 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Bridging Component Learning with Degradation Modelling for Blind Image Super-Resolution
Dec 03, 2022

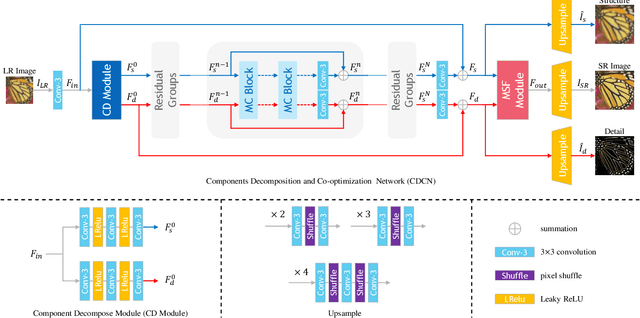
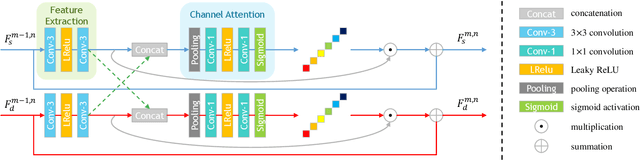
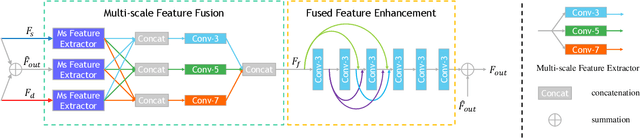
Convolutional Neural Network (CNN)-based image super-resolution (SR) has exhibited impressive success on known degraded low-resolution (LR) images. However, this type of approach is hard to hold its performance in practical scenarios when the degradation process is unknown. Despite existing blind SR methods proposed to solve this problem using blur kernel estimation, the perceptual quality and reconstruction accuracy are still unsatisfactory. In this paper, we analyze the degradation of a high-resolution (HR) image from image intrinsic components according to a degradation-based formulation model. We propose a components decomposition and co-optimization network (CDCN) for blind SR. Firstly, CDCN decomposes the input LR image into structure and detail components in feature space. Then, the mutual collaboration block (MCB) is presented to exploit the relationship between both two components. In this way, the detail component can provide informative features to enrich the structural context and the structure component can carry structural context for better detail revealing via a mutual complementary manner. After that, we present a degradation-driven learning strategy to jointly supervise the HR image detail and structure restoration process. Finally, a multi-scale fusion module followed by an upsampling layer is designed to fuse the structure and detail features and perform SR reconstruction. Empowered by such degradation-based components decomposition, collaboration, and mutual optimization, we can bridge the correlation between component learning and degradation modelling for blind SR, thereby producing SR results with more accurate textures. Extensive experiments on both synthetic SR datasets and real-world images show that the proposed method achieves the state-of-the-art performance compared to existing methods.
Learnable Blur Kernel for Single-Image Defocus Deblurring in the Wild
Nov 25, 2022
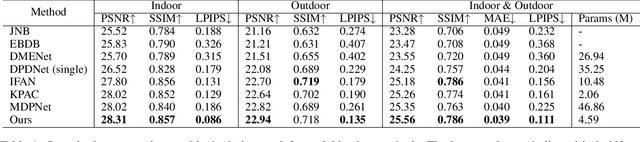
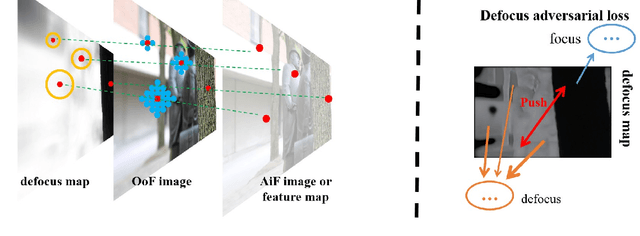
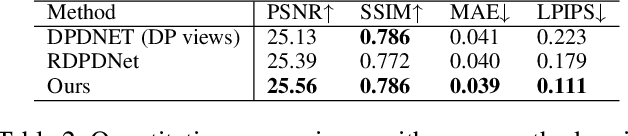
Recent research showed that the dual-pixel sensor has made great progress in defocus map estimation and image defocus deblurring. However, extracting real-time dual-pixel views is troublesome and complex in algorithm deployment. Moreover, the deblurred image generated by the defocus deblurring network lacks high-frequency details, which is unsatisfactory in human perception. To overcome this issue, we propose a novel defocus deblurring method that uses the guidance of the defocus map to implement image deblurring. The proposed method consists of a learnable blur kernel to estimate the defocus map, which is an unsupervised method, and a single-image defocus deblurring generative adversarial network (DefocusGAN) for the first time. The proposed network can learn the deblurring of different regions and recover realistic details. We propose a defocus adversarial loss to guide this training process. Competitive experimental results confirm that with a learnable blur kernel, the generated defocus map can achieve results comparable to supervised methods. In the single-image defocus deblurring task, the proposed method achieves state-of-the-art results, especially significant improvements in perceptual quality, where PSNR reaches 25.56 dB and LPIPS reaches 0.111.
HiLo: Exploiting High Low Frequency Relations for Unbiased Panoptic Scene Graph Generation
Mar 28, 2023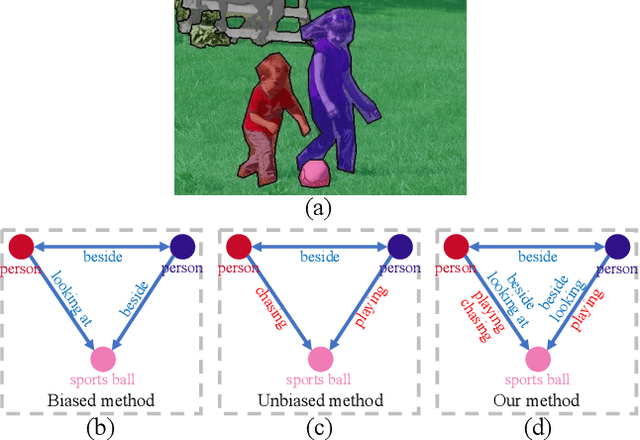
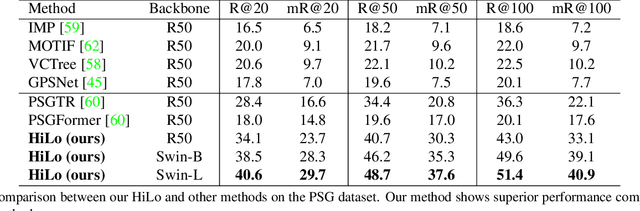
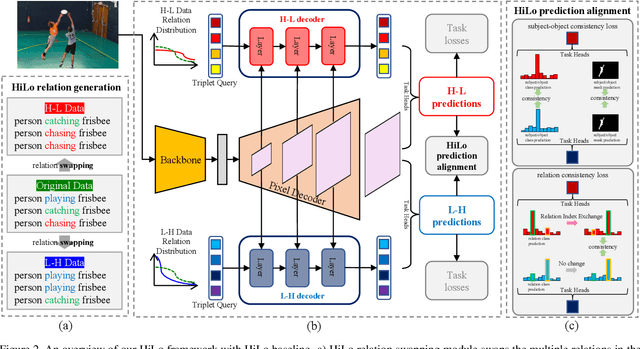
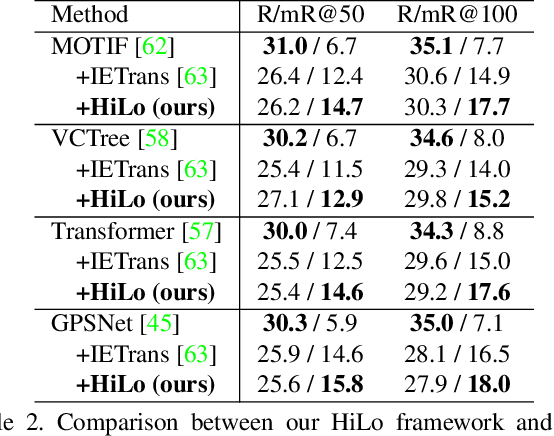
Panoptic Scene Graph generation (PSG) is a recently proposed task in image scene understanding that aims to segment the image and extract triplets of subjects, objects and their relations to build a scene graph. This task is particularly challenging for two reasons. First, it suffers from a long-tail problem in its relation categories, making naive biased methods more inclined to high-frequency relations. Existing unbiased methods tackle the long-tail problem by data/loss rebalancing to favor low-frequency relations. Second, a subject-object pair can have two or more semantically overlapping relations. While existing methods favor one over the other, our proposed HiLo framework lets different network branches specialize on low and high frequency relations, enforce their consistency and fuse the results. To the best of our knowledge we are the first to propose an explicitly unbiased PSG method. In extensive experiments we show that our HiLo framework achieves state-of-the-art results on the PSG task. We also apply our method to the Scene Graph Generation task that predicts boxes instead of masks and see improvements over all baseline methods.
Large-scale pretraining on pathological images for fine-tuning of small pathological benchmarks
Mar 28, 2023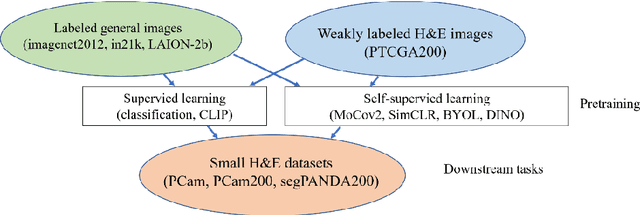
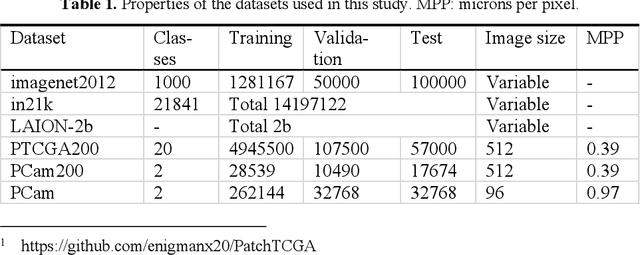
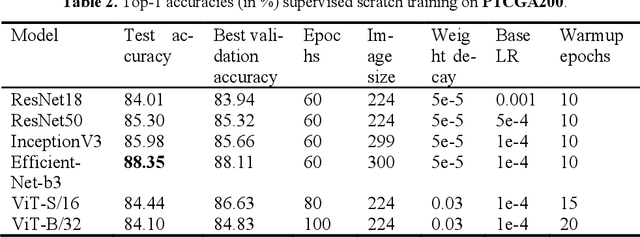

Pretraining a deep learning model on large image datasets is a standard step before fine-tuning the model on small targeted datasets. The large dataset is usually general images (e.g. imagenet2012) while the small dataset can be specialized datasets that have different distributions from the large dataset. However, this 'large-to-small' strategy is not well-validated when the large dataset is specialized and has a similar distribution to small datasets. We newly compiled three hematoxylin and eosin-stained image datasets, one large (PTCGA200) and two magnification-adjusted small datasets (PCam200 and segPANDA200). Major deep learning models were trained with supervised and self-supervised learning methods and fine-tuned on the small datasets for tumor classification and tissue segmentation benchmarks. ResNet50 pretrained with MoCov2, SimCLR, and BYOL on PTCGA200 was better than imagenet2012 pretraining when fine-tuned on PTCGA200 (accuracy of 83.94%, 86.41%, 84.91%, and 82.72%, respectively). ResNet50 pre-trained on PTCGA200 with MoCov2 exceeded the COCOtrain2017-pretrained baseline and was the best in ResNet50 for the tissue segmentation benchmark (mIoU of 63.53% and 63.22%). We found re-training imagenet-pretrained models (ResNet50, BiT-M-R50x1, and ViT-S/16) on PTCGA200 improved downstream benchmarks.
Constraining Multi-scale Pairwise Features between Encoder and Decoder Using Contrastive Learning for Unpaired Image-to-Image Translation
Nov 20, 2022
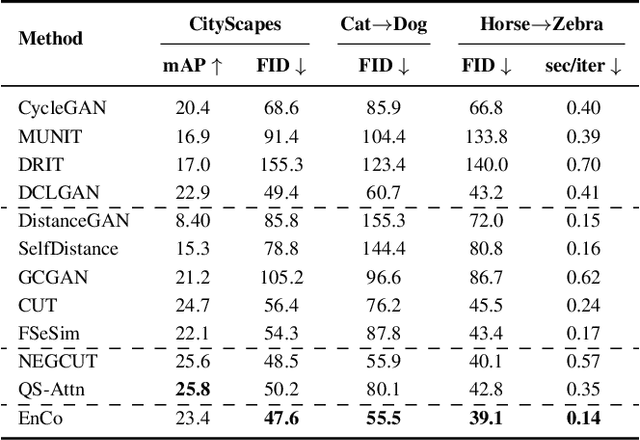


Contrastive learning (CL) has shown great potential in image-to-image translation (I2I). Current CL-based I2I methods usually re-exploit the encoder of the generator to maximize the mutual information between the input and generated images, which does not exert an active effect on the decoder part. In addition, though negative samples play a crucial role in CL, most existing methods adopt a random sampling strategy, which may be less effective. In this paper, we rethink the CL paradigm in the unpaired I2I tasks from two perspectives and propose a new one-sided image translation framework called EnCo. First, we present an explicit constraint on the multi-scale pairwise features between the encoder and decoder of the generator to guarantee the semantic consistency of the input and generated images. Second, we propose a discriminative attention-guided negative sampling strategy to replace the random negative sampling, which significantly improves the performance of the generative model with an almost negligible computational overhead. Compared with existing methods, EnCo acts more effective and efficient. Extensive experiments on several popular I2I datasets demonstrate the effectiveness and advantages of our proposed approach, and we achieve several state-of-the-art compared to previous methods.
Robust Split Federated Learning for U-shaped Medical Image Networks
Dec 13, 2022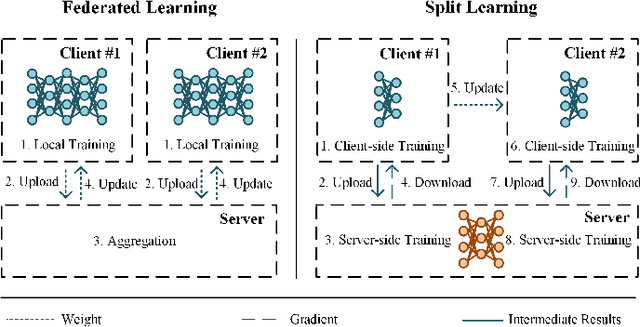

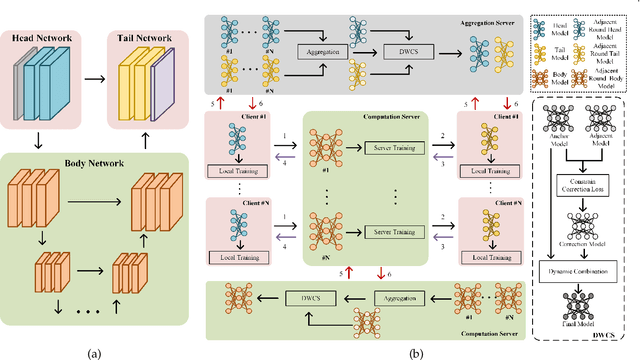
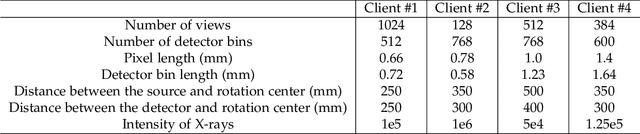
U-shaped networks are widely used in various medical image tasks, such as segmentation, restoration and reconstruction, but most of them usually rely on centralized learning and thus ignore privacy issues. To address the privacy concerns, federated learning (FL) and split learning (SL) have attracted increasing attention. However, it is hard for both FL and SL to balance the local computational cost, model privacy and parallel training simultaneously. To achieve this goal, in this paper, we propose Robust Split Federated Learning (RoS-FL) for U-shaped medical image networks, which is a novel hybrid learning paradigm of FL and SL. Previous works cannot preserve the data privacy, including the input, model parameters, label and output simultaneously. To effectively deal with all of them, we design a novel splitting method for U-shaped medical image networks, which splits the network into three parts hosted by different parties. Besides, the distributed learning methods usually suffer from a drift between local and global models caused by data heterogeneity. Based on this consideration, we propose a dynamic weight correction strategy (\textbf{DWCS}) to stabilize the training process and avoid model drift. Specifically, a weight correction loss is designed to quantify the drift between the models from two adjacent communication rounds. By minimizing this loss, a correction model is obtained. Then we treat the weighted sum of correction model and final round models as the result. The effectiveness of the proposed RoS-FL is supported by extensive experimental results on different tasks. Related codes will be released at https://github.com/Zi-YuanYang/RoS-FL.
OneFormer: One Transformer to Rule Universal Image Segmentation
Nov 10, 2022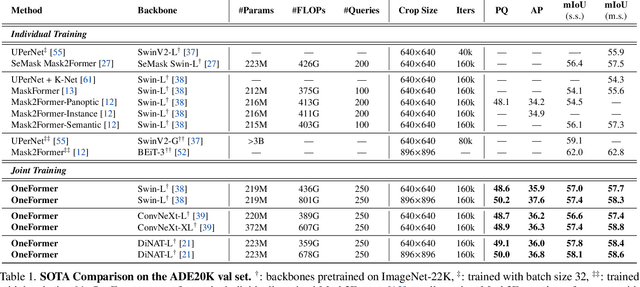
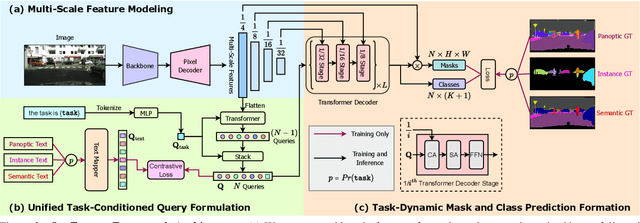
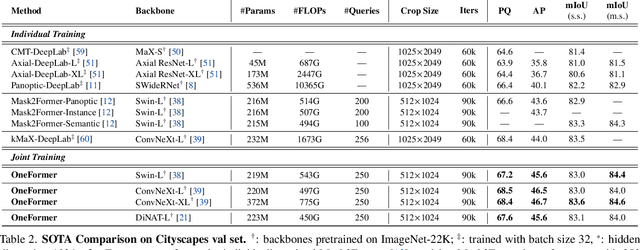
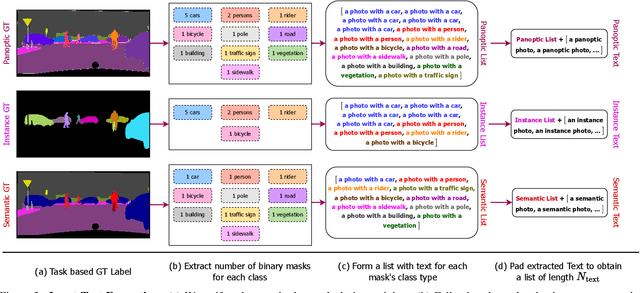
Universal Image Segmentation is not a new concept. Past attempts to unify image segmentation in the last decades include scene parsing, panoptic segmentation, and, more recently, new panoptic architectures. However, such panoptic architectures do not truly unify image segmentation because they need to be trained individually on the semantic, instance, or panoptic segmentation to achieve the best performance. Ideally, a truly universal framework should be trained only once and achieve SOTA performance across all three image segmentation tasks. To that end, we propose OneFormer, a universal image segmentation framework that unifies segmentation with a multi-task train-once design. We first propose a task-conditioned joint training strategy that enables training on ground truths of each domain (semantic, instance, and panoptic segmentation) within a single multi-task training process. Secondly, we introduce a task token to condition our model on the task at hand, making our model task-dynamic to support multi-task training and inference. Thirdly, we propose using a query-text contrastive loss during training to establish better inter-task and inter-class distinctions. Notably, our single OneFormer model outperforms specialized Mask2Former models across all three segmentation tasks on ADE20k, CityScapes, and COCO, despite the latter being trained on each of the three tasks individually with three times the resources. With new ConvNeXt and DiNAT backbones, we observe even more performance improvement. We believe OneFormer is a significant step towards making image segmentation more universal and accessible. To support further research, we open-source our code and models at https://github.com/SHI-Labs/OneFormer
DehazeNeRF: Multiple Image Haze Removal and 3D Shape Reconstruction using Neural Radiance Fields
Mar 20, 2023
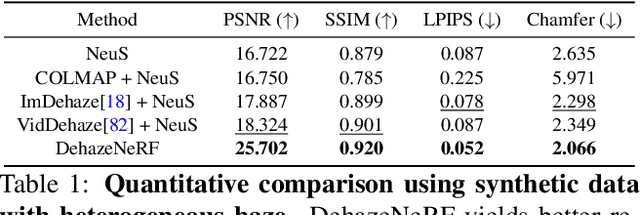
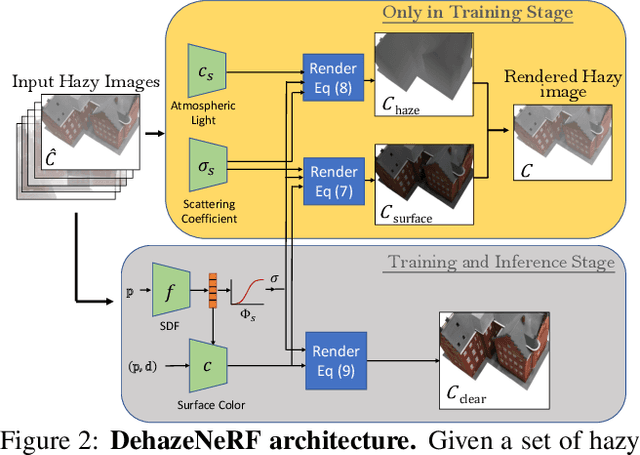
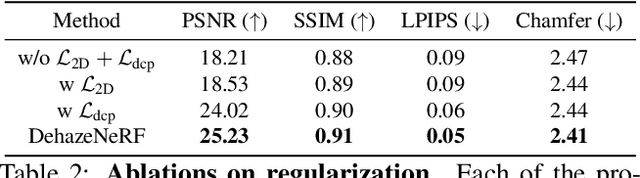
Neural radiance fields (NeRFs) have demonstrated state-of-the-art performance for 3D computer vision tasks, including novel view synthesis and 3D shape reconstruction. However, these methods fail in adverse weather conditions. To address this challenge, we introduce DehazeNeRF as a framework that robustly operates in hazy conditions. DehazeNeRF extends the volume rendering equation by adding physically realistic terms that model atmospheric scattering. By parameterizing these terms using suitable networks that match the physical properties, we introduce effective inductive biases, which, together with the proposed regularizations, allow DehazeNeRF to demonstrate successful multi-view haze removal, novel view synthesis, and 3D shape reconstruction where existing approaches fail.
Sketch-Guided Text-to-Image Diffusion Models
Nov 24, 2022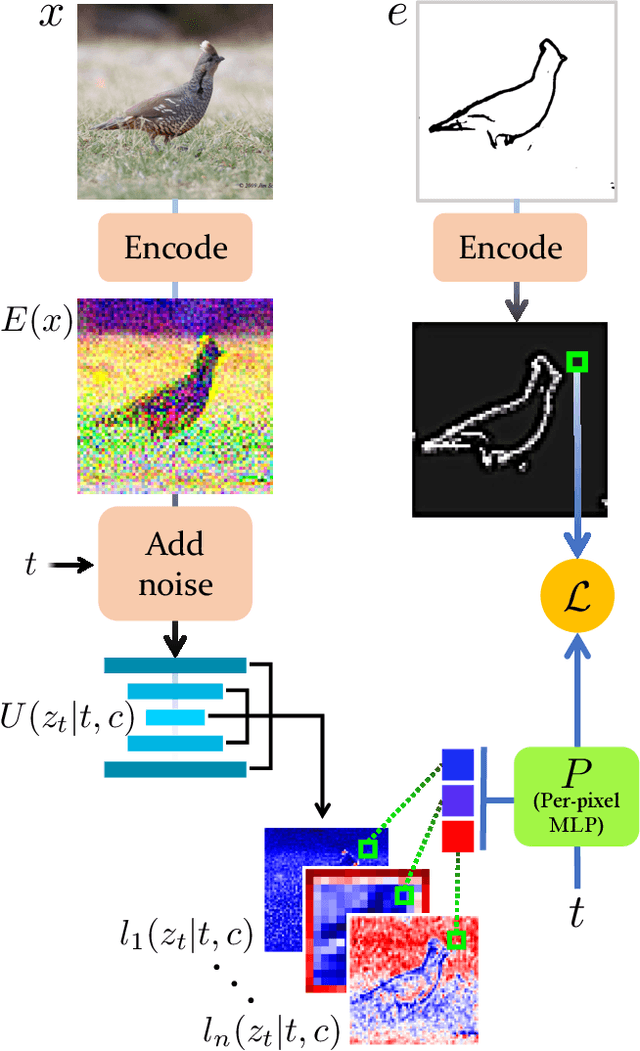
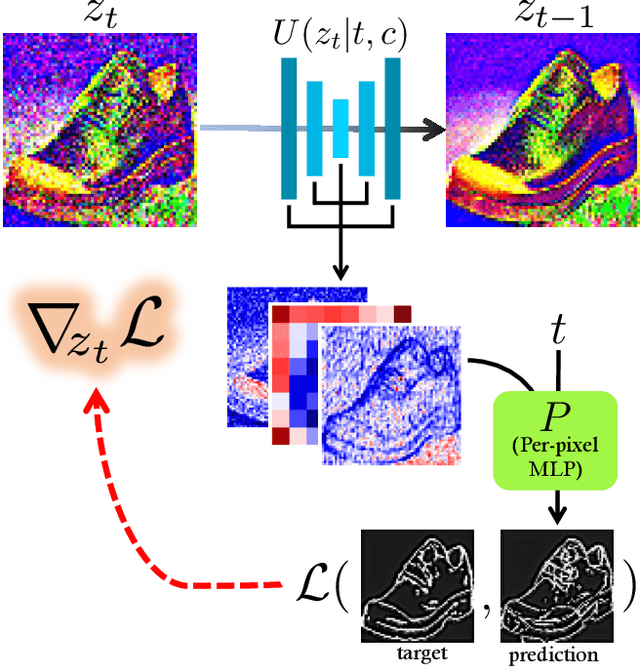

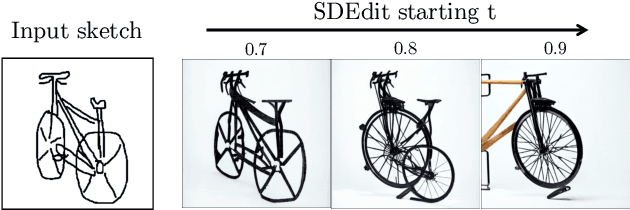
Text-to-Image models have introduced a remarkable leap in the evolution of machine learning, demonstrating high-quality synthesis of images from a given text-prompt. However, these powerful pretrained models still lack control handles that can guide spatial properties of the synthesized images. In this work, we introduce a universal approach to guide a pretrained text-to-image diffusion model, with a spatial map from another domain (e.g., sketch) during inference time. Unlike previous works, our method does not require to train a dedicated model or a specialized encoder for the task. Our key idea is to train a Latent Guidance Predictor (LGP) - a small, per-pixel, Multi-Layer Perceptron (MLP) that maps latent features of noisy images to spatial maps, where the deep features are extracted from the core Denoising Diffusion Probabilistic Model (DDPM) network. The LGP is trained only on a few thousand images and constitutes a differential guiding map predictor, over which the loss is computed and propagated back to push the intermediate images to agree with the spatial map. The per-pixel training offers flexibility and locality which allows the technique to perform well on out-of-domain sketches, including free-hand style drawings. We take a particular focus on the sketch-to-image translation task, revealing a robust and expressive way to generate images that follow the guidance of a sketch of arbitrary style or domain. Project page: sketch-guided-diffusion.github.io
CLIP-ReID: Exploiting Vision-Language Model for Image Re-Identification without Concrete Text Labels
Dec 07, 2022
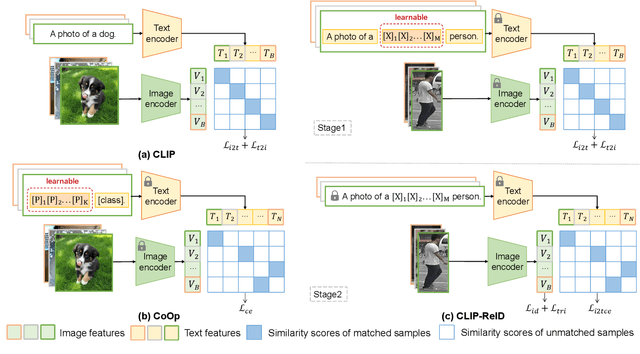
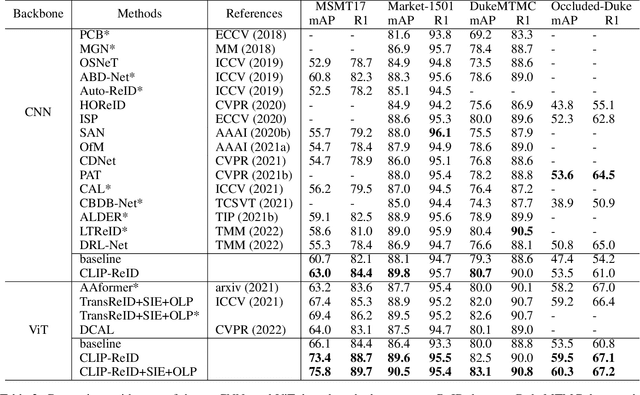
Pre-trained vision-language models like CLIP have recently shown superior performances on various downstream tasks, including image classification and segmentation. However, in fine-grained image re-identification (ReID), the labels are indexes, lacking concrete text descriptions. Therefore, it remains to be determined how such models could be applied to these tasks. This paper first finds out that simply fine-tuning the visual model initialized by the image encoder in CLIP, has already obtained competitive performances in various ReID tasks. Then we propose a two-stage strategy to facilitate a better visual representation. The key idea is to fully exploit the cross-modal description ability in CLIP through a set of learnable text tokens for each ID and give them to the text encoder to form ambiguous descriptions. In the first training stage, image and text encoders from CLIP keep fixed, and only the text tokens are optimized from scratch by the contrastive loss computed within a batch. In the second stage, the ID-specific text tokens and their encoder become static, providing constraints for fine-tuning the image encoder. With the help of the designed loss in the downstream task, the image encoder is able to represent data as vectors in the feature embedding accurately. The effectiveness of the proposed strategy is validated on several datasets for the person or vehicle ReID tasks. Code is available at https://github.com/Syliz517/CLIP-ReID.