 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuiding Evolutionary AutoEncoder Training with Activation-Based Pruning Operators
May 08, 2025



This study explores a novel approach to neural network pruning using evolutionary computation, focusing on simultaneously pruning the encoder and decoder of an autoencoder. We introduce two new mutation operators that use layer activations to guide weight pruning. Our findings reveal that one of these activation-informed operators outperforms random pruning, resulting in more efficient autoencoders with comparable performance to canonically trained models. Prior work has established that autoencoder training is effective and scalable with a spatial coevolutionary algorithm that cooperatively coevolves a population of encoders with a population of decoders, rather than one autoencoder. We evaluate how the same activity-guided mutation operators transfer to this context. We find that random pruning is better than guided pruning, in the coevolutionary setting. This suggests activation-based guidance proves more effective in low-dimensional pruning environments, where constrained sample spaces can lead to deviations from true uniformity in randomization. Conversely, population-driven strategies enhance robustness by expanding the total pruning dimensionality, achieving statistically uniform randomness that better preserves system dynamics. We experiment with pruning according to different schedules and present best combinations of operator and schedule for the canonical and coevolving populations cases.
ScatterUQ: Interactive Uncertainty Visualizations for Multiclass Deep Learning Problems
Aug 08, 2023Recently, uncertainty-aware deep learning methods for multiclass labeling problems have been developed that provide calibrated class prediction probabilities and out-of-distribution (OOD) indicators, letting machine learning (ML) consumers and engineers gauge a model's confidence in its predictions. However, this extra neural network prediction information is challenging to scalably convey visually for arbitrary data sources under multiple uncertainty contexts. To address these challenges, we present ScatterUQ, an interactive system that provides targeted visualizations to allow users to better understand model performance in context-driven uncertainty settings. ScatterUQ leverages recent advances in distance-aware neural networks, together with dimensionality reduction techniques, to construct robust, 2-D scatter plots explaining why a model predicts a test example to be (1) in-distribution and of a particular class, (2) in-distribution but unsure of the class, and (3) out-of-distribution. ML consumers and engineers can visually compare the salient features of test samples with training examples through the use of a ``hover callback'' to understand model uncertainty performance and decide follow up courses of action. We demonstrate the effectiveness of ScatterUQ to explain model uncertainty for a multiclass image classification on a distance-aware neural network trained on Fashion-MNIST and tested on Fashion-MNIST (in distribution) and MNIST digits (out of distribution), as well as a deep learning model for a cyber dataset. We quantitatively evaluate dimensionality reduction techniques to optimize our contextually driven UQ visualizations. Our results indicate that the ScatterUQ system should scale to arbitrary, multiclass datasets. Our code is available at https://github.com/mit-ll-responsible-ai/equine-webapp
Extensible Machine Learning for Encrypted Network Traffic Application Labeling via Uncertainty Quantification
May 11, 2022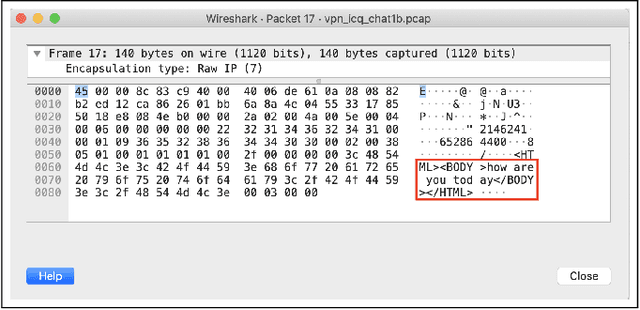
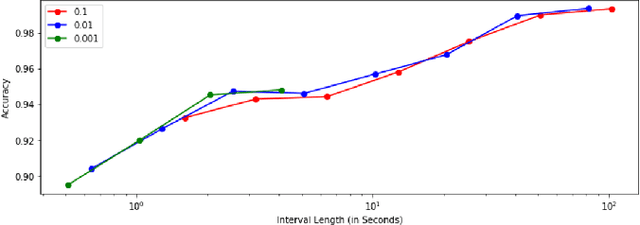
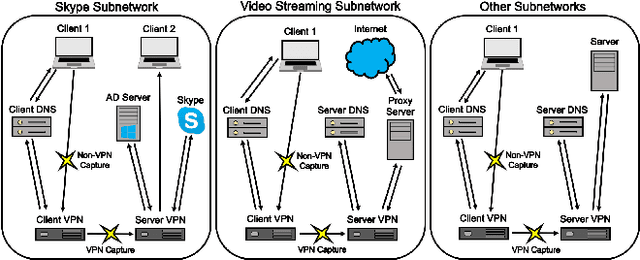
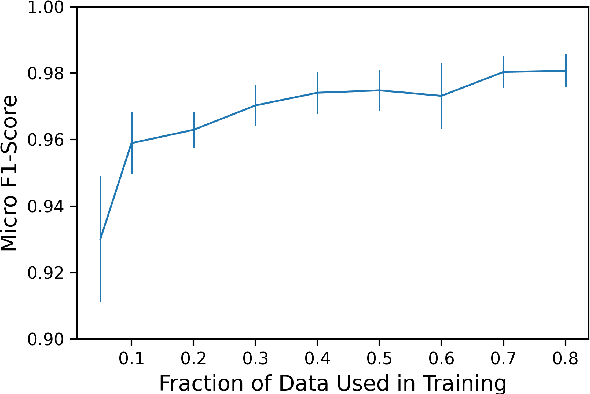
With the increasing prevalence of encrypted network traffic, cyber security analysts have been turning to machine learning (ML) techniques to elucidate the traffic on their networks. However, ML models can become stale as known traffic features can shift between networks and as new traffic emerges that is outside of the distribution of the training set. In order to reliably adapt in this dynamic environment, ML models must additionally provide contextualized uncertainty quantification to their predictions, which has received little attention in the cyber security domain. Uncertainty quantification is necessary both to signal when the model is uncertain about which class to choose in its label assignment and when the traffic is not likely to belong to any pre-trained classes. We present a new, public dataset of network traffic that includes labeled, Virtual Private Network (VPN)-encrypted network traffic generated by 10 applications and corresponding to 5 application categories. We also present an ML framework that is designed to rapidly train with modest data requirements and provide both calibrated, predictive probabilities as well as an interpretable ``out-of-distribution'' (OOD) score to flag novel traffic samples. We describe how to compute a calibrated OOD score from p-values of the so-called relative Mahalanobis distance. We demonstrate that our framework achieves an F1 score of 0.98 on our dataset and that it can extend to an enterprise network by testing the model: (1) on data from similar applications, (2) on dissimilar application traffic from an existing category, and (3) on application traffic from a new category. The model correctly flags uncertain traffic and, upon retraining, accurately incorporates the new data. We additionally demonstrate good performance (F1 score of 0.97) when packet sizes are made to be uniform, as occurs for certain encryption protocols.