The confidential feature is appropriately combined with noise, and the non-confidential feature is enhanced, and at the end, data with the original data format is produced by the decoder. The proposed architecture also allows data providers to set the level of privacy required for confidential features. The proposed method has been examined for both image and categorical databases, and the results show a significant performance improvement compared to previous methods.
Weakly supervised segmentation with point annotations for histopathology images via contrast-based variational model
Apr 07, 2023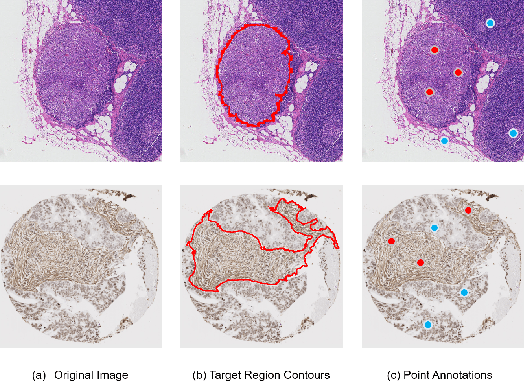
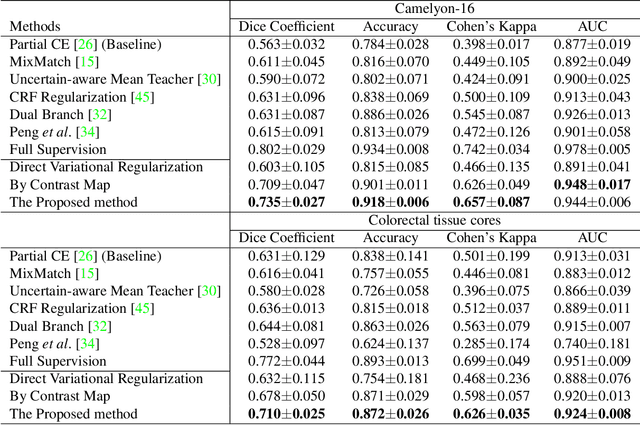
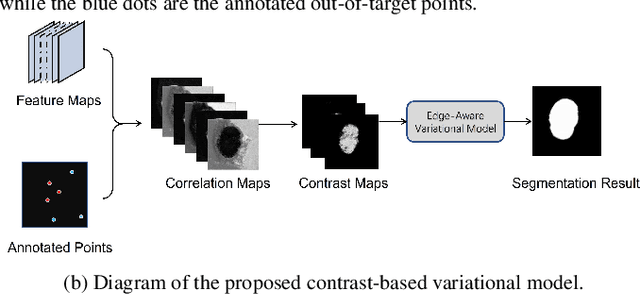
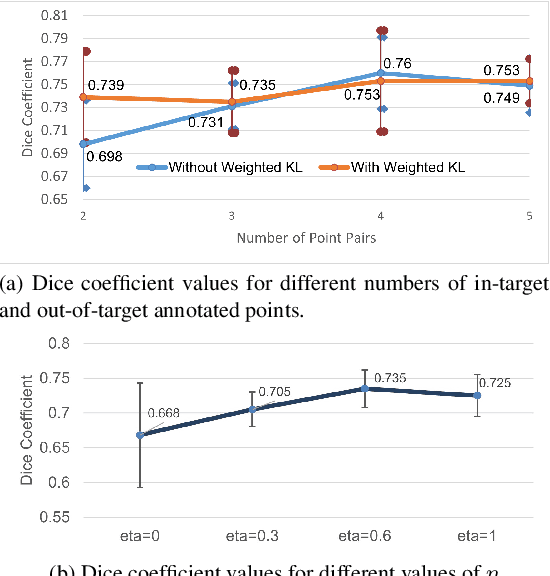
Image segmentation is a fundamental task in the field of imaging and vision. Supervised deep learning for segmentation has achieved unparalleled success when sufficient training data with annotated labels are available. However, annotation is known to be expensive to obtain, especially for histopathology images where the target regions are usually with high morphology variations and irregular shapes. Thus, weakly supervised learning with sparse annotations of points is promising to reduce the annotation workload. In this work, we propose a contrast-based variational model to generate segmentation results, which serve as reliable complementary supervision to train a deep segmentation model for histopathology images. The proposed method considers the common characteristics of target regions in histopathology images and can be trained in an end-to-end manner. It can generate more regionally consistent and smoother boundary segmentation, and is more robust to unlabeled `novel' regions. Experiments on two different histology datasets demonstrate its effectiveness and efficiency in comparison to previous models.
Rethinking Alignment and Uniformity in Unsupervised Image Semantic Segmentation
Nov 26, 2022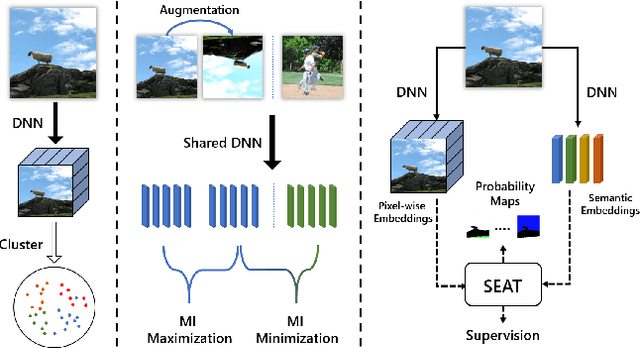

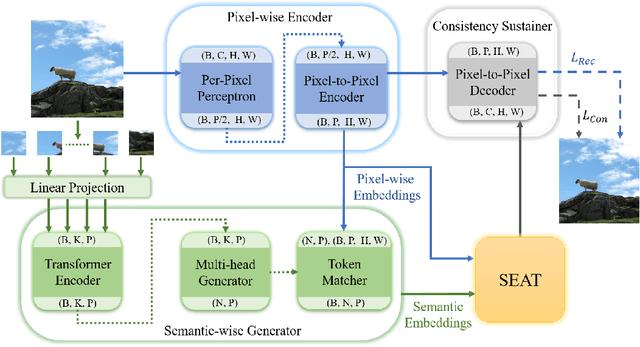
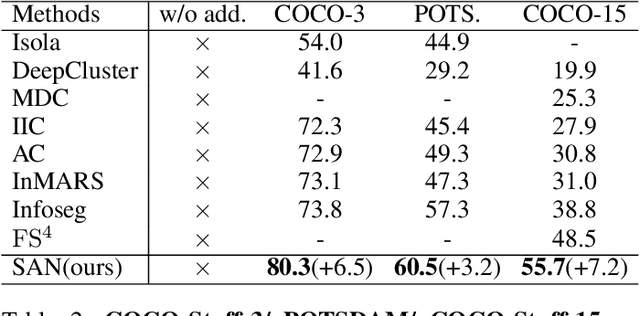
Unsupervised image semantic segmentation(UISS) aims to match low-level visual features with semantic-level representations without outer supervision. In this paper, we address the critical properties from the view of feature alignments and feature uniformity for UISS models. We also make a comparison between UISS and image-wise representation learning. Based on the analysis, we argue that the existing MI-based methods in UISS suffer from representation collapse. By this, we proposed a robust network called Semantic Attention Network(SAN), in which a new module Semantic Attention(SEAT) is proposed to generate pixel-wise and semantic features dynamically. Experimental results on multiple semantic segmentation benchmarks show that our unsupervised segmentation framework specializes in catching semantic representations, which outperforms all the unpretrained and even several pretrained methods.