 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Cardiac MRI Orientation Recognition and Standardization using Deep Neural Networks
Jul 31, 2023
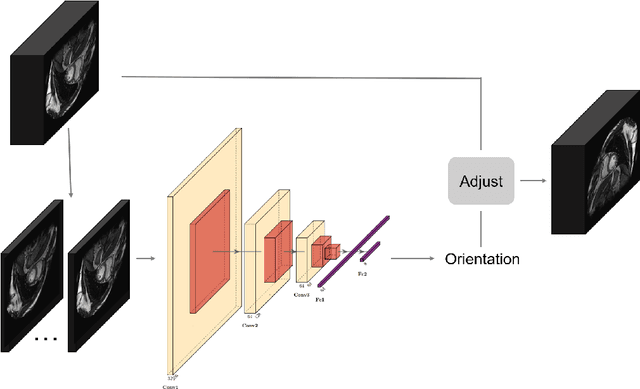
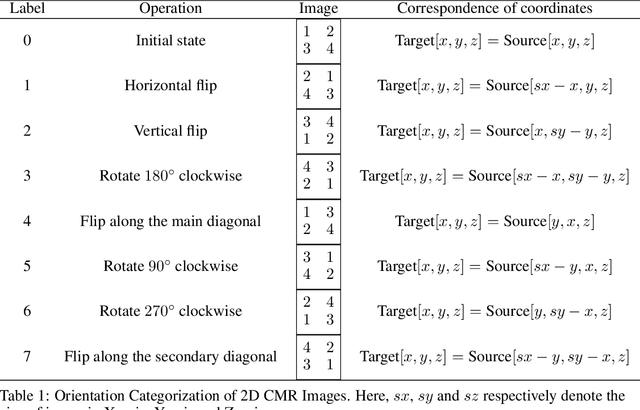
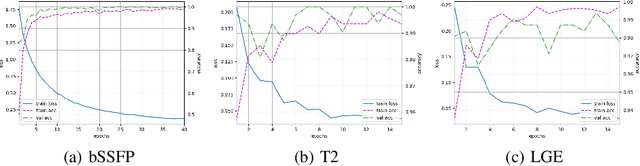

Orientation recognition and standardization play a crucial role in the effectiveness of medical image processing tasks. Deep learning-based methods have proven highly advantageous in orientation recognition and prediction tasks. In this paper, we address the challenge of imaging orientation in cardiac MRI and present a method that employs deep neural networks to categorize and standardize the orientation. To cater to multiple sequences and modalities of MRI, we propose a transfer learning strategy, enabling adaptation of our model from a single modality to diverse modalities. We conducted comprehensive experiments on CMR images from various modalities, including bSSFP, T2, and LGE. The validation accuracies achieved were 100.0\%, 100.0\%, and 99.4\%, confirming the robustness and effectiveness of our model. Our source code and network models are available at https://github.com/rxzhen/MSCMR-orient
ParGANDA: Making Synthetic Pedestrians A Reality For Object Detection
Jul 21, 2023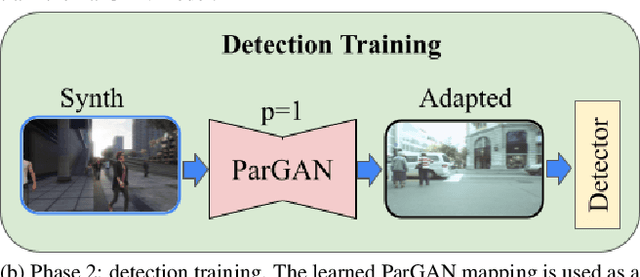



Object detection is the key technique to a number of Computer Vision applications, but it often requires large amounts of annotated data to achieve decent results. Moreover, for pedestrian detection specifically, the collected data might contain some personally identifiable information (PII), which is highly restricted in many countries. This label intensive and privacy concerning task has recently led to an increasing interest in training the detection models using synthetically generated pedestrian datasets collected with a photo-realistic video game engine. The engine is able to generate unlimited amounts of data with precise and consistent annotations, which gives potential for significant gains in the real-world applications. However, the use of synthetic data for training introduces a synthetic-to-real domain shift aggravating the final performance. To close the gap between the real and synthetic data, we propose to use a Generative Adversarial Network (GAN), which performsparameterized unpaired image-to-image translation to generate more realistic images. The key benefit of using the GAN is its intrinsic preference of low-level changes to geometric ones, which means annotations of a given synthetic image remain accurate even after domain translation is performed thus eliminating the need for labeling real data. We extensively experimented with the proposed method using MOTSynth dataset to train and MOT17 and MOT20 detection datasets to test, with experimental results demonstrating the effectiveness of this method. Our approach not only produces visually plausible samples but also does not require any labels of the real domain thus making it applicable to the variety of downstream tasks.
On the use of deep learning for phase recovery
Aug 02, 2023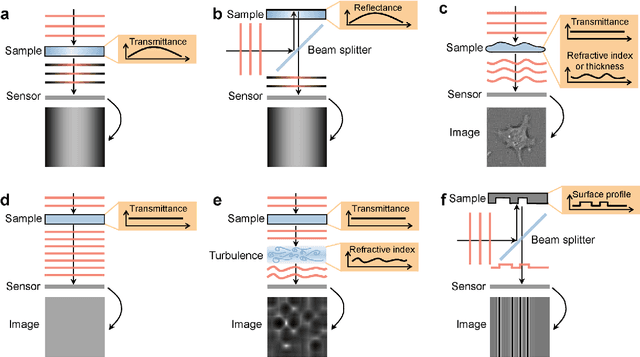
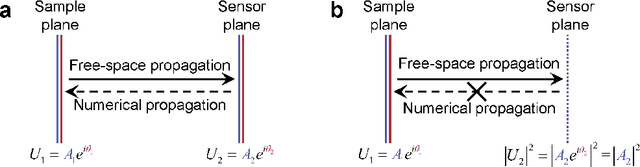
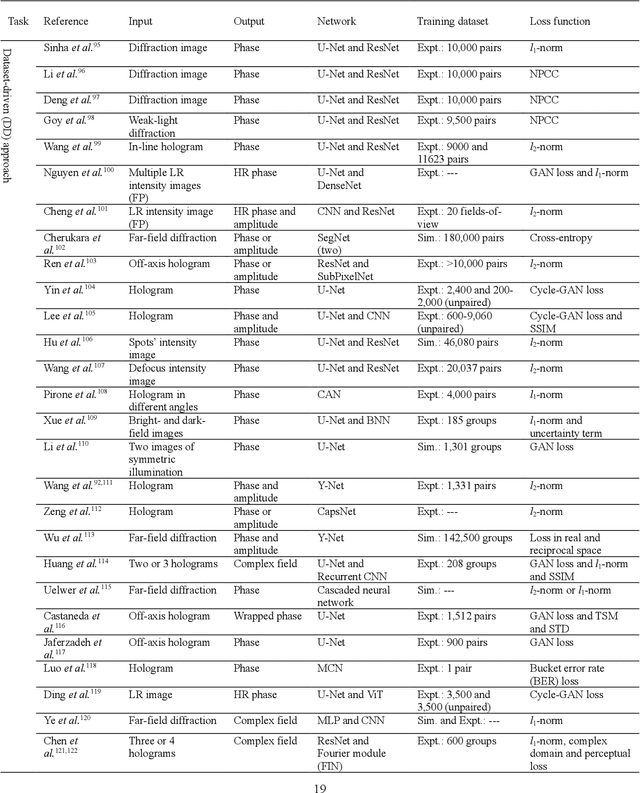
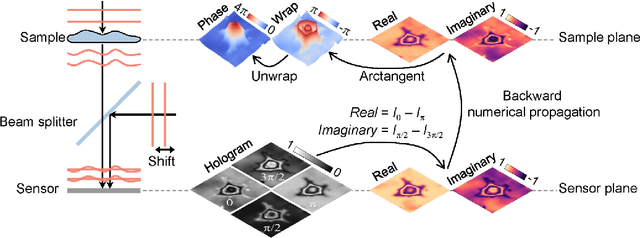
Phase recovery (PR) refers to calculating the phase of the light field from its intensity measurements. As exemplified from quantitative phase imaging and coherent diffraction imaging to adaptive optics, PR is essential for reconstructing the refractive index distribution or topography of an object and correcting the aberration of an imaging system. In recent years, deep learning (DL), often implemented through deep neural networks, has provided unprecedented support for computational imaging, leading to more efficient solutions for various PR problems. In this review, we first briefly introduce conventional methods for PR. Then, we review how DL provides support for PR from the following three stages, namely, pre-processing, in-processing, and post-processing. We also review how DL is used in phase image processing. Finally, we summarize the work in DL for PR and outlook on how to better use DL to improve the reliability and efficiency in PR. Furthermore, we present a live-updating resource (https://github.com/kqwang/phase-recovery) for readers to learn more about PR.
AutoPoster: A Highly Automatic and Content-aware Design System for Advertising Poster Generation
Aug 02, 2023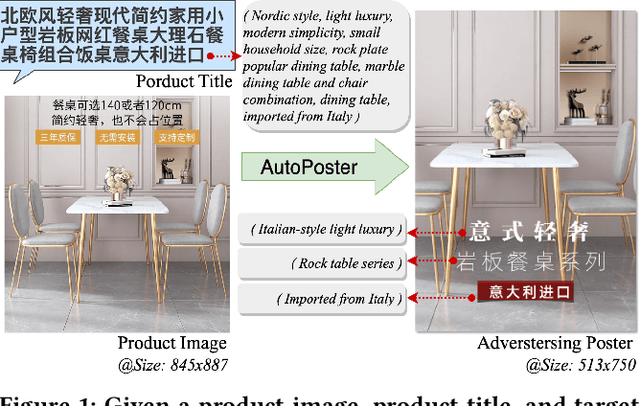

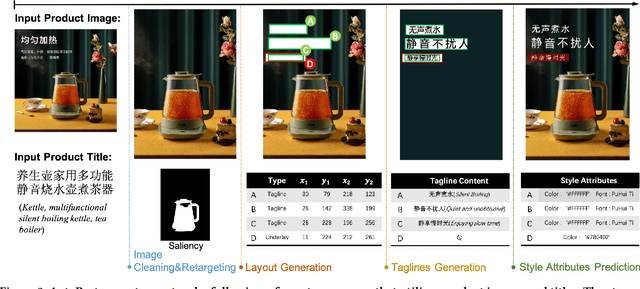

Advertising posters, a form of information presentation, combine visual and linguistic modalities. Creating a poster involves multiple steps and necessitates design experience and creativity. This paper introduces AutoPoster, a highly automatic and content-aware system for generating advertising posters. With only product images and titles as inputs, AutoPoster can automatically produce posters of varying sizes through four key stages: image cleaning and retargeting, layout generation, tagline generation, and style attribute prediction. To ensure visual harmony of posters, two content-aware models are incorporated for layout and tagline generation. Moreover, we propose a novel multi-task Style Attribute Predictor (SAP) to jointly predict visual style attributes. Meanwhile, to our knowledge, we propose the first poster generation dataset that includes visual attribute annotations for over 76k posters. Qualitative and quantitative outcomes from user studies and experiments substantiate the efficacy of our system and the aesthetic superiority of the generated posters compared to other poster generation methods.
Deep Learning for Diverse Data Types Steganalysis: A Review
Aug 08, 2023Steganography and steganalysis are two interrelated aspects of the field of information security. Steganography seeks to conceal communications, whereas steganalysis is aimed to either find them or even, if possible, recover the data they contain. Steganography and steganalysis have attracted a great deal of interest, particularly from law enforcement. Steganography is often used by cybercriminals and even terrorists to avoid being captured while in possession of incriminating evidence, even encrypted, since cryptography is prohibited or restricted in many countries. Therefore, knowledge of cutting-edge techniques to uncover concealed information is crucial in exposing illegal acts. Over the last few years, a number of strong and reliable steganography and steganalysis techniques have been introduced in the literature. This review paper provides a comprehensive overview of deep learning-based steganalysis techniques used to detect hidden information within digital media. The paper covers all types of cover in steganalysis, including image, audio, and video, and discusses the most commonly used deep learning techniques. In addition, the paper explores the use of more advanced deep learning techniques, such as deep transfer learning (DTL) and deep reinforcement learning (DRL), to enhance the performance of steganalysis systems. The paper provides a systematic review of recent research in the field, including data sets and evaluation metrics used in recent studies. It also presents a detailed analysis of DTL-based steganalysis approaches and their performance on different data sets. The review concludes with a discussion on the current state of deep learning-based steganalysis, challenges, and future research directions.
When More is Less: Incorporating Additional Datasets Can Hurt Performance By Introducing Spurious Correlations
Aug 08, 2023In machine learning, incorporating more data is often seen as a reliable strategy for improving model performance; this work challenges that notion by demonstrating that the addition of external datasets in many cases can hurt the resulting model's performance. In a large-scale empirical study across combinations of four different open-source chest x-ray datasets and 9 different labels, we demonstrate that in 43% of settings, a model trained on data from two hospitals has poorer worst group accuracy over both hospitals than a model trained on just a single hospital's data. This surprising result occurs even though the added hospital makes the training distribution more similar to the test distribution. We explain that this phenomenon arises from the spurious correlation that emerges between the disease and hospital, due to hospital-specific image artifacts. We highlight the trade-off one encounters when training on multiple datasets, between the obvious benefit of additional data and insidious cost of the introduced spurious correlation. In some cases, balancing the dataset can remove the spurious correlation and improve performance, but it is not always an effective strategy. We contextualize our results within the literature on spurious correlations to help explain these outcomes. Our experiments underscore the importance of exercising caution when selecting training data for machine learning models, especially in settings where there is a risk of spurious correlations such as with medical imaging. The risks outlined highlight the need for careful data selection and model evaluation in future research and practice.
ScatterUQ: Interactive Uncertainty Visualizations for Multiclass Deep Learning Problems
Aug 08, 2023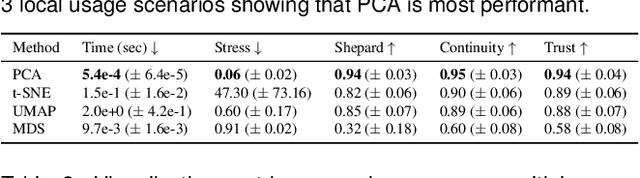
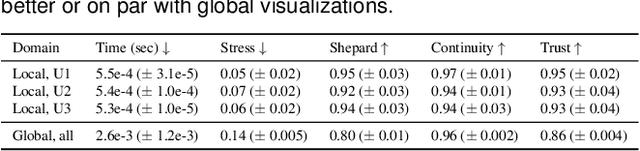
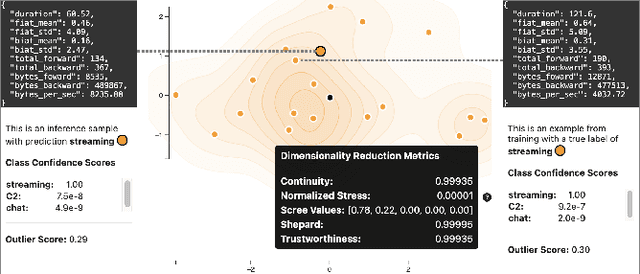
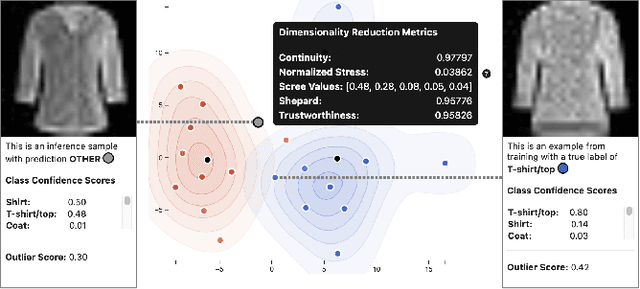
Recently, uncertainty-aware deep learning methods for multiclass labeling problems have been developed that provide calibrated class prediction probabilities and out-of-distribution (OOD) indicators, letting machine learning (ML) consumers and engineers gauge a model's confidence in its predictions. However, this extra neural network prediction information is challenging to scalably convey visually for arbitrary data sources under multiple uncertainty contexts. To address these challenges, we present ScatterUQ, an interactive system that provides targeted visualizations to allow users to better understand model performance in context-driven uncertainty settings. ScatterUQ leverages recent advances in distance-aware neural networks, together with dimensionality reduction techniques, to construct robust, 2-D scatter plots explaining why a model predicts a test example to be (1) in-distribution and of a particular class, (2) in-distribution but unsure of the class, and (3) out-of-distribution. ML consumers and engineers can visually compare the salient features of test samples with training examples through the use of a ``hover callback'' to understand model uncertainty performance and decide follow up courses of action. We demonstrate the effectiveness of ScatterUQ to explain model uncertainty for a multiclass image classification on a distance-aware neural network trained on Fashion-MNIST and tested on Fashion-MNIST (in distribution) and MNIST digits (out of distribution), as well as a deep learning model for a cyber dataset. We quantitatively evaluate dimensionality reduction techniques to optimize our contextually driven UQ visualizations. Our results indicate that the ScatterUQ system should scale to arbitrary, multiclass datasets. Our code is available at https://github.com/mit-ll-responsible-ai/equine-webapp
Online Distillation-enhanced Multi-modal Transformer for Sequential Recommendation
Aug 08, 2023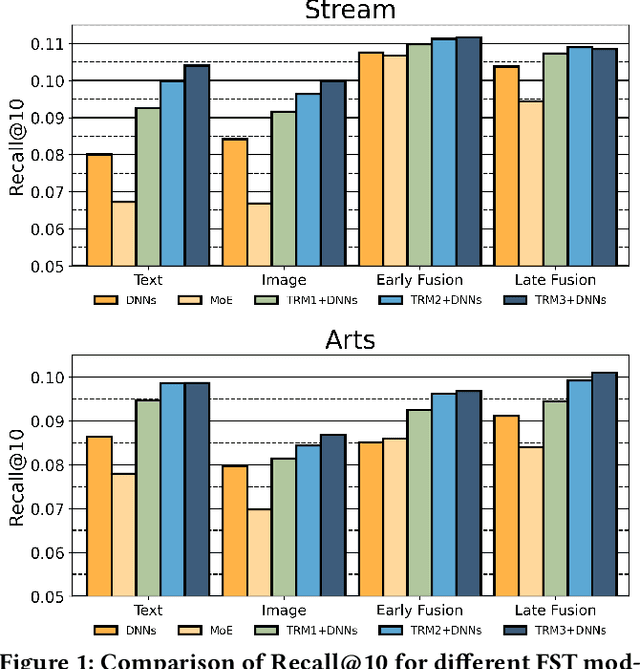
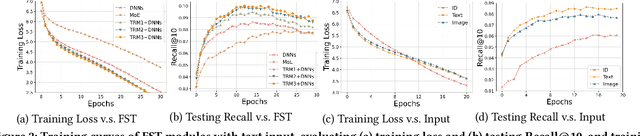
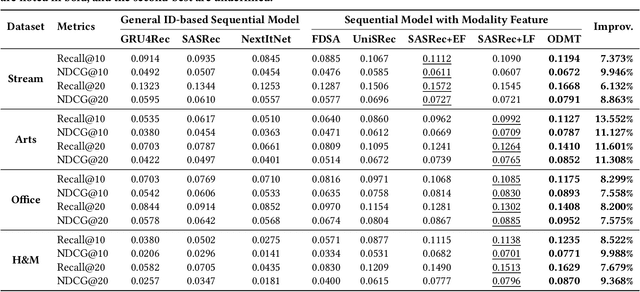
Multi-modal recommendation systems, which integrate diverse types of information, have gained widespread attention in recent years. However, compared to traditional collaborative filtering-based multi-modal recommendation systems, research on multi-modal sequential recommendation is still in its nascent stages. Unlike traditional sequential recommendation models that solely rely on item identifier (ID) information and focus on network structure design, multi-modal recommendation models need to emphasize item representation learning and the fusion of heterogeneous data sources. This paper investigates the impact of item representation learning on downstream recommendation tasks and examines the disparities in information fusion at different stages. Empirical experiments are conducted to demonstrate the need to design a framework suitable for collaborative learning and fusion of diverse information. Based on this, we propose a new model-agnostic framework for multi-modal sequential recommendation tasks, called Online Distillation-enhanced Multi-modal Transformer (ODMT), to enhance feature interaction and mutual learning among multi-source input (ID, text, and image), while avoiding conflicts among different features during training, thereby improving recommendation accuracy. To be specific, we first introduce an ID-aware Multi-modal Transformer module in the item representation learning stage to facilitate information interaction among different features. Secondly, we employ an online distillation training strategy in the prediction optimization stage to make multi-source data learn from each other and improve prediction robustness. Experimental results on a video content recommendation dataset and three e-commerce recommendation datasets demonstrate the effectiveness of the proposed two modules, which is approximately 10% improvement in performance compared to baseline models.
UMat: Uncertainty-Aware Single Image High Resolution Material Capture
May 25, 2023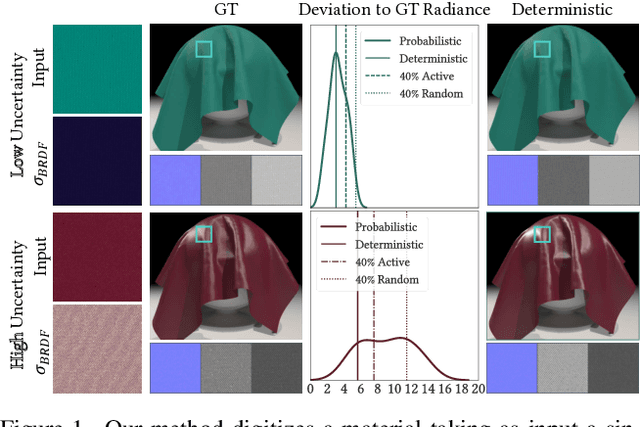
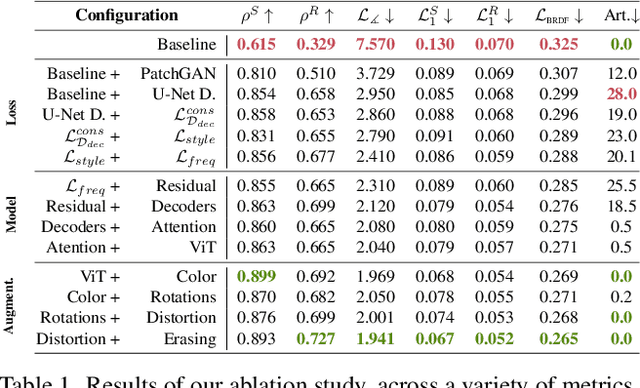

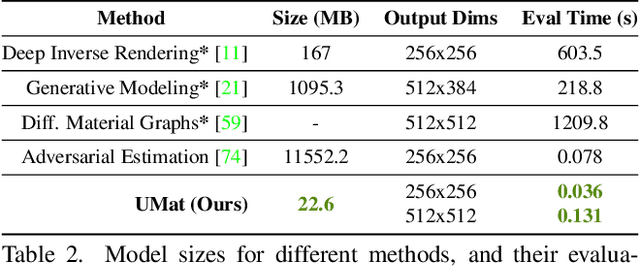
We propose a learning-based method to recover normals, specularity, and roughness from a single diffuse image of a material, using microgeometry appearance as our primary cue. Previous methods that work on single images tend to produce over-smooth outputs with artifacts, operate at limited resolution, or train one model per class with little room for generalization. Previous methods that work on single images tend to produce over-smooth outputs with artifacts, operate at limited resolution, or train one model per class with little room for generalization. In contrast, in this work, we propose a novel capture approach that leverages a generative network with attention and a U-Net discriminator, which shows outstanding performance integrating global information at reduced computational complexity. We showcase the performance of our method with a real dataset of digitized textile materials and show that a commodity flatbed scanner can produce the type of diffuse illumination required as input to our method. Additionally, because the problem might be illposed -more than a single diffuse image might be needed to disambiguate the specular reflection- or because the training dataset is not representative enough of the real distribution, we propose a novel framework to quantify the model's confidence about its prediction at test time. Our method is the first one to deal with the problem of modeling uncertainty in material digitization, increasing the trustworthiness of the process and enabling more intelligent strategies for dataset creation, as we demonstrate with an active learning experiment.
Integrating Listwise Ranking into Pairwise-based Image-Text Retrieval
May 26, 2023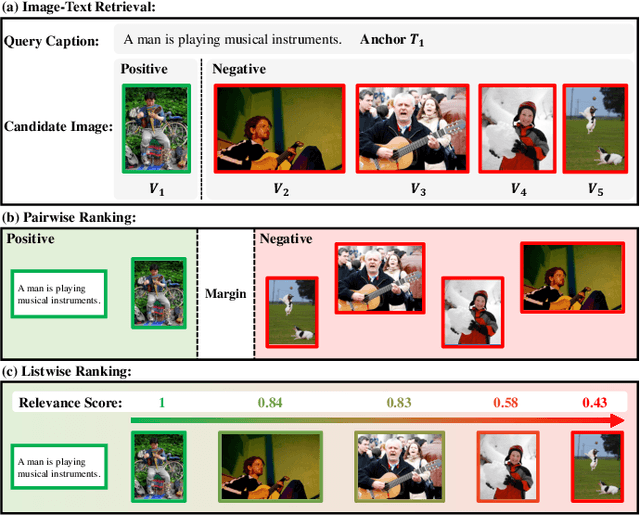

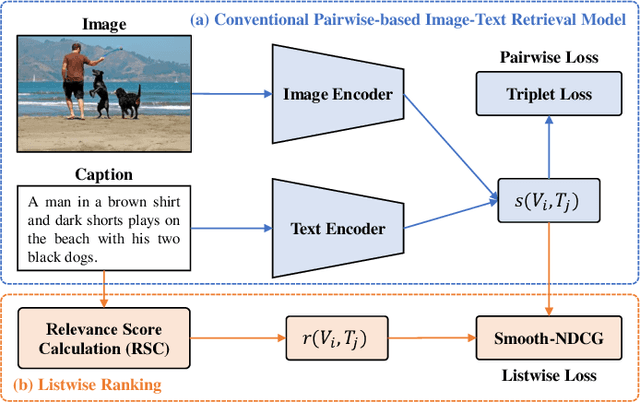
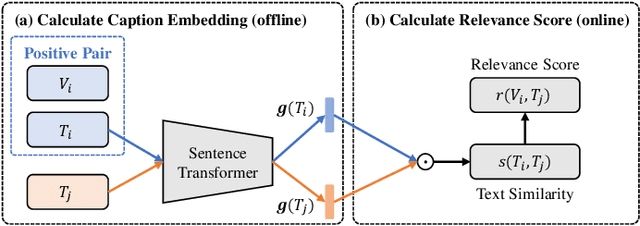
Image-Text Retrieval (ITR) is essentially a ranking problem. Given a query caption, the goal is to rank candidate images by relevance, from large to small. The current ITR datasets are constructed in a pairwise manner. Image-text pairs are annotated as positive or negative. Correspondingly, ITR models mainly use pairwise losses, such as triplet loss, to learn to rank. Pairwise-based ITR increases positive pair similarity while decreasing negative pair similarity indiscriminately. However, the relevance between dissimilar negative pairs is different. Pairwise annotations cannot reflect this difference in relevance. In the current datasets, pairwise annotations miss many correlations. There are many potential positive pairs among the pairs labeled as negative. Pairwise-based ITR can only rank positive samples before negative samples, but cannot rank negative samples by relevance. In this paper, we integrate listwise ranking into conventional pairwise-based ITR. Listwise ranking optimizes the entire ranking list based on relevance scores. Specifically, we first propose a Relevance Score Calculation (RSC) module to calculate the relevance score of the entire ranked list. Then we choose the ranking metric, Normalized Discounted Cumulative Gain (NDCG), as the optimization objective. We transform the non-differentiable NDCG into a differentiable listwise loss, named Smooth-NDCG (S-NDCG). Our listwise ranking approach can be plug-and-play integrated into current pairwise-based ITR models. Experiments on ITR benchmarks show that integrating listwise ranking can improve the performance of current ITR models and provide more user-friendly retrieval results. The code is available at https://github.com/AAA-Zheng/Listwise_ITR.