 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBit Distribution Study and Implementation of Spatial Quality Map in the JPEG-AI Standardization
Feb 27, 2024Currently, there is a high demand for neural network-based image compression codecs. These codecs employ non-linear transforms to create compact bit representations and facilitate faster coding speeds on devices compared to the hand-crafted transforms used in classical frameworks. The scientific and industrial communities are highly interested in these properties, leading to the standardization effort of JPEG-AI. The JPEG-AI verification model has been released and is currently under development for standardization. Utilizing neural networks, it can outperform the classic codec VVC intra by over 10% BD-rate operating at base operation point. Researchers attribute this success to the flexible bit distribution in the spatial domain, in contrast to VVC intra's anchor that is generated with a constant quality point. However, our study reveals that VVC intra displays a more adaptable bit distribution structure through the implementation of various block sizes. As a result of our observations, we have proposed a spatial bit allocation method to optimize the JPEG-AI verification model's bit distribution and enhance the visual quality. Furthermore, by applying the VVC bit distribution strategy, the objective performance of JPEG-AI verification mode can be further improved, resulting in a maximum gain of 0.45 dB in PSNR-Y.
Bit Rate Matching Algorithm Optimization in JPEG-AI Verification Model
Feb 27, 2024The research on neural network (NN) based image compression has shown superior performance compared to classical compression frameworks. Unlike the hand-engineered transforms in the classical frameworks, NN-based models learn the non-linear transforms providing more compact bit representations, and achieve faster coding speed on parallel devices over their classical counterparts. Those properties evoked the attention of both scientific and industrial communities, resulting in the standardization activity JPEG-AI. The verification model for the standardization process of JPEG-AI is already in development and has surpassed the advanced VVC intra codec. To generate reconstructed images with the desired bits per pixel and assess the BD-rate performance of both the JPEG-AI verification model and VVC intra, bit rate matching is employed. However, the current state of the JPEG-AI verification model experiences significant slowdowns during bit rate matching, resulting in suboptimal performance due to an unsuitable model. The proposed methodology offers a gradual algorithmic optimization for matching bit rates, resulting in a fourfold acceleration and over 1% improvement in BD-rate at the base operation point. At the high operation point, the acceleration increases up to sixfold.
Adapting Learned Image Codecs to Screen Content via Adjustable Transformations
Feb 27, 2024



As learned image codecs (LICs) become more prevalent, their low coding efficiency for out-of-distribution data becomes a bottleneck for some applications. To improve the performance of LICs for screen content (SC) images without breaking backwards compatibility, we propose to introduce parameterized and invertible linear transformations into the coding pipeline without changing the underlying baseline codec's operation flow. We design two neural networks to act as prefilters and postfilters in our setup to increase the coding efficiency and help with the recovery from coding artifacts. Our end-to-end trained solution achieves up to 10% bitrate savings on SC compression compared to the baseline LICs while introducing only 1% extra parameters.
Efficient Contextformer: Spatio-Channel Window Attention for Fast Context Modeling in Learned Image Compression
Jun 25, 2023



In this work, we introduce Efficient Contextformer (eContextformer) for context modeling in lossy learned image compression, which is built upon our previous work, Contextformer. The eContextformer combines the recent advancements in efficient transformers and fast context models with the spatio-channel attention mechanism. The proposed model enables content-adaptive exploitation of the spatial and channel-wise latent dependencies for a high performance and efficient entropy modeling. By incorporating several innovations, the eContextformer features improved decoding speed, model complexity and rate-distortion performance over previous work. For instance, compared to Contextformer, the eContextformer requires 145x less model complexity, 210x less decoding speed and achieves higher average bit savings on the Kodak, CLIC2020 and Tecnick datasets. Compared to the standard Versatile Video Coding (VVC) Test Model (VTM) 16.2, the proposed model provides up to 17.1% bitrate savings and surpasses various learning-based models.
Contextformer: A Transformer with Spatio-Channel Attention for Context Modeling in Learned Image Compression
Mar 04, 2022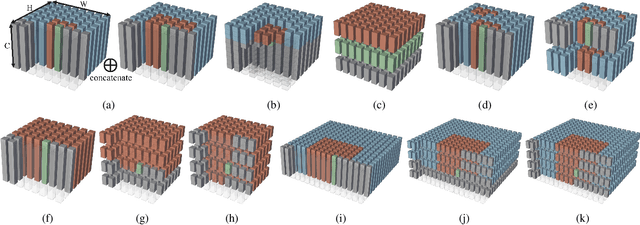

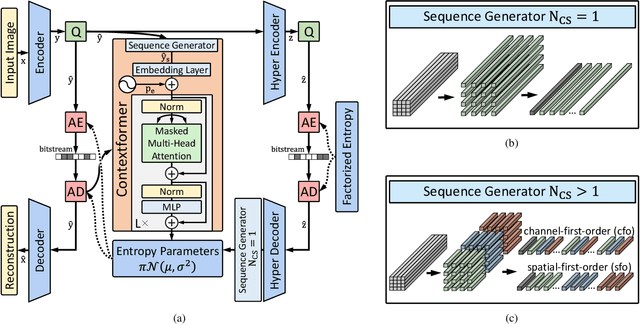
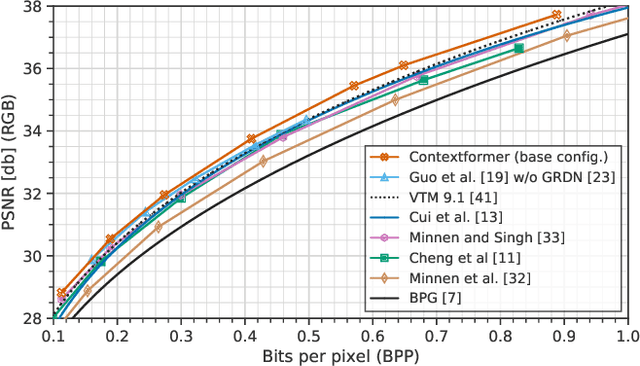
Entropy modeling is a key component for high-performance image compression algorithms. Recent developments in autoregressive context modeling helped learning-based methods to surpass their classical counterparts. However, the performance of those models can be further improved due to the underexploited spatio-channel dependencies in latent space, and the suboptimal implementation of context adaptivity. Inspired by the adaptive characteristics of the transformers, we propose a transformer-based context model, a.k.a. Contextformer, which generalizes the de facto standard attention mechanism to spatio-channel attention. We replace the context model of a modern compression framework with the Contextformer and test it on the widely used Kodak image dataset. Our experimental results show that the proposed model provides up to 10% rate savings compared to the standard Versatile Video Coding (VVC) Test Model (VTM) 9.1, and outperforms various learning-based models.