 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgemusic generation
Music generation is the task of generating music or music-like sounds from a model or algorithm.
Papers and Code
Aliasing-Free Neural Audio Synthesis
Dec 23, 2025



Neural vocoders and codecs reconstruct waveforms from acoustic representations, which directly impact the audio quality. Among existing methods, upsampling-based time-domain models are superior in both inference speed and synthesis quality, achieving state-of-the-art performance. Still, despite their success in producing perceptually natural sound, their synthesis fidelity remains limited due to the aliasing artifacts brought by the inadequately designed model architectures. In particular, the unconstrained nonlinear activation generates an infinite number of harmonics that exceed the Nyquist frequency, resulting in ``folded-back'' aliasing artifacts. The widely used upsampling layer, ConvTranspose, copies the mirrored low-frequency parts to fill the empty high-frequency region, resulting in ``mirrored'' aliasing artifacts. Meanwhile, the combination of its inherent periodicity and the mirrored DC bias also brings ``tonal artifact,'' resulting in constant-frequency ringing. This paper aims to solve these issues from a signal processing perspective. Specifically, we apply oversampling and anti-derivative anti-aliasing to the activation function to obtain its anti-aliased form, and replace the problematic ConvTranspose layer with resampling to avoid the ``tonal artifact'' and eliminate aliased components. Based on our proposed anti-aliased modules, we introduce Pupu-Vocoder and Pupu-Codec, and release high-quality pre-trained checkpoints to facilitate audio generation research. We build a test signal benchmark to illustrate the effectiveness of the anti-aliased modules, and conduct experiments on speech, singing voice, music, and audio to validate our proposed models. Experimental results confirm that our lightweight Pupu-Vocoder and Pupu-Codec models can easily outperform existing systems on singing voice, music, and audio, while achieving comparable performance on speech.
Aligning Generative Music AI with Human Preferences: Methods and Challenges
Nov 19, 2025Recent advances in generative AI for music have achieved remarkable fidelity and stylistic diversity, yet these systems often fail to align with nuanced human preferences due to the specific loss functions they use. This paper advocates for the systematic application of preference alignment techniques to music generation, addressing the fundamental gap between computational optimization and human musical appreciation. Drawing on recent breakthroughs including MusicRL's large-scale preference learning, multi-preference alignment frameworks like diffusion-based preference optimization in DiffRhythm+, and inference-time optimization techniques like Text2midi-InferAlign, we discuss how these techniques can address music's unique challenges: temporal coherence, harmonic consistency, and subjective quality assessment. We identify key research challenges including scalability to long-form compositions, reliability amongst others in preference modelling. Looking forward, we envision preference-aligned music generation enabling transformative applications in interactive composition tools and personalized music services. This work calls for sustained interdisciplinary research combining advances in machine learning, music-theory to create music AI systems that truly serve human creative and experiential needs.
Efficient Optimization of Hierarchical Identifiers for Generative Recommendation
Dec 20, 2025SEATER is a generative retrieval model that improves recommendation inference efficiency and retrieval quality by utilizing balanced tree-structured item identifiers and contrastive training objectives. We reproduce and validate SEATER's reported improvements in retrieval quality over strong baselines across all datasets from the original work, and extend the evaluation to Yambda, a large-scale music recommendation dataset. Our experiments verify SEATER's strong performance, but show that its tree construction step during training becomes a major bottleneck as the number of items grows. To address this, we implement and evaluate two alternative construction algorithms: a greedy method optimized for minimal build time, and a hybrid method that combines greedy clustering at high levels with more precise grouping at lower levels. The greedy method reduces tree construction time to less than 2% of the original with only a minor drop in quality on the dataset with the largest item collection. The hybrid method achieves retrieval quality on par with the original, and even improves on the largest dataset, while cutting construction time to just 5-8%. All data and code are publicly available for full reproducibility at https://github.com/joshrosie/re-seater.
Emovectors: assessing emotional content in jazz improvisations for creativity evaluation
Dec 09, 2025Music improvisation is fascinating to study, being essentially a live demonstration of a creative process. In jazz, musicians often improvise across predefined chord progressions (leadsheets). How do we assess the creativity of jazz improvisations? And can we capture this in automated metrics for creativity for current LLM-based generative systems? Demonstration of emotional involvement is closely linked with creativity in improvisation. Analysing musical audio, can we detect emotional involvement? This study hypothesises that if an improvisation contains more evidence of emotion-laden content, it is more likely to be recognised as creative. An embeddings-based method is proposed for capturing the emotional content in musical improvisations, using a psychologically-grounded classification of musical characteristics associated with emotions. Resulting 'emovectors' are analysed to test the above hypothesis, comparing across multiple improvisations. Capturing emotional content in this quantifiable way can contribute towards new metrics for creativity evaluation that can be applied at scale.
Generating Piano Music with Transformers: A Comparative Study of Scale, Data, and Metrics
Nov 10, 2025Although a variety of transformers have been proposed for symbolic music generation in recent years, there is still little comprehensive study on how specific design choices affect the quality of the generated music. In this work, we systematically compare different datasets, model architectures, model sizes, and training strategies for the task of symbolic piano music generation. To support model development and evaluation, we examine a range of quantitative metrics and analyze how well they correlate with human judgment collected through listening studies. Our best-performing model, a 950M-parameter transformer trained on 80K MIDI files from diverse genres, produces outputs that are often rated as human-composed in a Turing-style listening survey.
Memo2496: Expert-Annotated Dataset and Dual-View Adaptive Framework for Music Emotion Recognition
Dec 17, 2025
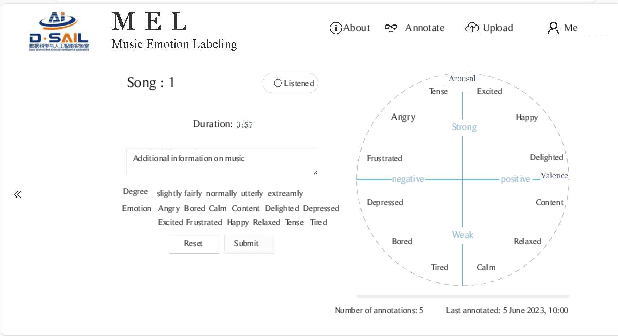
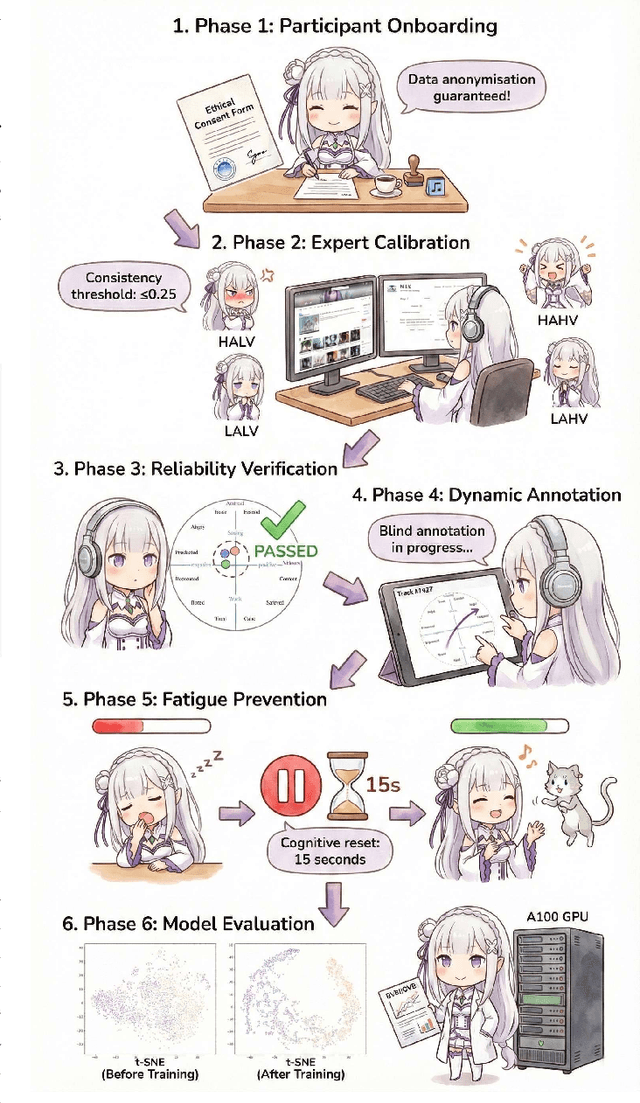
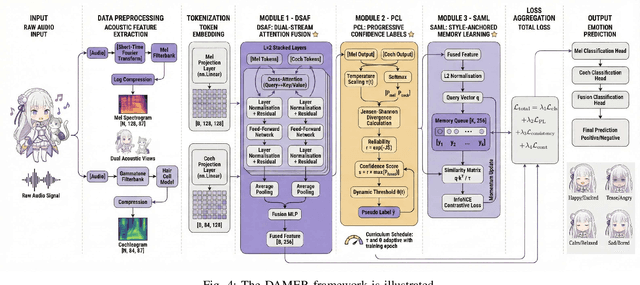
Music Emotion Recogniser (MER) research faces challenges due to limited high-quality annotated datasets and difficulties in addressing cross-track feature drift. This work presents two primary contributions to address these issues. Memo2496, a large-scale dataset, offers 2496 instrumental music tracks with continuous valence arousal labels, annotated by 30 certified music specialists. Annotation quality is ensured through calibration with extreme emotion exemplars and a consistency threshold of 0.25, measured by Euclidean distance in the valence arousal space. Furthermore, the Dual-view Adaptive Music Emotion Recogniser (DAMER) is introduced. DAMER integrates three synergistic modules: Dual Stream Attention Fusion (DSAF) facilitates token-level bidirectional interaction between Mel spectrograms and cochleagrams via cross attention mechanisms; Progressive Confidence Labelling (PCL) generates reliable pseudo labels employing curriculum-based temperature scheduling and consistency quantification using Jensen Shannon divergence; and Style Anchored Memory Learning (SAML) maintains a contrastive memory queue to mitigate cross-track feature drift. Extensive experiments on the Memo2496, 1000songs, and PMEmo datasets demonstrate DAMER's state-of-the-art performance, improving arousal dimension accuracy by 3.43%, 2.25%, and 0.17%, respectively. Ablation studies and visualisation analyses validate each module's contribution. Both the dataset and source code are publicly available.
Diff-V2M: A Hierarchical Conditional Diffusion Model with Explicit Rhythmic Modeling for Video-to-Music Generation
Nov 12, 2025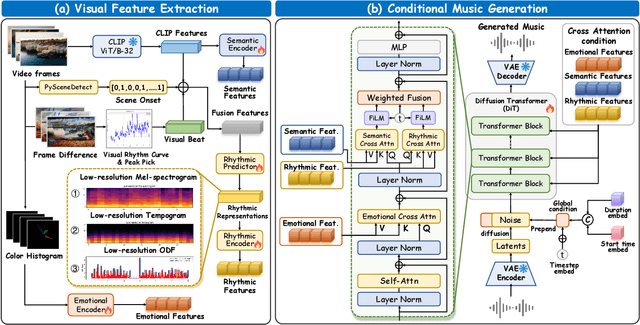
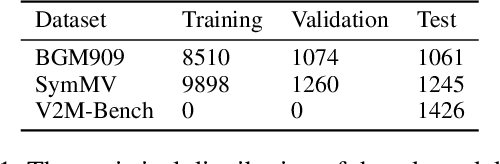
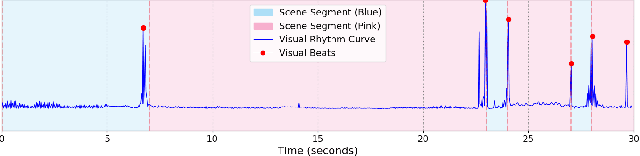
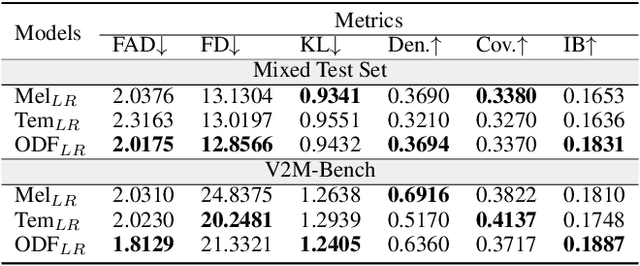
Video-to-music (V2M) generation aims to create music that aligns with visual content. However, two main challenges persist in existing methods: (1) the lack of explicit rhythm modeling hinders audiovisual temporal alignments; (2) effectively integrating various visual features to condition music generation remains non-trivial. To address these issues, we propose Diff-V2M, a general V2M framework based on a hierarchical conditional diffusion model, comprising two core components: visual feature extraction and conditional music generation. For rhythm modeling, we begin by evaluating several rhythmic representations, including low-resolution mel-spectrograms, tempograms, and onset detection functions (ODF), and devise a rhythmic predictor to infer them directly from videos. To ensure contextual and affective coherence, we also extract semantic and emotional features. All features are incorporated into the generator via a hierarchical cross-attention mechanism, where emotional features shape the affective tone via the first layer, while semantic and rhythmic features are fused in the second cross-attention layer. To enhance feature integration, we introduce timestep-aware fusion strategies, including feature-wise linear modulation (FiLM) and weighted fusion, allowing the model to adaptively balance semantic and rhythmic cues throughout the diffusion process. Extensive experiments identify low-resolution ODF as a more effective signal for modeling musical rhythm and demonstrate that Diff-V2M outperforms existing models on both in-domain and out-of-domain datasets, achieving state-of-the-art performance in terms of objective metrics and subjective comparisons. Demo and code are available at https://Tayjsl97.github.io/Diff-V2M-Demo/.
Melodia: Training-Free Music Editing Guided by Attention Probing in Diffusion Models
Nov 18, 2025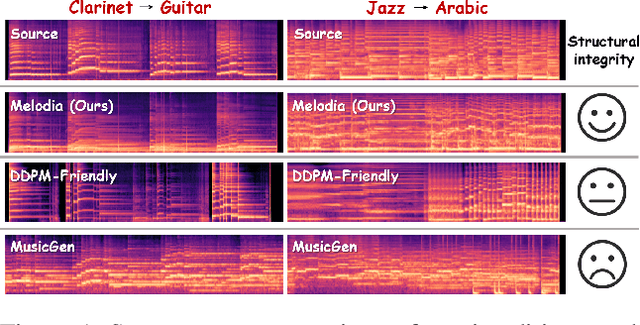
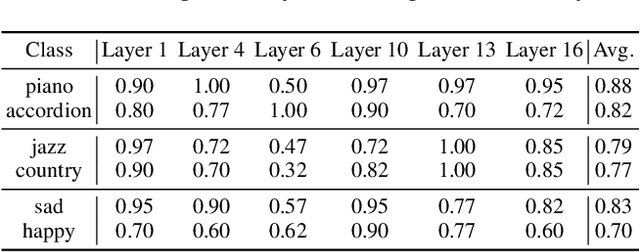
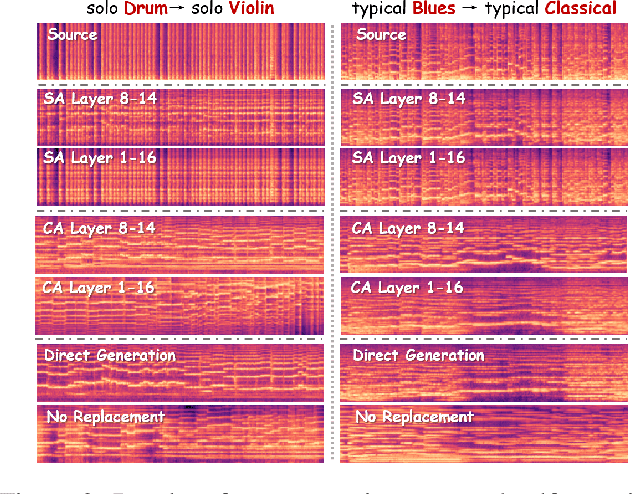
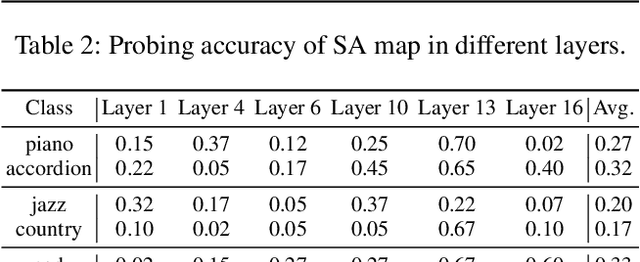
Text-to-music generation technology is progressing rapidly, creating new opportunities for musical composition and editing. However, existing music editing methods often fail to preserve the source music's temporal structure, including melody and rhythm, when altering particular attributes like instrument, genre, and mood. To address this challenge, this paper conducts an in-depth probing analysis on attention maps within AudioLDM 2, a diffusion-based model commonly used as the backbone for existing music editing methods. We reveal a key finding: cross-attention maps encompass details regarding distinct musical characteristics, and interventions on these maps frequently result in ineffective modifications. In contrast, self-attention maps are essential for preserving the temporal structure of the source music during its conversion into the target music. Building upon this understanding, we present Melodia, a training-free technique that selectively manipulates self-attention maps in particular layers during the denoising process and leverages an attention repository to store source music information, achieving accurate modification of musical characteristics while preserving the original structure without requiring textual descriptions of the source music. Additionally, we propose two novel metrics to better evaluate music editing methods. Both objective and subjective experiments demonstrate that our approach achieves superior results in terms of textual adherence and structural integrity across various datasets. This research enhances comprehension of internal mechanisms within music generation models and provides improved control for music creation.
On the Joint Minimization of Regularization Loss Functions in Deep Variational Bayesian Methods for Attribute-Controlled Symbolic Music Generation
Nov 10, 2025Explicit latent variable models provide a flexible yet powerful framework for data synthesis, enabling controlled manipulation of generative factors. With latent variables drawn from a tractable probability density function that can be further constrained, these models enable continuous and semantically rich exploration of the output space by navigating their latent spaces. Structured latent representations are typically obtained through the joint minimization of regularization loss functions. In variational information bottleneck models, reconstruction loss and Kullback-Leibler Divergence (KLD) are often linearly combined with an auxiliary Attribute-Regularization (AR) loss. However, balancing KLD and AR turns out to be a very delicate matter. When KLD dominates over AR, generative models tend to lack controllability; when AR dominates over KLD, the stochastic encoder is encouraged to violate the standard normal prior. We explore this trade-off in the context of symbolic music generation with explicit control over continuous musical attributes. We show that existing approaches struggle to jointly minimize both regularization objectives, whereas suitable attribute transformations can help achieve both controllability and regularization of the target latent dimensions.
* IEEE Catalog No.: CFP2540S-ART ISBN: 978-9-46-459362-4
Conditional Diffusion as Latent Constraints for Controllable Symbolic Music Generation
Nov 10, 2025



Recent advances in latent diffusion models have demonstrated state-of-the-art performance in high-dimensional time-series data synthesis while providing flexible control through conditioning and guidance. However, existing methodologies primarily rely on musical context or natural language as the main modality of interacting with the generative process, which may not be ideal for expert users who seek precise fader-like control over specific musical attributes. In this work, we explore the application of denoising diffusion processes as plug-and-play latent constraints for unconditional symbolic music generation models. We focus on a framework that leverages a library of small conditional diffusion models operating as implicit probabilistic priors on the latents of a frozen unconditional backbone. While previous studies have explored domain-specific use cases, this work, to the best of our knowledge, is the first to demonstrate the versatility of such an approach across a diverse array of musical attributes, such as note density, pitch range, contour, and rhythm complexity. Our experiments show that diffusion-driven constraints outperform traditional attribute regularization and other latent constraints architectures, achieving significantly stronger correlations between target and generated attributes while maintaining high perceptual quality and diversity.