 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
OCTraN: 3D Occupancy Convolutional Transformer Network in Unstructured Traffic Scenarios
Jul 20, 2023
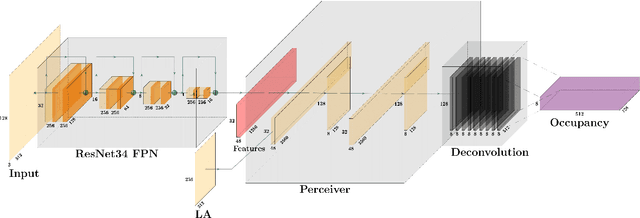

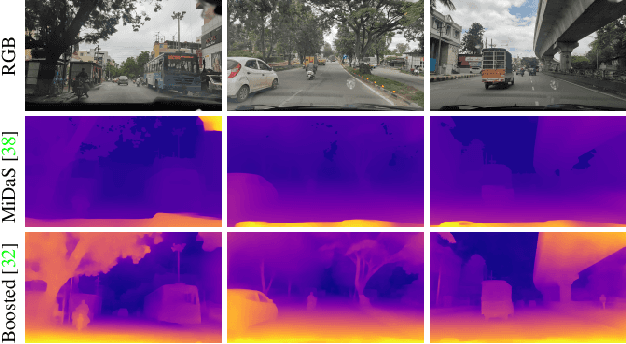
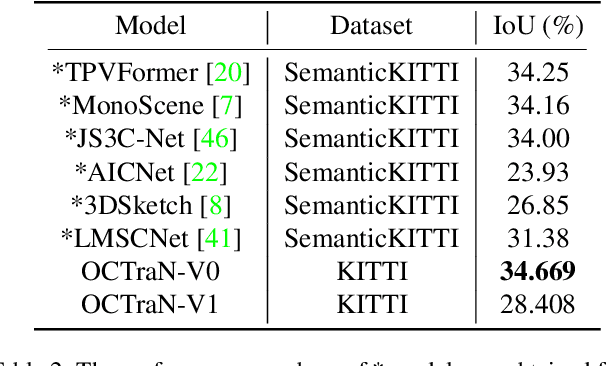
Modern approaches for vision-centric environment perception for autonomous navigation make extensive use of self-supervised monocular depth estimation algorithms that output disparity maps. However, when this disparity map is projected onto 3D space, the errors in disparity are magnified, resulting in a depth estimation error that increases quadratically as the distance from the camera increases. Though Light Detection and Ranging (LiDAR) can solve this issue, it is expensive and not feasible for many applications. To address the challenge of accurate ranging with low-cost sensors, we propose, OCTraN, a transformer architecture that uses iterative-attention to convert 2D image features into 3D occupancy features and makes use of convolution and transpose convolution to efficiently operate on spatial information. We also develop a self-supervised training pipeline to generalize the model to any scene by eliminating the need for LiDAR ground truth by substituting it with pseudo-ground truth labels obtained from boosted monocular depth estimation.
Learning Dense UV Completion for Human Mesh Recovery
Jul 20, 2023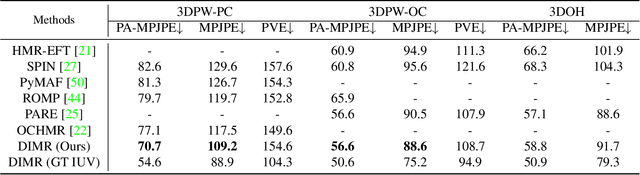
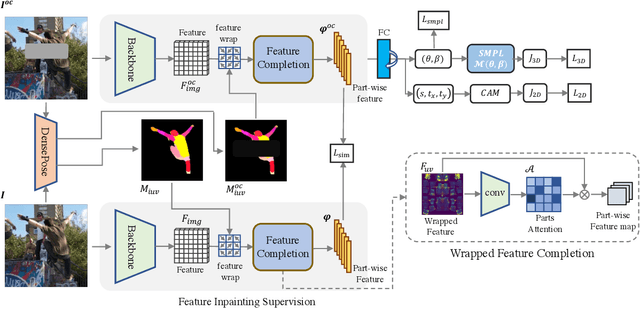
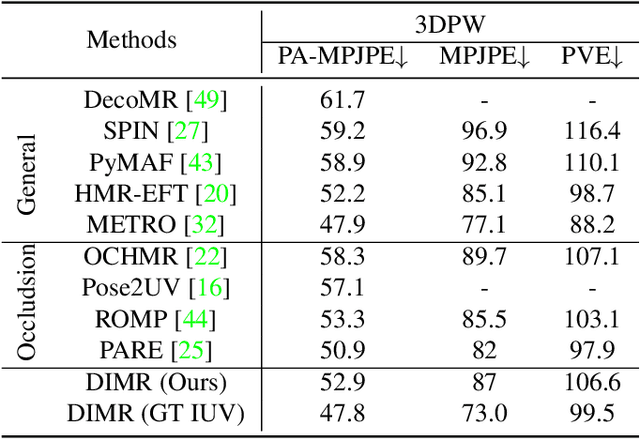

Human mesh reconstruction from a single image is challenging in the presence of occlusion, which can be caused by self, objects, or other humans. Existing methods either fail to separate human features accurately or lack proper supervision for feature completion. In this paper, we propose Dense Inpainting Human Mesh Recovery (DIMR), a two-stage method that leverages dense correspondence maps to handle occlusion. Our method utilizes a dense correspondence map to separate visible human features and completes human features on a structured UV map dense human with an attention-based feature completion module. We also design a feature inpainting training procedure that guides the network to learn from unoccluded features. We evaluate our method on several datasets and demonstrate its superior performance under heavily occluded scenarios compared to other methods. Extensive experiments show that our method obviously outperforms prior SOTA methods on heavily occluded images and achieves comparable results on the standard benchmarks (3DPW).
Detecting Images Generated by Deep Diffusion Models using their Local Intrinsic Dimensionality
Jul 20, 2023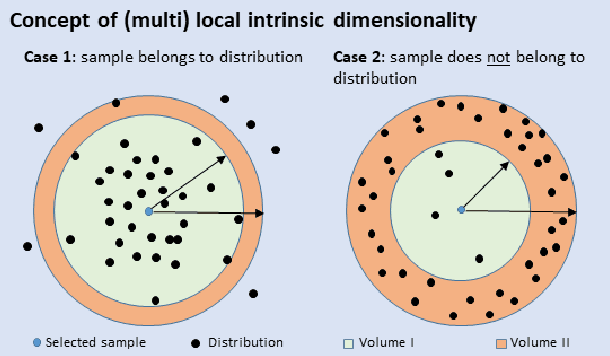
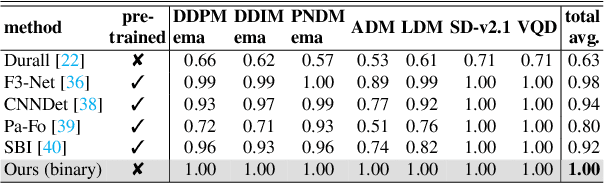
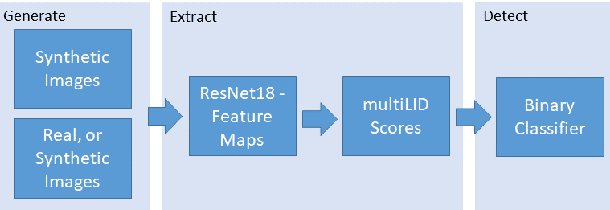
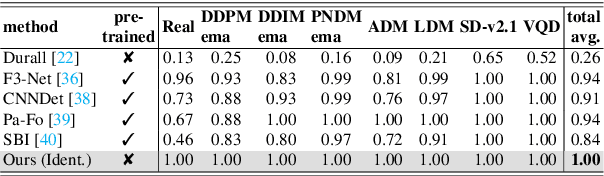
Diffusion models recently have been successfully applied for the visual synthesis of strikingly realistic appearing images. This raises strong concerns about their potential for malicious purposes. In this paper, we propose using the lightweight multi Local Intrinsic Dimensionality (multiLID), which has been originally developed in context of the detection of adversarial examples, for the automatic detection of synthetic images and the identification of the according generator networks. In contrast to many existing detection approaches, which often only work for GAN-generated images, the proposed method provides close to perfect detection results in many realistic use cases. Extensive experiments on known and newly created datasets demonstrate that the proposed multiLID approach exhibits superiority in diffusion detection and model identification. Since the empirical evaluations of recent publications on the detection of generated images are often mainly focused on the "LSUN-Bedroom" dataset, we further establish a comprehensive benchmark for the detection of diffusion-generated images, including samples from several diffusion models with different image sizes.
DisPlacing Objects: Improving Dynamic Vehicle Detection via Visual Place Recognition under Adverse Conditions
Jun 30, 2023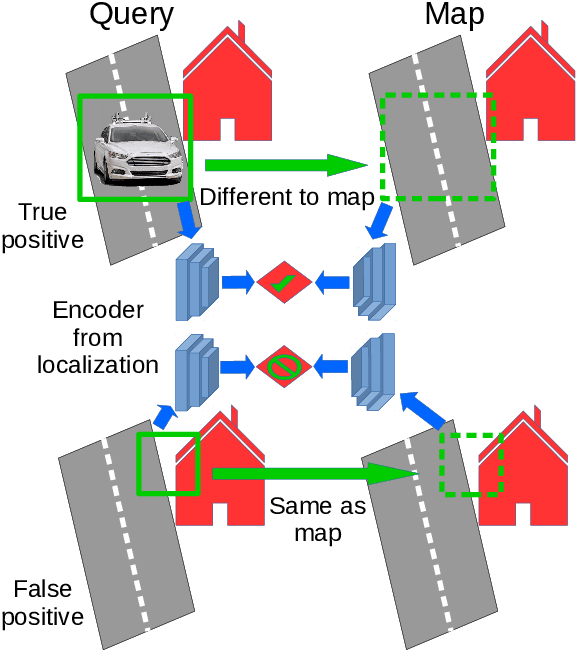
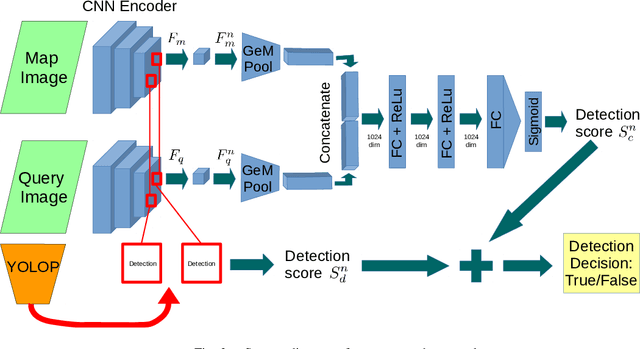
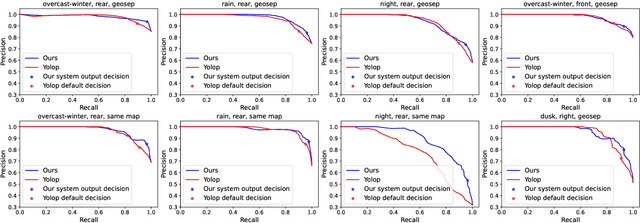

Can knowing where you are assist in perceiving objects in your surroundings, especially under adverse weather and lighting conditions? In this work we investigate whether a prior map can be leveraged to aid in the detection of dynamic objects in a scene without the need for a 3D map or pixel-level map-query correspondences. We contribute an algorithm which refines an initial set of candidate object detections and produces a refined subset of highly accurate detections using a prior map. We begin by using visual place recognition (VPR) to retrieve a reference map image for a given query image, then use a binary classification neural network that compares the query and mapping image regions to validate the query detection. Once our classification network is trained, on approximately 1000 query-map image pairs, it is able to improve the performance of vehicle detection when combined with an existing off-the-shelf vehicle detector. We demonstrate our approach using standard datasets across two cities (Oxford and Zurich) under different settings of train-test separation of map-query traverse pairs. We further emphasize the performance gains of our approach against alternative design choices and show that VPR suffices for the task, eliminating the need for precise ground truth localization.
Quantum-noise-limited optical neural networks operating at a few quanta per activation
Jul 28, 2023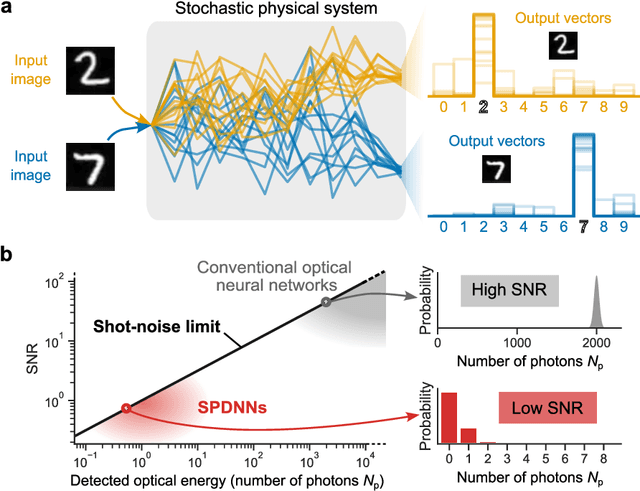

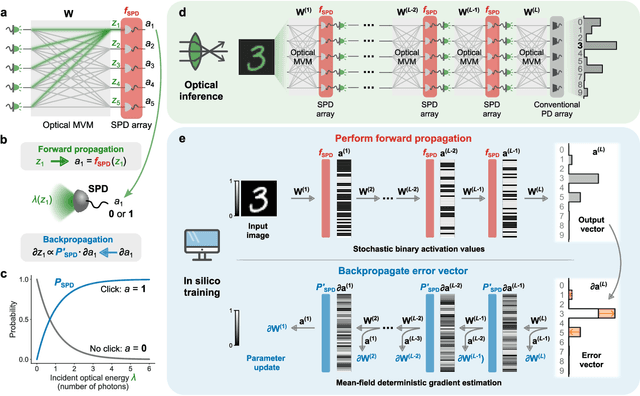
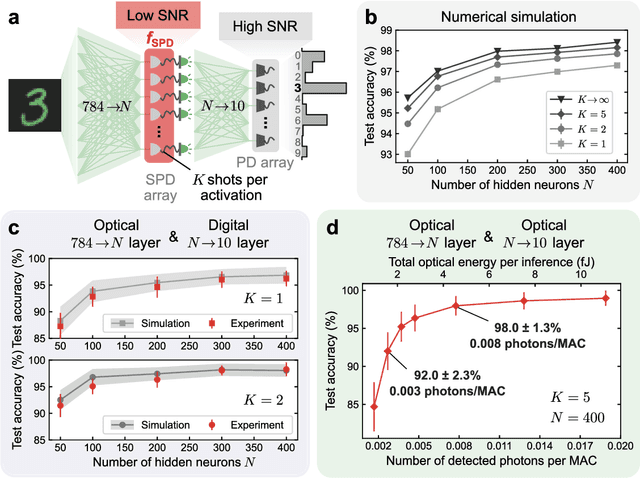
Analog physical neural networks, which hold promise for improved energy efficiency and speed compared to digital electronic neural networks, are nevertheless typically operated in a relatively high-power regime so that the signal-to-noise ratio (SNR) is large (>10). What happens if an analog system is instead operated in an ultra-low-power regime, in which the behavior of the system becomes highly stochastic and the noise is no longer a small perturbation on the signal? In this paper, we study this question in the setting of optical neural networks operated in the limit where some layers use only a single photon to cause a neuron activation. Neuron activations in this limit are dominated by quantum noise from the fundamentally probabilistic nature of single-photon detection of weak optical signals. We show that it is possible to train stochastic optical neural networks to perform deterministic image-classification tasks with high accuracy in spite of the extremely high noise (SNR ~ 1) by using a training procedure that directly models the stochastic behavior of photodetection. We experimentally demonstrated MNIST classification with a test accuracy of 98% using an optical neural network with a hidden layer operating in the single-photon regime; the optical energy used to perform the classification corresponds to 0.008 photons per multiply-accumulate (MAC) operation, which is equivalent to 0.003 attojoules of optical energy per MAC. Our experiment used >40x fewer photons per inference than previous state-of-the-art low-optical-energy demonstrations, to achieve the same accuracy of >90%. Our work shows that some extremely stochastic analog systems, including those operating in the limit where quantum noise dominates, can nevertheless be used as layers in neural networks that deterministically perform classification tasks with high accuracy if they are appropriately trained.
Identity-Preserving Aging of Face Images via Latent Diffusion Models
Jul 17, 2023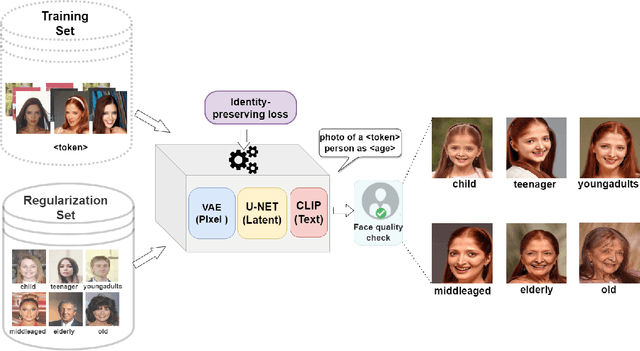
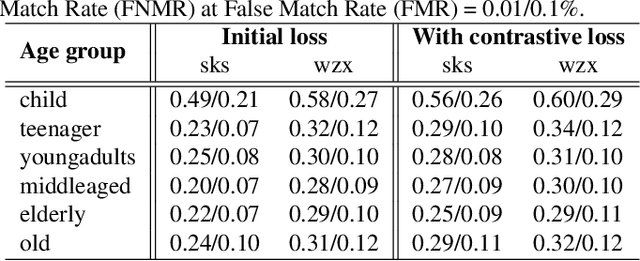

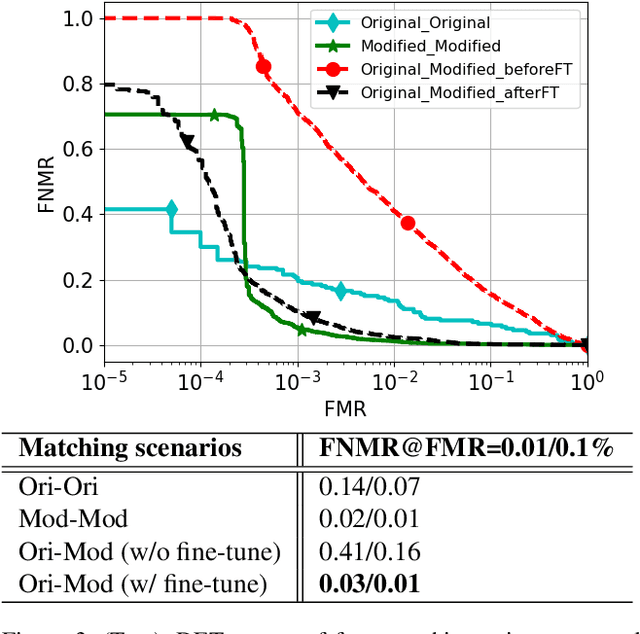
The performance of automated face recognition systems is inevitably impacted by the facial aging process. However, high quality datasets of individuals collected over several years are typically small in scale. In this work, we propose, train, and validate the use of latent text-to-image diffusion models for synthetically aging and de-aging face images. Our models succeed with few-shot training, and have the added benefit of being controllable via intuitive textual prompting. We observe high degrees of visual realism in the generated images while maintaining biometric fidelity measured by commonly used metrics. We evaluate our method on two benchmark datasets (CelebA and AgeDB) and observe significant reduction (~44%) in the False Non-Match Rate compared to existing state-of the-art baselines.
Panoramic Voltage-Sensitive Optical Mapping of Contracting Hearts using Cooperative Multi-View Motion Tracking with 12 to 24 Cameras
Jul 16, 2023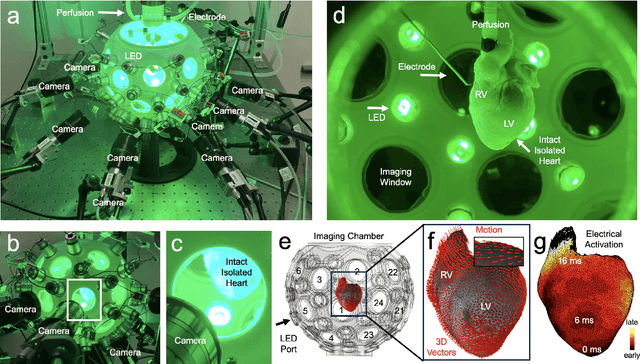

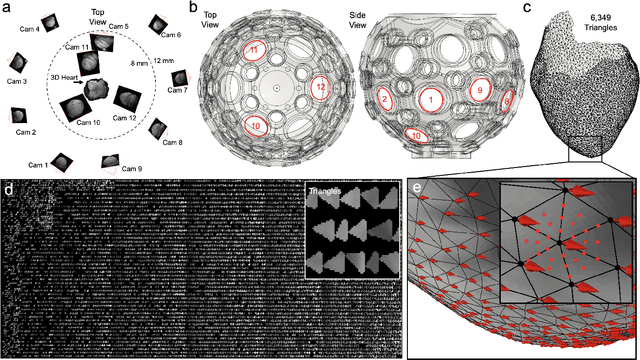
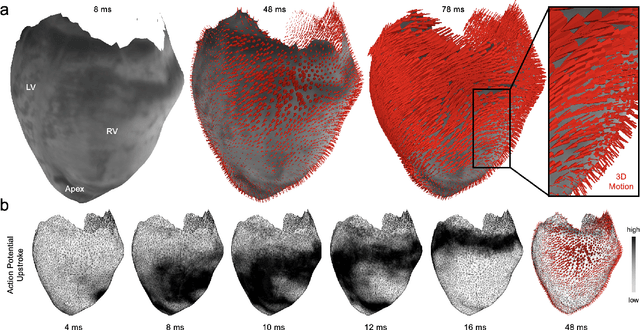
Action potential waves triggering the heart's contractions can be imaged at high spatial and temporal resolutions across the heart surface using voltage-sensitive optical mapping. However, for over three decades, optical mapping has been performed with contraction-inhibited hearts. While it was recently demonstrated that action potential waves can be imaged on parts of the three-dimensional deforming ventricular surface using multi-camera optical mapping, panoramic measurements of action potential waves across the entire beating heart surface remained elusive. Here, we introduce a high-resolution multi-camera optical mapping system consisting of up to 24 high-speed, low-cost cameras with which it is possible to image action potential waves at high resolutions on the entire, strongly deforming ventricular surface of the heart. We imaged isolated hearts inside a custom-designed soccerball-shaped imaging chamber, which facilitates imaging and even illumination with excitation light from all sides in a panoramic fashion. We found that it is possible to image the entire ventricular surface using 12 cameras with 0.5-1.0 megapixels combined resolution. The 12 calibrated cameras generate 1.5 gigabytes of video data per second at imaging speeds of 500 fps, which we process using various computer vision techniques, including three-dimensional cooperative multi-view motion tracking, to generate three-dimensional dynamic reconstructions of the deforming heart surface with corresponding high-resolution voltage-sensitive optical measurements. With our setup, we measured action potential waves at unprecedented resolutions on the contracting three-dimensional surface of rabbit hearts during sinus rhythm, paced rhythm as well as ventricular fibrillation. Our imaging setup defines a new state-of-the-art in the field and can be used to study the heart's electromechanical dynamics during health and disease.
Unraveling the Age Estimation Puzzle: Comparative Analysis of Deep Learning Approaches for Facial Age Estimation
Jul 10, 2023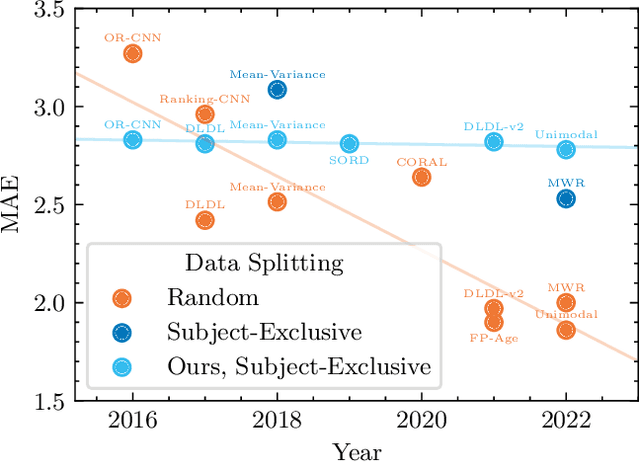
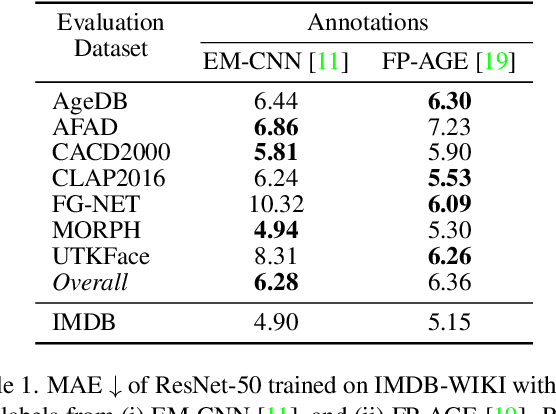

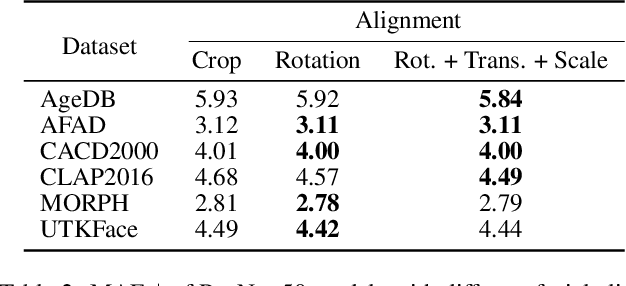
Comparing different age estimation methods poses a challenge due to the unreliability of published results, stemming from inconsistencies in the benchmarking process. Previous studies have reported continuous performance improvements over the past decade using specialized methods; however, our findings challenge these claims. We argue that, for age estimation tasks outside of the low-data regime, designing specialized methods is unnecessary, and the standard approach of utilizing cross-entropy loss is sufficient. This paper aims to address the benchmark shortcomings by evaluating state-of-the-art age estimation methods in a unified and comparable setting. We systematically analyze the impact of various factors, including facial alignment, facial coverage, image resolution, image representation, model architecture, and the amount of data on age estimation results. Surprisingly, these factors often exert a more significant influence than the choice of the age estimation method itself. We assess the generalization capability of each method by evaluating the cross-dataset performance for publicly available age estimation datasets. The results emphasize the importance of using consistent data preprocessing practices and establishing standardized benchmarks to ensure reliable and meaningful comparisons. The source code is available at https://github.com/paplhjak/Facial-Age-Estimation-Benchmark.
Internal-External Boundary Attention Fusion for Glass Surface Segmentation
Jul 01, 2023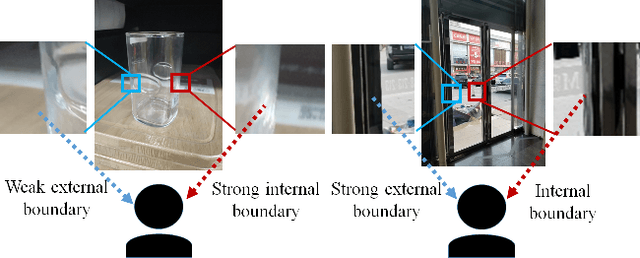
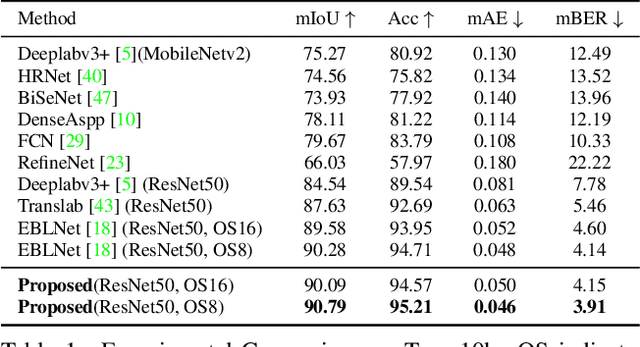
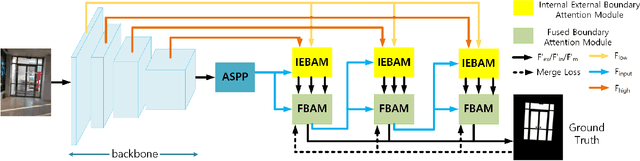
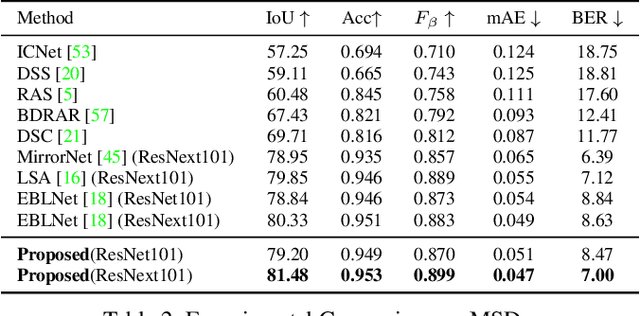
Glass surfaces of transparent objects and mirrors are not able to be uniquely and explicitly characterized by their visual appearances because they contain the visual appearance of other reflected or transmitted surfaces as well. Detecting glass regions from a single-color image is a challenging task. Recent deep-learning approaches have paid attention to the description of glass surface boundary where the transition of visual appearances between glass and non-glass surfaces are observed. In this work, we analytically investigate how glass surface boundary helps to characterize glass objects. Inspired by prior semantic segmentation approaches with challenging image types such as X-ray or CT scans, we propose separated internal-external boundary attention modules that individually learn and selectively integrate visual characteristics of the inside and outside region of glass surface from a single color image. Our proposed method is evaluated on six public benchmarks comparing with state-of-the-art methods showing promising results.
Fast Adversarial CNN-based Perturbation Attack on No-Reference Image- and Video-Quality Metrics
May 24, 2023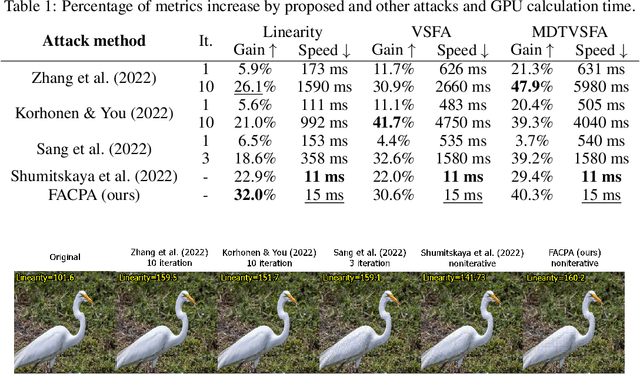
Modern neural-network-based no-reference image- and video-quality metrics exhibit performance as high as full-reference metrics. These metrics are widely used to improve visual quality in computer vision methods and compare video processing methods. However, these metrics are not stable to traditional adversarial attacks, which can cause incorrect results. Our goal is to investigate the boundaries of no-reference metrics applicability, and in this paper, we propose a fast adversarial perturbation attack on no-reference quality metrics. The proposed attack (FACPA) can be exploited as a preprocessing step in real-time video processing and compression algorithms. This research can yield insights to further aid in designing of stable neural-network-based no-reference quality metrics.