 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Variation-Aware Semantic Image Synthesis
Jan 25, 2023

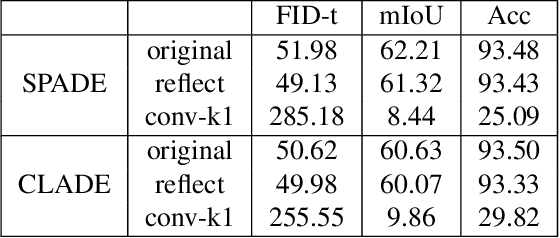
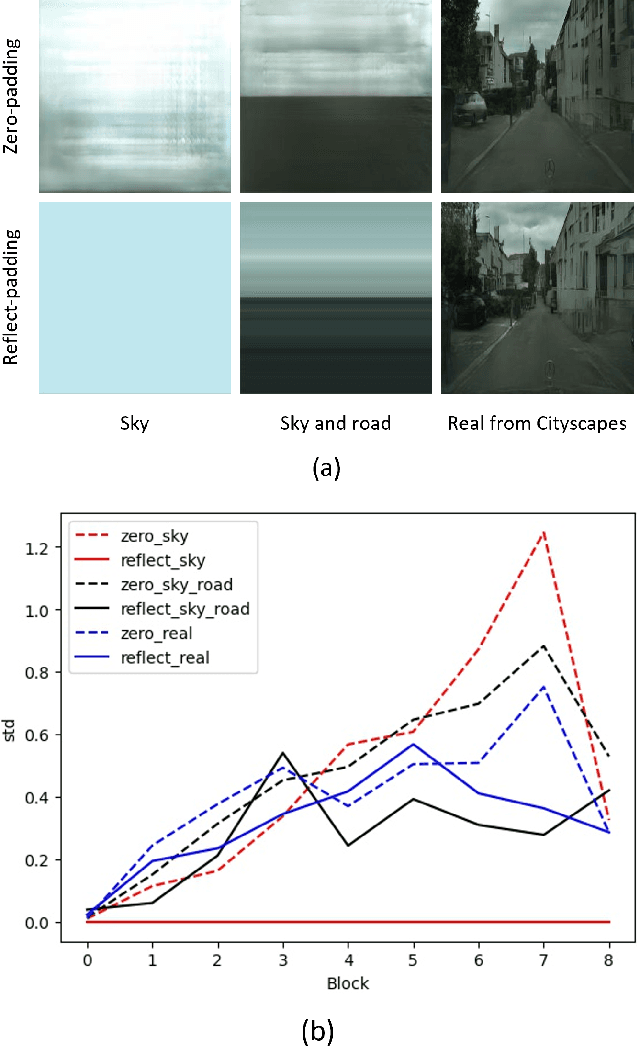
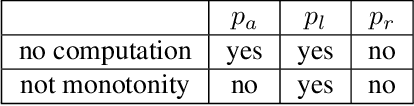
Semantic image synthesis (SIS) aims to produce photorealistic images aligning to given conditional semantic layout and has witnessed a significant improvement in recent years. Although the diversity in image-level has been discussed heavily, class-level mode collapse widely exists in current algorithms. Therefore, we declare a new requirement for SIS to achieve more photorealistic images, variation-aware, which consists of inter- and intra-class variation. The inter-class variation is the diversity between different semantic classes while the intra-class variation stresses the diversity inside one class. Through analysis, we find that current algorithms elusively embrace the inter-class variation but the intra-class variation is still not enough. Further, we introduce two simple methods to achieve variation-aware semantic image synthesis (VASIS) with a higher intra-class variation, semantic noise and position code. We combine our method with several state-of-the-art algorithms and the experimental result shows that our models generate more natural images and achieves slightly better FIDs and/or mIoUs than the counterparts. Our codes and models will be publicly available.
We never go out of Style: Motion Disentanglement by Subspace Decomposition of Latent Space
Jun 01, 2023
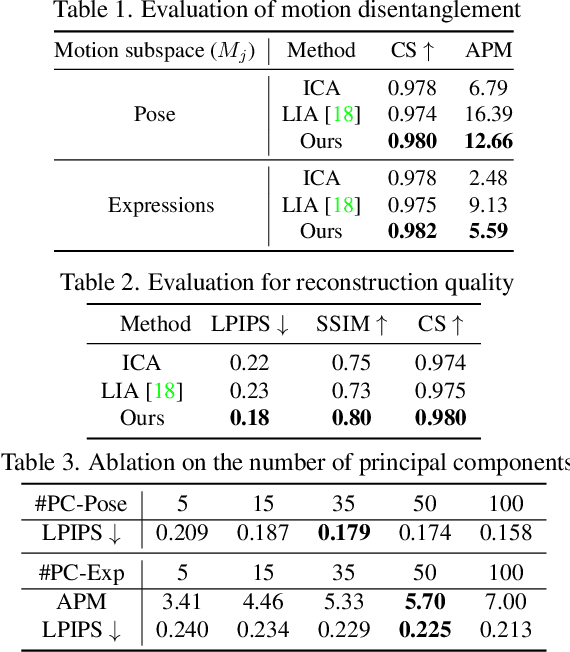

Real-world objects perform complex motions that involve multiple independent motion components. For example, while talking, a person continuously changes their expressions, head, and body pose. In this work, we propose a novel method to decompose motion in videos by using a pretrained image GAN model. We discover disentangled motion subspaces in the latent space of widely used style-based GAN models that are semantically meaningful and control a single explainable motion component. The proposed method uses only a few $(\approx10)$ ground truth video sequences to obtain such subspaces. We extensively evaluate the disentanglement properties of motion subspaces on face and car datasets, quantitatively and qualitatively. Further, we present results for multiple downstream tasks such as motion editing, and selective motion transfer, e.g. transferring only facial expressions without training for it.
Measuring Faithful and Plausible Visual Grounding in VQA
May 24, 2023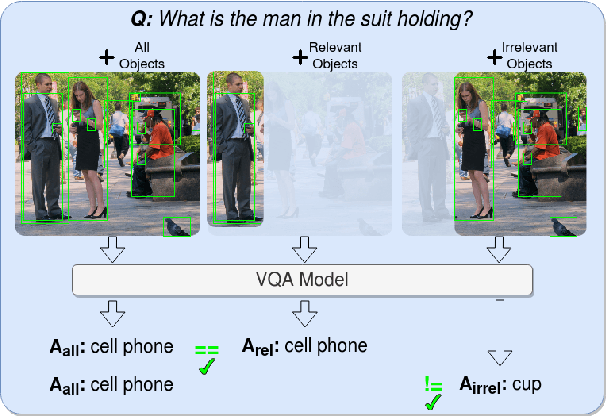

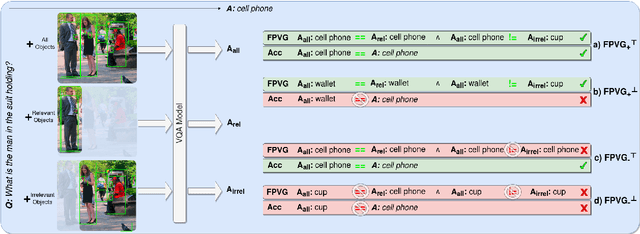
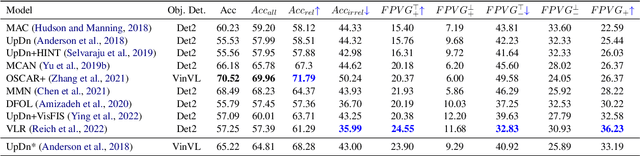
Metrics for Visual Grounding (VG) in Visual Question Answering (VQA) systems primarily aim to measure a system's reliance on relevant parts of the image when inferring an answer to the given question. Lack of VG has been a common problem among state-of-the-art VQA systems and can manifest in over-reliance on irrelevant image parts or a disregard for the visual modality entirely. Although inference capabilities of VQA models are often illustrated by a few qualitative illustrations, most systems are not quantitatively assessed for their VG properties. We believe, an easily calculated criterion for meaningfully measuring a system's VG can help remedy this shortcoming, as well as add another valuable dimension to model evaluations and analysis. To this end, we propose a new VG metric that captures if a model a) identifies question-relevant objects in the scene, and b) actually relies on the information contained in the relevant objects when producing its answer, i.e., if its visual grounding is both "faithful" and "plausible". Our metric, called "Faithful and Plausible Visual Grounding" (FPVG), is straightforward to determine for most VQA model designs. We give a detailed description of FPVG and evaluate several reference systems spanning various VQA architectures. Code to support the metric calculations on the GQA data set is available on GitHub.
3D Colored Shape Reconstruction from a Single RGB Image through Diffusion
Feb 11, 2023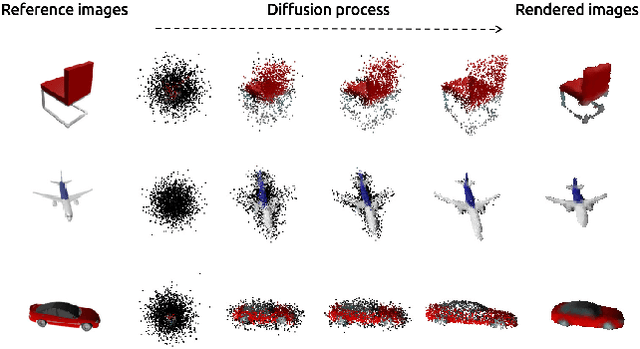
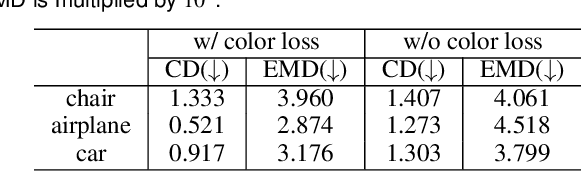
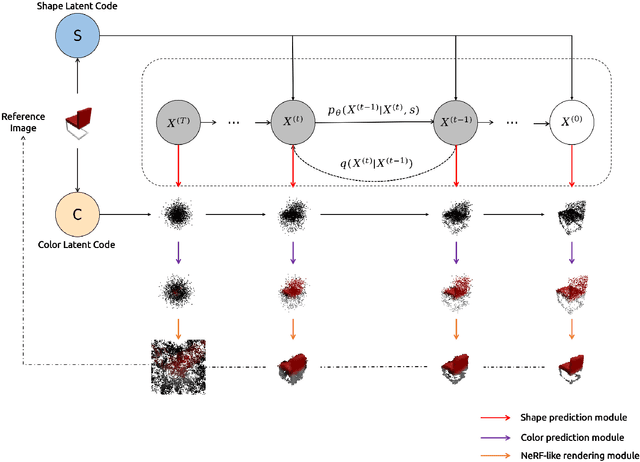
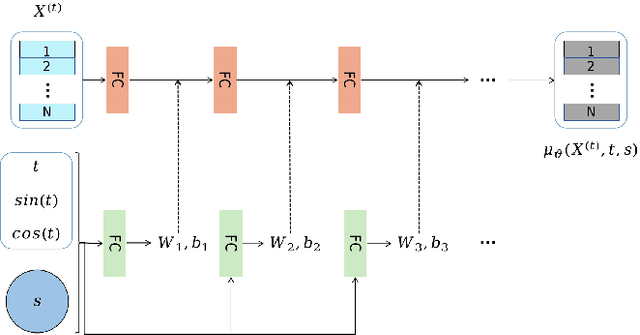
We propose a novel 3d colored shape reconstruction method from a single RGB image through diffusion model. Diffusion models have shown great development potentials for high-quality 3D shape generation. However, most existing work based on diffusion models only focus on geometric shape generation, they cannot either accomplish 3D reconstruction from a single image, or produce 3D geometric shape with color information. In this work, we propose to reconstruct a 3D colored shape from a single RGB image through a novel conditional diffusion model. The reverse process of the proposed diffusion model is consisted of three modules, shape prediction module, color prediction module and NeRF-like rendering module. In shape prediction module, the reference RGB image is first encoded into a high-level shape feature and then the shape feature is utilized as a condition to predict the reverse geometric noise in diffusion model. Then the color of each 3D point updated in shape prediction module is predicted by color prediction module. Finally, a NeRF-like rendering module is designed to render the colored point cloud predicted by the former two modules to 2D image space to guide the training conditioned only on a reference image. As far as the authors know, the proposed method is the first diffusion model for 3D colored shape reconstruction from a single RGB image. Experimental results demonstrate that the proposed method achieves competitive performance on colored 3D shape reconstruction, and the ablation study validates the positive role of the color prediction module in improving the reconstruction quality of 3D geometric point cloud.
A novel Cross-Component Context Model for End-to-End Wavelet Image Coding
Mar 09, 2023
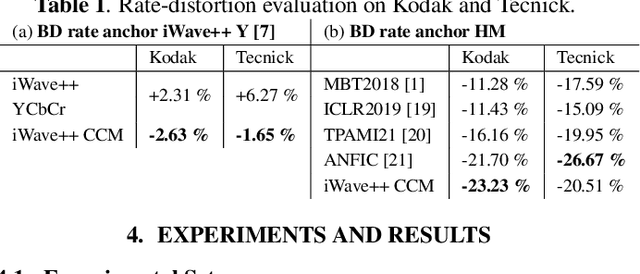
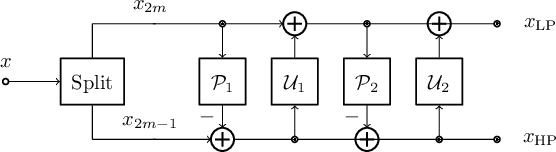
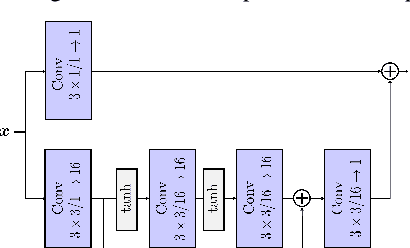
In contrast to traditional compression techniques performing linear transforms, the latent space of popular compressive autoencoders is obtained from a learned nonlinear mapping and hard to interpret. In this paper, we explore a promising alternative approach for neural compression, with an autoencoder whose latent space represents a nonlinear wavelet decomposition. Previous work has shown that neural wavelet image coding can outperform HEVC. However, the approach codes color components independently, thereby ignoring inter-component dependencies. Hence, we propose a novel cross-component context model (CCM). With CCM, the entropy model for the chroma latent space can be conditioned on previously coded components exploiting correlations in the learned wavelet space. The proposed CCM outperforms the baseline model with average Bj{\o}ntegaard delta rate savings of 2.6 % and 1.6 % for the Kodak and Tecnick image sets. Also, our method is competitive with VVC and learning-based methods.
A quality assurance framework for real-time monitoring of deep learning segmentation models in radiotherapy
May 19, 2023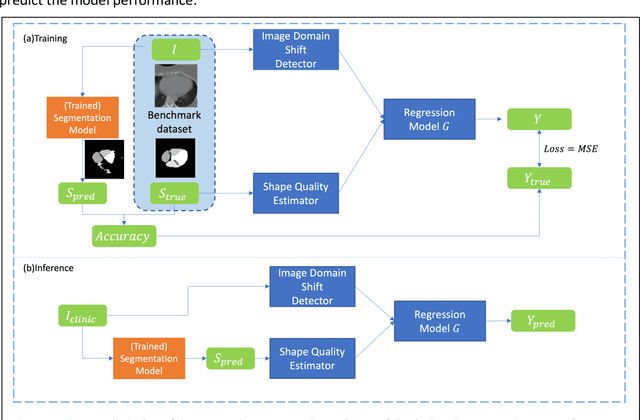

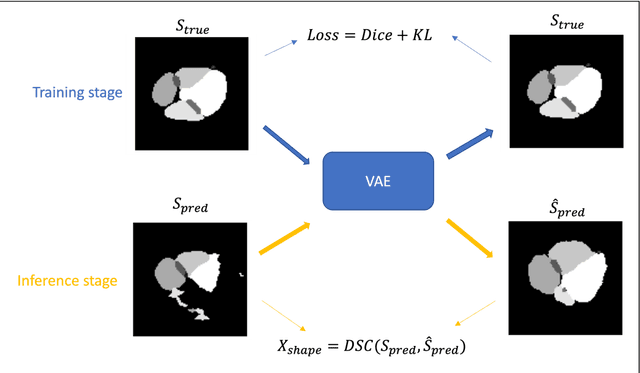
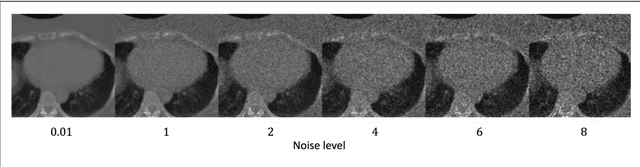
To safely deploy deep learning models in the clinic, a quality assurance framework is needed for routine or continuous monitoring of input-domain shift and the models' performance without ground truth contours. In this work, cardiac substructure segmentation was used as an example task to establish a QA framework. A benchmark dataset consisting of Computed Tomography (CT) images along with manual cardiac delineations of 241 patients were collected, including one 'common' image domain and five 'uncommon' domains. Segmentation models were tested on the benchmark dataset for an initial evaluation of model capacity and limitations. An image domain shift detector was developed by utilizing a trained Denoising autoencoder (DAE) and two hand-engineered features. Another Variational Autoencoder (VAE) was also trained to estimate the shape quality of the auto-segmentation results. Using the extracted features from the image/segmentation pair as inputs, a regression model was trained to predict the per-patient segmentation accuracy, measured by Dice coefficient similarity (DSC). The framework was tested across 19 segmentation models to evaluate the generalizability of the entire framework. As results, the predicted DSC of regression models achieved a mean absolute error (MAE) ranging from 0.036 to 0.046 with an averaged MAE of 0.041. When tested on the benchmark dataset, the performances of all segmentation models were not significantly affected by scanning parameters: FOV, slice thickness and reconstructions kernels. For input images with Poisson noise, CNN-based segmentation models demonstrated a decreased DSC ranging from 0.07 to 0.41, while the transformer-based model was not significantly affected.
JOINEDTrans: Prior Guided Multi-task Transformer for Joint Optic Disc/Cup Segmentation and Fovea Detection
May 19, 2023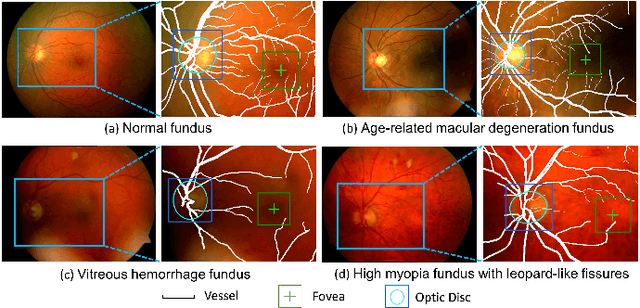
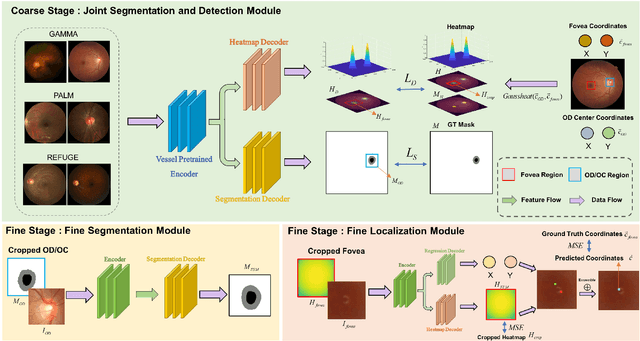
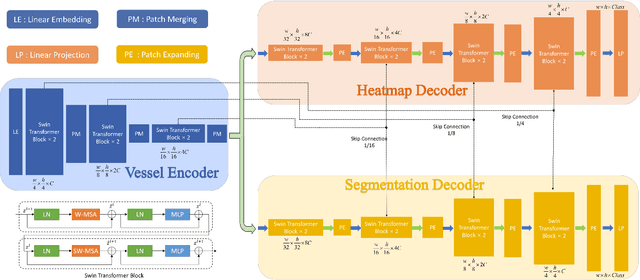
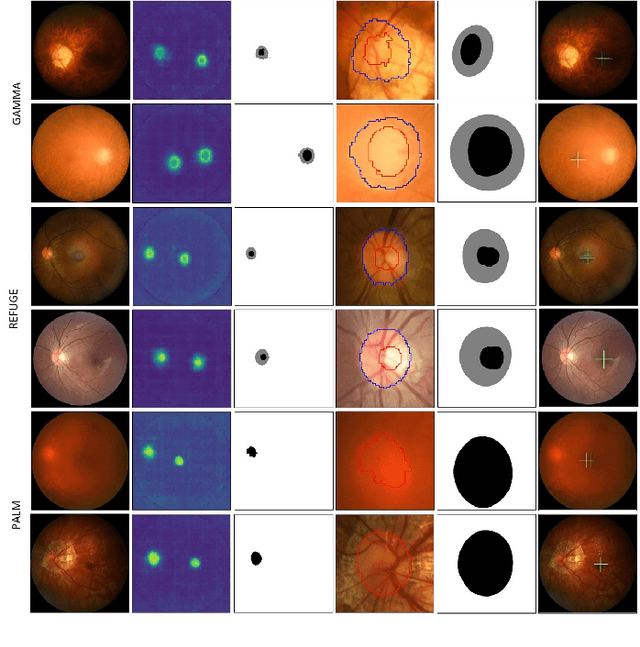
Deep learning-based image segmentation and detection models have largely improved the efficiency of analyzing retinal landmarks such as optic disc (OD), optic cup (OC), and fovea. However, factors including ophthalmic disease-related lesions and low image quality issues may severely complicate automatic OD/OC segmentation and fovea detection. Most existing works treat the identification of each landmark as a single task, and take into account no prior information. To address these issues, we propose a prior guided multi-task transformer framework for joint OD/OC segmentation and fovea detection, named JOINEDTrans. JOINEDTrans effectively combines various spatial features of the fundus images, relieving the structural distortions induced by lesions and other imaging issues. It contains a segmentation branch and a detection branch. To be noted, we employ an encoder pretrained in a vessel segmentation task to effectively exploit the positional relationship among vessel, OD/OC, and fovea, successfully incorporating spatial prior into the proposed JOINEDTrans framework. There are a coarse stage and a fine stage in JOINEDTrans. In the coarse stage, OD/OC coarse segmentation and fovea heatmap localization are obtained through a joint segmentation and detection module. In the fine stage, we crop regions of interest for subsequent refinement and use predictions obtained in the coarse stage to provide additional information for better performance and faster convergence. Experimental results demonstrate that JOINEDTrans outperforms existing state-of-the-art methods on the publicly available GAMMA, REFUGE, and PALM fundus image datasets. We make our code available at https://github.com/HuaqingHe/JOINEDTrans
Single Image Backdoor Inversion via Robust Smoothed Classifiers
Mar 01, 2023


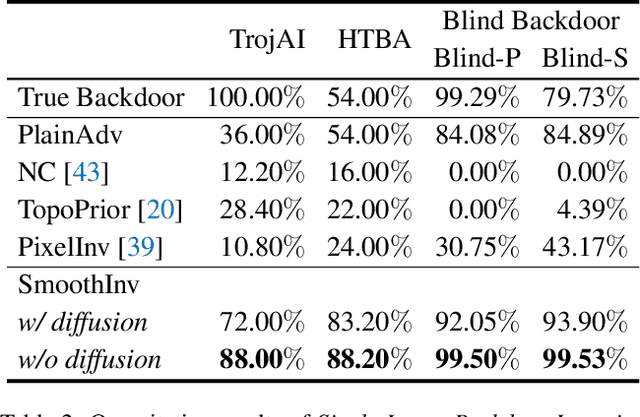
Backdoor inversion, the process of finding a backdoor trigger inserted into a machine learning model, has become the pillar of many backdoor detection and defense methods. Previous works on backdoor inversion often recover the backdoor through an optimization process to flip a support set of clean images into the target class. However, it is rarely studied and understood how large this support set should be to recover a successful backdoor. In this work, we show that one can reliably recover the backdoor trigger with as few as a single image. Specifically, we propose the SmoothInv method, which first constructs a robust smoothed version of the backdoored classifier and then performs guided image synthesis towards the target class to reveal the backdoor pattern. SmoothInv requires neither an explicit modeling of the backdoor via a mask variable, nor any complex regularization schemes, which has become the standard practice in backdoor inversion methods. We perform both quantitaive and qualitative study on backdoored classifiers from previous published backdoor attacks. We demonstrate that compared to existing methods, SmoothInv is able to recover successful backdoors from single images, while maintaining high fidelity to the original backdoor. We also show how we identify the target backdoored class from the backdoored classifier. Last, we propose and analyze two countermeasures to our approach and show that SmoothInv remains robust in the face of an adaptive attacker. Our code is available at https://github.com/locuslab/smoothinv .
MPS-AMS: Masked Patches Selection and Adaptive Masking Strategy Based Self-Supervised Medical Image Segmentation
Feb 27, 2023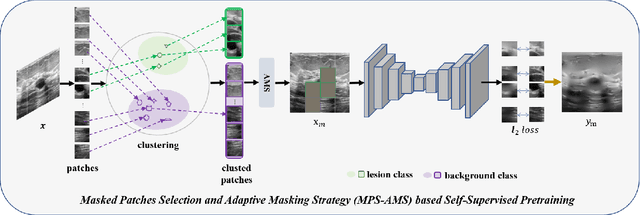
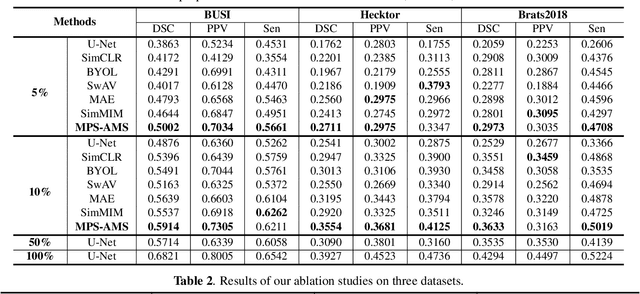
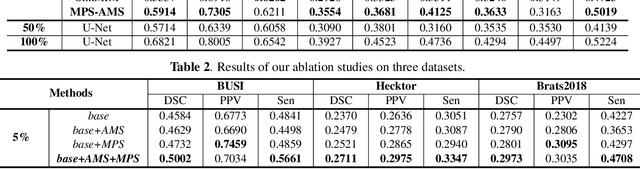
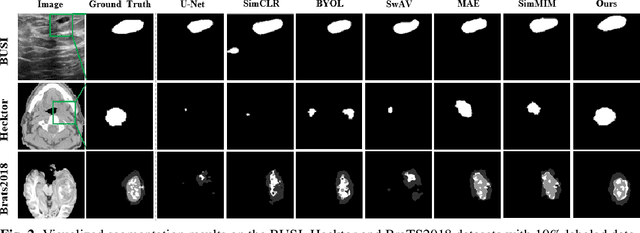
Existing self-supervised learning methods based on contrastive learning and masked image modeling have demonstrated impressive performances. However, current masked image modeling methods are mainly utilized in natural images, and their applications in medical images are relatively lacking. Besides, their fixed high masking strategy limits the upper bound of conditional mutual information, and the gradient noise is considerable, making less the learned representation information. Motivated by these limitations, in this paper, we propose masked patches selection and adaptive masking strategy based self-supervised medical image segmentation method, named MPS-AMS. We leverage the masked patches selection strategy to choose masked patches with lesions to obtain more lesion representation information, and the adaptive masking strategy is utilized to help learn more mutual information and improve performance further. Extensive experiments on three public medical image segmentation datasets (BUSI, Hecktor, and Brats2018) show that our proposed method greatly outperforms the state-of-the-art self-supervised baselines.
DreamPaint: Few-Shot Inpainting of E-Commerce Items for Virtual Try-On without 3D Modeling
May 02, 2023

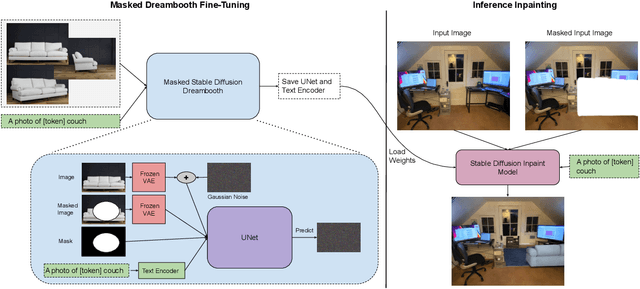

We introduce DreamPaint, a framework to intelligently inpaint any e-commerce product on any user-provided context image. The context image can be, for example, the user's own image for virtual try-on of clothes from the e-commerce catalog on themselves, the user's room image for virtual try-on of a piece of furniture from the e-commerce catalog in their room, etc. As opposed to previous augmented-reality (AR)-based virtual try-on methods, DreamPaint does not use, nor does it require, 3D modeling of neither the e-commerce product nor the user context. Instead, it directly uses 2D images of the product as available in product catalog database, and a 2D picture of the context, for example taken from the user's phone camera. The method relies on few-shot fine tuning a pre-trained diffusion model with the masked latents (e.g., Masked DreamBooth) of the catalog images per item, whose weights are then loaded on a pre-trained inpainting module that is capable of preserving the characteristics of the context image. DreamPaint allows to preserve both the product image and the context (environment/user) image without requiring text guidance to describe the missing part (product/context). DreamPaint also allows to intelligently infer the best 3D angle of the product to place at the desired location on the user context, even if that angle was previously unseen in the product's reference 2D images. We compare our results against both text-guided and image-guided inpainting modules and show that DreamPaint yields superior performance in both subjective human study and quantitative metrics.