 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
IconShop: Text-Based Vector Icon Synthesis with Autoregressive Transformers
Apr 27, 2023

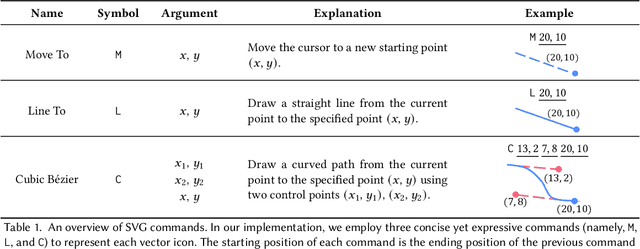
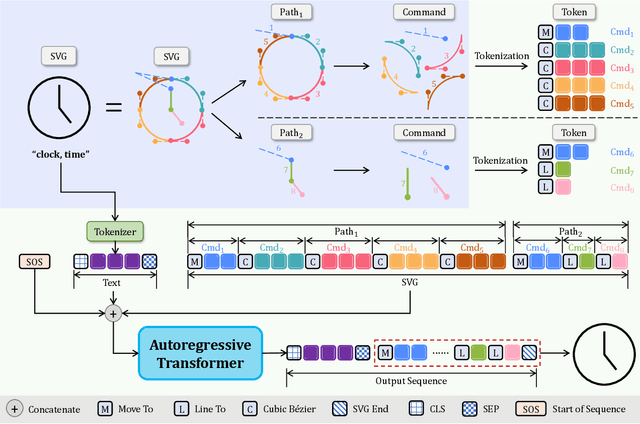
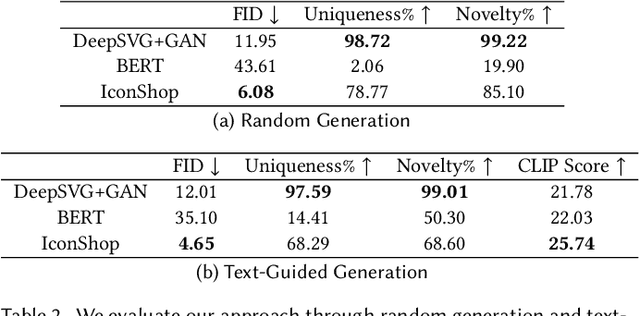
Scalable Vector Graphics (SVG) is a prevalent vector image format with good support for interactivity and animation. Despite such appealing characteristics, it is generally challenging for users to create their own SVG content because of the long learning curve to comprehend SVG grammars or acquaint themselves with professional editing software. Recent progress in text-to-image generation has inspired researchers to explore image-based icon synthesis (i.e., text -> raster image -> vector image) via differential rendering and language-based icon synthesis (i.e., text -> vector image script) via the "zero-shot" capabilities of large language models. However, these methods may suffer from several limitations regarding generation quality, diversity, flexibility, and speed. In this paper, we introduce IconShop, a text-guided vector icon synthesis method using an autoregressive transformer. The key to success of our approach is to sequentialize and tokenize the SVG paths (and textual descriptions) into a uniquely decodable command sequence. With such a single sequence as input, we are able to fully exploit the sequence learning power of autoregressive transformers, while enabling various icon synthesis and manipulation tasks. Through standard training to predict the next token on a large-scale icon dataset accompanied by textural descriptions, the proposed IconShop consistently exhibits better icon synthesis performance than existing image-based and language-based methods both quantitatively (using the FID and CLIP score) and qualitatively (through visual inspection). Meanwhile, we observe a dramatic improvement in generation diversity, which is supported by objective measures (Uniqueness and Novelty). More importantly, we demonstrate the flexibility of IconShop with two novel icon manipulation tasks - text-guided icon infilling, and text-combined icon synthesis.
Topology-Aware Focal Loss for 3D Image Segmentation
Apr 24, 2023The efficacy of segmentation algorithms is frequently compromised by topological errors like overlapping regions, disrupted connections, and voids. To tackle this problem, we introduce a novel loss function, namely Topology-Aware Focal Loss (TAFL), that incorporates the conventional Focal Loss with a topological constraint term based on the Wasserstein distance between the ground truth and predicted segmentation masks' persistence diagrams. By enforcing identical topology as the ground truth, the topological constraint can effectively resolve topological errors, while Focal Loss tackles class imbalance. We begin by constructing persistence diagrams from filtered cubical complexes of the ground truth and predicted segmentation masks. We subsequently utilize the Sinkhorn-Knopp algorithm to determine the optimal transport plan between the two persistence diagrams. The resultant transport plan minimizes the cost of transporting mass from one distribution to the other and provides a mapping between the points in the two persistence diagrams. We then compute the Wasserstein distance based on this travel plan to measure the topological dissimilarity between the ground truth and predicted masks. We evaluate our approach by training a 3D U-Net with the MICCAI Brain Tumor Segmentation (BraTS) challenge validation dataset, which requires accurate segmentation of 3D MRI scans that integrate various modalities for the precise identification and tracking of malignant brain tumors. Then, we demonstrate that the quality of segmentation performance is enhanced by regularizing the focal loss through the addition of a topological constraint as a penalty term.
Data-Driven Stochastic Motion Evaluation and Optimization with Image by Spatially-Aligned Temporal Encoding
Feb 10, 2023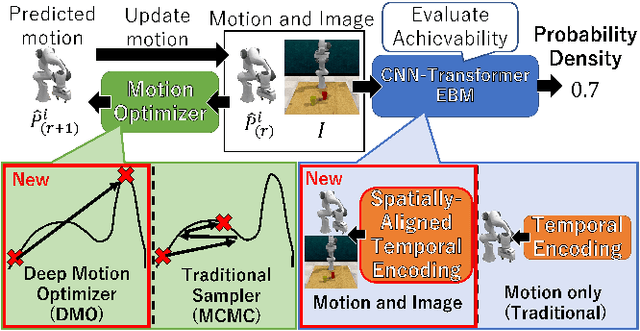
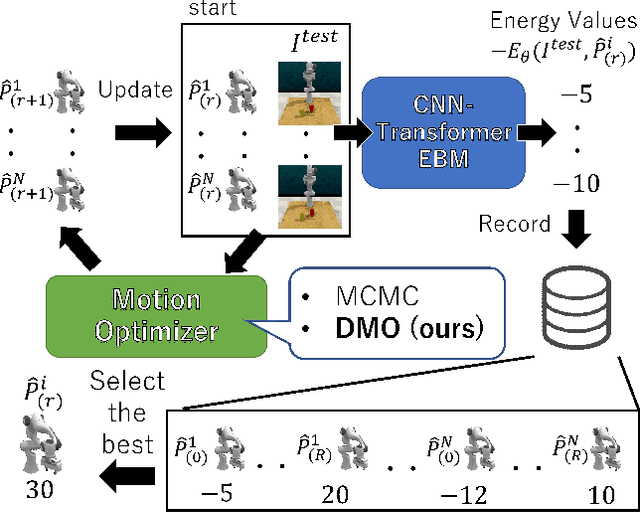
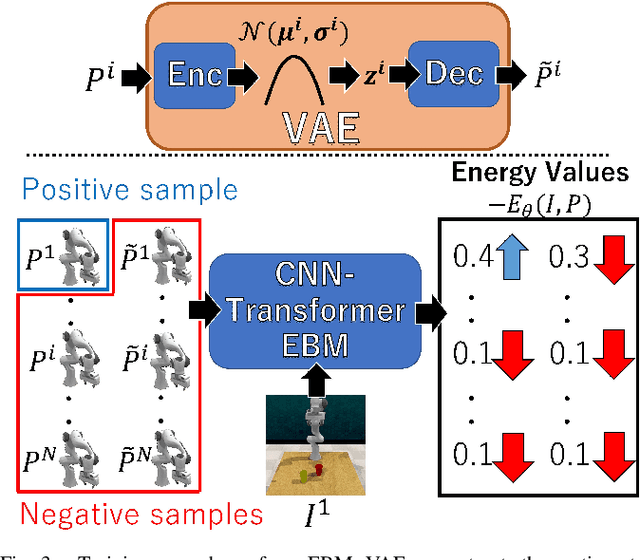
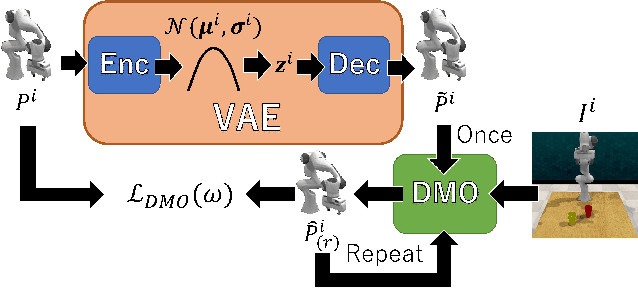
This paper proposes a probabilistic motion prediction method for long motions. The motion is predicted so that it accomplishes a task from the initial state observed in the given image. While our method evaluates the task achievability by the Energy-Based Model (EBM), previous EBMs are not designed for evaluating the consistency between different domains (i.e., image and motion in our method). Our method seamlessly integrates the image and motion data into the image feature domain by spatially-aligned temporal encoding so that features are extracted along the motion trajectory projected onto the image. Furthermore, this paper also proposes a data-driven motion optimization method, Deep Motion Optimizer (DMO), that works with EBM for motion prediction. Different from previous gradient-based optimizers, our self-supervised DMO alleviates the difficulty of hyper-parameter tuning to avoid local minima. The effectiveness of the proposed method is demonstrated with a variety of experiments with similar SOTA methods.
Inserting Anybody in Diffusion Models via Celeb Basis
Jun 01, 2023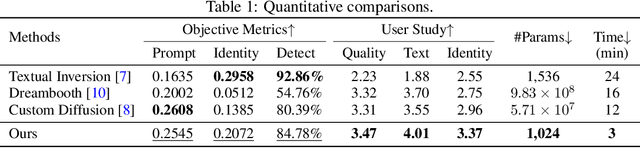
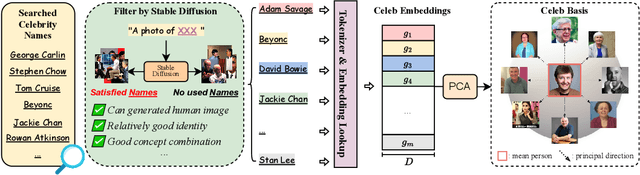
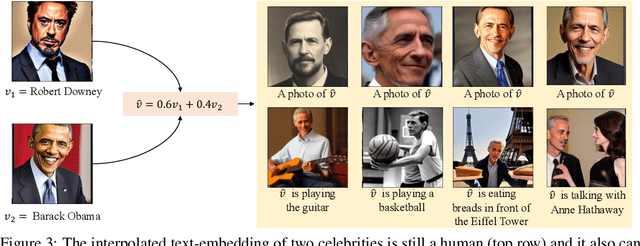
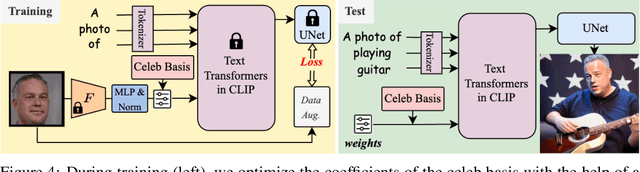
Exquisite demand exists for customizing the pretrained large text-to-image model, $\textit{e.g.}$, Stable Diffusion, to generate innovative concepts, such as the users themselves. However, the newly-added concept from previous customization methods often shows weaker combination abilities than the original ones even given several images during training. We thus propose a new personalization method that allows for the seamless integration of a unique individual into the pre-trained diffusion model using just $\textbf{one facial photograph}$ and only $\textbf{1024 learnable parameters}$ under $\textbf{3 minutes}$. So as we can effortlessly generate stunning images of this person in any pose or position, interacting with anyone and doing anything imaginable from text prompts. To achieve this, we first analyze and build a well-defined celeb basis from the embedding space of the pre-trained large text encoder. Then, given one facial photo as the target identity, we generate its own embedding by optimizing the weight of this basis and locking all other parameters. Empowered by the proposed celeb basis, the new identity in our customized model showcases a better concept combination ability than previous personalization methods. Besides, our model can also learn several new identities at once and interact with each other where the previous customization model fails to. The code will be released.
FDNeRF: Semantics-Driven Face Reconstruction, Prompt Editing and Relighting with Diffusion Models
Jun 01, 2023
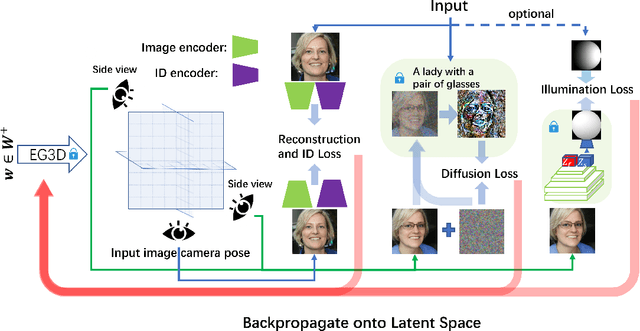

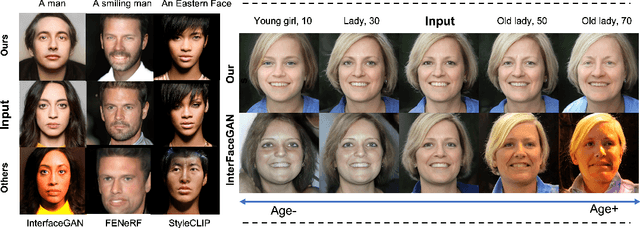
The ability to create high-quality 3D faces from a single image has become increasingly important with wide applications in video conferencing, AR/VR, and advanced video editing in movie industries. In this paper, we propose Face Diffusion NeRF (FDNeRF), a new generative method to reconstruct high-quality Face NeRFs from single images, complete with semantic editing and relighting capabilities. FDNeRF utilizes high-resolution 3D GAN inversion and expertly trained 2D latent-diffusion model, allowing users to manipulate and construct Face NeRFs in zero-shot learning without the need for explicit 3D data. With carefully designed illumination and identity preserving loss, as well as multi-modal pre-training, FD-NeRF offers users unparalleled control over the editing process enabling them to create and edit face NeRFs using just single-view images, text prompts, and explicit target lighting. The advanced features of FDNeRF have been designed to produce more impressive results than existing 2D editing approaches that rely on 2D segmentation maps for editable attributes. Experiments show that our FDNeRF achieves exceptionally realistic results and unprecedented flexibility in editing compared with state-of-the-art 3D face reconstruction and editing methods. Our code will be available at https://github.com/BillyXYB/FDNeRF.
Text2Video-Zero: Text-to-Image Diffusion Models are Zero-Shot Video Generators
Mar 23, 2023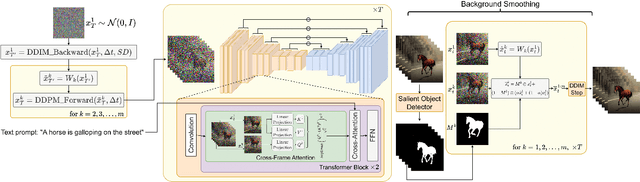

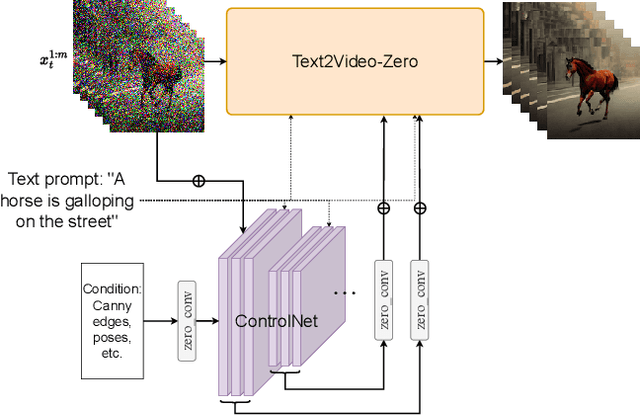

Recent text-to-video generation approaches rely on computationally heavy training and require large-scale video datasets. In this paper, we introduce a new task of zero-shot text-to-video generation and propose a low-cost approach (without any training or optimization) by leveraging the power of existing text-to-image synthesis methods (e.g., Stable Diffusion), making them suitable for the video domain. Our key modifications include (i) enriching the latent codes of the generated frames with motion dynamics to keep the global scene and the background time consistent; and (ii) reprogramming frame-level self-attention using a new cross-frame attention of each frame on the first frame, to preserve the context, appearance, and identity of the foreground object. Experiments show that this leads to low overhead, yet high-quality and remarkably consistent video generation. Moreover, our approach is not limited to text-to-video synthesis but is also applicable to other tasks such as conditional and content-specialized video generation, and Video Instruct-Pix2Pix, i.e., instruction-guided video editing. As experiments show, our method performs comparably or sometimes better than recent approaches, despite not being trained on additional video data. Our code will be open sourced at: https://github.com/Picsart-AI-Research/Text2Video-Zero .
Searching Mobile App Screens via Text + Doodle
May 12, 2023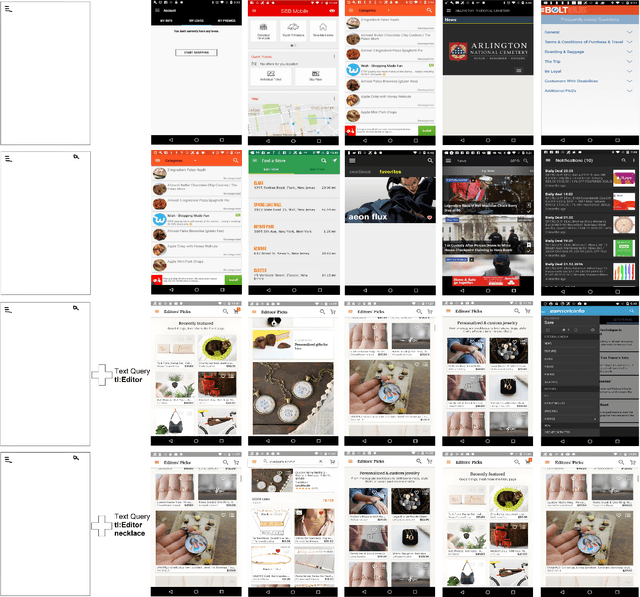
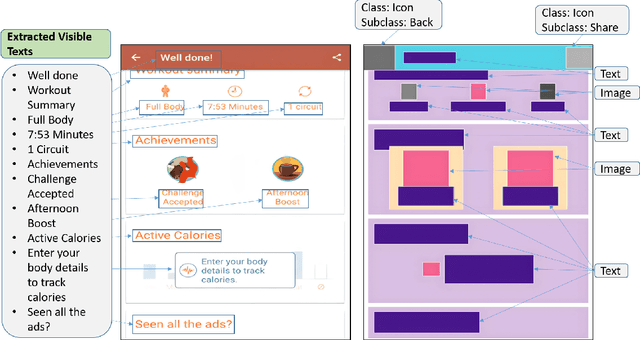
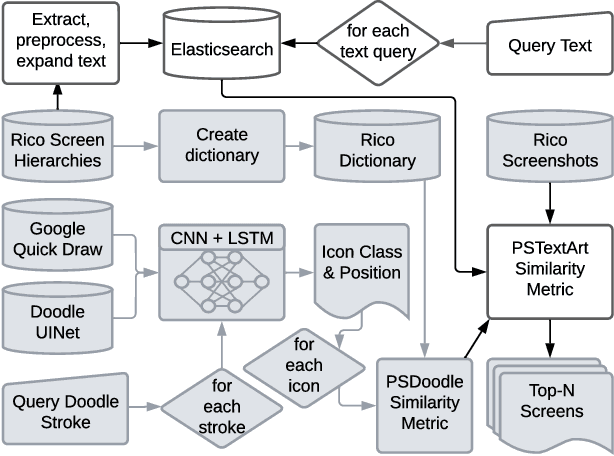
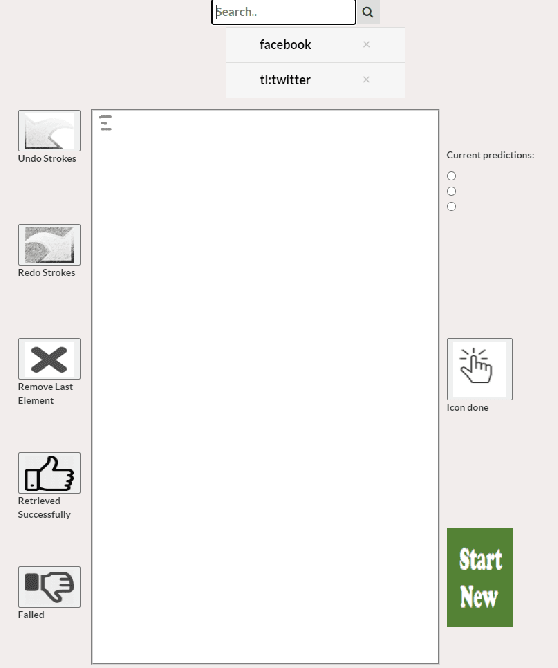
Locating a specific mobile application screen from existing repositories is restricted to basic keyword searches, such as Google Image Search, or necessitates a complete query screen image, as in the case of Swire. However, interactive partial sketch-based solutions like PSDoodle have limitations, including inaccuracy and an inability to consider text appearing on the screen. A potentially effective solution involves implementing a system that provides interactive partial sketching functionality for efficiently structuring user interface elements. Additionally, the system should incorporate text queries to enhance its capabilities further. Our approach, TpD, represents the pioneering effort to enable an iterative search of screens by combining interactive sketching and keyword search techniques. TpD is built on a combination of the Rico repository of approximately 58k Android app screens and the PSDoodle. Our evaluation with third-party software developers showed that PSDoodle provided higher top-10 screen retrieval accuracy than state-of-the-art Swire and required less time to complete a query than other interactive solutions.
PanoGRF: Generalizable Spherical Radiance Fields for Wide-baseline Panoramas
Jun 02, 2023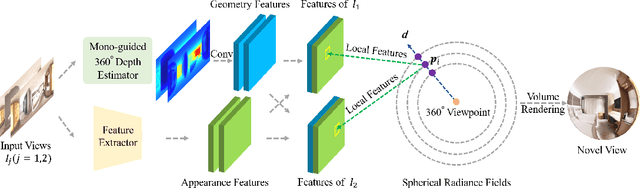

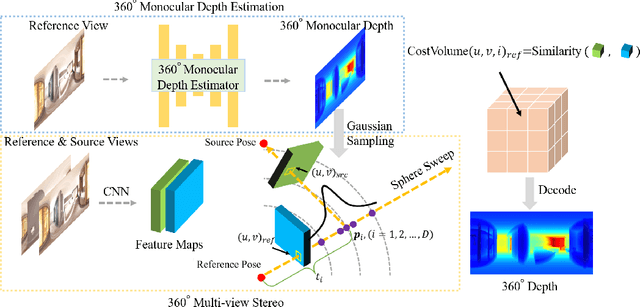
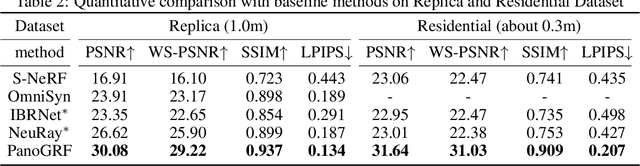
Achieving an immersive experience enabling users to explore virtual environments with six degrees of freedom (6DoF) is essential for various applications such as virtual reality (VR). Wide-baseline panoramas are commonly used in these applications to reduce network bandwidth and storage requirements. However, synthesizing novel views from these panoramas remains a key challenge. Although existing neural radiance field methods can produce photorealistic views under narrow-baseline and dense image captures, they tend to overfit the training views when dealing with \emph{wide-baseline} panoramas due to the difficulty in learning accurate geometry from sparse $360^{\circ}$ views. To address this problem, we propose PanoGRF, Generalizable Spherical Radiance Fields for Wide-baseline Panoramas, which construct spherical radiance fields incorporating $360^{\circ}$ scene priors. Unlike generalizable radiance fields trained on perspective images, PanoGRF avoids the information loss from panorama-to-perspective conversion and directly aggregates geometry and appearance features of 3D sample points from each panoramic view based on spherical projection. Moreover, as some regions of the panorama are only visible from one view while invisible from others under wide baseline settings, PanoGRF incorporates $360^{\circ}$ monocular depth priors into spherical depth estimation to improve the geometry features. Experimental results on multiple panoramic datasets demonstrate that PanoGRF significantly outperforms state-of-the-art generalizable view synthesis methods for wide-baseline panoramas (e.g., OmniSyn) and perspective images (e.g., IBRNet, NeuRay).
Attacking Perceptual Similarity Metrics
May 15, 2023
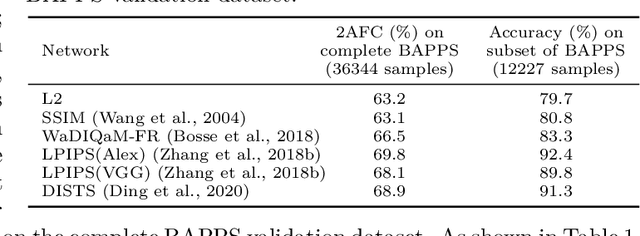

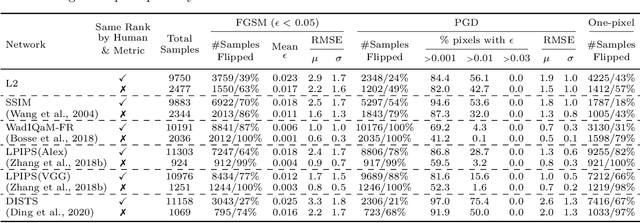
Perceptual similarity metrics have progressively become more correlated with human judgments on perceptual similarity; however, despite recent advances, the addition of an imperceptible distortion can still compromise these metrics. In our study, we systematically examine the robustness of these metrics to imperceptible adversarial perturbations. Following the two-alternative forced-choice experimental design with two distorted images and one reference image, we perturb the distorted image closer to the reference via an adversarial attack until the metric flips its judgment. We first show that all metrics in our study are susceptible to perturbations generated via common adversarial attacks such as FGSM, PGD, and the One-pixel attack. Next, we attack the widely adopted LPIPS metric using spatial-transformation-based adversarial perturbations (stAdv) in a white-box setting to craft adversarial examples that can effectively transfer to other similarity metrics in a black-box setting. We also combine the spatial attack stAdv with PGD ($\ell_\infty$-bounded) attack to increase transferability and use these adversarial examples to benchmark the robustness of both traditional and recently developed metrics. Our benchmark provides a good starting point for discussion and further research on the robustness of metrics to imperceptible adversarial perturbations.
Bridging the Domain Gap: Self-Supervised 3D Scene Understanding with Foundation Models
May 15, 2023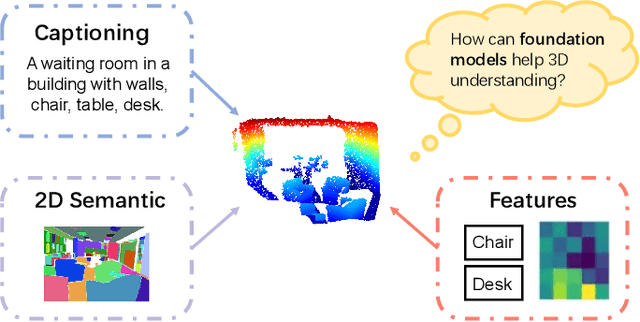
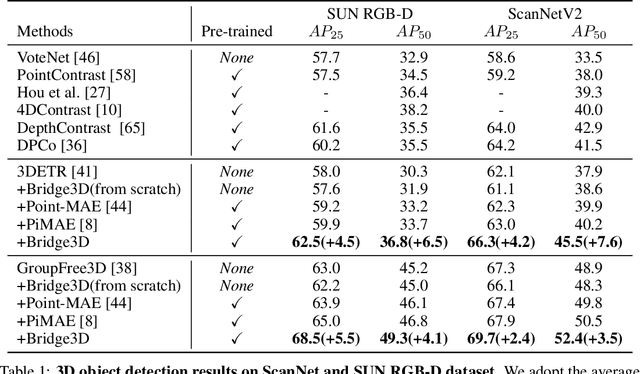
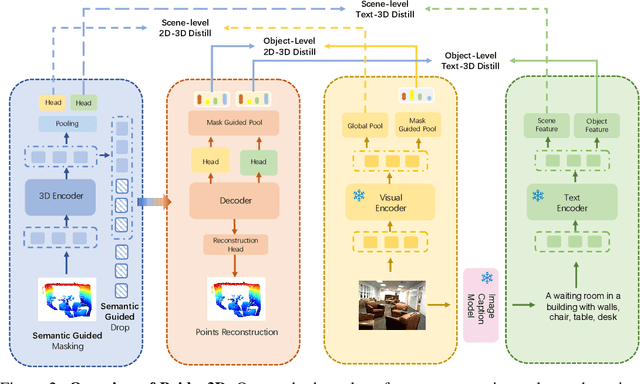
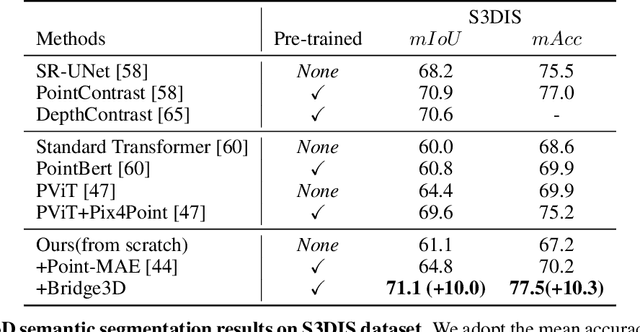
Foundation models have made significant strides in 2D and language tasks such as image segmentation, object detection, and visual-language understanding. Nevertheless, their potential to enhance 3D scene representation learning remains largely untapped due to the domain gap. In this paper, we propose an innovative methodology Bridge3D to address this gap, pre-training 3D models using features, semantic masks, and captions sourced from foundation models. Specifically, our approach utilizes semantic masks from these models to guide the masking and reconstruction process in the masked autoencoder. This strategy enables the network to concentrate more on foreground objects, thereby enhancing 3D representation learning. Additionally, we bridge the 3D-text gap at the scene level by harnessing image captioning foundation models. To further facilitate knowledge distillation from well-learned 2D and text representations to the 3D model, we introduce a novel method that employs foundation models to generate highly accurate object-level masks and semantic text information at the object level. Our approach notably outshines state-of-the-art methods in 3D object detection and semantic segmentation tasks. For instance, on the ScanNet dataset, our method surpasses the previous state-of-the-art method, PiMAE, by a significant margin of 5.3%.