 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image To Image Translation": models, code, and papers
TuiGAN: Learning Versatile Image-to-Image Translation with Two Unpaired Images
Apr 09, 2020


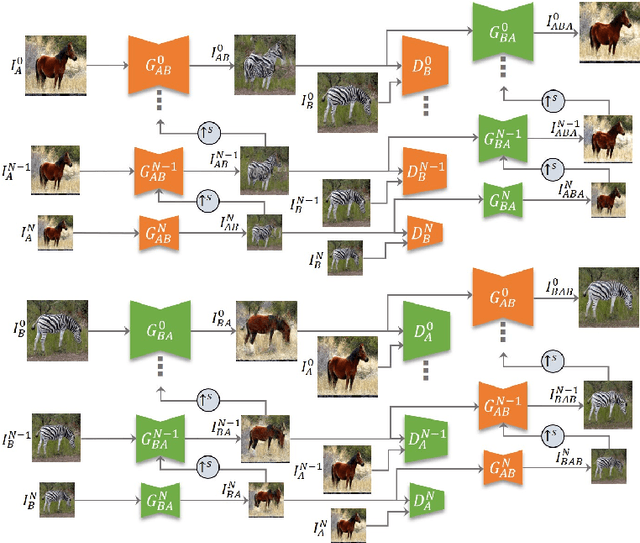
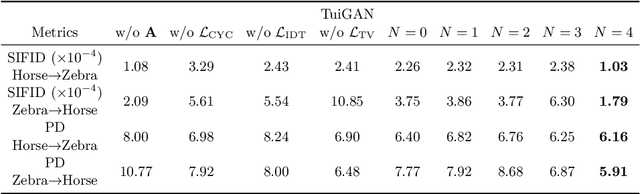
An unsupervised image-to-image translation (UI2I) task deals with learning a mapping between two domains without paired images. While existing UI2I methods usually require numerous unpaired images from different domains for training, there are many scenarios where training data is quite limited. In this paper, we argue that even if each domain contains a single image, UI2I can still be achieved. To this end, we propose TuiGAN, a generative model that is trained on only two unpaired images and amounts to one-shot unsupervised learning. With TuiGAN, an image is translated in a coarse-to-fine manner where the generated image is gradually refined from global structures to local details. We conduct extensive experiments to verify that our versatile method can outperform strong baselines on a wide variety of UI2I tasks. Moreover, TuiGAN is capable of achieving comparable performance with the state-of-the-art UI2I models trained with sufficient data.
Improving Shape Deformation in Unsupervised Image-to-Image Translation
Aug 13, 2018



Unsupervised image-to-image translation techniques are able to map local texture between two domains, but they are typically unsuccessful when the domains require larger shape change. Inspired by semantic segmentation, we introduce a discriminator with dilated convolutions that is able to use information from across the entire image to train a more context-aware generator. This is coupled with a multi-scale perceptual loss that is better able to represent error in the underlying shape of objects. We demonstrate that this design is more capable of representing shape deformation in a challenging toy dataset, plus in complex mappings with significant dataset variation between humans, dolls, and anime faces, and between cats and dogs.
Towards Lifelong Self-Supervision For Unpaired Image-to-Image Translation
Mar 31, 2020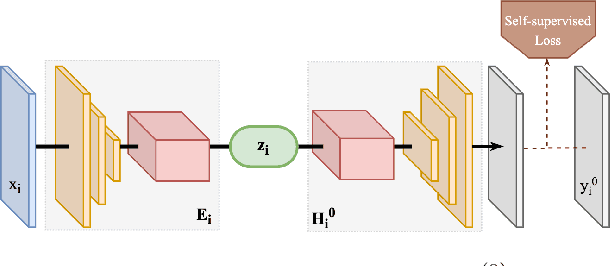
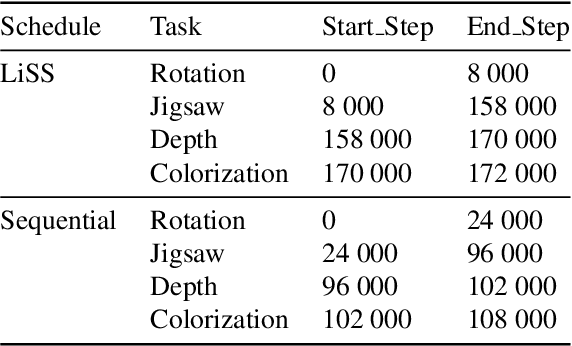
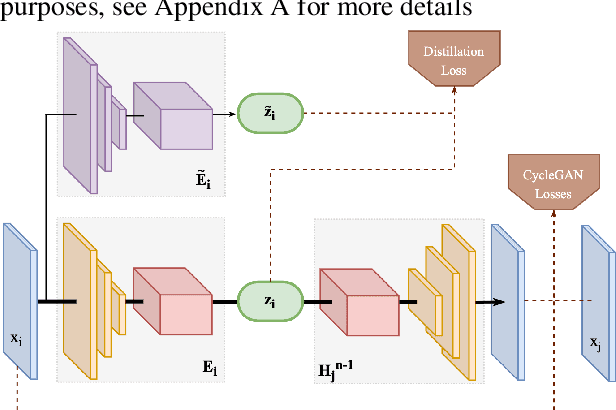
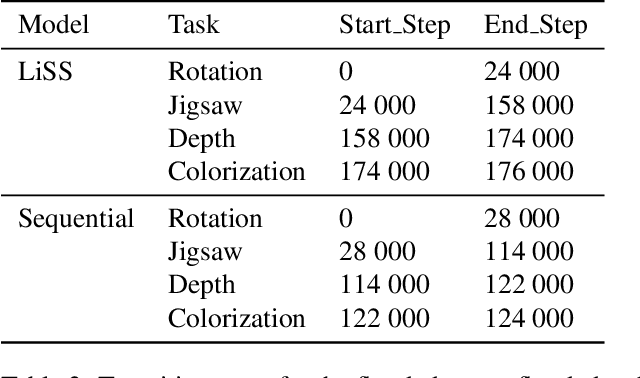
Unpaired Image-to-Image Translation (I2IT) tasks often suffer from lack of data, a problem which self-supervised learning (SSL) has recently been very popular and successful at tackling. Leveraging auxiliary tasks such as rotation prediction or generative colorization, SSL can produce better and more robust representations in a low data regime. Training such tasks along an I2IT task is however computationally intractable as model size and the number of task grow. On the other hand, learning sequentially could incur catastrophic forgetting of previously learned tasks. To alleviate this, we introduce Lifelong Self-Supervision (LiSS) as a way to pre-train an I2IT model (e.g., CycleGAN) on a set of self-supervised auxiliary tasks. By keeping an exponential moving average of past encoders and distilling the accumulated knowledge, we are able to maintain the network's validation performance on a number of tasks without any form of replay, parameter isolation or retraining techniques typically used in continual learning. We show that models trained with LiSS perform better on past tasks, while also being more robust than the CycleGAN baseline to color bias and entity entanglement (when two entities are very close).
Image Disentanglement and Uncooperative Re-Entanglement for High-Fidelity Image-to-Image Translation
Jan 11, 2019
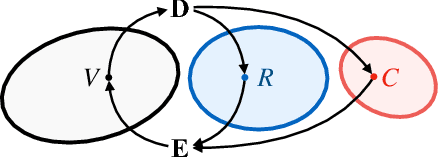
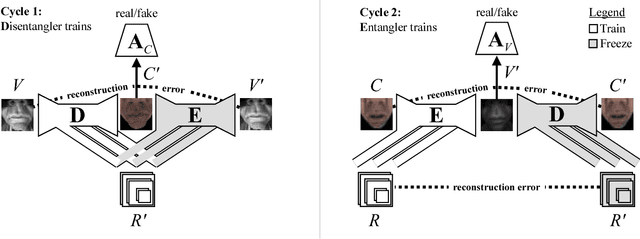
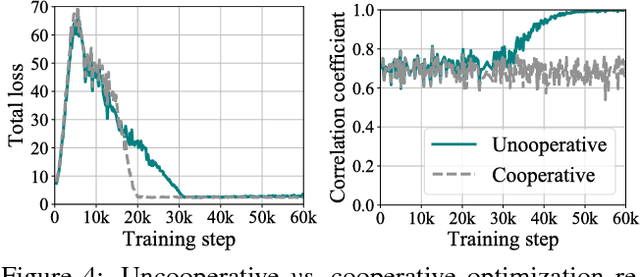
Cross-domain image-to-image translation should satisfy two requirements: (1) preserve the information that is common to both domains, and (2) generate convincing images covering variations that appear in the target domain. This is challenging, especially when there are no example translations available as supervision. Adversarial cycle consistency was recently proposed as a solution, with beautiful and creative results, yielding much follow-up work. However, augmented reality applications cannot readily use such techniques to provide users with compelling translations of real scenes, because the translations do not have high-fidelity constraints. In other words, current models are liable to change details that should be preserved: while re-texturing a face, they may alter the face's expression in an unpredictable way. In this paper, we introduce the problem of high-fidelity image-to-image translation, and present a method for solving it. Our main insight is that low-fidelity translations typically escape a cycle-consistency penalty, because the back-translator learns to compensate for the forward-translator's errors. We therefore introduce an optimization technique that prevents the networks from cooperating: simply train each network only when its input data is real. Prior works, in comparison, train each network with a mix of real and generated data. Experimental results show that our method accurately disentangles the factors that separate the domains, and converges to semantics-preserving translations that prior methods miss.
Depth- and Semantics-aware Multi-modal Domain Translation: Generating 3D Panoramic Color Images from LiDAR Point Clouds
Feb 15, 2023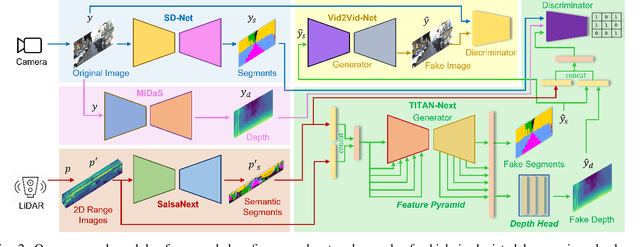



This work presents a new depth- and semantics-aware conditional generative model, named TITAN-Next, for cross-domain image-to-image translation in a multi-modal setup between LiDAR and camera sensors. The proposed model leverages scene semantics as a mid-level representation and is able to translate raw LiDAR point clouds to RGB-D camera images by solely relying on semantic scene segments. We claim that this is the first framework of its kind and it has practical applications in autonomous vehicles such as providing a fail-safe mechanism and augmenting available data in the target image domain. The proposed model is evaluated on the large-scale and challenging Semantic-KITTI dataset, and experimental findings show that it considerably outperforms the original TITAN-Net and other strong baselines by 23.7$\%$ margin in terms of IoU.
Auto-Encoding for Shared Cross Domain Feature Representation and Image-to-Image Translation
Jun 11, 2020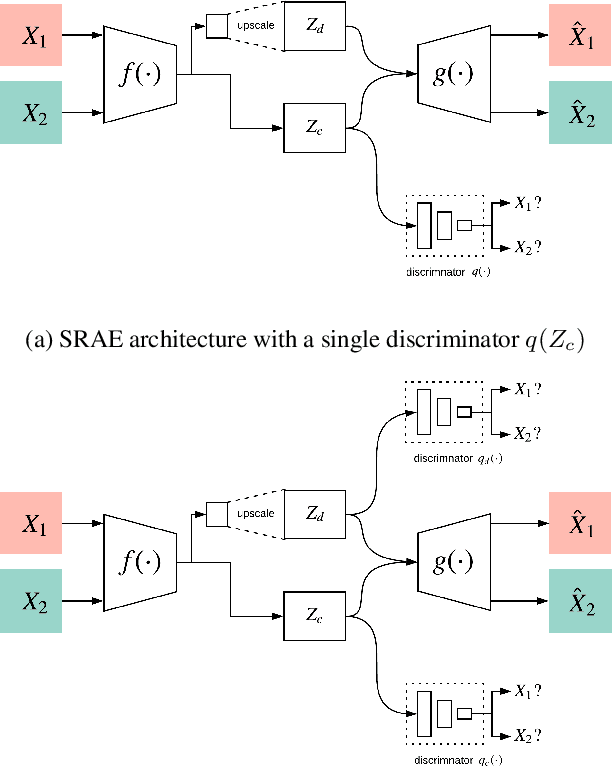
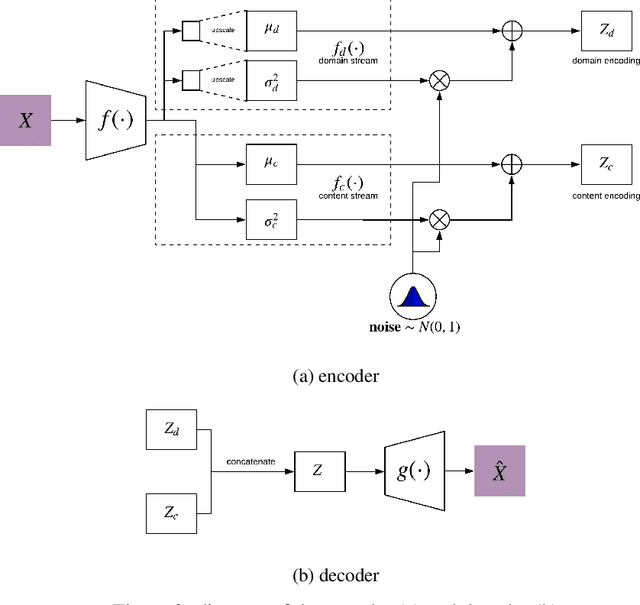
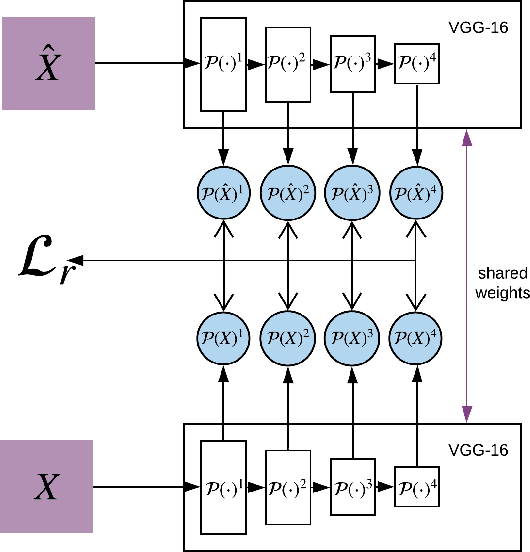

Image-to-image translation is a subset of computer vision and pattern recognition problems where our goal is to learn a mapping between input images of domain $\mathbf{X}_1$ and output images of domain $\mathbf{X}_2$. Current methods use neural networks with an encoder-decoder structure to learn a mapping $G:\mathbf{X}_1 \to\mathbf{X}_2$ such that the distribution of images from $\mathbf{X}_2$ and $G(\mathbf{X}_1)$ are identical, where $G(\mathbf{X}_1) = d_G (f_G (\mathbf{X}_1))$ and $f_G (\cdot)$ is referred as the encoder and $d_G(\cdot)$ is referred to as the decoder. Currently, such methods which also compute an inverse mapping $F:\mathbf{X}_2 \to \mathbf{X}_1$ use a separate encoder-decoder pair $d_F (f_F (\mathbf{X}_2))$ or at least a separate decoder $d_F (\cdot)$ to do so. Here we introduce a method to perform cross domain image-to-image translation across multiple domains using a single encoder-decoder architecture. We use an auto-encoder network which given an input image $\mathbf{X}_1$, first computes a latent domain encoding $Z_d = f_d (\mathbf{X}_1)$ and a latent content encoding $Z_c = f_c (\mathbf{X}_1)$, where the domain encoding $Z_d$ and content encoding $Z_c$ are independent. And then a decoder network $g(Z_d,Z_c)$ creates a reconstruction of the original image $\mathbf{\widehat{X}}_1=g(Z_d,Z_c )\approx \mathbf{X}_1$. Ideally, the domain encoding $Z_d$ contains no information regarding the content of the image and the content encoding $Z_c$ contains no information regarding the domain of the image. We use this property of the encodings to find the mapping across domains $G: X\to Y$ by simply changing the domain encoding $Z_d$ of the decoder's input. $G(\mathbf{X}_1 )=d(f_d (\mathbf{x}_2^i ),f_c (\mathbf{X}_1))$ where $\mathbf{x}_2^i$ is the $i^{th}$ observation of $\mathbf{X}_2$.
Generative Modeling with Flow-Guided Density Ratio Learning
Mar 07, 2023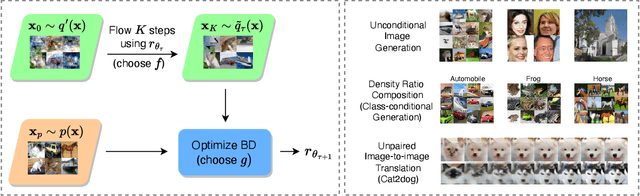

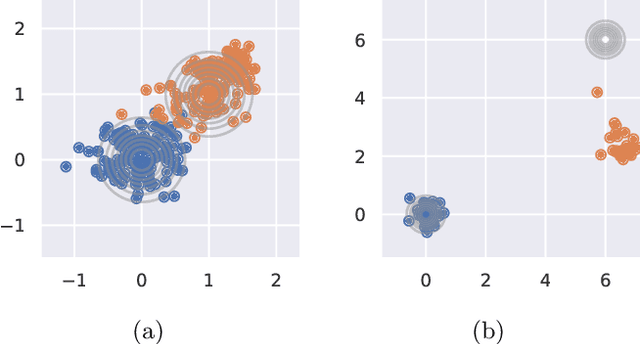
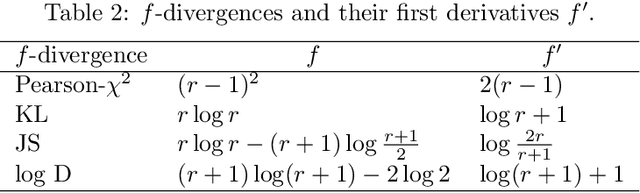
We present Flow-Guided Density Ratio Learning (FDRL), a simple and scalable approach to generative modeling which builds on the stale (time-independent) approximation of the gradient flow of entropy-regularized f-divergences introduced in DGflow. In DGflow, the intractable time-dependent density ratio is approximated by a stale estimator given by a GAN discriminator. This is sufficient in the case of sample refinement, where the source and target distributions of the flow are close to each other. However, this assumption is invalid for generation and a naive application of the stale estimator fails due to the large chasm between the two distributions. FDRL proposes to train a density ratio estimator such that it learns from progressively improving samples during the training process. We show that this simple method alleviates the density chasm problem, allowing FDRL to generate images of dimensions as high as $128\times128$, as well as outperform existing gradient flow baselines on quantitative benchmarks. We also show the flexibility of FDRL with two use cases. First, unconditional FDRL can be easily composed with external classifiers to perform class-conditional generation. Second, FDRL can be directly applied to unpaired image-to-image translation with no modifications needed to the framework. Code is publicly available at https://github.com/ajrheng/FDRL.
Optimal Transport Guided Unsupervised Learning for Enhancing low-quality Retinal Images
Feb 06, 2023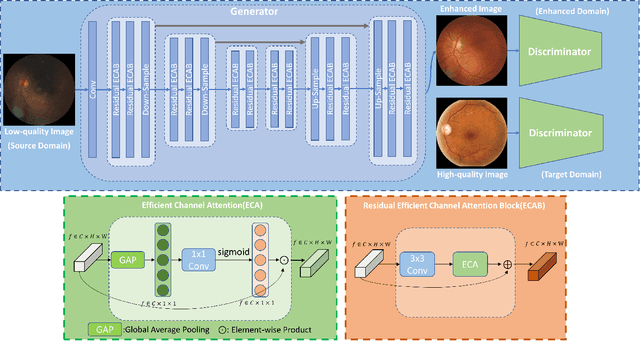
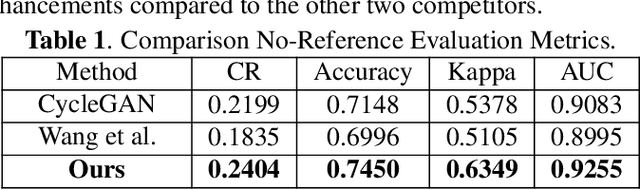
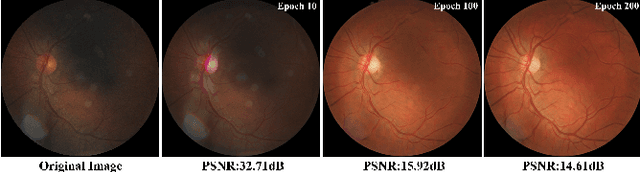
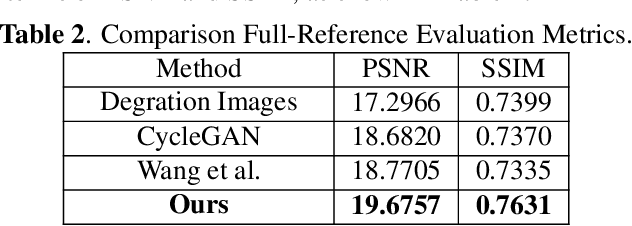
Real-world non-mydriatic retinal fundus photography is prone to artifacts, imperfections and low-quality when certain ocular or systemic co-morbidities exist. Artifacts may result in inaccuracy or ambiguity in clinical diagnoses. In this paper, we proposed a simple but effective end-to-end framework for enhancing poor-quality retinal fundus images. Leveraging the optimal transport theory, we proposed an unpaired image-to-image translation scheme for transporting low-quality images to their high-quality counterparts. We theoretically proved that a Generative Adversarial Networks (GAN) model with a generator and discriminator is sufficient for this task. Furthermore, to mitigate the inconsistency of information between the low-quality images and their enhancements, an information consistency mechanism was proposed to maximally maintain structural consistency (optical discs, blood vessels, lesions) between the source and enhanced domains. Extensive experiments were conducted on the EyeQ dataset to demonstrate the superiority of our proposed method perceptually and quantitatively.
Transformation Consistency Regularization- A Semi-Supervised Paradigm for Image-to-Image Translation
Jul 15, 2020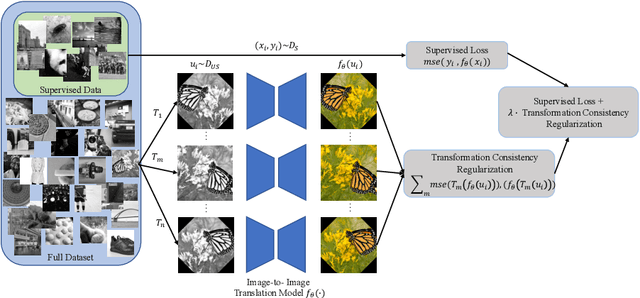
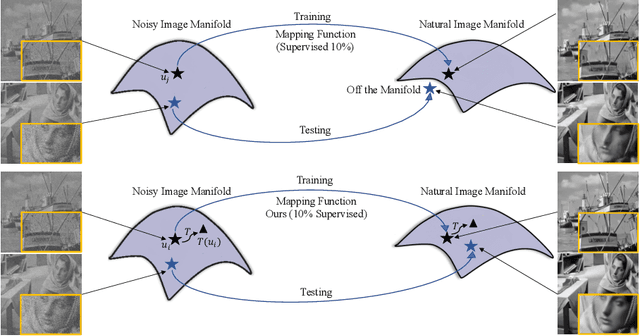
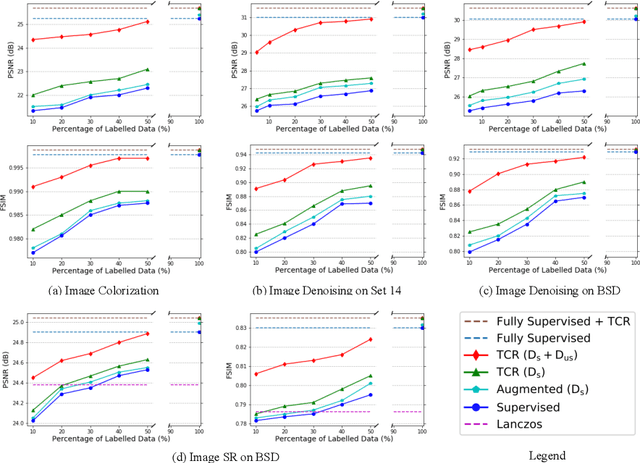

Scarcity of labeled data has motivated the development of semi-supervised learning methods, which learn from large portions of unlabeled data alongside a few labeled samples. Consistency Regularization between model's predictions under different input perturbations, particularly has shown to provide state-of-the art results in a semi-supervised framework. However, most of these method have been limited to classification and segmentation applications. We propose Transformation Consistency Regularization, which delves into a more challenging setting of image-to-image translation, which remains unexplored by semi-supervised algorithms. The method introduces a diverse set of geometric transformations and enforces the model's predictions for unlabeled data to be invariant to those transformations. We evaluate the efficacy of our algorithm on three different applications: image colorization, denoising and super-resolution. Our method is significantly data efficient, requiring only around 10 - 20% of labeled samples to achieve similar image reconstructions to its fully-supervised counterpart. Furthermore, we show the effectiveness of our method in video processing applications, where knowledge from a few frames can be leveraged to enhance the quality of the rest of the movie.
Reusing Discriminators for Encoding: Towards Unsupervised Image-to-Image Translation
Mar 28, 2020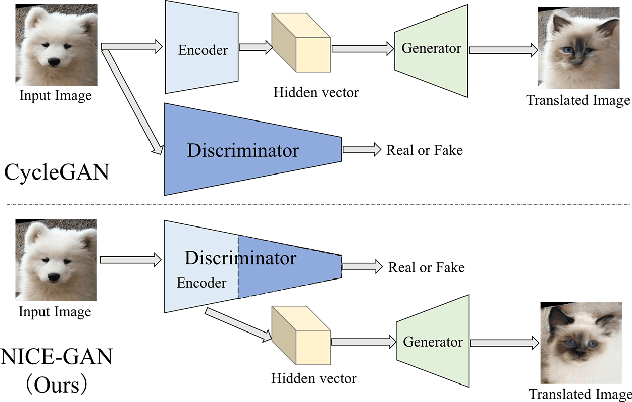
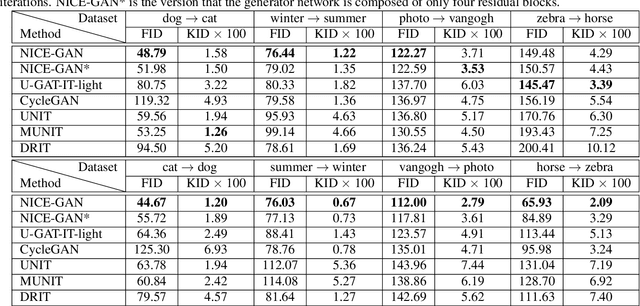
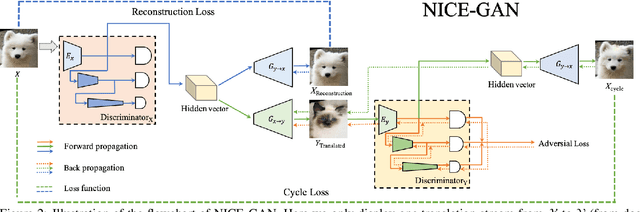
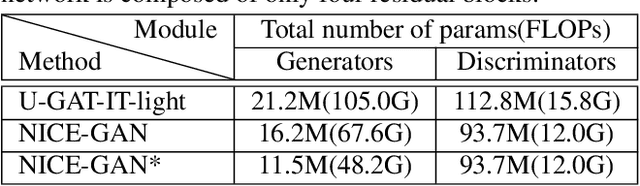
Unsupervised image-to-image translation is a central task in computer vision. Current translation frameworks will abandon the discriminator once the training process is completed. This paper contends a novel role of the discriminator by reusing it for encoding the images of the target domain. The proposed architecture, termed as NICE-GAN, exhibits two advantageous patterns over previous approaches: First, it is more compact since no independent encoding component is required; Second, this plug-in encoder is directly trained by the adversary loss, making it more informative and trained more effectively if a multi-scale discriminator is applied. The main issue in NICE-GAN is the coupling of translation with discrimination along the encoder, which could incur training inconsistency when we play the min-max game via GAN. To tackle this issue, we develop a decoupled training strategy by which the encoder is only trained when maximizing the adversary loss while keeping frozen otherwise. Extensive experiments on four popular benchmarks demonstrate the superior performance of NICE-GAN over state-of-the-art methods in terms of FID, KID, and also human preference. Comprehensive ablation studies are also carried out to isolate the validity of each proposed component. Our codes are available at https://github.com/alpc91/NICE-GAN-pytorch.