 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Table and Image Generation for Investigating Knowledge of Entities in Pre-trained Vision and Language Models
Jun 03, 2023
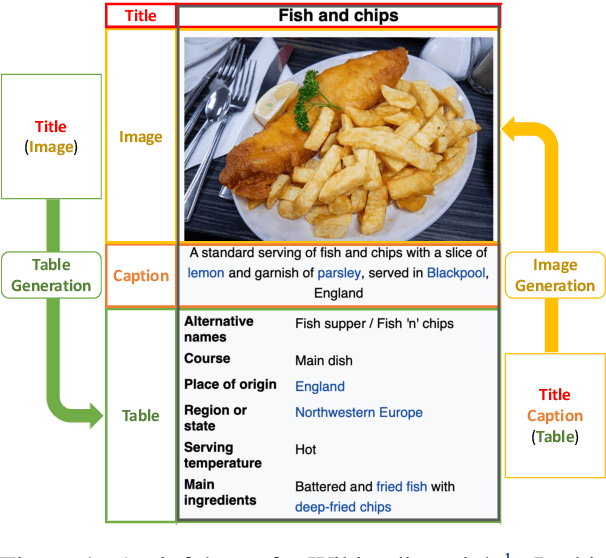

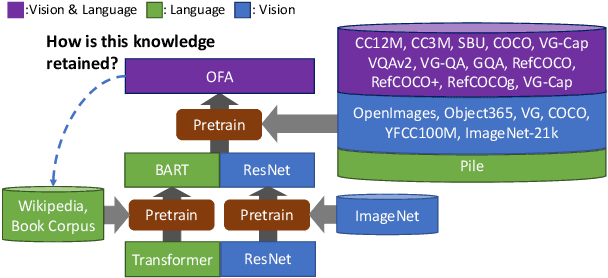
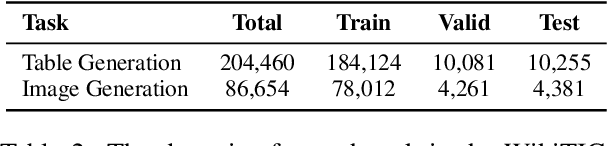
In this paper, we propose a table and image generation task to verify how the knowledge about entities acquired from natural language is retained in Vision & Language (V & L) models. This task consists of two parts: the first is to generate a table containing knowledge about an entity and its related image, and the second is to generate an image from an entity with a caption and a table containing related knowledge of the entity. In both tasks, the model must know the entities used to perform the generation properly. We created the Wikipedia Table and Image Generation (WikiTIG) dataset from about 200,000 infoboxes in English Wikipedia articles to perform the proposed tasks. We evaluated the performance on the tasks with respect to the above research question using the V & L model OFA, which has achieved state-of-the-art results in multiple tasks. Experimental results show that OFA forgets part of its entity knowledge by pre-training as a complement to improve the performance of image related tasks.
Exploring the Grounding Issues in Image Caption
May 24, 2023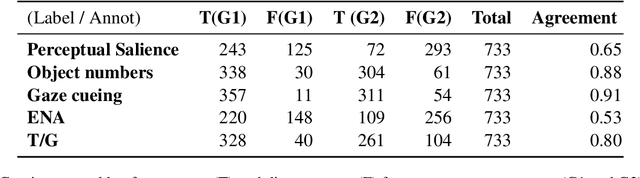
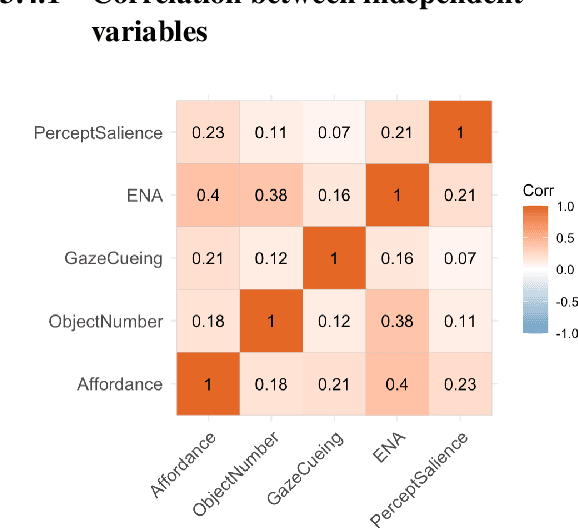
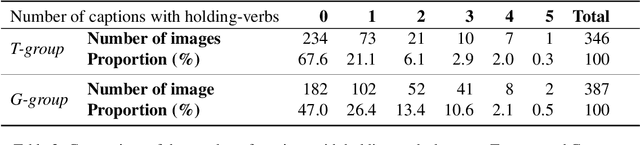

This paper explores the grounding issue concerning multimodal semantic representation from a computational cognitive-linguistic view. Five perceptual properties of groundedness are annotated and analyzed: Affordance, Perceptual salience, Object number, Gaze cueing, and Ecological Niche Association (ENA). We annotated selected images from the Flickr30k dataset with exploratory analyses and statistical modeling of their captions. Our findings suggest that a comprehensive understanding of an object or event requires cognitive attention, semantic distinctions in linguistic expression, and multimodal construction. During this construction process, viewers integrate situated meaning and affordance into multimodal semantics, which is consolidated into image captions used in the image-text dataset incorporating visual and textual elements. Our findings suggest that situated meaning and affordance grounding are critical for grounded natural language understanding systems to generate appropriate responses and show the potential to advance the understanding of human construal in diverse situations.
Enhanced Masked Image Modeling for Analysis of Dental Panoramic Radiographs
Jun 18, 2023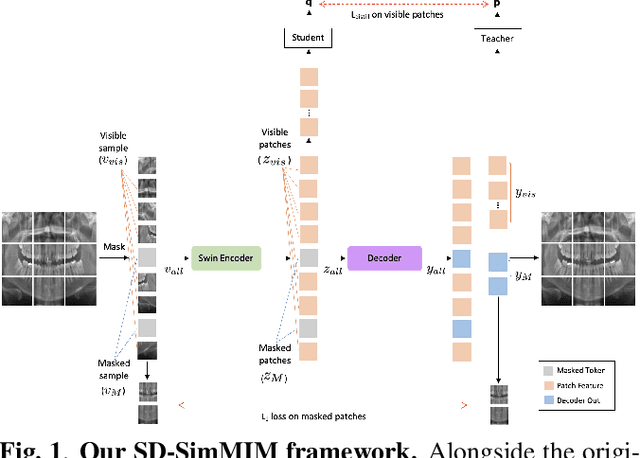
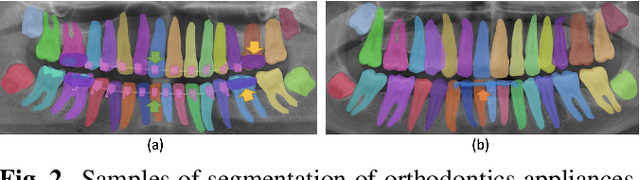
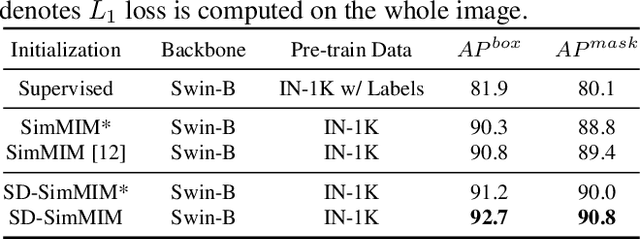
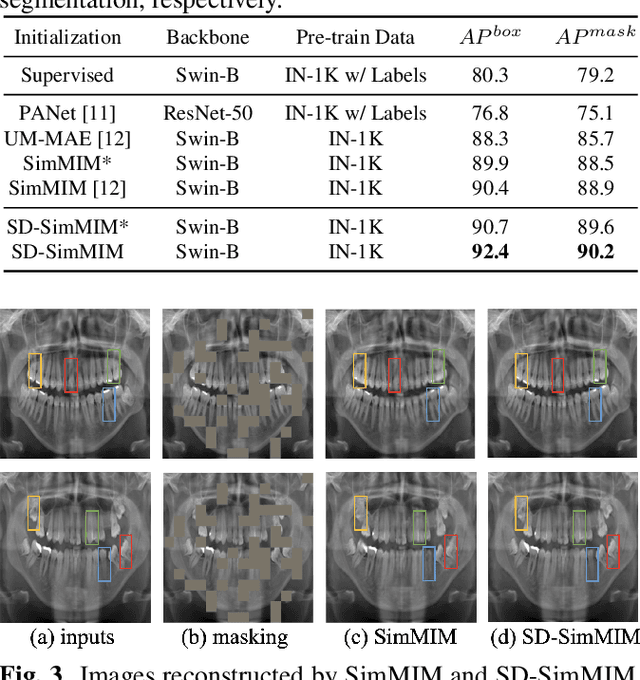
The computer-assisted radiologic informative report has received increasing research attention to facilitate diagnosis and treatment planning for dental care providers. However, manual interpretation of dental images is limited, expensive, and time-consuming. Another barrier in dental imaging is the limited number of available images for training, which is a challenge in the era of deep learning. This study proposes a novel self-distillation (SD) enhanced self-supervised learning on top of the masked image modeling (SimMIM) Transformer, called SD-SimMIM, to improve the outcome with a limited number of dental radiographs. In addition to the prediction loss on masked patches, SD-SimMIM computes the self-distillation loss on the visible patches. We apply SD-SimMIM on dental panoramic X-rays for teeth numbering, detection of dental restorations and orthodontic appliances, and instance segmentation tasks. Our results show that SD-SimMIM outperforms other self-supervised learning methods. Furthermore, we augment and improve the annotation of an existing dataset of panoramic X-rays.
Efficient Contextformer: Spatio-Channel Window Attention for Fast Context Modeling in Learned Image Compression
Jun 25, 2023
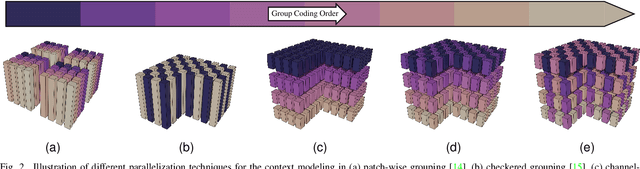
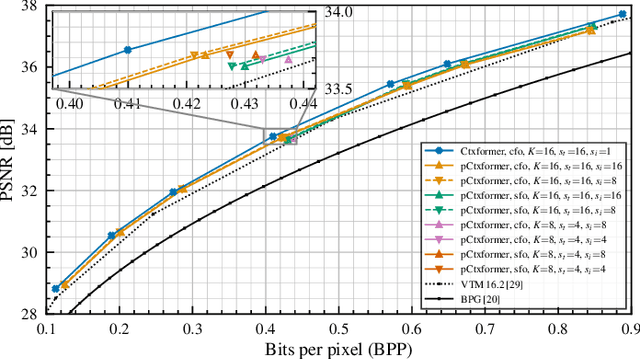
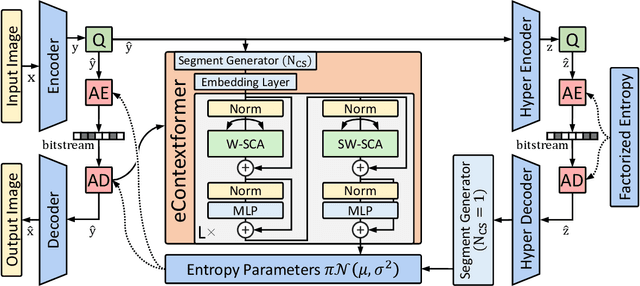
In this work, we introduce Efficient Contextformer (eContextformer) for context modeling in lossy learned image compression, which is built upon our previous work, Contextformer. The eContextformer combines the recent advancements in efficient transformers and fast context models with the spatio-channel attention mechanism. The proposed model enables content-adaptive exploitation of the spatial and channel-wise latent dependencies for a high performance and efficient entropy modeling. By incorporating several innovations, the eContextformer features improved decoding speed, model complexity and rate-distortion performance over previous work. For instance, compared to Contextformer, the eContextformer requires 145x less model complexity, 210x less decoding speed and achieves higher average bit savings on the Kodak, CLIC2020 and Tecnick datasets. Compared to the standard Versatile Video Coding (VVC) Test Model (VTM) 16.2, the proposed model provides up to 17.1% bitrate savings and surpasses various learning-based models.
AC-Norm: Effective Tuning for Medical Image Analysis via Affine Collaborative Normalization
Jul 28, 2023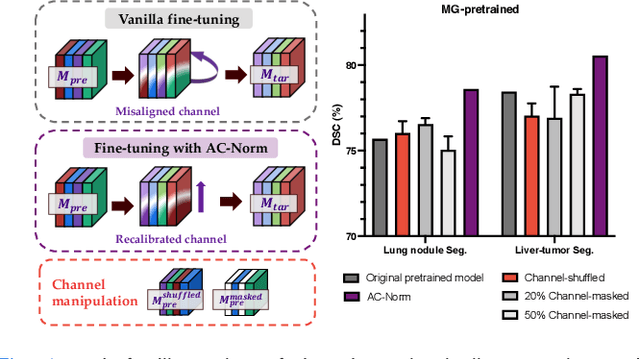
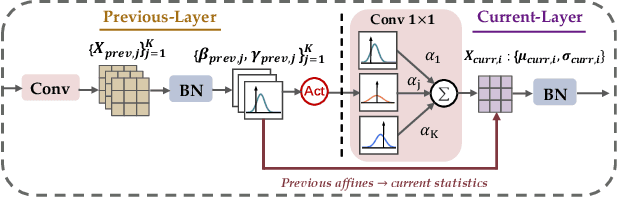
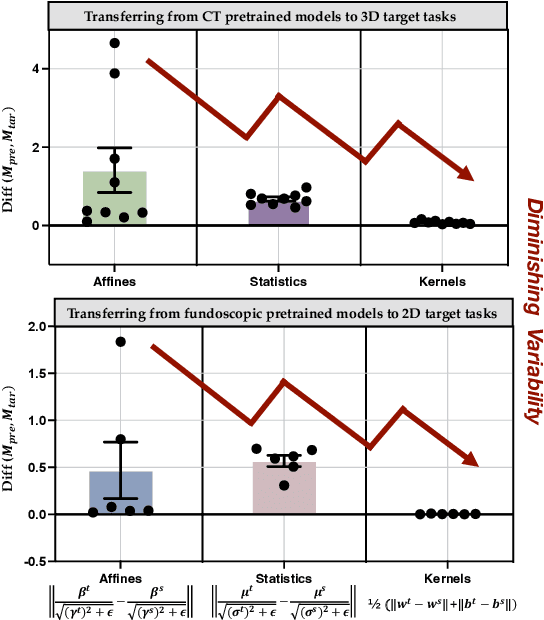
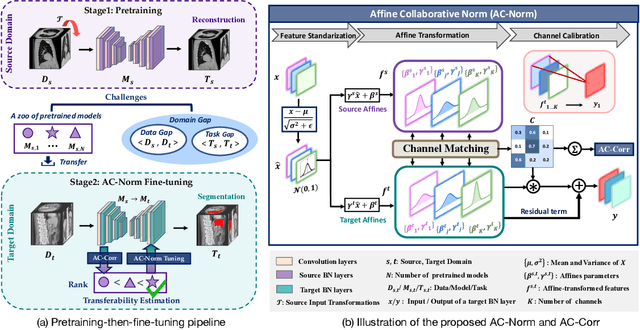
Driven by the latest trend towards self-supervised learning (SSL), the paradigm of "pretraining-then-finetuning" has been extensively explored to enhance the performance of clinical applications with limited annotations. Previous literature on model finetuning has mainly focused on regularization terms and specific policy models, while the misalignment of channels between source and target models has not received sufficient attention. In this work, we revisited the dynamics of batch normalization (BN) layers and observed that the trainable affine parameters of BN serve as sensitive indicators of domain information. Therefore, Affine Collaborative Normalization (AC-Norm) is proposed for finetuning, which dynamically recalibrates the channels in the target model according to the cross-domain channel-wise correlations without adding extra parameters. Based on a single-step backpropagation, AC-Norm can also be utilized to measure the transferability of pretrained models. We evaluated AC-Norm against the vanilla finetuning and state-of-the-art fine-tuning methods on transferring diverse pretrained models to the diabetic retinopathy grade classification, retinal vessel segmentation, CT lung nodule segmentation/classification, CT liver-tumor segmentation and MRI cardiac segmentation tasks. Extensive experiments demonstrate that AC-Norm unanimously outperforms the vanilla finetuning by up to 4% improvement, even under significant domain shifts where the state-of-the-art methods bring no gains. We also prove the capability of AC-Norm in fast transferability estimation. Our code is available at https://github.com/EndoluminalSurgicalVision-IMR/ACNorm.
Generalizable Synthetic Image Detection via Language-guided Contrastive Learning
May 23, 2023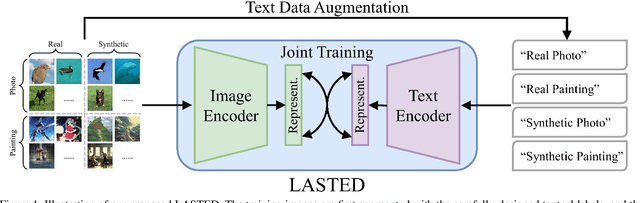

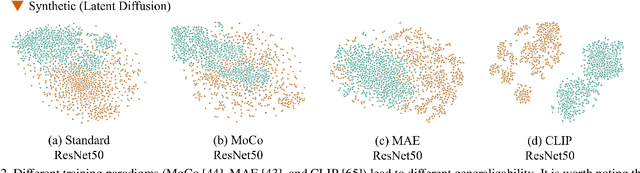
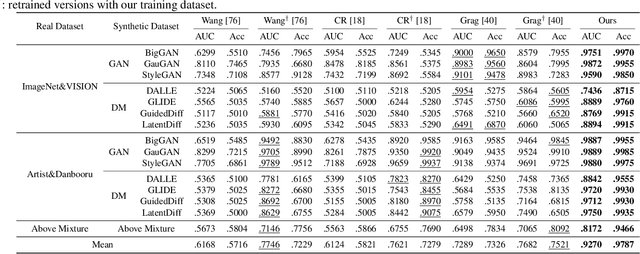
The heightened realism of AI-generated images can be attributed to the rapid development of synthetic models, including generative adversarial networks (GANs) and diffusion models (DMs). The malevolent use of synthetic images, such as the dissemination of fake news or the creation of fake profiles, however, raises significant concerns regarding the authenticity of images. Though many forensic algorithms have been developed for detecting synthetic images, their performance, especially the generalization capability, is still far from being adequate to cope with the increasing number of synthetic models. In this work, we propose a simple yet very effective synthetic image detection method via a language-guided contrastive learning and a new formulation of the detection problem. We first augment the training images with carefully-designed textual labels, enabling us to use a joint image-text contrastive learning for the forensic feature extraction. In addition, we formulate the synthetic image detection as an identification problem, which is vastly different from the traditional classification-based approaches. It is shown that our proposed LanguAge-guided SynThEsis Detection (LASTED) model achieves much improved generalizability to unseen image generation models and delivers promising performance that far exceeds state-of-the-art competitors by +22.66% accuracy and +15.24% AUC. The code is available at https://github.com/HighwayWu/LASTED.
StyleAvatar3D: Leveraging Image-Text Diffusion Models for High-Fidelity 3D Avatar Generation
May 31, 2023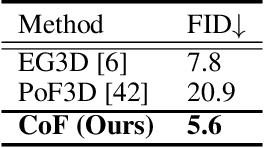
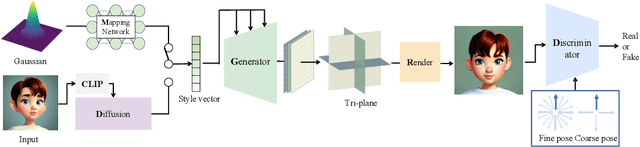


The recent advancements in image-text diffusion models have stimulated research interest in large-scale 3D generative models. Nevertheless, the limited availability of diverse 3D resources presents significant challenges to learning. In this paper, we present a novel method for generating high-quality, stylized 3D avatars that utilizes pre-trained image-text diffusion models for data generation and a Generative Adversarial Network (GAN)-based 3D generation network for training. Our method leverages the comprehensive priors of appearance and geometry offered by image-text diffusion models to generate multi-view images of avatars in various styles. During data generation, we employ poses extracted from existing 3D models to guide the generation of multi-view images. To address the misalignment between poses and images in data, we investigate view-specific prompts and develop a coarse-to-fine discriminator for GAN training. We also delve into attribute-related prompts to increase the diversity of the generated avatars. Additionally, we develop a latent diffusion model within the style space of StyleGAN to enable the generation of avatars based on image inputs. Our approach demonstrates superior performance over current state-of-the-art methods in terms of visual quality and diversity of the produced avatars.
Can Self-Supervised Representation Learning Methods Withstand Distribution Shifts and Corruptions?
Jul 31, 2023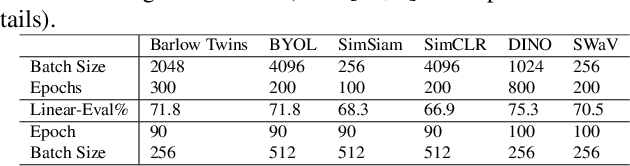
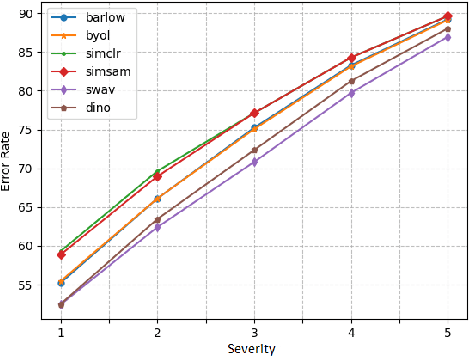
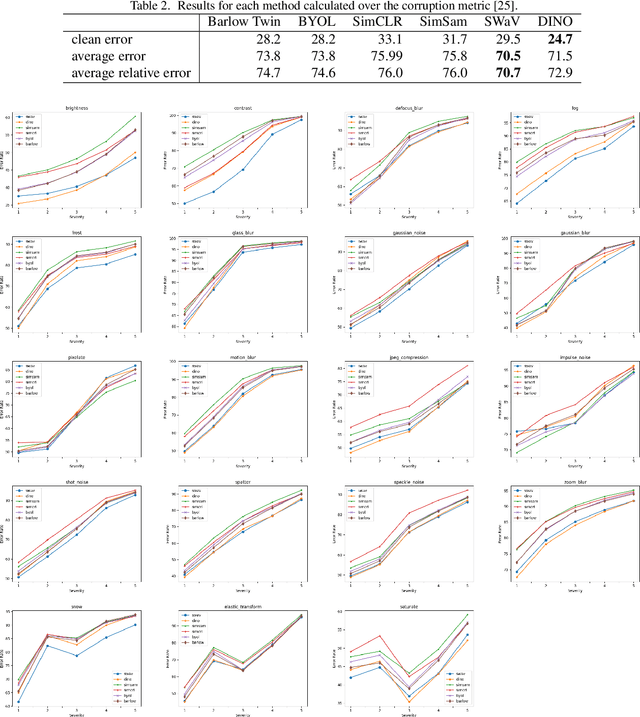

Self-supervised learning in computer vision aims to leverage the inherent structure and relationships within data to learn meaningful representations without explicit human annotation, enabling a holistic understanding of visual scenes. Robustness in vision machine learning ensures reliable and consistent performance, enhancing generalization, adaptability, and resistance to noise, variations, and adversarial attacks. Self-supervised paradigms, namely contrastive learning, knowledge distillation, mutual information maximization, and clustering, have been considered to have shown advances in invariant learning representations. This work investigates the robustness of learned representations of self-supervised learning approaches focusing on distribution shifts and image corruptions in computer vision. Detailed experiments have been conducted to study the robustness of self-supervised learning methods on distribution shifts and image corruptions. The empirical analysis demonstrates a clear relationship between the performance of learned representations within self-supervised paradigms and the severity of distribution shifts and corruptions. Notably, higher levels of shifts and corruptions are found to significantly diminish the robustness of the learned representations. These findings highlight the critical impact of distribution shifts and image corruptions on the performance and resilience of self-supervised learning methods, emphasizing the need for effective strategies to mitigate their adverse effects. The study strongly advocates for future research in the field of self-supervised representation learning to prioritize the key aspects of safety and robustness in order to ensure practical applicability. The source code and results are available on GitHub.
A Study on Quantifying Sim2Real Image Gap in Autonomous Driving Simulations Using Lane Segmentation Attention Map Similarity
Jun 18, 2023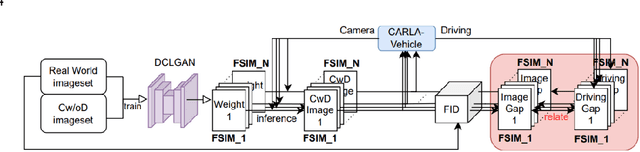
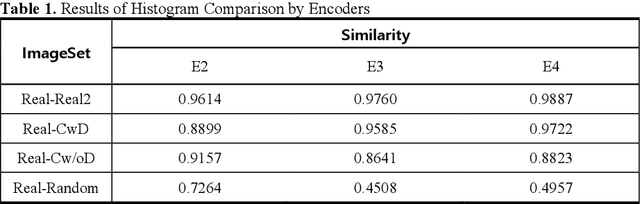
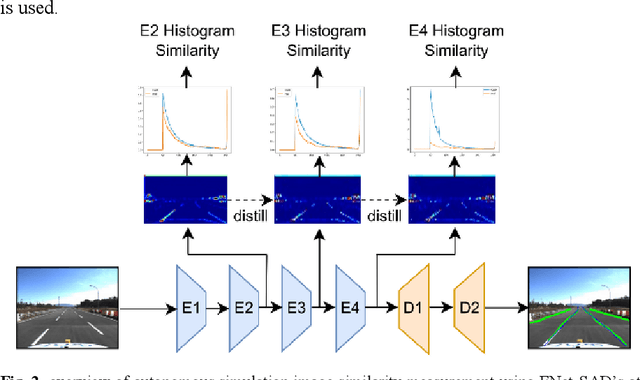

Autonomous driving simulations require highly realistic images. Our preliminary study found that when the CARLA Simulator image was made more like reality by using DCLGAN, the performance of the lane recognition model improved to levels comparable to real-world driving. It was also confirmed that the vehicle's ability to return to the center of the lane after deviating from it improved significantly. However, there is currently no agreed-upon metric for quantitatively evaluating the realism of simulation images. To address this issue, based on the idea that FID (Fr\'echet Inception Distance) measures the feature vector distribution distance using a pre-trained model, this paper proposes a metric that measures the similarity of simulation road images using the attention map from the self-attention distillation process of ENet-SAD. Finally, this paper verified the suitability of the measurement method by applying it to the image of the CARLA map that implemented a realworld autonomous driving test road.
PUGAN: Physical Model-Guided Underwater Image Enhancement Using GAN with Dual-Discriminators
Jun 15, 2023
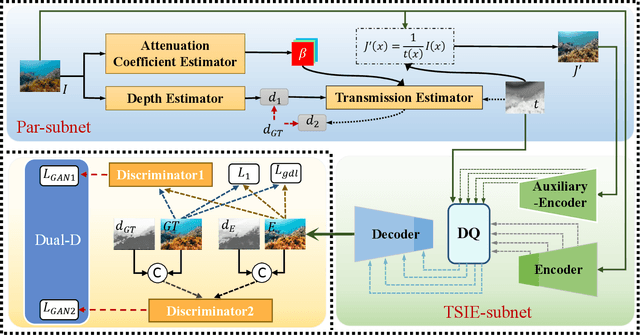
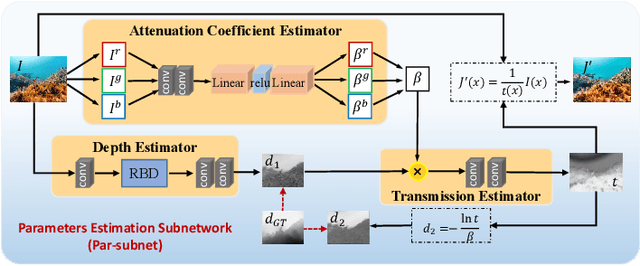
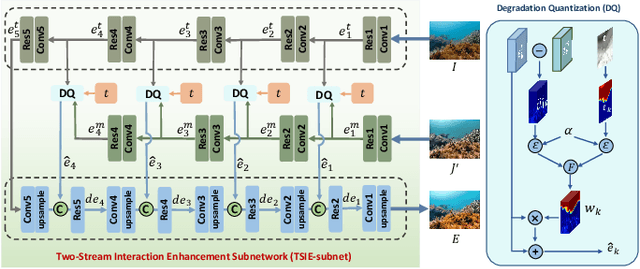
Due to the light absorption and scattering induced by the water medium, underwater images usually suffer from some degradation problems, such as low contrast, color distortion, and blurring details, which aggravate the difficulty of downstream underwater understanding tasks. Therefore, how to obtain clear and visually pleasant images has become a common concern of people, and the task of underwater image enhancement (UIE) has also emerged as the times require. Among existing UIE methods, Generative Adversarial Networks (GANs) based methods perform well in visual aesthetics, while the physical model-based methods have better scene adaptability. Inheriting the advantages of the above two types of models, we propose a physical model-guided GAN model for UIE in this paper, referred to as PUGAN. The entire network is under the GAN architecture. On the one hand, we design a Parameters Estimation subnetwork (Par-subnet) to learn the parameters for physical model inversion, and use the generated color enhancement image as auxiliary information for the Two-Stream Interaction Enhancement sub-network (TSIE-subnet). Meanwhile, we design a Degradation Quantization (DQ) module in TSIE-subnet to quantize scene degradation, thereby achieving reinforcing enhancement of key regions. On the other hand, we design the Dual-Discriminators for the style-content adversarial constraint, promoting the authenticity and visual aesthetics of the results. Extensive experiments on three benchmark datasets demonstrate that our PUGAN outperforms state-of-the-art methods in both qualitative and quantitative metrics.