 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Fast 3D Volumetric Image Reconstruction from 2D MRI Slices by Parallel Processing
Mar 16, 2023
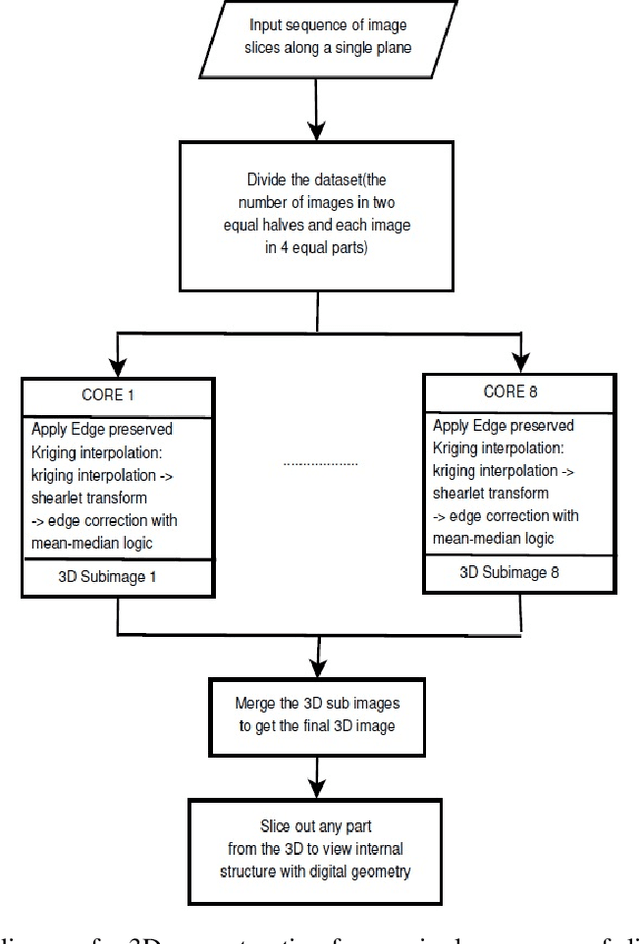
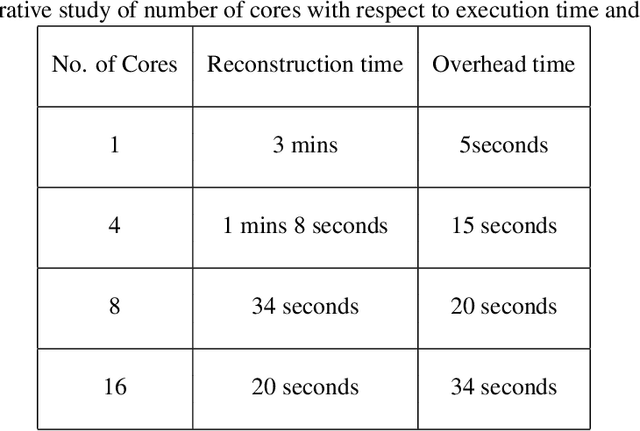
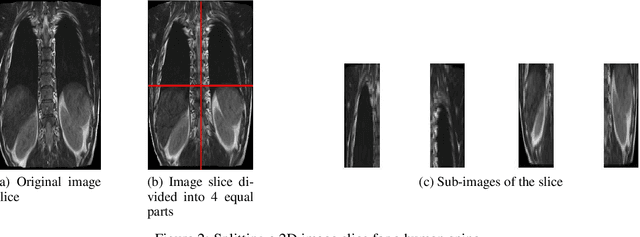
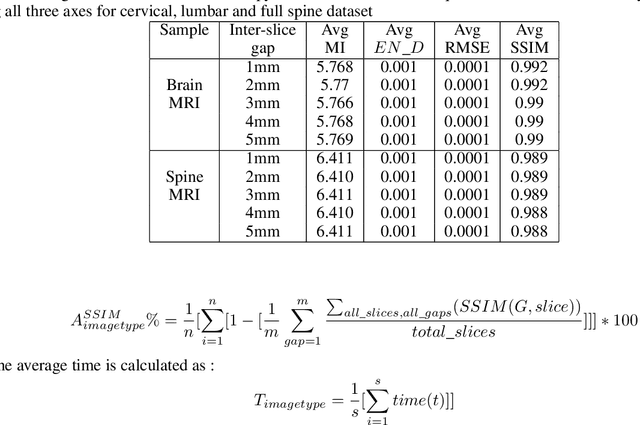
Magnetic Resonance Imaging (MRI) is a technology for non-invasive imaging of anatomical features in detail. It can help in functional analysis of organs of a specimen but it is very costly. In this work, methods for (i) virtual three-dimensional (3D) reconstruction from a single sequence of two-dimensional (2D) slices of MR images of a human spine and brain along a single axis, and (ii) generation of missing inter-slice data are proposed. Our approach helps in preserving the edges, shape, size, as well as the internal tissue structures of the object being captured. The sequence of original 2D slices along a single axis is divided into smaller equal sub-parts which are then reconstructed using edge preserved kriging interpolation to predict the missing slice information. In order to speed up the process of interpolation, we have used multiprocessing by carrying out the initial interpolation on parallel cores. From the 3D matrix thus formed, shearlet transform is applied to estimate the edges considering the 2D blocks along the $Z$ axis, and to minimize the blurring effect using a proposed mean-median logic. Finally, for visualization, the sub-matrices are merged into a final 3D matrix. Next, the newly formed 3D matrix is split up into voxels and marching cubes method is applied to get the approximate 3D image for viewing. To the best of our knowledge it is a first of its kind approach based on kriging interpolation and multiprocessing for 3D reconstruction from 2D slices, and approximately 98.89\% accuracy is achieved with respect to similarity metrics for image comparison. The time required for reconstruction has also been reduced by approximately 70\% with multiprocessing even for a large input data set compared to that with single core processing.
A statistically constrained internal method for single image super-resolution
Feb 03, 2023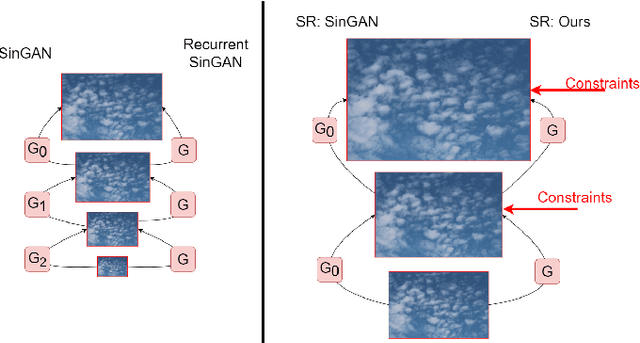


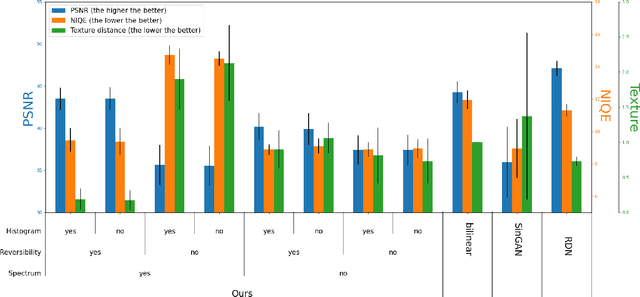
Deep learning based methods for single-image super-resolution (SR) have drawn a lot of attention lately. In particular, various papers have shown that the learning stage can be performed on a single image, resulting in the so-called internal approaches. The SinGAN method is one of these contributions, where the distribution of image patches is learnt on the image at hand and propagated at finer scales. Now, there are situations where some statistical a priori can be assumed for the final image. In particular, many natural phenomena yield images having power law Fourier spectrum, such as clouds and other texture images. In this work, we show how such a priori information can be integrated into an internal super-resolution approach, by constraining the learned up-sampling procedure of SinGAN. We consider various types of constraints, related to the Fourier power spectrum, the color histograms and the consistency of the upsampling scheme. We demonstrate on various experiments that these constraints are indeed satisfied, but also that some perceptual quality measures can be improved by the proposed approach.
Towards Understanding the Interplay of Generative Artificial Intelligence and the Internet
Jun 08, 2023
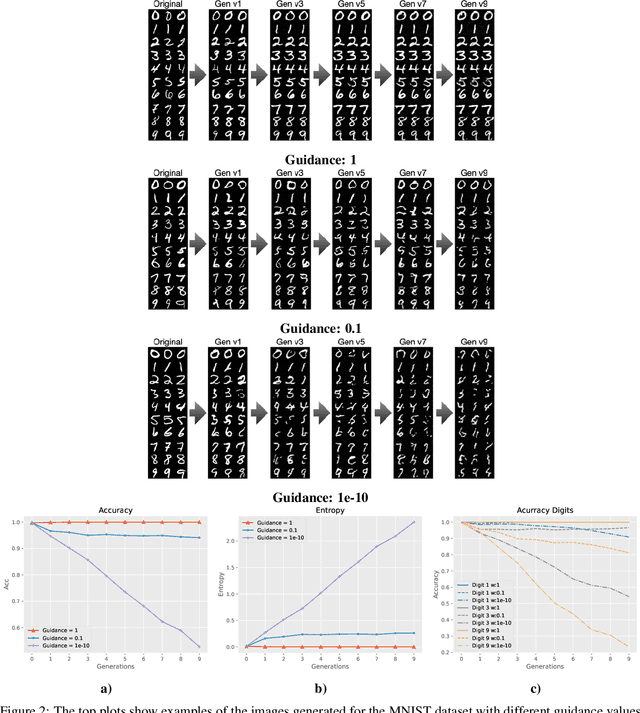
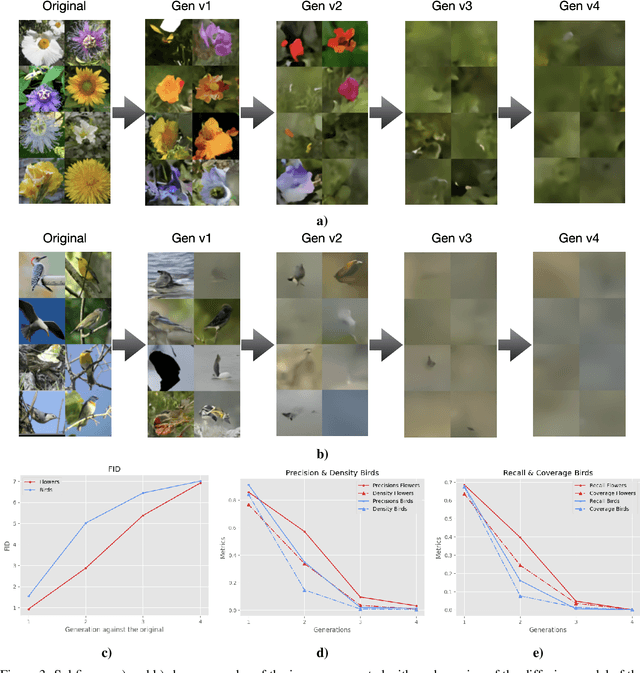
The rapid adoption of generative Artificial Intelligence (AI) tools that can generate realistic images or text, such as DALL-E, MidJourney, or ChatGPT, have put the societal impacts of these technologies at the center of public debate. These tools are possible due to the massive amount of data (text and images) that is publicly available through the Internet. At the same time, these generative AI tools become content creators that are already contributing to the data that is available to train future models. Therefore, future versions of generative AI tools will be trained with a mix of human-created and AI-generated content, causing a potential feedback loop between generative AI and public data repositories. This interaction raises many questions: how will future versions of generative AI tools behave when trained on a mixture of real and AI generated data? Will they evolve and improve with the new data sets or on the contrary will they degrade? Will evolution introduce biases or reduce diversity in subsequent generations of generative AI tools? What are the societal implications of the possible degradation of these models? Can we mitigate the effects of this feedback loop? In this document, we explore the effect of this interaction and report some initial results using simple diffusion models trained with various image datasets. Our results show that the quality and diversity of the generated images can degrade over time suggesting that incorporating AI-created data can have undesired effects on future versions of generative models.
Joint ANN-SNN Co-training for Object Localization and Image Segmentation
Mar 10, 2023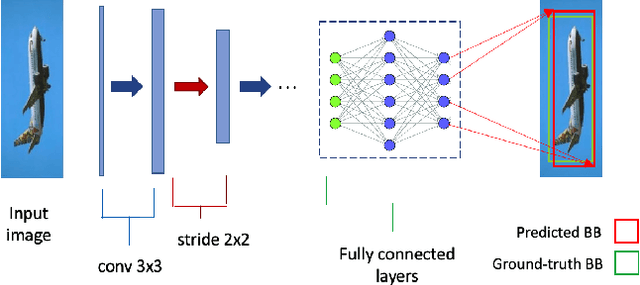
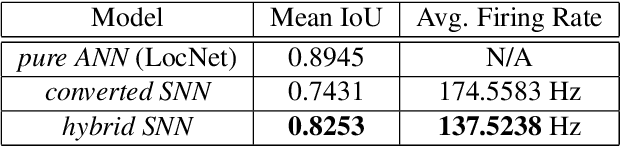
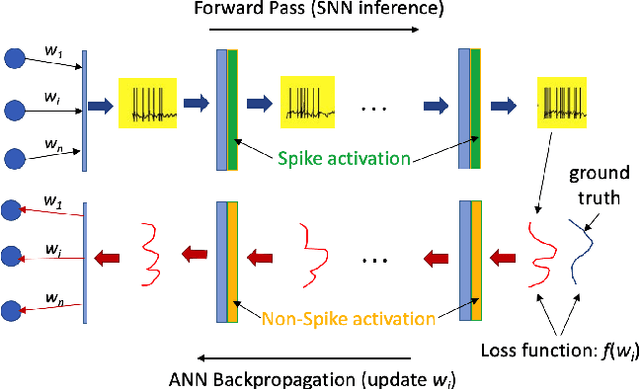
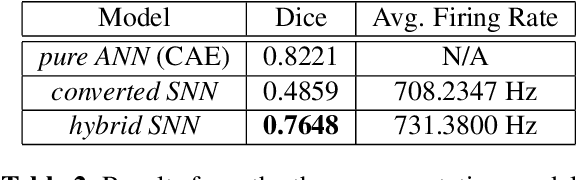
The field of machine learning has been greatly transformed with the advancement of deep artificial neural networks (ANNs) and the increased availability of annotated data. Spiking neural networks (SNNs) have recently emerged as a low-power alternative to ANNs due to their sparsity nature. In this work, we propose a novel hybrid ANN-SNN co-training framework to improve the performance of converted SNNs. Our approach is a fine-tuning scheme, conducted through an alternating, forward-backward training procedure. We apply our framework to object detection and image segmentation tasks. Experiments demonstrate the effectiveness of our approach in achieving the design goals.
Embodied Executable Policy Learning with Language-based Scene Summarization
Jun 09, 2023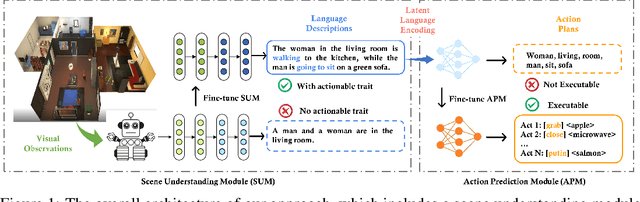
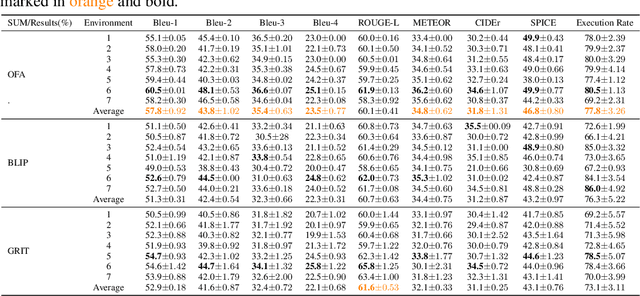
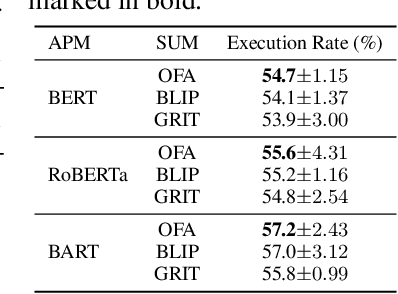

Large Language models (LLMs) have shown remarkable success in assisting robot learning tasks, i.e., complex household planning. However, the performance of pretrained LLMs heavily relies on domain-specific templated text data, which may be infeasible in real-world robot learning tasks with image-based observations. Moreover, existing LLMs with text inputs lack the capability to evolve with non-expert interactions with environments. In this work, we introduce a novel learning paradigm that generates robots' executable actions in the form of text, derived solely from visual observations, using language-based summarization of these observations as the connecting bridge between both domains. Our proposed paradigm stands apart from previous works, which utilized either language instructions or a combination of language and visual data as inputs. Moreover, our method does not require oracle text summarization of the scene, eliminating the need for human involvement in the learning loop, which makes it more practical for real-world robot learning tasks. Our proposed paradigm consists of two modules: the SUM module, which interprets the environment using visual observations and produces a text summary of the scene, and the APM module, which generates executable action policies based on the natural language descriptions provided by the SUM module. We demonstrate that our proposed method can employ two fine-tuning strategies, including imitation learning and reinforcement learning approaches, to adapt to the target test tasks effectively. We conduct extensive experiments involving various SUM/APM model selections, environments, and tasks across 7 house layouts in the VirtualHome environment. Our experimental results demonstrate that our method surpasses existing baselines, confirming the effectiveness of this novel learning paradigm.
Learning to Evaluate the Artness of AI-generated Images
May 08, 2023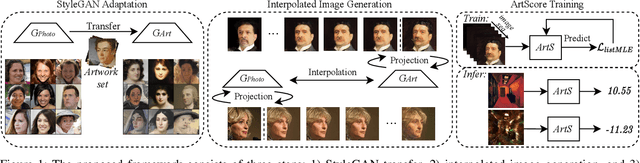
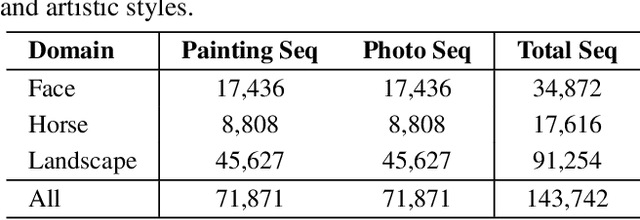
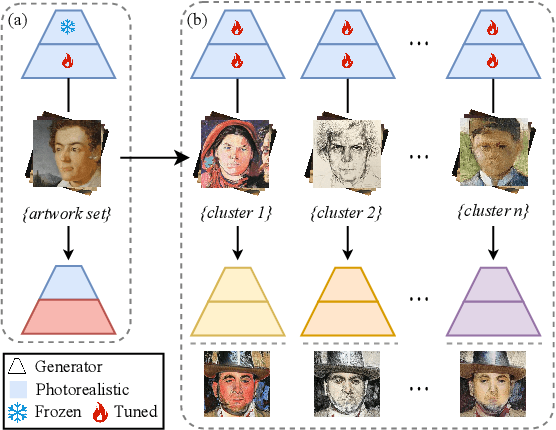
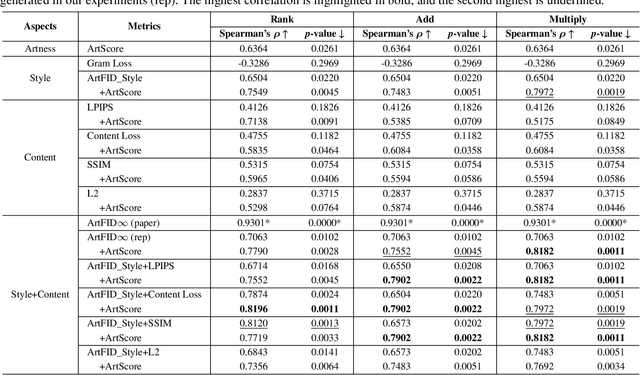
Assessing the artness of AI-generated images continues to be a challenge within the realm of image generation. Most existing metrics cannot be used to perform instance-level and reference-free artness evaluation. This paper presents ArtScore, a metric designed to evaluate the degree to which an image resembles authentic artworks by artists (or conversely photographs), thereby offering a novel approach to artness assessment. We first blend pre-trained models for photo and artwork generation, resulting in a series of mixed models. Subsequently, we utilize these mixed models to generate images exhibiting varying degrees of artness with pseudo-annotations. Each photorealistic image has a corresponding artistic counterpart and a series of interpolated images that range from realistic to artistic. This dataset is then employed to train a neural network that learns to estimate quantized artness levels of arbitrary images. Extensive experiments reveal that the artness levels predicted by ArtScore align more closely with human artistic evaluation than existing evaluation metrics, such as Gram loss and ArtFID.
SCOPE: Structural Continuity Preservation for Medical Image Segmentation
Apr 28, 2023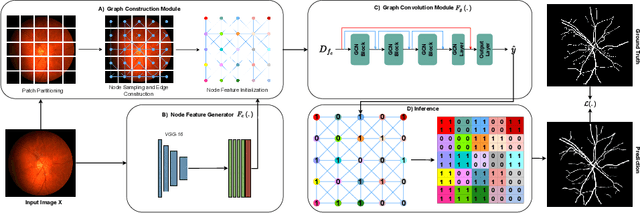
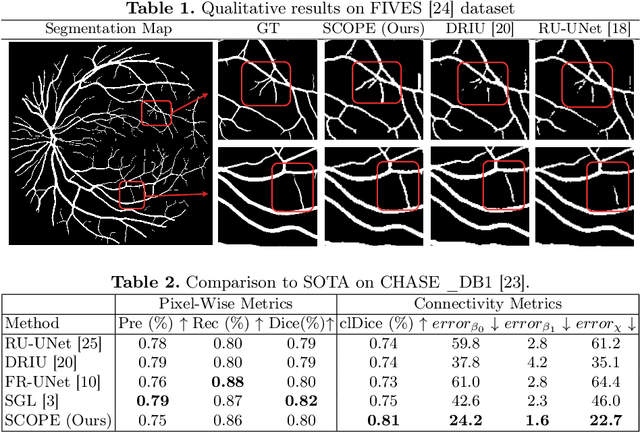
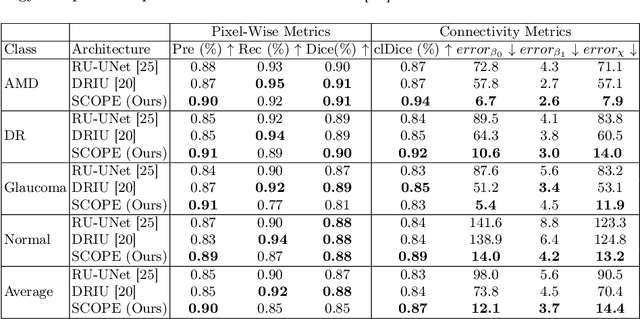
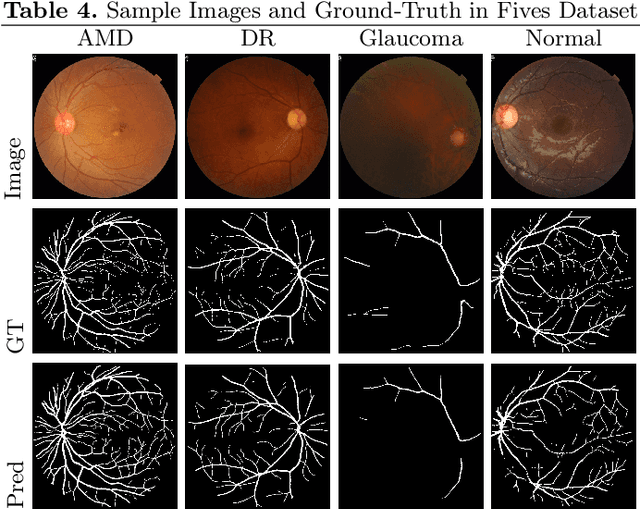
Although the preservation of shape continuity and physiological anatomy is a natural assumption in the segmentation of medical images, it is often neglected by deep learning methods that mostly aim for the statistical modeling of input data as pixels rather than interconnected structures. In biological structures, however, organs are not separate entities; for example, in reality, a severed vessel is an indication of an underlying problem, but traditional segmentation models are not designed to strictly enforce the continuity of anatomy, potentially leading to inaccurate medical diagnoses. To address this issue, we propose a graph-based approach that enforces the continuity and connectivity of anatomical topology in medical images. Our method encodes the continuity of shapes as a graph constraint, ensuring that the network's predictions maintain this continuity. We evaluate our method on two public benchmarks on retinal vessel segmentation, showing significant improvements in connectivity metrics compared to traditional methods while getting better or on-par performance on segmentation metrics.
Dual-layer Image Compression via Adaptive Downsampling and Spatially Varying Upconversion
Feb 13, 2023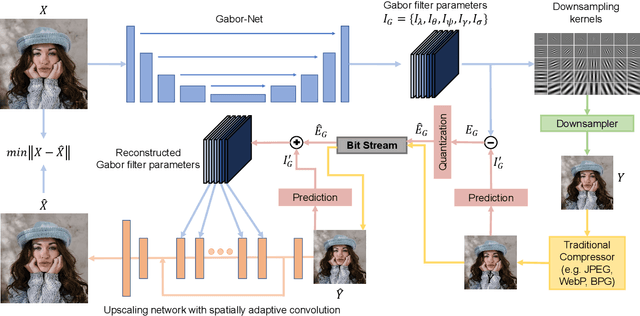

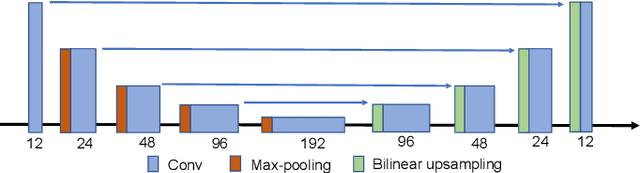
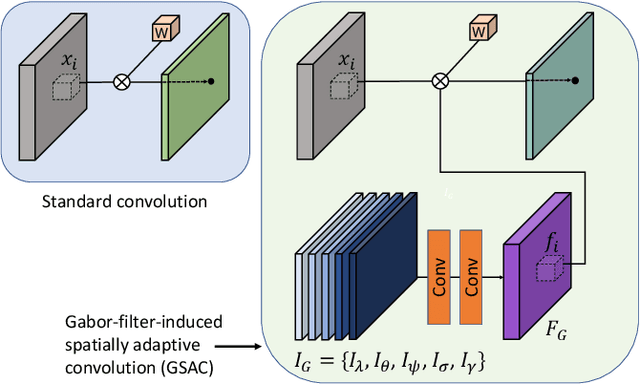
Ultra high resolution (UHR) images are almost always downsampled to fit small displays of mobile end devices and upsampled to its original resolution when exhibited on very high-resolution displays. This observation motivates us on jointly optimizing operation pairs of downsampling and upsampling that are spatially adaptive to image contents for maximal rate-distortion performance. In this paper, we propose an adaptive downsampled dual-layer (ADDL) image compression system. In the ADDL compression system, an image is reduced in resolution by learned content-adaptive downsampling kernels and compressed to form a coded base layer. For decompression the base layer is decoded and upconverted to the original resolution using a deep upsampling neural network, aided by the prior knowledge of the learned adaptive downsampling kernels. We restrict the downsampling kernels to the form of Gabor filters in order to reduce the complexity of filter optimization and also reduce the amount of side information needed by the decoder for adaptive upsampling. Extensive experiments demonstrate that the proposed ADDL compression approach of jointly optimized, spatially adaptive downsampling and upconversion outperforms the state of the art image compression methods.
Improving Handwritten OCR with Training Samples Generated by Glyph Conditional Denoising Diffusion Probabilistic Model
May 31, 2023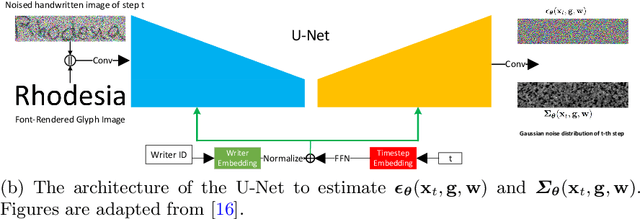
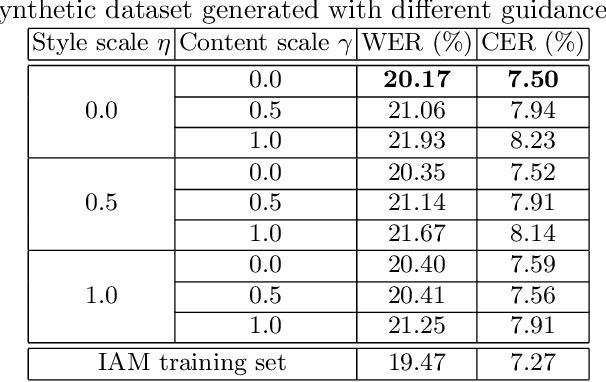

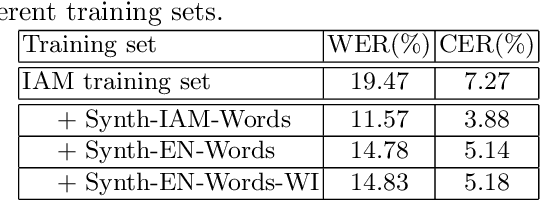
Constructing a highly accurate handwritten OCR system requires large amounts of representative training data, which is both time-consuming and expensive to collect. To mitigate the issue, we propose a denoising diffusion probabilistic model (DDPM) to generate training samples. This model conditions on a printed glyph image and creates mappings between printed characters and handwritten images, thus enabling the generation of photo-realistic handwritten samples with diverse styles and unseen text contents. However, the text contents in synthetic images are not always consistent with the glyph conditional images, leading to unreliable labels of synthetic samples. To address this issue, we further propose a progressive data filtering strategy to add those samples with a high confidence of correctness to the training set. Experimental results on IAM benchmark task show that OCR model trained with augmented DDPM-synthesized training samples can achieve about 45% relative word error rate reduction compared with the one trained on real data only.
A Unified GAN Framework Regarding Manifold Alignment for Remote Sensing Images Generation
May 31, 2023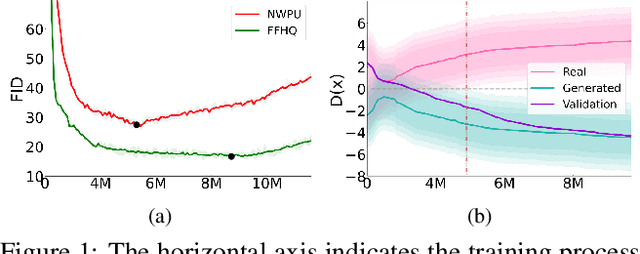
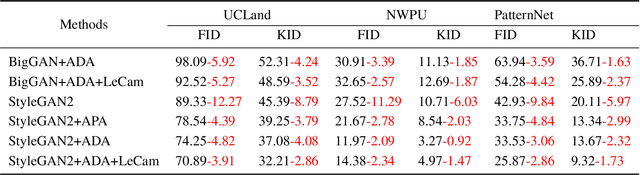
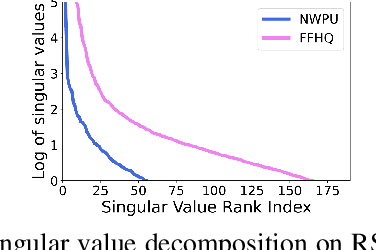
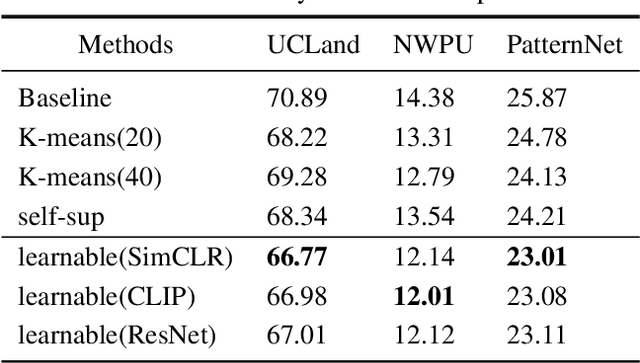
Generative Adversarial Networks (GANs) and their variants have achieved remarkable success on natural images. It aims to approximate the distribution of the training datasets. However, their performance degrades when applied to remote sensing (RS) images, and the discriminator often suffers from the overfitting problem. In this paper, we examine the differences between natural and RS images and find that the intrinsic dimensions of RS images are much lower than those of natural images. Besides, the low-dimensional data manifold of RS images may exacerbate the uneven sampling of training datasets and introduce biased information. The discriminator can easily overfit to the biased training distribution, leading to a faulty generation model, even the mode collapse problem. While existing GANs focus on the general distribution of RS datasets, they often neglect the underlying data manifold. In respond, we propose a learnable information-theoretic measure that preserves the intrinsic structures of the original data, and establish a unified GAN framework for manifold alignment in supervised and unsupervised RS image generation.