 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgechatbots
Papers and Code
Addressing accuracy and hallucination of LLMs in Alzheimer's disease research through knowledge graphs
Aug 28, 2025



In the past two years, large language model (LLM)-based chatbots, such as ChatGPT, have revolutionized various domains by enabling diverse task completion and question-answering capabilities. However, their application in scientific research remains constrained by challenges such as hallucinations, limited domain-specific knowledge, and lack of explainability or traceability for the response. Graph-based Retrieval-Augmented Generation (GraphRAG) has emerged as a promising approach to improving chatbot reliability by integrating domain-specific contextual information before response generation, addressing some limitations of standard LLMs. Despite its potential, there are only limited studies that evaluate GraphRAG on specific domains that require intensive knowledge, like Alzheimer's disease or other biomedical domains. In this paper, we assess the quality and traceability of two popular GraphRAG systems. We compile a database of 50 papers and 70 expert questions related to Alzheimer's disease, construct a GraphRAG knowledge base, and employ GPT-4o as the LLM for answering queries. We then compare the quality of responses generated by GraphRAG with those from a standard GPT-4o model. Additionally, we discuss and evaluate the traceability of several Retrieval-Augmented Generation (RAG) and GraphRAG systems. Finally, we provide an easy-to-use interface with a pre-built Alzheimer's disease database for researchers to test the performance of both standard RAG and GraphRAG.
ChatThero: An LLM-Supported Chatbot for Behavior Change and Therapeutic Support in Addiction Recovery
Aug 28, 2025
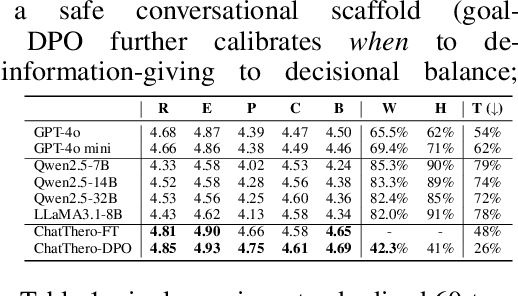
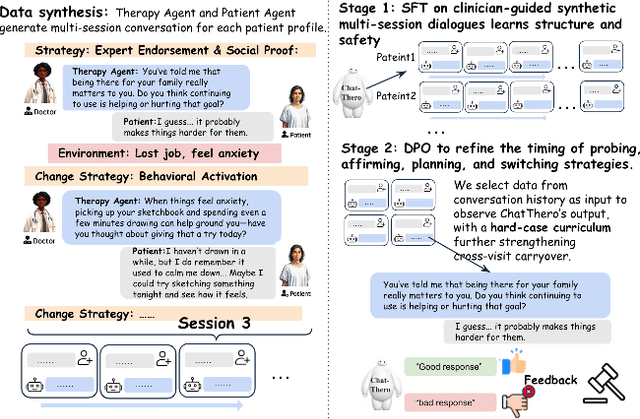

Substance use disorders (SUDs) affect over 36 million people worldwide, yet few receive effective care due to stigma, motivational barriers, and limited personalized support. Although large language models (LLMs) show promise for mental-health assistance, most systems lack tight integration with clinically validated strategies, reducing effectiveness in addiction recovery. We present ChatThero, a multi-agent conversational framework that couples dynamic patient modeling with context-sensitive therapeutic dialogue and adaptive persuasive strategies grounded in cognitive behavioral therapy (CBT) and motivational interviewing (MI). We build a high-fidelity synthetic benchmark spanning Easy, Medium, and Hard resistance levels, and train ChatThero with a two-stage pipeline comprising supervised fine-tuning (SFT) followed by direct preference optimization (DPO). In evaluation, ChatThero yields a 41.5\% average gain in patient motivation, a 0.49\% increase in treatment confidence, and resolves hard cases with 26\% fewer turns than GPT-4o, and both automated and human clinical assessments rate it higher in empathy, responsiveness, and behavioral realism. The framework supports rigorous, privacy-preserving study of therapeutic conversation and provides a robust, replicable basis for research and clinical translation.
Hallucinating with AI: AI Psychosis as Distributed Delusions
Aug 27, 2025There is much discussion of the false outputs that generative AI systems such as ChatGPT, Claude, Gemini, DeepSeek, and Grok create. In popular terminology, these have been dubbed AI hallucinations. However, deeming these AI outputs hallucinations is controversial, with many claiming this is a metaphorical misnomer. Nevertheless, in this paper, I argue that when viewed through the lens of distributed cognition theory, we can better see the dynamic and troubling ways in which inaccurate beliefs, distorted memories and self-narratives, and delusional thinking can emerge through human-AI interactions; examples of which are popularly being referred to as cases of AI psychosis. In such cases, I suggest we move away from thinking about how an AI system might hallucinate at us, by generating false outputs, to thinking about how, when we routinely rely on generative AI to help us think, remember, and narrate, we can come to hallucinate with AI. This can happen when AI introduces errors into the distributed cognitive process, but it can also happen when AI sustains, affirms, and elaborates on our own delusional thinking and self-narratives, such as in the case of Jaswant Singh Chail. I also examine how the conversational style of chatbots can lead them to play a dual-function, both as a cognitive artefact and a quasi-Other with whom we co-construct our beliefs, narratives, and our realities. It is this dual function, I suggest, that makes generative AI an unusual, and particularly seductive, case of distributed cognition.
Scalable Engine and the Performance of Different LLM Models in a SLURM based HPC architecture
Aug 25, 2025This work elaborates on a High performance computing (HPC) architecture based on Simple Linux Utility for Resource Management (SLURM) [1] for deploying heterogeneous Large Language Models (LLMs) into a scalable inference engine. Dynamic resource scheduling and seamless integration of containerized microservices have been leveraged herein to manage CPU, GPU, and memory allocations efficiently in multi-node clusters. Extensive experiments, using Llama 3.2 (1B and 3B parameters) [2] and Llama 3.1 (8B and 70B) [3], probe throughput, latency, and concurrency and show that small models can handle up to 128 concurrent requests at sub-50 ms latency, while for larger models, saturation happens with as few as two concurrent users, with a latency of more than 2 seconds. This architecture includes Representational State Transfer Application Programming Interfaces (REST APIs) [4] endpoints for single and bulk inferences, as well as advanced workflows such as multi-step "tribunal" refinement. Experimental results confirm minimal overhead from container and scheduling activities and show that the approach scales reliably both for batch and interactive settings. We further illustrate real-world scenarios, including the deployment of chatbots with retrievalaugmented generation, which helps to demonstrate the flexibility and robustness of the architecture. The obtained results pave ways for significantly more efficient, responsive, and fault-tolerant LLM inference on large-scale HPC infrastructures.
Unraveling the cognitive patterns of Large Language Models through module communities
Aug 25, 2025Large Language Models (LLMs) have reshaped our world with significant advancements in science, engineering, and society through applications ranging from scientific discoveries and medical diagnostics to Chatbots. Despite their ubiquity and utility, the underlying mechanisms of LLM remain concealed within billions of parameters and complex structures, making their inner architecture and cognitive processes challenging to comprehend. We address this gap by adopting approaches to understanding emerging cognition in biology and developing a network-based framework that links cognitive skills, LLM architectures, and datasets, ushering in a paradigm shift in foundation model analysis. The skill distribution in the module communities demonstrates that while LLMs do not strictly parallel the focalized specialization observed in specific biological systems, they exhibit unique communities of modules whose emergent skill patterns partially mirror the distributed yet interconnected cognitive organization seen in avian and small mammalian brains. Our numerical results highlight a key divergence from biological systems to LLMs, where skill acquisition benefits substantially from dynamic, cross-regional interactions and neural plasticity. By integrating cognitive science principles with machine learning, our framework provides new insights into LLM interpretability and suggests that effective fine-tuning strategies should leverage distributed learning dynamics rather than rigid modular interventions.
Detecting Reading-Induced Confusion Using EEG and Eye Tracking
Aug 20, 2025


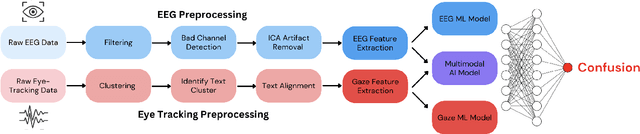
Humans regularly navigate an overwhelming amount of information via text media, whether reading articles, browsing social media, or interacting with chatbots. Confusion naturally arises when new information conflicts with or exceeds a reader's comprehension or prior knowledge, posing a challenge for learning. In this study, we present a multimodal investigation of reading-induced confusion using EEG and eye tracking. We collected neural and gaze data from 11 adult participants as they read short paragraphs sampled from diverse, real-world sources. By isolating the N400 event-related potential (ERP), a well-established neural marker of semantic incongruence, and integrating behavioral markers from eye tracking, we provide a detailed analysis of the neural and behavioral correlates of confusion during naturalistic reading. Using machine learning, we show that multimodal (EEG + eye tracking) models improve classification accuracy by 4-22% over unimodal baselines, reaching an average weighted participant accuracy of 77.3% and a best accuracy of 89.6%. Our results highlight the dominance of the brain's temporal regions in these neural signatures of confusion, suggesting avenues for wearable, low-electrode brain-computer interfaces (BCI) for real-time monitoring. These findings lay the foundation for developing adaptive systems that dynamically detect and respond to user confusion, with potential applications in personalized learning, human-computer interaction, and accessibility.
Out of the Box, into the Clinic? Evaluating State-of-the-Art ASR for Clinical Applications for Older Adults
Aug 12, 2025


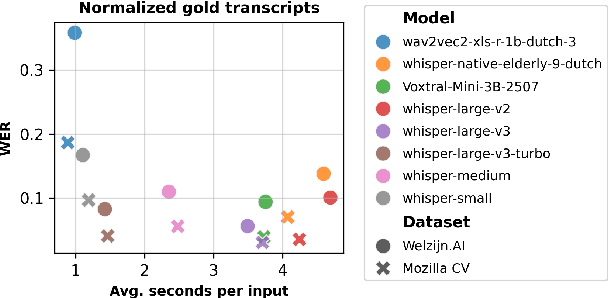
Voice-controlled interfaces can support older adults in clinical contexts, with chatbots being a prime example, but reliable Automatic Speech Recognition (ASR) for underrepresented groups remains a bottleneck. This study evaluates state-of-the-art ASR models on language use of older Dutch adults, who interacted with the Welzijn.AI chatbot designed for geriatric contexts. We benchmark generic multilingual ASR models, and models fine-tuned for Dutch spoken by older adults, while also considering processing speed. Our results show that generic multilingual models outperform fine-tuned models, which suggests recent ASR models can generalise well out of the box to realistic datasets. Furthermore, our results suggest that truncating existing architectures is helpful in balancing the accuracy-speed trade-off, though we also identify some cases with high WER due to hallucinations.
Strategies of Code-switching in Human-Machine Dialogs
Aug 10, 2025Most people are multilingual, and most multilinguals code-switch, yet the characteristics of code-switched language are not fully understood. We developed a chatbot capable of completing a Map Task with human participants using code-switched Spanish and English. In two experiments, we prompted the bot to code-switch according to different strategies, examining (1) the feasibility of such experiments for investigating bilingual language use, and (2) whether participants would be sensitive to variations in discourse and grammatical patterns. Participants generally enjoyed code-switching with our bot as long as it produced predictable code-switching behavior; when code-switching was random or ungrammatical (as when producing unattested incongruent mixed-language noun phrases, such as `la fork'), participants enjoyed the task less and were less successful at completing it. These results underscore the potential downsides of deploying insufficiently developed multilingual language technology, while also illustrating the promise of such technology for conducting research on bilingual language use.
Can Large Models Fool the Eye? A New Turing Test for Biological Animation
Aug 08, 2025Evaluating the abilities of large models and manifesting their gaps are challenging. Current benchmarks adopt either ground-truth-based score-form evaluation on static datasets or indistinct textual chatbot-style human preferences collection, which may not provide users with immediate, intuitive, and perceptible feedback on performance differences. In this paper, we introduce BioMotion Arena, a novel framework for evaluating large language models (LLMs) and multimodal large language models (MLLMs) via visual animation. Our methodology draws inspiration from the inherent visual perception of motion patterns characteristic of living organisms that utilizes point-light source imaging to amplify the performance discrepancies between models. Specifically, we employ a pairwise comparison evaluation and collect more than 45k votes for 53 mainstream LLMs and MLLMs on 90 biological motion variants. Data analyses show that the crowd-sourced human votes are in good agreement with those of expert raters, demonstrating the superiority of our BioMotion Arena in offering discriminative feedback. We also find that over 90\% of evaluated models, including the cutting-edge open-source InternVL3 and proprietary Claude-4 series, fail to produce fundamental humanoid point-light groups, much less smooth and biologically plausible motions. This enables BioMotion Arena to serve as a challenging benchmark for performance visualization and a flexible evaluation framework without restrictions on ground-truth.
Mitigating Undesired Conditions in Flexible Production with Product-Process-Resource Asset Knowledge Graphs
Aug 08, 2025Contemporary industrial cyber-physical production systems (CPPS) composed of robotic workcells face significant challenges in the analysis of undesired conditions due to the flexibility of Industry 4.0 that disrupts traditional quality assurance mechanisms. This paper presents a novel industry-oriented semantic model called Product-Process-Resource Asset Knowledge Graph (PPR-AKG), which is designed to analyze and mitigate undesired conditions in flexible CPPS. Built on top of the well-proven Product-Process-Resource (PPR) model originating from ISA-95 and VDI-3682, a comprehensive OWL ontology addresses shortcomings of conventional model-driven engineering for CPPS, particularly inadequate undesired condition and error handling representation. The integration of semantic technologies with large language models (LLMs) provides intuitive interfaces for factory operators, production planners, and engineers to interact with the entire model using natural language. Evaluation with the use case addressing electric vehicle battery remanufacturing demonstrates that the PPR-AKG approach efficiently supports resource allocation based on explicitly represented capabilities as well as identification and mitigation of undesired conditions in production. The key contributions include (1) a holistic PPR-AKG model capturing multi-dimensional production knowledge, and (2) the useful combination of the PPR-AKG with LLM-based chatbots for human interaction.