 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Object Focused Attention
Apr 10, 2025We propose an adaptation to the training of Vision Transformers (ViTs) that allows for an explicit modeling of objects during the attention computation. This is achieved by adding a new branch to selected attention layers that computes an auxiliary loss which we call the object-focused attention (OFA) loss. We restrict the attention to image patches that belong to the same object class, which allows ViTs to gain a better understanding of configural (or holistic) object shapes by focusing on intra-object patches instead of other patches such as those in the background. Our proposed inductive bias fits easily into the attention framework of transformers since it only adds an auxiliary loss over selected attention layers. Furthermore, our approach has no additional overhead during inference. We also experiment with multiscale masking to further improve the performance of our OFA model and give a path forward for self-supervised learning with our method. Our experimental results demonstrate that ViTs with OFA achieve better classification results than their base models, exhibit a stronger generalization ability to out-of-distribution (OOD) and adversarially corrupted images, and learn representations based on object shapes rather than spurious correlations via general textures. For our OOD setting, we generate a novel dataset using the COCO dataset and Stable Diffusion inpainting which we plan to share with the community.
Enhanced Masked Image Modeling for Analysis of Dental Panoramic Radiographs
Jun 18, 2023The computer-assisted radiologic informative report has received increasing research attention to facilitate diagnosis and treatment planning for dental care providers. However, manual interpretation of dental images is limited, expensive, and time-consuming. Another barrier in dental imaging is the limited number of available images for training, which is a challenge in the era of deep learning. This study proposes a novel self-distillation (SD) enhanced self-supervised learning on top of the masked image modeling (SimMIM) Transformer, called SD-SimMIM, to improve the outcome with a limited number of dental radiographs. In addition to the prediction loss on masked patches, SD-SimMIM computes the self-distillation loss on the visible patches. We apply SD-SimMIM on dental panoramic X-rays for teeth numbering, detection of dental restorations and orthodontic appliances, and instance segmentation tasks. Our results show that SD-SimMIM outperforms other self-supervised learning methods. Furthermore, we augment and improve the annotation of an existing dataset of panoramic X-rays.
Self-Supervised Learning with Masked Image Modeling for Teeth Numbering, Detection of Dental Restorations, and Instance Segmentation in Dental Panoramic Radiographs
Oct 20, 2022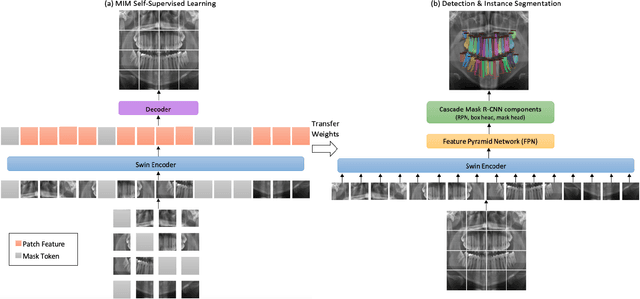
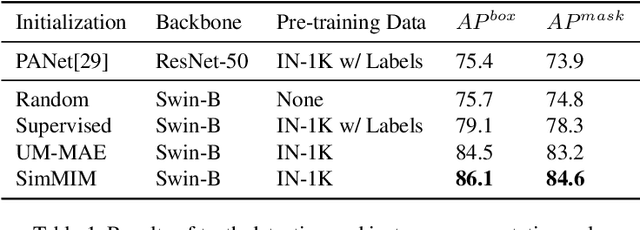
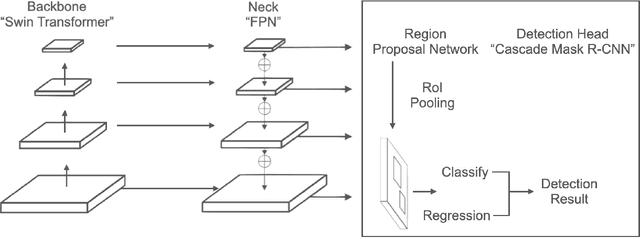

The computer-assisted radiologic informative report is currently emerging in dental practice to facilitate dental care and reduce time consumption in manual panoramic radiographic interpretation. However, the amount of dental radiographs for training is very limited, particularly from the point of view of deep learning. This study aims to utilize recent self-supervised learning methods like SimMIM and UM-MAE to increase the model efficiency and understanding of the limited number of dental radiographs. We use the Swin Transformer for teeth numbering, detection of dental restorations, and instance segmentation tasks. To the best of our knowledge, this is the first study that applied self-supervised learning methods to Swin Transformer on dental panoramic radiographs. Our results show that the SimMIM method obtained the highest performance of 90.4% and 88.9% on detecting teeth and dental restorations and instance segmentation, respectively, increasing the average precision by 13.4 and 12.8 over the random initialization baseline. Moreover, we augment and correct the existing dataset of panoramic radiographs. The code and the dataset are available at https://github.com/AmaniHAlmalki/DentalMIM.