 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWord Level Pronunciation Scoring
Papers and Code
End-to-End Simultaneous Dysarthric Speech Reconstruction with Frame-Level Adaptor and Multiple Wait-k Knowledge Distillation
Mar 02, 2026Dysarthric speech reconstruction (DSR) typically employs a cascaded system that combines automatic speech recognition (ASR) and sentence-level text-to-speech (TTS) to convert dysarthric speech into normally-prosodied speech. However, dysarthric individuals often speak more slowly, leading to excessively long response times in such systems, rendering them impractical in long-speech scenarios. Cascaded DSR systems based on streaming ASR and incremental TTS can help reduce latency. However, patients with differing dysarthria severity exhibit substantial pronunciation variability for the same text, resulting in poor robustness of ASR and limiting the intelligibility of reconstructed speech. In addition, incremental TTS suffers from poor prosodic feature prediction due to a limited receptive field. In this study, we propose an end-to-end simultaneous DSR system with two key innovations: 1) A frame-level adaptor module is introduced to bridge ASR and TTS. By employing explicit-implicit semantic information fusion and joint module training, it enhances the error tolerance of TTS to ASR outputs. 2) A multiple wait-k autoregressive TTS module is designed to mitigate prosodic degradation via multi-view knowledge distillation. Our system has an average response time of 1.03 seconds on Tesla A100, with an average real-time factor (RTF) of 0.71. On the UASpeech dataset, it attains a mean opinion score (MOS) of 4.67 and demonstrates a 54.25% relative reduction in word error rate (WER) compared to the state-of-the-art. Our demo is available at: https://wflrz123.github.io/
* Submitted to 2025 Asia Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC)
End-to-End Word-Level Pronunciation Assessment with MASK Pre-training
Jun 05, 2023



Pronunciation assessment is a major challenge in the computer-aided pronunciation training system, especially at the word (phoneme)-level. To obtain word (phoneme)-level scores, current methods usually rely on aligning components to obtain acoustic features of each word (phoneme), which limits the performance of assessment to the accuracy of alignments. Therefore, to address this problem, we propose a simple yet effective method, namely \underline{M}asked pre-training for \underline{P}ronunciation \underline{A}ssessment (MPA). Specifically, by incorporating a mask-predict strategy, our MPA supports end-to-end training without leveraging any aligning components and can solve misalignment issues to a large extent during prediction. Furthermore, we design two evaluation strategies to enable our model to conduct assessments in both unsupervised and supervised settings. Experimental results on SpeechOcean762 dataset demonstrate that MPA could achieve better performance than previous methods, without any explicit alignment. In spite of this, MPA still has some limitations, such as requiring more inference time and reference text. They expect to be addressed in future work.
The DeepZen Speech Synthesis System for Blizzard Challenge 2023
Sep 01, 2023



This paper describes the DeepZen text to speech (TTS) system for Blizzard Challenge 2023. The goal of this challenge is to synthesise natural and high-quality speech in French, from a large monospeaker dataset (hub task) and from a smaller dataset by speaker adaptation (spoke task). We participated to both tasks with the same model architecture. Our approach has been to use an auto-regressive model, which retains an advantage for generating natural sounding speech but to improve prosodic control in several ways. Similarly to non-attentive Tacotron, the model uses a duration predictor and gaussian upsampling at inference, but with a simpler unsupervised training. We also model the speaking style at both sentence and word levels by extracting global and local style tokens from the reference speech. At inference, the global and local style tokens are predicted from a BERT model run on text. This BERT model is also used to predict specific pronunciation features like schwa elision and optional liaisons. Finally, a modified version of HifiGAN trained on a large public dataset and fine-tuned on the target voices is used to generate speech waveform. Our team is identified as O in the the Blizzard evaluation and MUSHRA test results show that our system performs second ex aequo in both hub task (median score of 0.75) and spoke task (median score of 0.68), over 18 and 14 participants, respectively.
The FruitShell French synthesis system at the Blizzard 2023 Challenge
Sep 01, 2023



This paper presents a French text-to-speech synthesis system for the Blizzard Challenge 2023. The challenge consists of two tasks: generating high-quality speech from female speakers and generating speech that closely resembles specific individuals. Regarding the competition data, we conducted a screening process to remove missing or erroneous text data. We organized all symbols except for phonemes and eliminated symbols that had no pronunciation or zero duration. Additionally, we added word boundary and start/end symbols to the text, which we have found to improve speech quality based on our previous experience. For the Spoke task, we performed data augmentation according to the competition rules. We used an open-source G2P model to transcribe the French texts into phonemes. As the G2P model uses the International Phonetic Alphabet (IPA), we applied the same transcription process to the provided competition data for standardization. However, due to compiler limitations in recognizing special symbols from the IPA chart, we followed the rules to convert all phonemes into the phonetic scheme used in the competition data. Finally, we resampled all competition audio to a uniform sampling rate of 16 kHz. We employed a VITS-based acoustic model with the hifigan vocoder. For the Spoke task, we trained a multi-speaker model and incorporated speaker information into the duration predictor, vocoder, and flow layers of the model. The evaluation results of our system showed a quality MOS score of 3.6 for the Hub task and 3.4 for the Spoke task, placing our system at an average level among all participating teams.
Improving Non-native Word-level Pronunciation Scoring with Phone-level Mixup Data Augmentation and Multi-source Information
Mar 01, 2022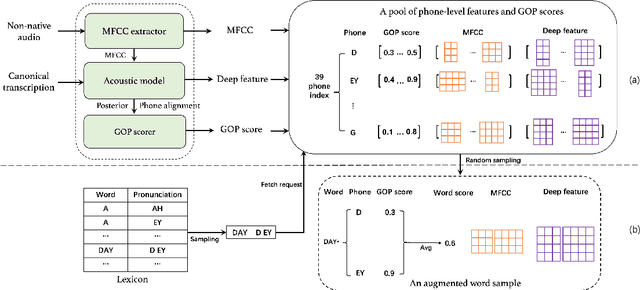

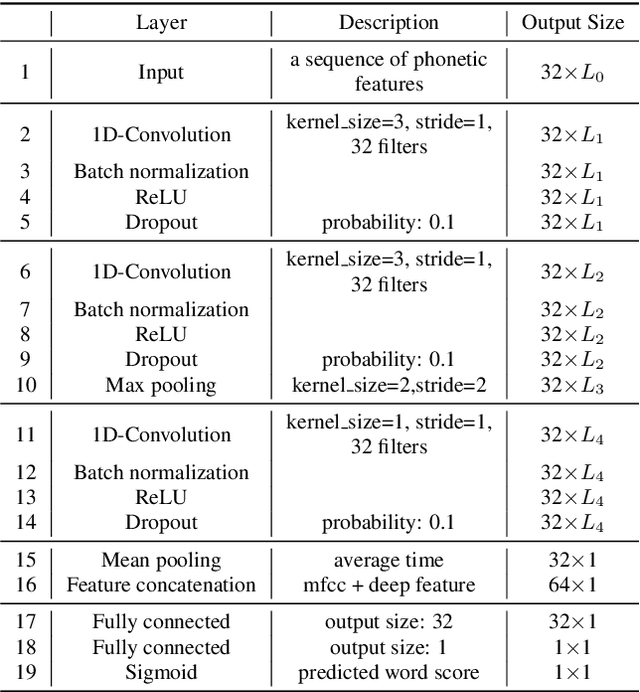
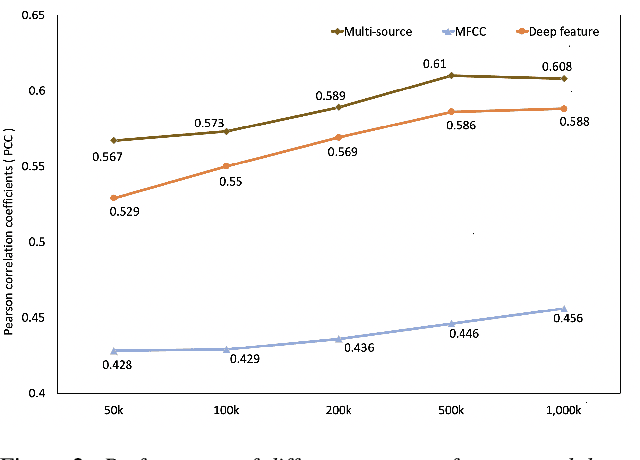
Deep learning-based pronunciation scoring models highly rely on the availability of the annotated non-native data, which is costly and has scalability issues. To deal with the data scarcity problem, data augmentation is commonly used for model pretraining. In this paper, we propose a phone-level mixup, a simple yet effective data augmentation method, to improve the performance of word-level pronunciation scoring. Specifically, given a phoneme sequence from lexicon, the artificial augmented word sample can be generated by randomly sampling from the corresponding phone-level features in training data, while the word score is the average of their GOP scores. Benefit from the arbitrary phone-level combination, the mixup is able to generate any word with various pronunciation scores. Moreover, we utilize multi-source information (e.g., MFCC and deep features) to further improve the scoring system performance. The experiments conducted on the Speechocean762 show that the proposed system outperforms the baseline by adding the mixup data for pretraining, with Pearson correlation coefficients (PCC) increasing from 0.567 to 0.61. The results also indicate that proposed method achieves similar performance by using 1/10 unlabeled data of baseline. In addition, the experimental results also demonstrate the efficiency of our proposed multi-source approach.
A Hierarchical Context-aware Modeling Approach for Multi-aspect and Multi-granular Pronunciation Assessment
Jun 07, 2023



Automatic Pronunciation Assessment (APA) plays a vital role in Computer-assisted Pronunciation Training (CAPT) when evaluating a second language (L2) learner's speaking proficiency. However, an apparent downside of most de facto methods is that they parallelize the modeling process throughout different speech granularities without accounting for the hierarchical and local contextual relationships among them. In light of this, a novel hierarchical approach is proposed in this paper for multi-aspect and multi-granular APA. Specifically, we first introduce the notion of sup-phonemes to explore more subtle semantic traits of L2 speakers. Second, a depth-wise separable convolution layer is exploited to better encapsulate the local context cues at the sub-word level. Finally, we use a score-restraint attention pooling mechanism to predict the sentence-level scores and optimize the component models with a multitask learning (MTL) framework. Extensive experiments carried out on a publicly-available benchmark dataset, viz. speechocean762, demonstrate the efficacy of our approach in relation to some cutting-edge baselines.
Hierarchical Pronunciation Assessment with Multi-Aspect Attention
Nov 15, 2022



Automatic pronunciation assessment is a major component of a computer-assisted pronunciation training system. To provide in-depth feedback, scoring pronunciation at various levels of granularity such as phoneme, word, and utterance, with diverse aspects such as accuracy, fluency, and completeness, is essential. However, existing multi-aspect multi-granularity methods simultaneously predict all aspects at all granularity levels; therefore, they have difficulty in capturing the linguistic hierarchy of phoneme, word, and utterance. This limitation further leads to neglecting intimate cross-aspect relations at the same linguistic unit. In this paper, we propose a Hierarchical Pronunciation Assessment with Multi-aspect Attention (HiPAMA) model, which hierarchically represents the granularity levels to directly capture their linguistic structures and introduces multi-aspect attention that reflects associations across aspects at the same level to create more connotative representations. By obtaining relational information from both the granularity- and aspect-side, HiPAMA can take full advantage of multi-task learning. Remarkable improvements in the experimental results on the speachocean762 datasets demonstrate the robustness of HiPAMA, particularly in the difficult-to-assess aspects.
Goodness of Pronunciation Pipelines for OOV Problem
Sep 14, 2022
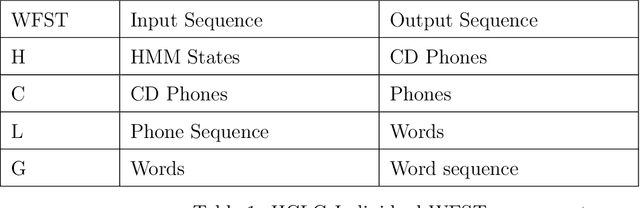
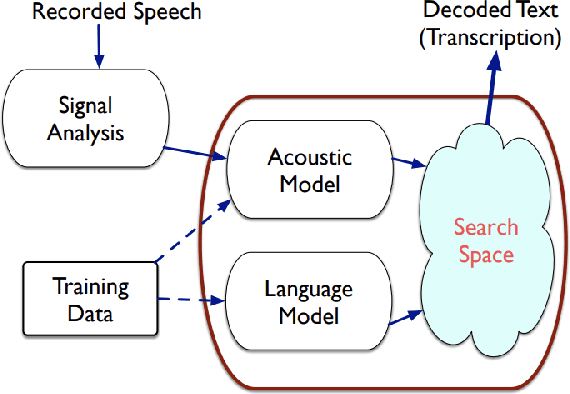
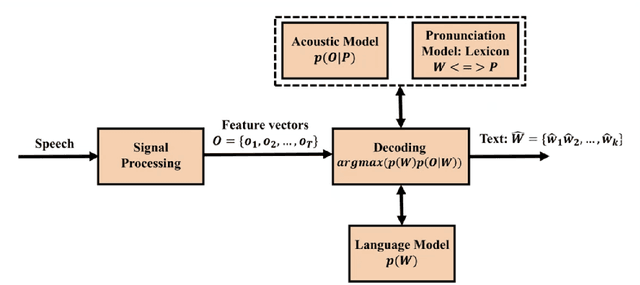
In the following report we propose pipelines for Goodness of Pronunciation (GoP) computation solving OOV problem at testing time using Vocab/Lexicon expansion techniques. The pipeline uses different components of ASR system to quantify accent and automatically evaluate them as scores. We use the posteriors of an ASR model trained on native English speech, along with the phone level boundaries to obtain phone level pronunciation scores. We used this as a baseline pipeline and implemented methods to remove UNK and SPN phonemes in the GoP output by building three pipelines. The Online, Offline and Hybrid pipeline which returns the scores but also can prevent unknown words in the final output. The Online method is based per utterance, Offline method pre-incorporates a set of OOV words for a given data set and the Hybrid method combines the above two ideas to expand the lexicon as well work per utterance. We further provide utilities such as the Phoneme to posterior mappings, GoP scores of each utterance as a vector, and Word boundaries used in the GoP pipeline for use in future research.