 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Joint Hierarchical Priors and Adaptive Spatial Resolution for Efficient Neural Image Compression
Jul 12, 2023
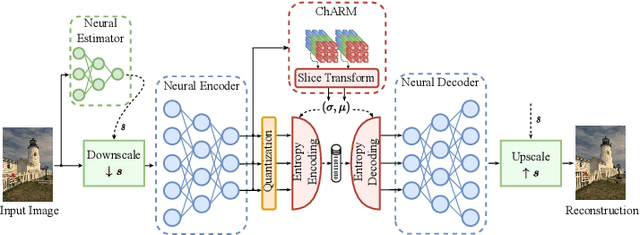
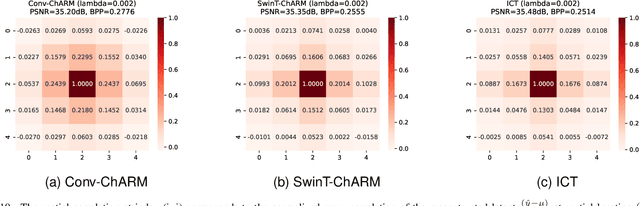

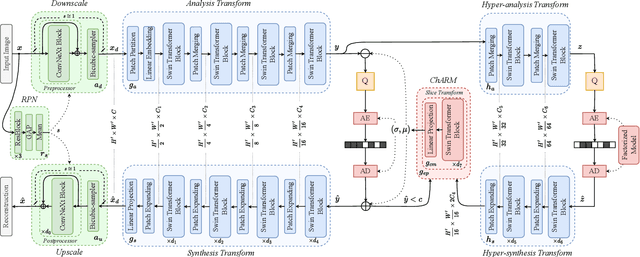
Recently, the performance of neural image compression (NIC) has steadily improved thanks to the last line of study, reaching or outperforming state-of-the-art conventional codecs. Despite significant progress, current NIC methods still rely on ConvNet-based entropy coding, limited in modeling long-range dependencies due to their local connectivity and the increasing number of architectural biases and priors, resulting in complex underperforming models with high decoding latency. Motivated by the efficiency investigation of the Tranformer-based transform coding framework, namely SwinT-ChARM, we propose to enhance the latter, as first, with a more straightforward yet effective Tranformer-based channel-wise auto-regressive prior model, resulting in an absolute image compression transformer (ICT). Through the proposed ICT, we can capture both global and local contexts from the latent representations and better parameterize the distribution of the quantized latents. Further, we leverage a learnable scaling module with a sandwich ConvNeXt-based pre-/post-processor to accurately extract more compact latent codes while reconstructing higher-quality images. Extensive experimental results on benchmark datasets showed that the proposed framework significantly improves the trade-off between coding efficiency and decoder complexity over the versatile video coding (VVC) reference encoder (VTM-18.0) and the neural codec SwinT-ChARM. Moreover, we provide model scaling studies to verify the computational efficiency of our approach and conduct several objective and subjective analyses to bring to the fore the performance gap between the adaptive image compression transformer (AICT) and the neural codec SwinT-ChARM.
UX Heuristics and Checklist for Deep Learning powered Mobile Applications with Image Classification
Jul 05, 2023
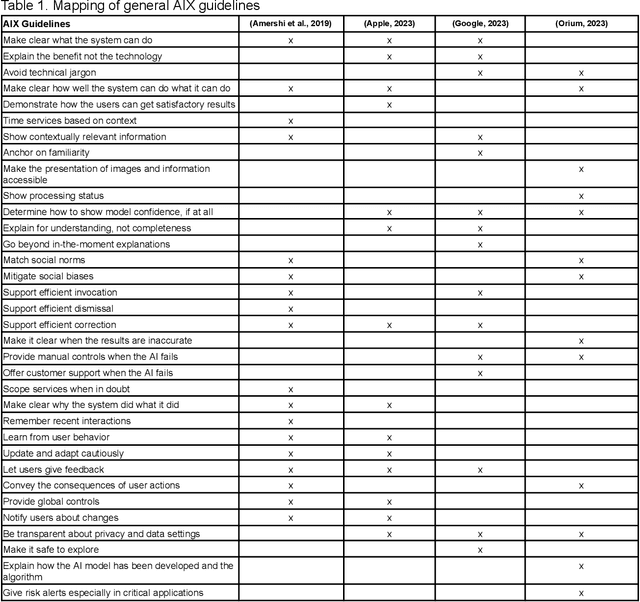
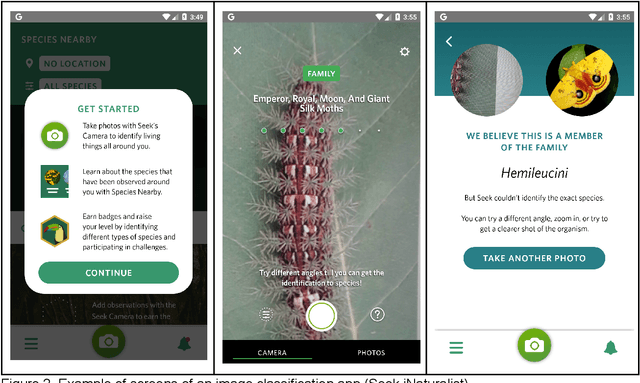
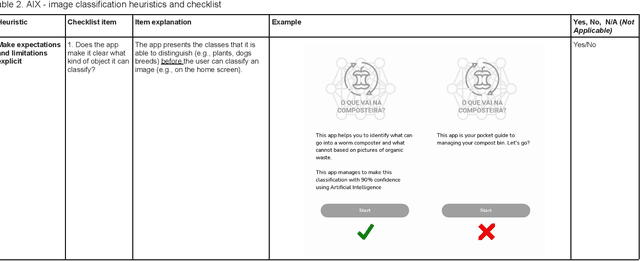
Advances in mobile applications providing image classification enabled by Deep Learning require innovative User Experience solutions in order to assure their adequate use by users. To aid the design process, usability heuristics are typically customized for a specific kind of application. Therefore, based on a literature review and analyzing existing mobile applications with image classification, we propose an initial set of AIX heuristics for Deep Learning powered mobile applications with image classification decomposed into a checklist. In order to facilitate the usage of the checklist we also developed an online course presenting the concepts and heuristics as well as a web-based tool in order to support an evaluation using these heuristics. These results of this research can be used to guide the design of the interfaces of such applications as well as support the conduction of heuristic evaluations supporting practitioners to develop image classification apps that people can understand, trust, and can engage with effectively.
Mutual Query Network for Multi-Modal Product Image Segmentation
Jun 26, 2023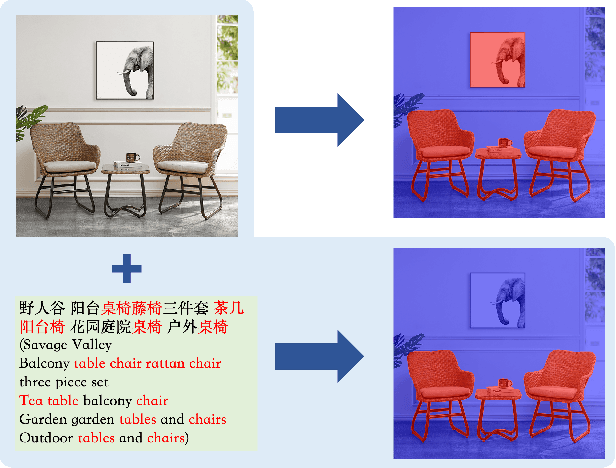

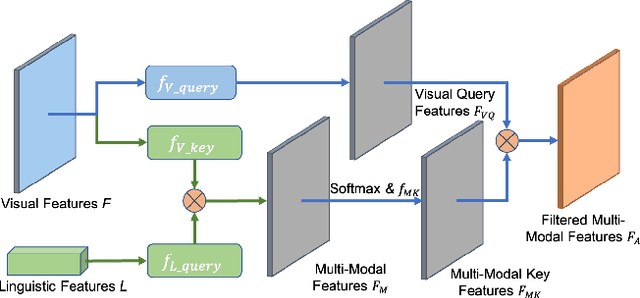
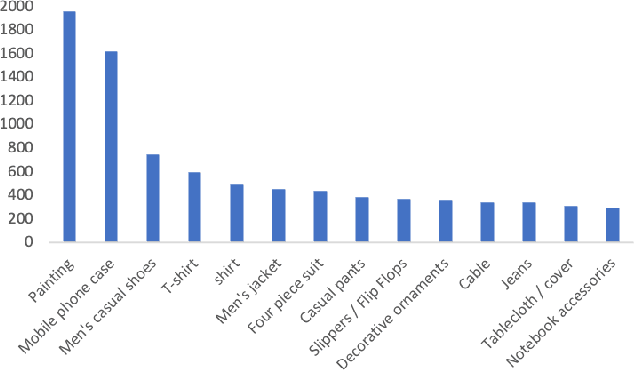
Product image segmentation is vital in e-commerce. Most existing methods extract the product image foreground only based on the visual modality, making it difficult to distinguish irrelevant products. As product titles contain abundant appearance information and provide complementary cues for product image segmentation, we propose a mutual query network to segment products based on both visual and linguistic modalities. First, we design a language query vision module to obtain the response of language description in image areas, thus aligning the visual and linguistic representations across modalities. Then, a vision query language module utilizes the correlation between visual and linguistic modalities to filter the product title and effectively suppress the content irrelevant to the vision in the title. To promote the research in this field, we also construct a Multi-Modal Product Segmentation dataset (MMPS), which contains 30,000 images and corresponding titles. The proposed method significantly outperforms the state-of-the-art methods on MMPS.
Fast Dust Sand Image Enhancement Based on Color Correction and New Membership Function
Jul 27, 2023Images captured in dusty environments suffering from poor visibility and quality. Enhancement of these images such as sand dust images plays a critical role in various atmospheric optics applications. In this work, proposed a new model based on Color Correction and new membership function to enhance san dust images. The proposed model consists of three phases: correction of color shift, removal of haze, and enhancement of contrast and brightness. The color shift is corrected using a new membership function to adjust the values of U and V in the YUV color space. The Adaptive Dark Channel Prior (A-DCP) is used for haze removal. The stretching contrast and improving image brightness are based on Contrast Limited Adaptive Histogram Equalization (CLAHE). The proposed model tests and evaluates through many real sand dust images. The experimental results show that the proposed solution is outperformed the current studies in terms of effectively removing the red and yellow cast and provides high quality and quantity dust images.
Localized Text-to-Image Generation for Free via Cross Attention Control
Jun 26, 2023
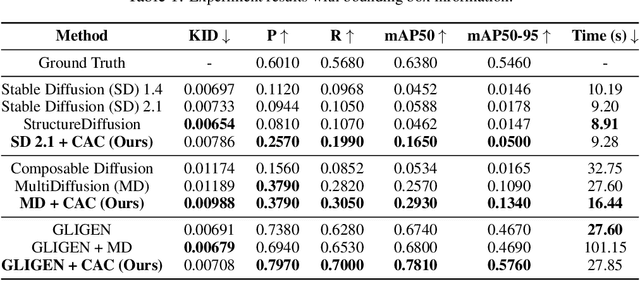
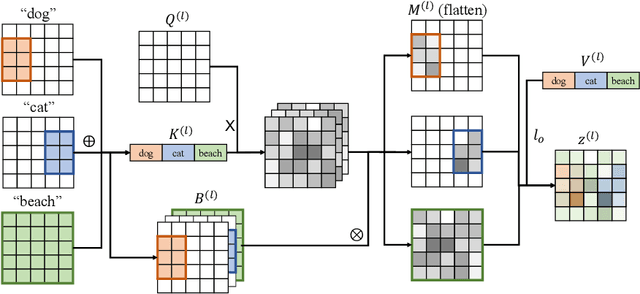

Despite the tremendous success in text-to-image generative models, localized text-to-image generation (that is, generating objects or features at specific locations in an image while maintaining a consistent overall generation) still requires either explicit training or substantial additional inference time. In this work, we show that localized generation can be achieved by simply controlling cross attention maps during inference. With no additional training, model architecture modification or inference time, our proposed cross attention control (CAC) provides new open-vocabulary localization abilities to standard text-to-image models. CAC also enhances models that are already trained for localized generation when deployed at inference time. Furthermore, to assess localized text-to-image generation performance automatically, we develop a standardized suite of evaluations using large pretrained recognition models. Our experiments show that CAC improves localized generation performance with various types of location information ranging from bounding boxes to semantic segmentation maps, and enhances the compositional capability of state-of-the-art text-to-image generative models.
MDTD: A Multi Domain Trojan Detector for Deep Neural Networks
Sep 03, 2023

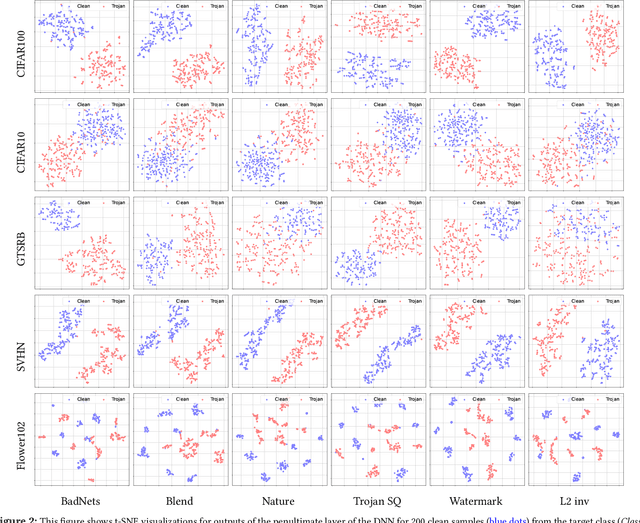

Machine learning models that use deep neural networks (DNNs) are vulnerable to backdoor attacks. An adversary carrying out a backdoor attack embeds a predefined perturbation called a trigger into a small subset of input samples and trains the DNN such that the presence of the trigger in the input results in an adversary-desired output class. Such adversarial retraining however needs to ensure that outputs for inputs without the trigger remain unaffected and provide high classification accuracy on clean samples. In this paper, we propose MDTD, a Multi-Domain Trojan Detector for DNNs, which detects inputs containing a Trojan trigger at testing time. MDTD does not require knowledge of trigger-embedding strategy of the attacker and can be applied to a pre-trained DNN model with image, audio, or graph-based inputs. MDTD leverages an insight that input samples containing a Trojan trigger are located relatively farther away from a decision boundary than clean samples. MDTD estimates the distance to a decision boundary using adversarial learning methods and uses this distance to infer whether a test-time input sample is Trojaned or not. We evaluate MDTD against state-of-the-art Trojan detection methods across five widely used image-based datasets: CIFAR100, CIFAR10, GTSRB, SVHN, and Flowers102; four graph-based datasets: AIDS, WinMal, Toxicant, and COLLAB; and the SpeechCommand audio dataset. MDTD effectively identifies samples that contain different types of Trojan triggers. We evaluate MDTD against adaptive attacks where an adversary trains a robust DNN to increase (decrease) distance of benign (Trojan) inputs from a decision boundary.
ToothSegNet: Image Degradation meets Tooth Segmentation in CBCT Images
Jul 05, 2023
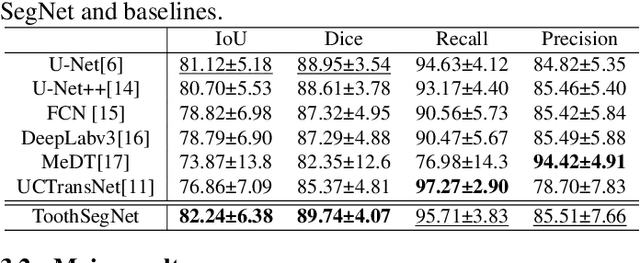
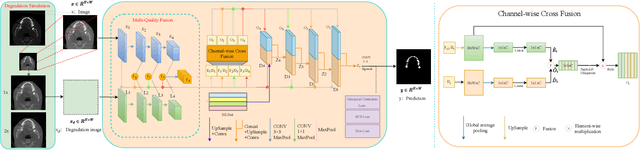
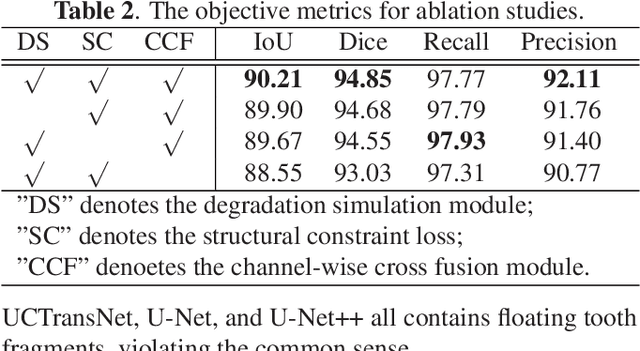
In computer-assisted orthodontics, three-dimensional tooth models are required for many medical treatments. Tooth segmentation from cone-beam computed tomography (CBCT) images is a crucial step in constructing the models. However, CBCT image quality problems such as metal artifacts and blurring caused by shooting equipment and patients' dental conditions make the segmentation difficult. In this paper, we propose ToothSegNet, a new framework which acquaints the segmentation model with generated degraded images during training. ToothSegNet merges the information of high and low quality images from the designed degradation simulation module using channel-wise cross fusion to reduce the semantic gap between encoder and decoder, and also refines the shape of tooth prediction through a structural constraint loss. Experimental results suggest that ToothSegNet produces more precise segmentation and outperforms the state-of-the-art medical image segmentation methods.
Crucial Feature Capture and Discrimination for Limited Training Data SAR ATR
Aug 20, 2023Although deep learning-based methods have achieved excellent performance on SAR ATR, the fact that it is difficult to acquire and label a lot of SAR images makes these methods, which originally performed well, perform weakly. This may be because most of them consider the whole target images as input, but the researches find that, under limited training data, the deep learning model can't capture discriminative image regions in the whole images, rather focus on more useless even harmful image regions for recognition. Therefore, the results are not satisfactory. In this paper, we design a SAR ATR framework under limited training samples, which mainly consists of two branches and two modules, global assisted branch and local enhanced branch, feature capture module and feature discrimination module. In every training process, the global assisted branch first finishes the initial recognition based on the whole image. Based on the initial recognition results, the feature capture module automatically searches and locks the crucial image regions for correct recognition, which we named as the golden key of image. Then the local extract the local features from the captured crucial image regions. Finally, the overall features and local features are input into the classifier and dynamically weighted using the learnable voting parameters to collaboratively complete the final recognition under limited training samples. The model soundness experiments demonstrate the effectiveness of our method through the improvement of feature distribution and recognition probability. The experimental results and comparisons on MSTAR and OPENSAR show that our method has achieved superior recognition performance.
SGDiff: A Style Guided Diffusion Model for Fashion Synthesis
Aug 15, 2023This paper reports on the development of \textbf{a novel style guided diffusion model (SGDiff)} which overcomes certain weaknesses inherent in existing models for image synthesis. The proposed SGDiff combines image modality with a pretrained text-to-image diffusion model to facilitate creative fashion image synthesis. It addresses the limitations of text-to-image diffusion models by incorporating supplementary style guidance, substantially reducing training costs, and overcoming the difficulties of controlling synthesized styles with text-only inputs. This paper also introduces a new dataset -- SG-Fashion, specifically designed for fashion image synthesis applications, offering high-resolution images and an extensive range of garment categories. By means of comprehensive ablation study, we examine the application of classifier-free guidance to a variety of conditions and validate the effectiveness of the proposed model for generating fashion images of the desired categories, product attributes, and styles. The contributions of this paper include a novel classifier-free guidance method for multi-modal feature fusion, a comprehensive dataset for fashion image synthesis application, a thorough investigation on conditioned text-to-image synthesis, and valuable insights for future research in the text-to-image synthesis domain. The code and dataset are available at: \url{https://github.com/taited/SGDiff}.
CNN or ViT? Revisiting Vision Transformers Through the Lens of Convolution
Sep 11, 2023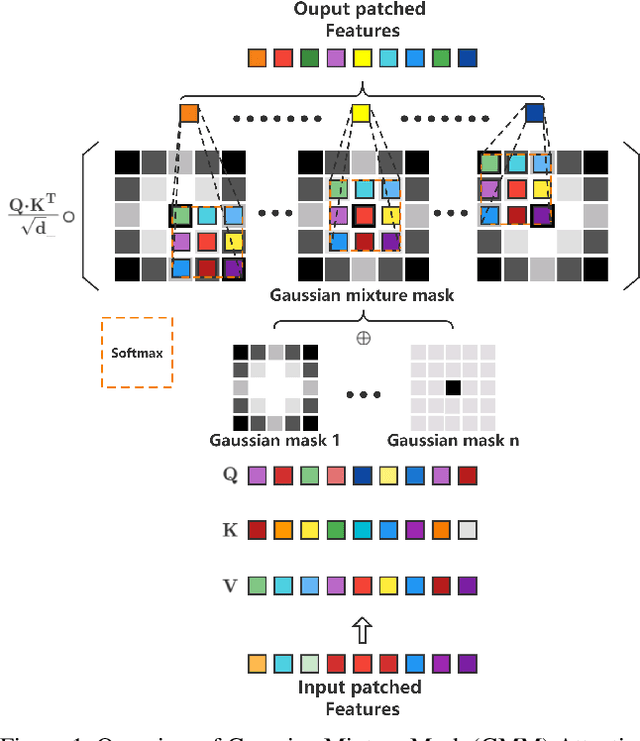
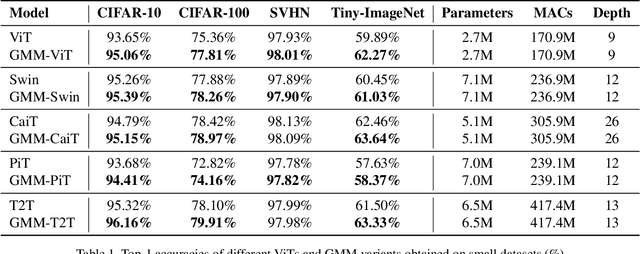
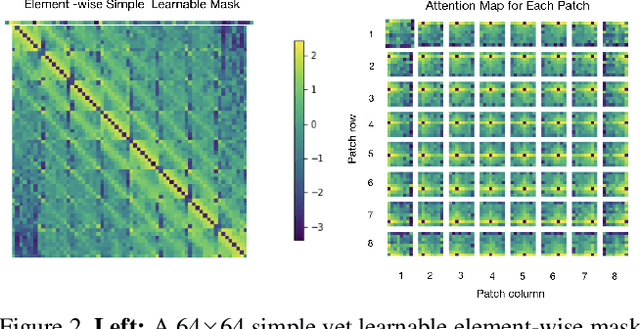
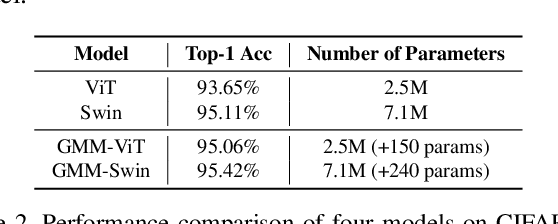
The success of Vision Transformer (ViT) has been widely reported on a wide range of image recognition tasks. The merit of ViT over CNN has been largely attributed to large training datasets or auxiliary pre-training. Without pre-training, the performance of ViT on small datasets is limited because the global self-attention has limited capacity in local modeling. Towards boosting ViT on small datasets without pre-training, this work improves its local modeling by applying a weight mask on the original self-attention matrix. A straightforward way to locally adapt the self-attention matrix can be realized by an element-wise learnable weight mask (ELM), for which our preliminary results show promising results. However, the element-wise simple learnable weight mask not only induces a non-trivial additional parameter overhead but also increases the optimization complexity. To this end, this work proposes a novel Gaussian mixture mask (GMM) in which one mask only has two learnable parameters and it can be conveniently used in any ViT variants whose attention mechanism allows the use of masks. Experimental results on multiple small datasets demonstrate that the effectiveness of our proposed Gaussian mask for boosting ViTs for free (almost zero additional parameter or computation cost). Our code will be publicly available at \href{https://github.com/CatworldLee/Gaussian-Mixture-Mask-Attention}{https://github.com/CatworldLee/Gaussian-Mixture-Mask-Attention}.