 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Interaction-Aware Prompting for Zero-Shot Spatio-Temporal Action Detection
Apr 11, 2023

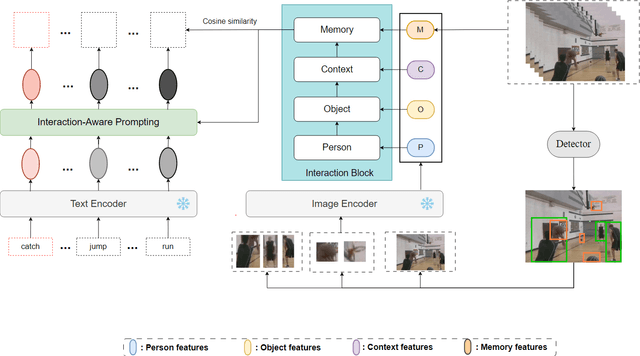

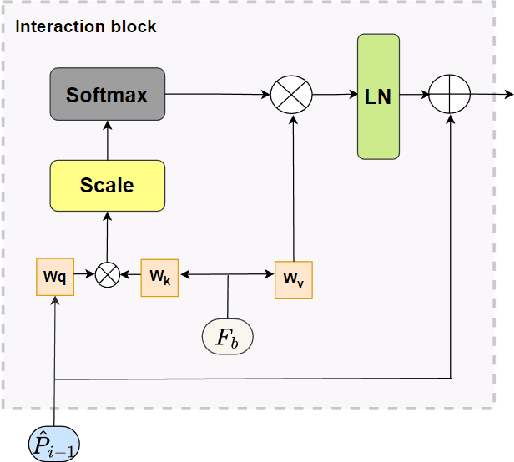
The goal of spatial-temporal action detection is to determine the time and place where each person's action occurs in a video and classify the corresponding action category. Most of the existing methods adopt fully-supervised learning, which requires a large amount of training data, making it very difficult to achieve zero-shot learning. In this paper, we propose to utilize a pre-trained visual-language model to extract the representative image and text features, and model the relationship between these features through different interaction modules to obtain the interaction feature. In addition, we use this feature to prompt each label to obtain more appropriate text features. Finally, we calculate the similarity between the interaction feature and the text feature for each label to determine the action category. Our experiments on J-HMDB and UCF101-24 datasets demonstrate that the proposed interaction module and prompting make the visual-language features better aligned, thus achieving excellent accuracy for zero-shot spatio-temporal action detection. The code will be released upon acceptance.
The MONET dataset: Multimodal drone thermal dataset recorded in rural scenarios
Apr 11, 2023
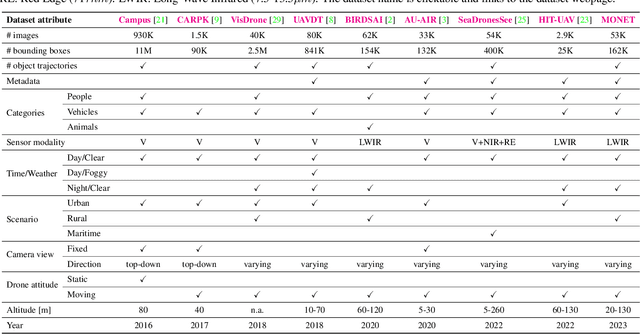
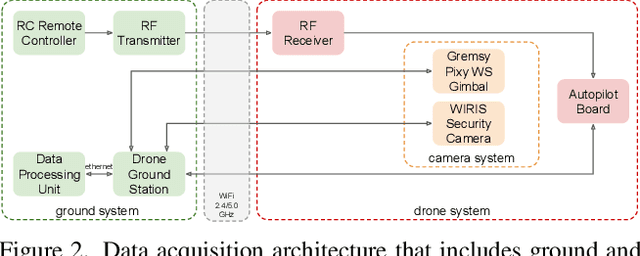
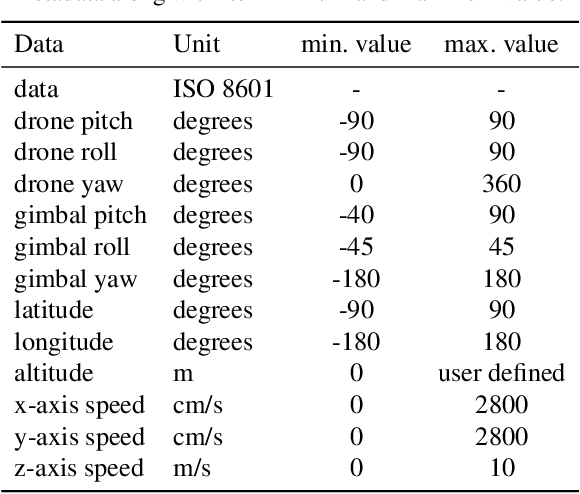
We present MONET, a new multimodal dataset captured using a thermal camera mounted on a drone that flew over rural areas, and recorded human and vehicle activities. We captured MONET to study the problem of object localisation and behaviour understanding of targets undergoing large-scale variations and being recorded from different and moving viewpoints. Target activities occur in two different land sites, each with unique scene structures and cluttered backgrounds. MONET consists of approximately 53K images featuring 162K manually annotated bounding boxes. Each image is timestamp-aligned with drone metadata that includes information about attitudes, speed, altitude, and GPS coordinates. MONET is different from previous thermal drone datasets because it features multimodal data, including rural scenes captured with thermal cameras containing both person and vehicle targets, along with trajectory information and metadata. We assessed the difficulty of the dataset in terms of transfer learning between the two sites and evaluated nine object detection algorithms to identify the open challenges associated with this type of data. Project page: https://github.com/fabiopoiesi/monet_dataset.
Boosting Cross-task Transferability of Adversarial Patches with Visual Relations
Apr 11, 2023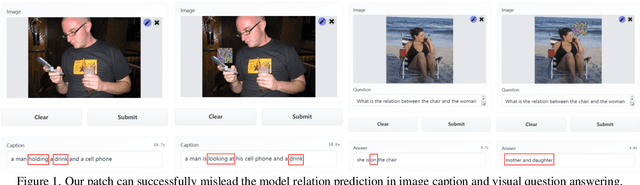
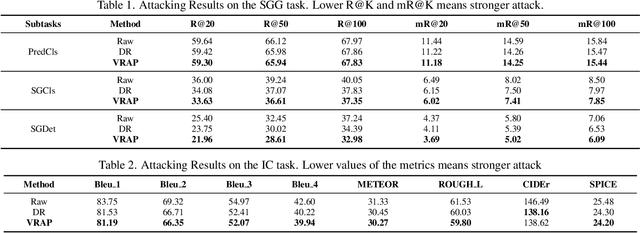
The transferability of adversarial examples is a crucial aspect of evaluating the robustness of deep learning systems, particularly in black-box scenarios. Although several methods have been proposed to enhance cross-model transferability, little attention has been paid to the transferability of adversarial examples across different tasks. This issue has become increasingly relevant with the emergence of foundational multi-task AI systems such as Visual ChatGPT, rendering the utility of adversarial samples generated by a single task relatively limited. Furthermore, these systems often entail inferential functions beyond mere recognition-like tasks. To address this gap, we propose a novel Visual Relation-based cross-task Adversarial Patch generation method called VRAP, which aims to evaluate the robustness of various visual tasks, especially those involving visual reasoning, such as Visual Question Answering and Image Captioning. VRAP employs scene graphs to combine object recognition-based deception with predicate-based relations elimination, thereby disrupting the visual reasoning information shared among inferential tasks. Our extensive experiments demonstrate that VRAP significantly surpasses previous methods in terms of black-box transferability across diverse visual reasoning tasks.
Pointless Global Bundle Adjustment With Relative Motions Hessians
Apr 11, 2023Bundle adjustment (BA) is the standard way to optimise camera poses and to produce sparse representations of a scene. However, as the number of camera poses and features grows, refinement through bundle adjustment becomes inefficient. Inspired by global motion averaging methods, we propose a new bundle adjustment objective which does not rely on image features' reprojection errors yet maintains precision on par with classical BA. Our method averages over relative motions while implicitly incorporating the contribution of the structure in the adjustment. To that end, we weight the objective function by local hessian matrices - a by-product of local bundle adjustments performed on relative motions (e.g., pairs or triplets) during the pose initialisation step. Such hessians are extremely rich as they encapsulate both the features' random errors and the geometric configuration between the cameras. These pieces of information propagated to the global frame help to guide the final optimisation in a more rigorous way. We argue that this approach is an upgraded version of the motion averaging approach and demonstrate its effectiveness on both photogrammetric datasets and computer vision benchmarks.
MOST: Multiple Object localization with Self-supervised Transformers for object discovery
Apr 11, 2023
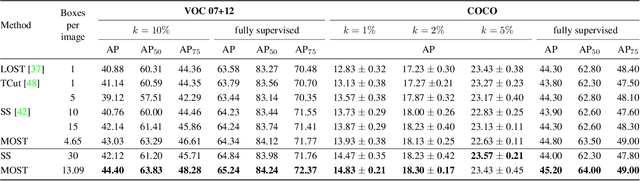
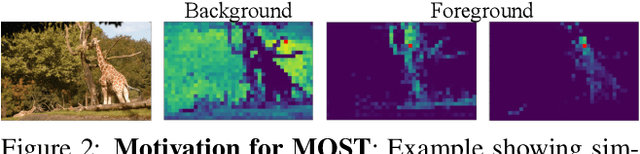
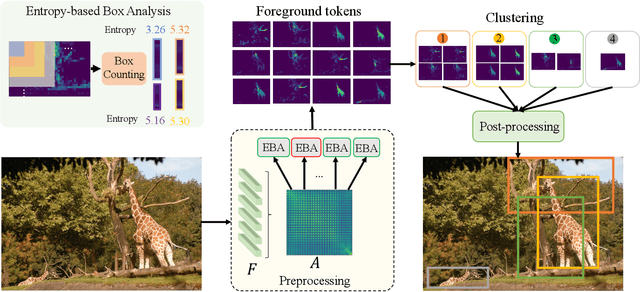
We tackle the challenging task of unsupervised object localization in this work. Recently, transformers trained with self-supervised learning have been shown to exhibit object localization properties without being trained for this task. In this work, we present Multiple Object localization with Self-supervised Transformers (MOST) that uses features of transformers trained using self-supervised learning to localize multiple objects in real world images. MOST analyzes the similarity maps of the features using box counting; a fractal analysis tool to identify tokens lying on foreground patches. The identified tokens are then clustered together, and tokens of each cluster are used to generate bounding boxes on foreground regions. Unlike recent state-of-the-art object localization methods, MOST can localize multiple objects per image and outperforms SOTA algorithms on several object localization and discovery benchmarks on PASCAL-VOC 07, 12 and COCO20k datasets. Additionally, we show that MOST can be used for self-supervised pre-training of object detectors, and yields consistent improvements on fully, semi-supervised object detection and unsupervised region proposal generation.
FindVehicle and VehicleFinder: A NER dataset for natural language-based vehicle retrieval and a keyword-based cross-modal vehicle retrieval system
Apr 21, 2023
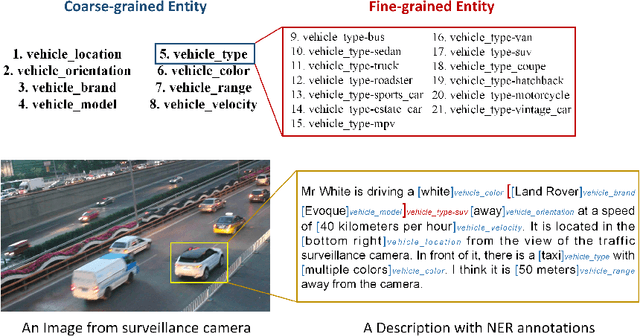
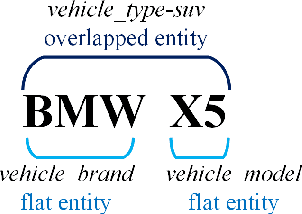
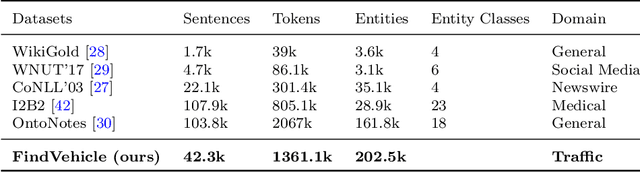
Natural language (NL) based vehicle retrieval is a task aiming to retrieve a vehicle that is most consistent with a given NL query from among all candidate vehicles. Because NL query can be easily obtained, such a task has a promising prospect in building an interactive intelligent traffic system (ITS). Current solutions mainly focus on extracting both text and image features and mapping them to the same latent space to compare the similarity. However, existing methods usually use dependency analysis or semantic role-labelling techniques to find keywords related to vehicle attributes. These techniques may require a lot of pre-processing and post-processing work, and also suffer from extracting the wrong keyword when the NL query is complex. To tackle these problems and simplify, we borrow the idea from named entity recognition (NER) and construct FindVehicle, a NER dataset in the traffic domain. It has 42.3k labelled NL descriptions of vehicle tracks, containing information such as the location, orientation, type and colour of the vehicle. FindVehicle also adopts both overlapping entities and fine-grained entities to meet further requirements. To verify its effectiveness, we propose a baseline NL-based vehicle retrieval model called VehicleFinder. Our experiment shows that by using text encoders pre-trained by FindVehicle, VehicleFinder achieves 87.7\% precision and 89.4\% recall when retrieving a target vehicle by text command on our homemade dataset based on UA-DETRAC. The time cost of VehicleFinder is 279.35 ms on one ARM v8.2 CPU and 93.72 ms on one RTX A4000 GPU, which is much faster than the Transformer-based system. The dataset is open-source via the link https://github.com/GuanRunwei/FindVehicle, and the implementation can be found via the link https://github.com/GuanRunwei/VehicleFinder-CTIM.
Discovering Class-Specific GAN Controls for Semantic Image Synthesis
Dec 02, 2022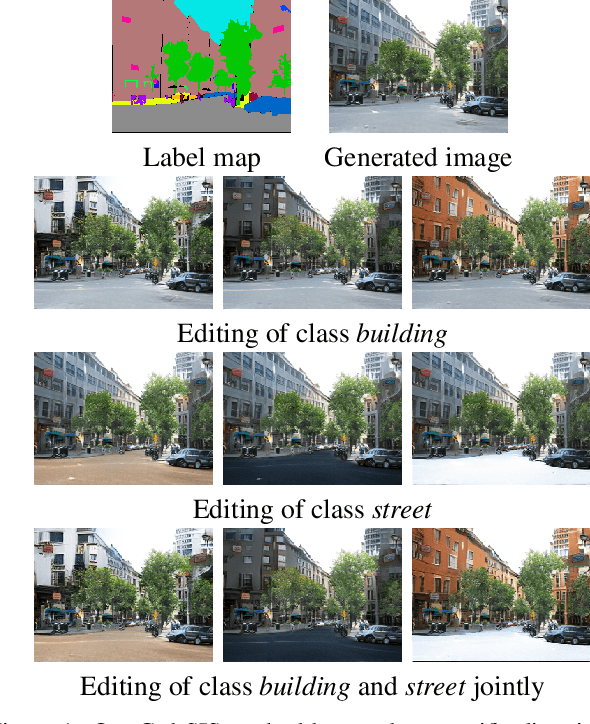

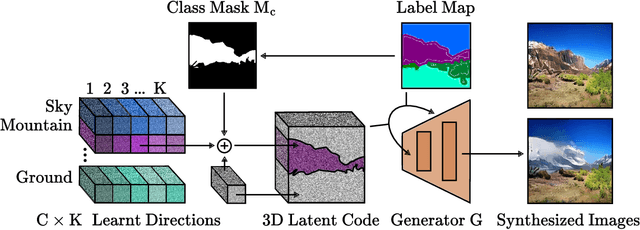
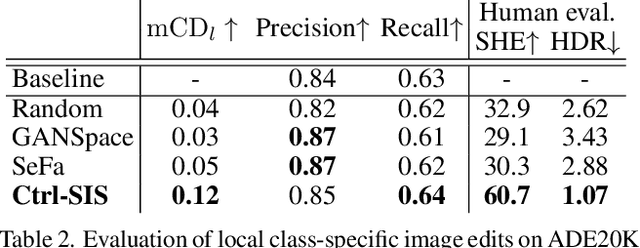
Prior work has extensively studied the latent space structure of GANs for unconditional image synthesis, enabling global editing of generated images by the unsupervised discovery of interpretable latent directions. However, the discovery of latent directions for conditional GANs for semantic image synthesis (SIS) has remained unexplored. In this work, we specifically focus on addressing this gap. We propose a novel optimization method for finding spatially disentangled class-specific directions in the latent space of pretrained SIS models. We show that the latent directions found by our method can effectively control the local appearance of semantic classes, e.g., changing their internal structure, texture or color independently from each other. Visual inspection and quantitative evaluation of the discovered GAN controls on various datasets demonstrate that our method discovers a diverse set of unique and semantically meaningful latent directions for class-specific edits.
Nighttime Smartphone Reflective Flare Removal Using Optical Center Symmetry Prior
Mar 27, 2023
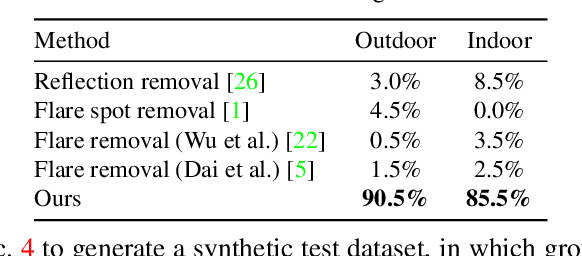
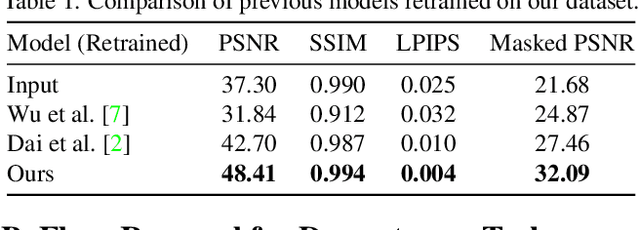
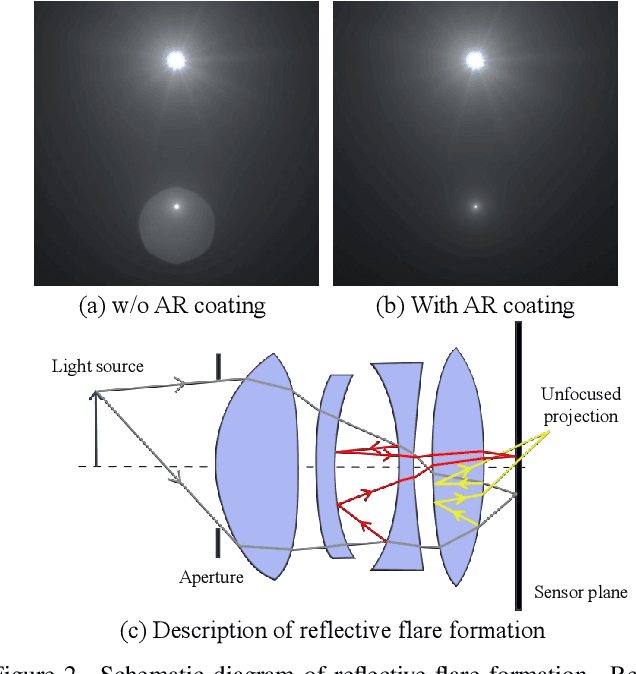
Reflective flare is a phenomenon that occurs when light reflects inside lenses, causing bright spots or a "ghosting effect" in photos, which can impact their quality. Eliminating reflective flare is highly desirable but challenging. Many existing methods rely on manually designed features to detect these bright spots, but they often fail to identify reflective flares created by various types of light and may even mistakenly remove the light sources in scenarios with multiple light sources. To address these challenges, we propose an optical center symmetry prior, which suggests that the reflective flare and light source are always symmetrical around the lens's optical center. This prior helps to locate the reflective flare's proposal region more accurately and can be applied to most smartphone cameras. Building on this prior, we create the first reflective flare removal dataset called BracketFlare, which contains diverse and realistic reflective flare patterns. We use continuous bracketing to capture the reflective flare pattern in the underexposed image and combine it with a normally exposed image to synthesize a pair of flare-corrupted and flare-free images. With the dataset, neural networks can be trained to remove the reflective flares effectively. Extensive experiments demonstrate the effectiveness of our method on both synthetic and real-world datasets.
CCLAP: Controllable Chinese Landscape Painting Generation via Latent Diffusion Model
Apr 09, 2023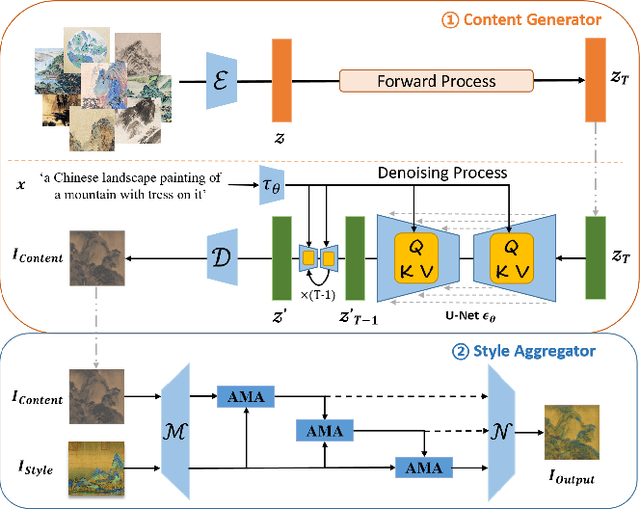
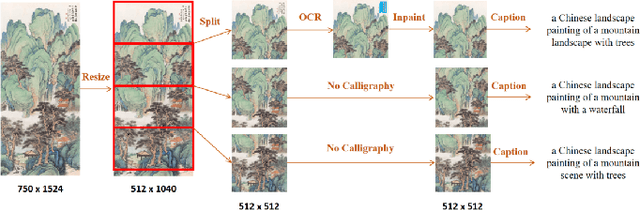


With the development of deep generative models, recent years have seen great success of Chinese landscape painting generation. However, few works focus on controllable Chinese landscape painting generation due to the lack of data and limited modeling capabilities. In this work, we propose a controllable Chinese landscape painting generation method named CCLAP, which can generate painting with specific content and style based on Latent Diffusion Model. Specifically, it consists of two cascaded modules, i.e., content generator and style aggregator. The content generator module guarantees the content of generated paintings specific to the input text. While the style aggregator module is to generate paintings of a style corresponding to a reference image. Moreover, a new dataset of Chinese landscape paintings named CLAP is collected for comprehensive evaluation. Both the qualitative and quantitative results demonstrate that our method achieves state-of-the-art performance, especially in artfully-composed and artistic conception. Codes are available at https://github.com/Robin-WZQ/CCLAP.
Multi-Exposure HDR Composition by Gated Swin Transformer
Mar 15, 2023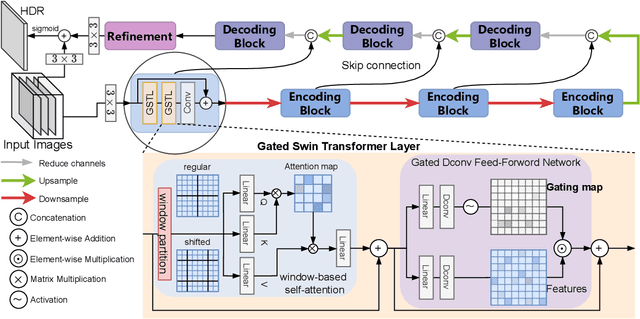
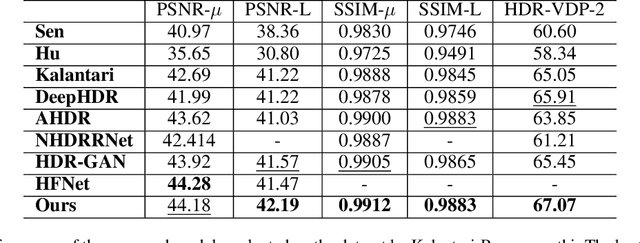


Fusing a sequence of perfectly aligned images captured at various exposures, has shown great potential to approach High Dynamic Range (HDR) imaging by sensors with limited dynamic range. However, in the presence of large motion of scene objects or the camera, mis-alignment is almost inevitable and leads to the notorious ``ghost'' artifacts. Besides, factors such as the noise in the dark region or color saturation in the over-bright region may also fail to fill local image details to the HDR image. This paper provides a novel multi-exposure fusion model based on Swin Transformer. Particularly, we design feature selection gates, which are integrated with the feature extraction layers to detect outliers and block them from HDR image synthesis. To reconstruct the missing local details by well-aligned and properly-exposed regions, we exploit the long distance contextual dependency in the exposure-space pyramid by the self-attention mechanism. Extensive numerical and visual evaluation has been conducted on a variety of benchmark datasets. The experiments show that our model achieves the accuracy on par with current top performing multi-exposure HDR imaging models, while gaining higher efficiency.