 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Equivariant Spherical CNN for Data Efficient and High-Performance Medical Image Processing
Jul 06, 2023
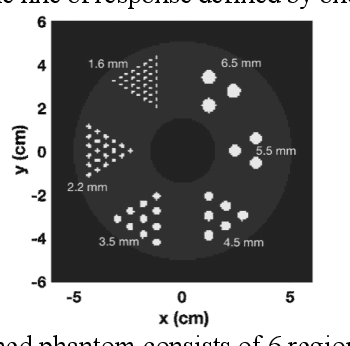
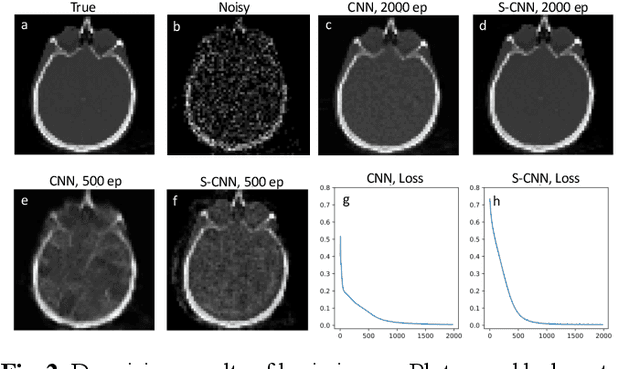
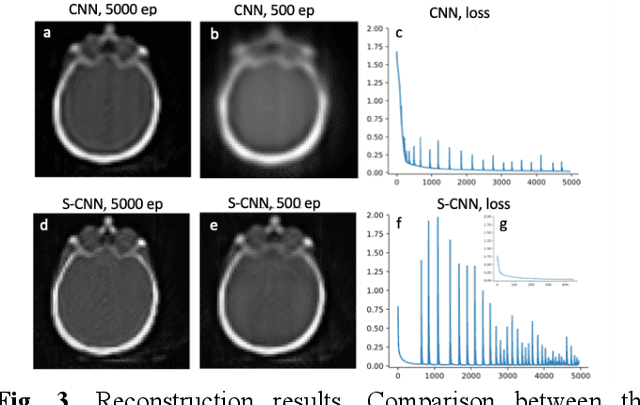
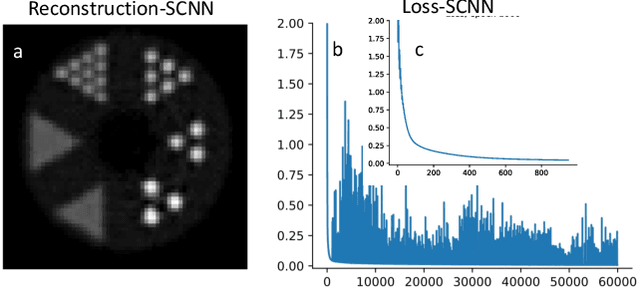
This work highlights the significance of equivariant networks as efficient and high-performance approaches for tomography applications. Our study builds upon the limitations of Convolutional Neural Networks (CNNs), which have shown promise in post-processing various medical imaging systems. However, the efficiency of conventional CNNs heavily relies on an undiminished and proper training set. To tackle this issue, in this study, we introduce an equivariant network, aiming to reduce CNN's dependency on specific training sets. We evaluate the efficacy of equivariant CNNs on spherical signals for tomographic medical imaging problems. Our results demonstrate superior quality and computational efficiency of spherical CNNs (SCNNs) in denoising and reconstructing benchmark problems. Furthermore, we propose a novel approach to employ SCNNs as a complement to conventional image reconstruction tools, enhancing the outcomes while reducing reliance on the training set. Across all cases, we observe a significant decrease in computational costs while maintaining the same or higher quality of image processing using SCNNs compared to CNNs. Additionally, we explore the potential of this network for broader tomography applications, particularly those requiring omnidirectional representation.
Interpretable Small Training Set Image Segmentation Network Originated from Multi-Grid Variational Model
Jun 25, 2023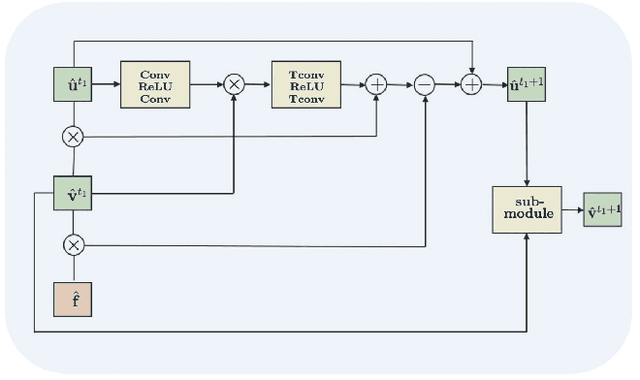
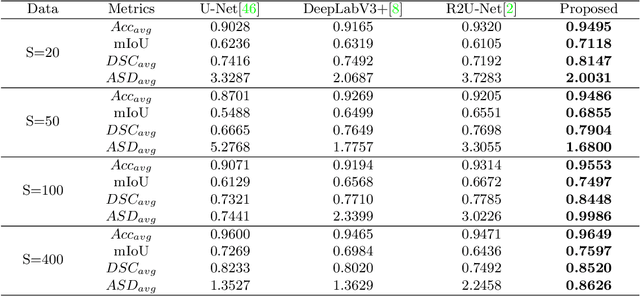
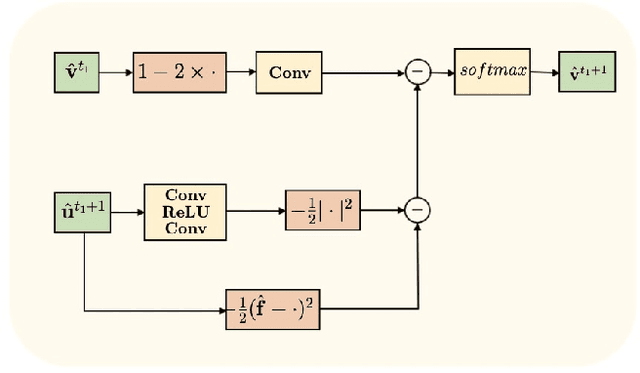
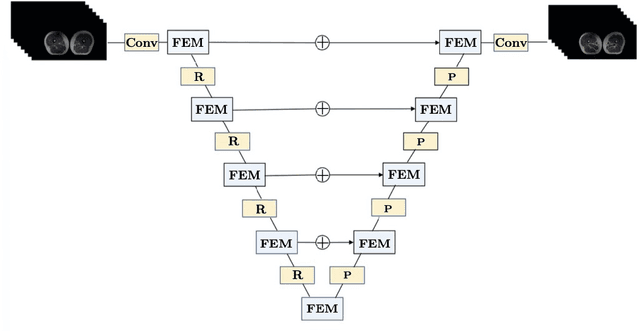
The main objective of image segmentation is to divide an image into homogeneous regions for further analysis. This is a significant and crucial task in many applications such as medical imaging. Deep learning (DL) methods have been proposed and widely used for image segmentation. However, these methods usually require a large amount of manually segmented data as training data and suffer from poor interpretability (known as the black box problem). The classical Mumford-Shah (MS) model is effective for segmentation and provides a piece-wise smooth approximation of the original image. In this paper, we replace the hand-crafted regularity term in the MS model with a data adaptive generalized learnable regularity term and use a multi-grid framework to unroll the MS model and obtain a variational model-based segmentation network with better generalizability and interpretability. This approach allows for the incorporation of learnable prior information into the network structure design. Moreover, the multi-grid framework enables multi-scale feature extraction and offers a mathematical explanation for the effectiveness of the U-shaped network structure in producing good image segmentation results. Due to the proposed network originates from a variational model, it can also handle small training sizes. Our experiments on the REFUGE dataset, the White Blood Cell image dataset, and 3D thigh muscle magnetic resonance (MR) images demonstrate that even with smaller training datasets, our method yields better segmentation results compared to related state of the art segmentation methods.
Non-iterative Coarse-to-fine Transformer Networks for Joint Affine and Deformable Image Registration
Jul 07, 2023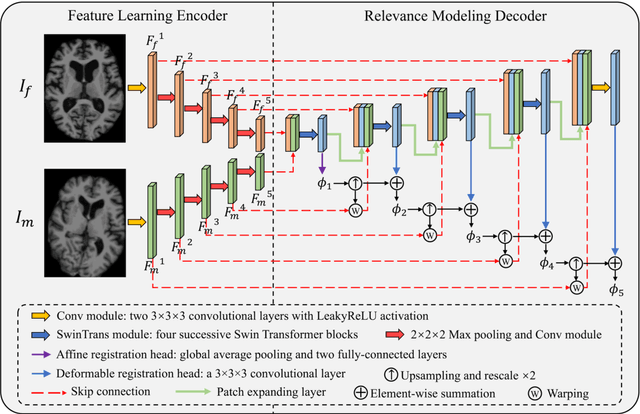
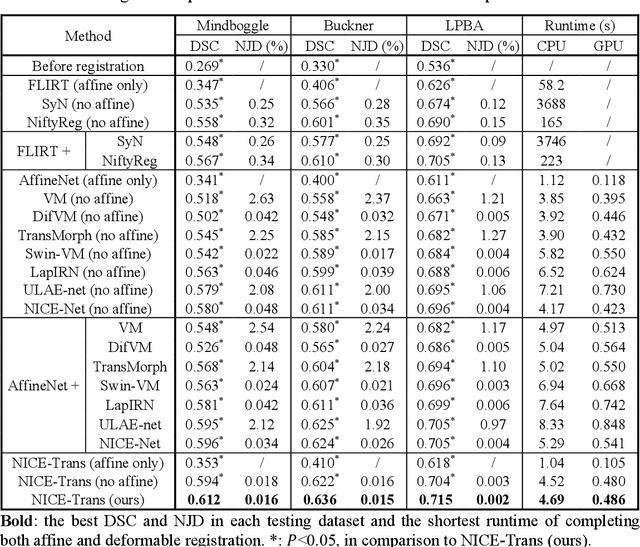
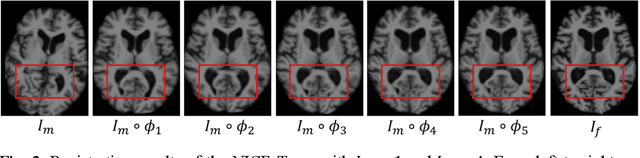
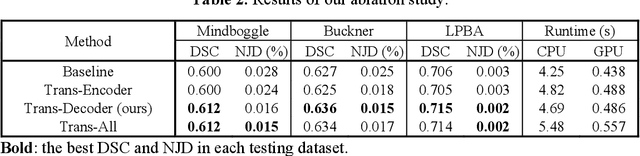
Image registration is a fundamental requirement for medical image analysis. Deep registration methods based on deep learning have been widely recognized for their capabilities to perform fast end-to-end registration. Many deep registration methods achieved state-of-the-art performance by performing coarse-to-fine registration, where multiple registration steps were iterated with cascaded networks. Recently, Non-Iterative Coarse-to-finE (NICE) registration methods have been proposed to perform coarse-to-fine registration in a single network and showed advantages in both registration accuracy and runtime. However, existing NICE registration methods mainly focus on deformable registration, while affine registration, a common prerequisite, is still reliant on time-consuming traditional optimization-based methods or extra affine registration networks. In addition, existing NICE registration methods are limited by the intrinsic locality of convolution operations. Transformers may address this limitation for their capabilities to capture long-range dependency, but the benefits of using transformers for NICE registration have not been explored. In this study, we propose a Non-Iterative Coarse-to-finE Transformer network (NICE-Trans) for image registration. Our NICE-Trans is the first deep registration method that (i) performs joint affine and deformable coarse-to-fine registration within a single network, and (ii) embeds transformers into a NICE registration framework to model long-range relevance between images. Extensive experiments with seven public datasets show that our NICE-Trans outperforms state-of-the-art registration methods on both registration accuracy and runtime.
Orientation-Independent Chinese Text Recognition in Scene Images
Sep 03, 2023
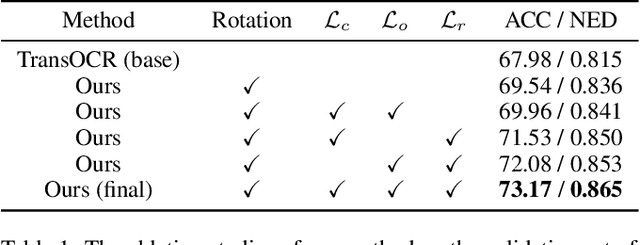
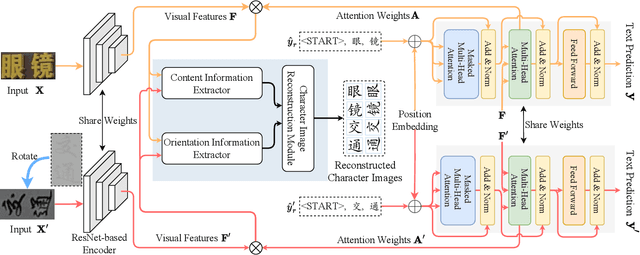
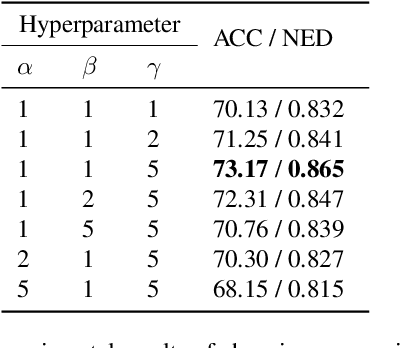
Scene text recognition (STR) has attracted much attention due to its broad applications. The previous works pay more attention to dealing with the recognition of Latin text images with complex backgrounds by introducing language models or other auxiliary networks. Different from Latin texts, many vertical Chinese texts exist in natural scenes, which brings difficulties to current state-of-the-art STR methods. In this paper, we take the first attempt to extract orientation-independent visual features by disentangling content and orientation information of text images, thus recognizing both horizontal and vertical texts robustly in natural scenes. Specifically, we introduce a Character Image Reconstruction Network (CIRN) to recover corresponding printed character images with disentangled content and orientation information. We conduct experiments on a scene dataset for benchmarking Chinese text recognition, and the results demonstrate that the proposed method can indeed improve performance through disentangling content and orientation information. To further validate the effectiveness of our method, we additionally collect a Vertical Chinese Text Recognition (VCTR) dataset. The experimental results show that the proposed method achieves 45.63% improvement on VCTR when introducing CIRN to the baseline model.
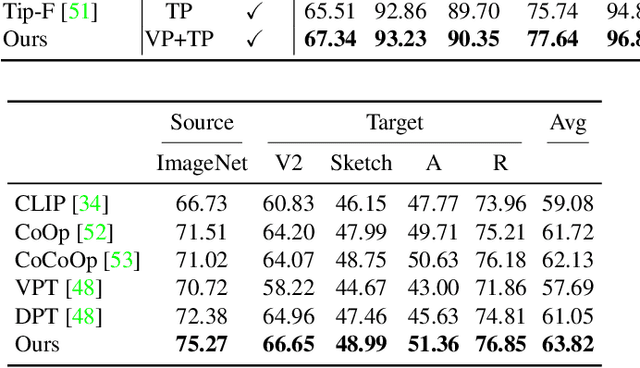
BDC-Adapter: Brownian Distance Covariance for Better Vision-Language Reasoning
Sep 03, 2023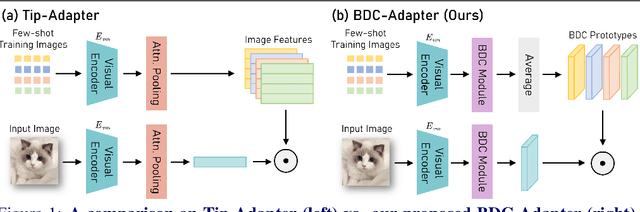
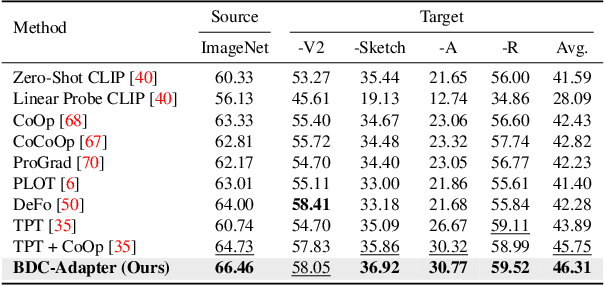
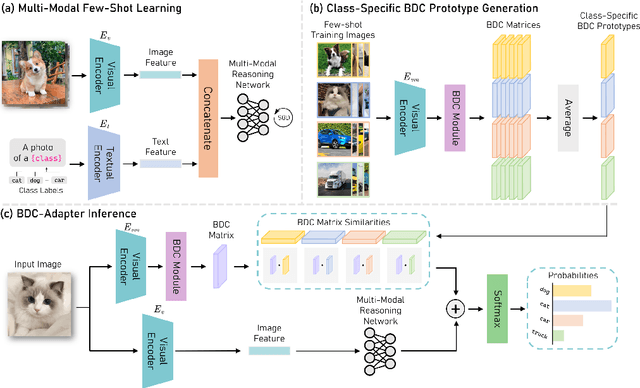
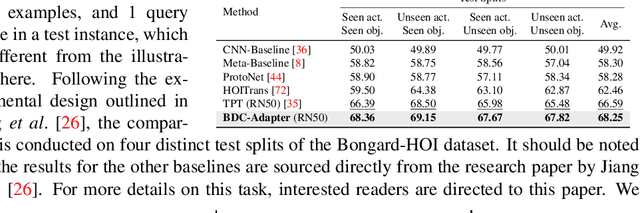
Large-scale pre-trained Vision-Language Models (VLMs), such as CLIP and ALIGN, have introduced a new paradigm for learning transferable visual representations. Recently, there has been a surge of interest among researchers in developing lightweight fine-tuning techniques to adapt these models to downstream visual tasks. We recognize that current state-of-the-art fine-tuning methods, such as Tip-Adapter, simply consider the covariance between the query image feature and features of support few-shot training samples, which only captures linear relations and potentially instigates a deceptive perception of independence. To address this issue, in this work, we innovatively introduce Brownian Distance Covariance (BDC) to the field of vision-language reasoning. The BDC metric can model all possible relations, providing a robust metric for measuring feature dependence. Based on this, we present a novel method called BDC-Adapter, which integrates BDC prototype similarity reasoning and multi-modal reasoning network prediction to perform classification tasks. Our extensive experimental results show that the proposed BDC-Adapter can freely handle non-linear relations and fully characterize independence, outperforming the current state-of-the-art methods by large margins.
CoTDet: Affordance Knowledge Prompting for Task Driven Object Detection
Sep 03, 2023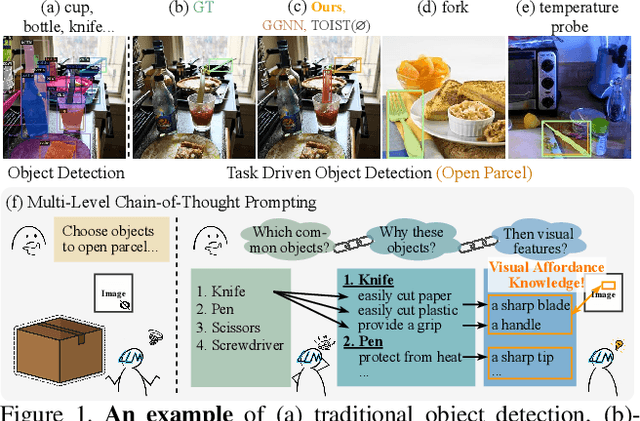
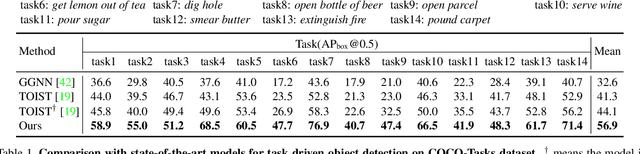
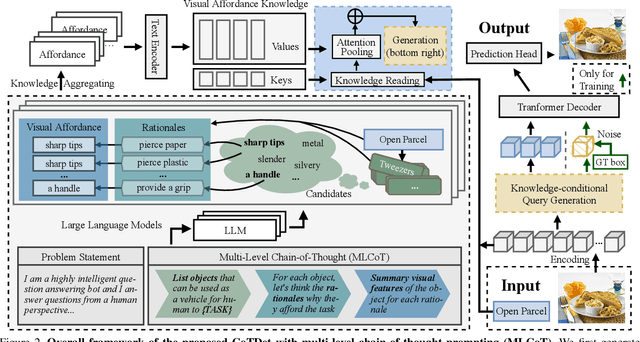

Task driven object detection aims to detect object instances suitable for affording a task in an image. Its challenge lies in object categories available for the task being too diverse to be limited to a closed set of object vocabulary for traditional object detection. Simply mapping categories and visual features of common objects to the task cannot address the challenge. In this paper, we propose to explore fundamental affordances rather than object categories, i.e., common attributes that enable different objects to accomplish the same task. Moreover, we propose a novel multi-level chain-of-thought prompting (MLCoT) to extract the affordance knowledge from large language models, which contains multi-level reasoning steps from task to object examples to essential visual attributes with rationales. Furthermore, to fully exploit knowledge to benefit object recognition and localization, we propose a knowledge-conditional detection framework, namely CoTDet. It conditions the detector from the knowledge to generate object queries and regress boxes. Experimental results demonstrate that our CoTDet outperforms state-of-the-art methods consistently and significantly (+15.6 box AP and +14.8 mask AP) and can generate rationales for why objects are detected to afford the task.
ArSDM: Colonoscopy Images Synthesis with Adaptive Refinement Semantic Diffusion Models
Sep 03, 2023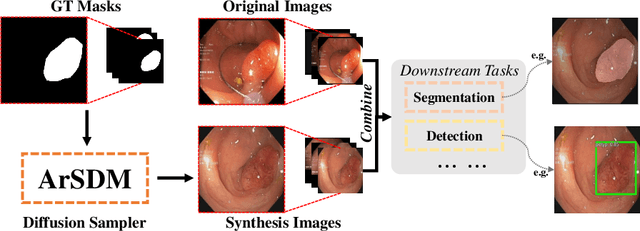
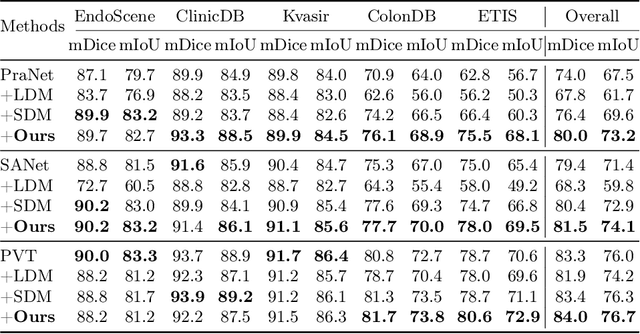
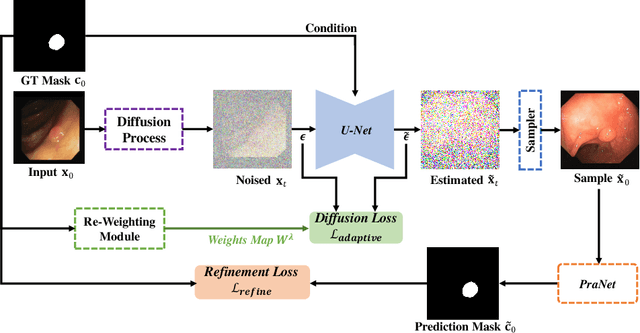
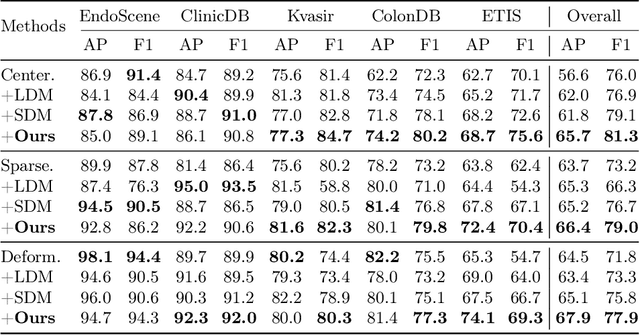
Colonoscopy analysis, particularly automatic polyp segmentation and detection, is essential for assisting clinical diagnosis and treatment. However, as medical image annotation is labour- and resource-intensive, the scarcity of annotated data limits the effectiveness and generalization of existing methods. Although recent research has focused on data generation and augmentation to address this issue, the quality of the generated data remains a challenge, which limits the contribution to the performance of subsequent tasks. Inspired by the superiority of diffusion models in fitting data distributions and generating high-quality data, in this paper, we propose an Adaptive Refinement Semantic Diffusion Model (ArSDM) to generate colonoscopy images that benefit the downstream tasks. Specifically, ArSDM utilizes the ground-truth segmentation mask as a prior condition during training and adjusts the diffusion loss for each input according to the polyp/background size ratio. Furthermore, ArSDM incorporates a pre-trained segmentation model to refine the training process by reducing the difference between the ground-truth mask and the prediction mask. Extensive experiments on segmentation and detection tasks demonstrate the generated data by ArSDM could significantly boost the performance of baseline methods.
LoGoPrompt: Synthetic Text Images Can Be Good Visual Prompts for Vision-Language Models
Sep 03, 2023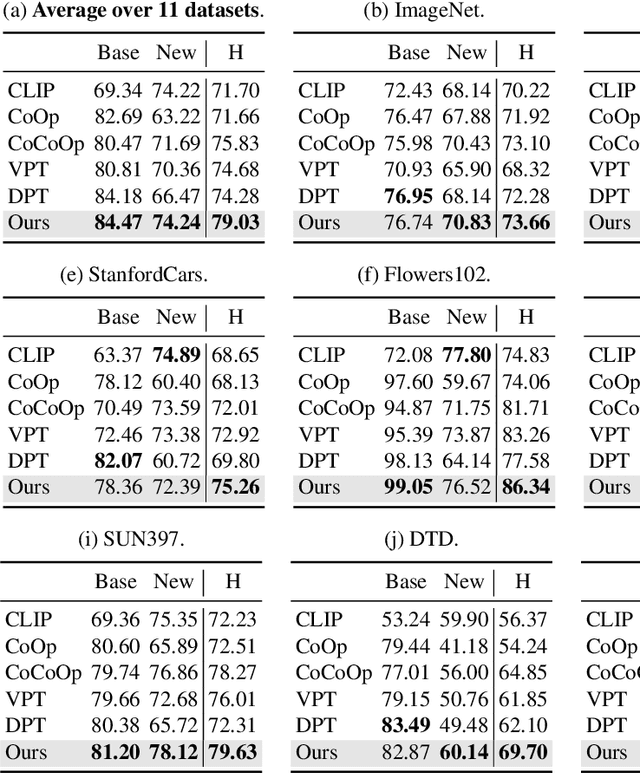

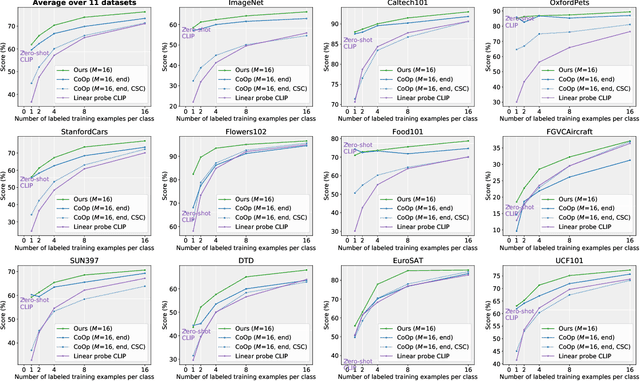
Prompt engineering is a powerful tool used to enhance the performance of pre-trained models on downstream tasks. For example, providing the prompt ``Let's think step by step" improved GPT-3's reasoning accuracy to 63% on MutiArith while prompting ``a photo of" filled with a class name enables CLIP to achieve $80$\% zero-shot accuracy on ImageNet. While previous research has explored prompt learning for the visual modality, analyzing what constitutes a good visual prompt specifically for image recognition is limited. In addition, existing visual prompt tuning methods' generalization ability is worse than text-only prompting tuning. This paper explores our key insight: synthetic text images are good visual prompts for vision-language models! To achieve that, we propose our LoGoPrompt, which reformulates the classification objective to the visual prompt selection and addresses the chicken-and-egg challenge of first adding synthetic text images as class-wise visual prompts or predicting the class first. Without any trainable visual prompt parameters, experimental results on 16 datasets demonstrate that our method consistently outperforms state-of-the-art methods in few-shot learning, base-to-new generalization, and domain generalization.
EdaDet: Open-Vocabulary Object Detection Using Early Dense Alignment
Sep 03, 2023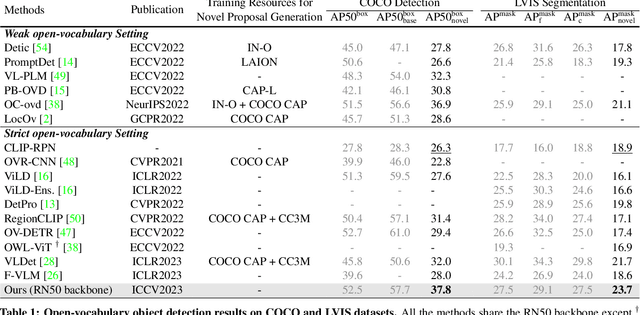

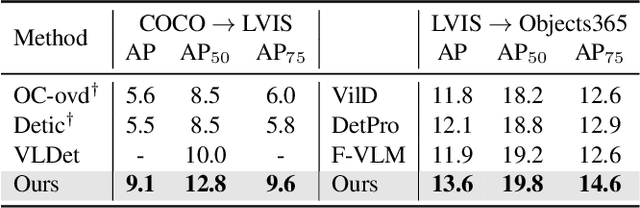
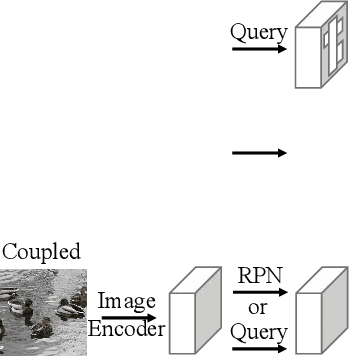
Vision-language models such as CLIP have boosted the performance of open-vocabulary object detection, where the detector is trained on base categories but required to detect novel categories. Existing methods leverage CLIP's strong zero-shot recognition ability to align object-level embeddings with textual embeddings of categories. However, we observe that using CLIP for object-level alignment results in overfitting to base categories, i.e., novel categories most similar to base categories have particularly poor performance as they are recognized as similar base categories. In this paper, we first identify that the loss of critical fine-grained local image semantics hinders existing methods from attaining strong base-to-novel generalization. Then, we propose Early Dense Alignment (EDA) to bridge the gap between generalizable local semantics and object-level prediction. In EDA, we use object-level supervision to learn the dense-level rather than object-level alignment to maintain the local fine-grained semantics. Extensive experiments demonstrate our superior performance to competing approaches under the same strict setting and without using external training resources, i.e., improving the +8.4% novel box AP50 on COCO and +3.9% rare mask AP on LVIS.
CFI2P: Coarse-to-Fine Cross-Modal Correspondence Learning for Image-to-Point Cloud Registration
Jul 14, 2023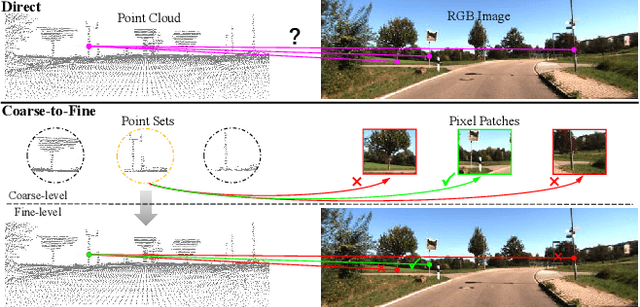

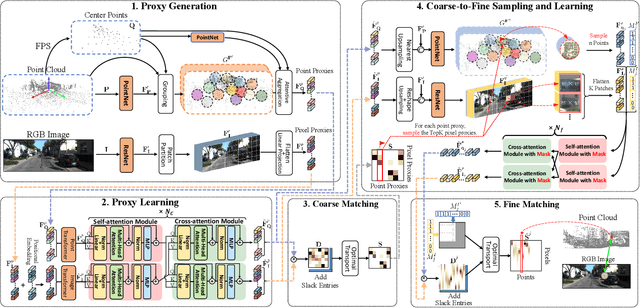
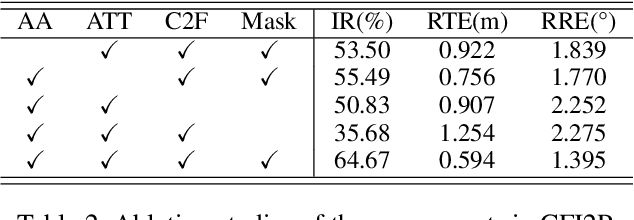
In the context of image-to-point cloud registration, acquiring point-to-pixel correspondences presents a challenging task since the similarity between individual points and pixels is ambiguous due to the visual differences in data modalities. Nevertheless, the same object present in the two data formats can be readily identified from the local perspective of point sets and pixel patches. Motivated by this intuition, we propose a coarse-to-fine framework that emphasizes the establishment of correspondences between local point sets and pixel patches, followed by the refinement of results at both the point and pixel levels. On a coarse scale, we mimic the classic Visual Transformer to translate both image and point cloud into two sequences of local representations, namely point and pixel proxies, and employ attention to capture global and cross-modal contexts. To supervise the coarse matching, we propose a novel projected point proportion loss, which guides to match point sets with pixel patches where more points can be projected into. On a finer scale, point-to-pixel correspondences are then refined from a smaller search space (i.e., the coarsely matched sets and patches) via well-designed sampling, attentional learning and fine matching, where sampling masks are embedded in the last two steps to mitigate the negative effect of sampling. With the high-quality correspondences, the registration problem is then resolved by EPnP algorithm within RANSAC. Experimental results on large-scale outdoor benchmarks demonstrate our superiority over existing methods.