 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSegment-level Tree Search for Long Meeting Document Summarization
Jun 07, 2026Meeting documents are challenging to summarize due to their length and complex conversational structure. Existing approaches typically adopt multi-stage pipelines that extract information prior to summarization; however, these approaches often suffer from cumulative error propagation without intermediate validation, a limitation further amplified by short and low-quality reference summaries. We propose segment-level summarization via Monte Carlo Tree Search (S3), a training-free framework that constructs a final summary by composing segment-level summary candidates. S3 partitions a long document into segments and generates multiple summary candidates per segment, forming nodes of a search tree. The best-scoring combination is selected via self-reward-guided tree search and refined into the final output. Despite using a 7B model, S3 achieves performance comparable to larger 72B models while producing length-appropriate summaries.
Learning When to Translate for Multilingual Reasoning
Jun 01, 2026Reasoning language models (RLMs) achieve strong performance on complex reasoning tasks, but still exhibit substantial multilingual reasoning gaps, largely due to language-understanding failures in non-English inputs. English translation can mitigate these failures by expressing non-English inputs in a form that RLMs can more reliably interpret, yet translating every input is unnecessary when the model can reason reliably from the original query. To address this challenge, we propose Luar, a Language Understanding Boundary-aware Reinforcement Learning framework that trains RLMs to selectively invoke translation when direct understanding is unreliable. Luar trains the model to choose between solving the original input directly and reasoning over its English translation, encouraging translation only when translator-augmented reasoning is expected to substantially outperform direct reasoning. Across multilingual reasoning benchmarks, Luar outperforms standard GRPO and other training-based baselines, with particularly large gains on low-resource languages. Further analysis shows that Luar avoids unnecessary translation in cases where direct reasoning is sufficient, while extending its translator-call behavior to unseen low-resource languages. Together, our work suggests a selective approach to multilingual reasoning: RLMs can learn to invoke translation only when their direct understanding is unreliable. The project will be made publicly available at https://github.com/deokhk/LUAR
Understanding LLM Behavior in Multi-Target Cross-Lingual Summarization
May 31, 2026Multi-target cross-lingual text summarization (MTXLS), which summarizes a source document into multiple target languages, is increasingly important as users consume content in diverse languages, but remains underexplored. To address this gap, we introduce multi-target cross-lingual element-aware (MEA), a new MTXLS benchmark covering 24 target languages. We benchmark end-to-end and pipeline approaches across various LLMs and show that MTXLS performance still substantially lags behind English monolingual summarization. To better understand MTXLS in LLMs, we propose a layer-wise analysis framework for investigating how LLMs internally perform MTXLS. Our analyses suggest that translation and summarization behaviors emerge jointly within later layers rather than as distinctly decomposed stages. Most task-relevant processing occurs within these layers, and errors also tend to arise at similar depths. Motivated by these findings, we introduce an inference-time activation steering method that leverages hidden representations from English summarization to guide MTXLS generation. Experiments show that our method consistently improves MTXLS quality across target languages.
A Multi-Agent Framework for Feature-Constrained Difficulty Control in Reading Comprehension Item Generation
May 19, 2026Recent studies in difficulty-controlled reading comprehension item generation have leveraged large language models (LLMs) to produce items by adjusting difficulty-related features. However, existing methods typically rely on a single-agent prompting approach, which often fails to consistently satisfy specified feature constraints, resulting in items that deviate from the target difficulty level. To address this limitation, we introduce MAFIG, a Multi-agent Framework for Feature-constrained Item Generation, where multiple LLM agents and feature-specific evaluators collaborate to generate and iteratively revise items based on intended constraints. Furthermore, to verify the efficacy of MAFIG in difficulty control, we propose a method for constructing a sequence of feature constraint sets that yield items with monotonically increasing difficulty. Experimental results demonstrate that MAFIG generates items that adhere to target constraints at a significantly higher rate than baselines, achieving robust difficulty control through the difficulty-calibrated constraint sequence.
Behavior-Aware Item Modeling via Dynamic Procedural Solution Representations for Knowledge Tracing
Apr 09, 2026Knowledge Tracing (KT) aims to predict learners' future performance from past interactions. While recent KT approaches have improved via learning item representations aligned with Knowledge Components, they overlook the procedural dynamics of problem solving. We propose Behavior-Aware Item Modeling (BAIM), a framework that enriches item representations by integrating dynamic procedural solution information. BAIM leverages a reasoning language model to decompose each item's solution into four problem-solving stages (i.e., understand, plan, carry out, and look back), pedagogically grounded in Polya's framework. Specifically, it derives stage-level representations from per-stage embedding trajectories, capturing latent signals beyond surface features. To reflect learner heterogeneity, BAIM adaptively routes these stage-wise representations, introducing a context-conditioned mechanism within a KT backbone, allowing different procedural stages to be emphasized for different learners. Experiments on XES3G5M and NIPS34 show that BAIM consistently outperforms strong pretraining-based baselines, achieving particularly large gains under repeated learner interactions.
PSY-STEP: Structuring Therapeutic Targets and Action Sequences for Proactive Counseling Dialogue Systems
Apr 06, 2026Cognitive Behavioral Therapy (CBT) aims to identify and restructure automatic negative thoughts pertaining to involuntary interpretations of events, yet existing counseling agents struggle to identify and address them in dialogue settings. To bridge this gap, we introduce STEP, a dataset that models CBT counseling by explicitly reflecting automatic thoughts alongside dynamic, action-level counseling sequences. Using this dataset, we train STEPPER, a counseling agent that proactively elicits automatic thoughts and executes cognitively grounded interventions. To further enhance both decision accuracy and empathic responsiveness, we refine STEPPER through preference learning based on simulated, synthesized counseling sessions. Extensive CBT-aligned evaluations show that STEPPER delivers more clinically grounded, coherent, and personalized counseling compared to other strong baseline models, and achieves higher counselor competence without inducing emotional disruption.
Mixture-of-Experts with Intermediate CTC Supervision for Accented Speech Recognition
Feb 02, 2026Accented speech remains a persistent challenge for automatic speech recognition (ASR), as most models are trained on data dominated by a few high-resource English varieties, leading to substantial performance degradation for other accents. Accent-agnostic approaches improve robustness yet struggle with heavily accented or unseen varieties, while accent-specific methods rely on limited and often noisy labels. We introduce Moe-Ctc, a Mixture-of-Experts architecture with intermediate CTC supervision that jointly promotes expert specialization and generalization. During training, accent-aware routing encourages experts to capture accent-specific patterns, which gradually transitions to label-free routing for inference. Each expert is equipped with its own CTC head to align routing with transcription quality, and a routing-augmented loss further stabilizes optimization. Experiments on the Mcv-Accent benchmark demonstrate consistent gains across both seen and unseen accents in low- and high-resource conditions, achieving up to 29.3% relative WER reduction over strong FastConformer baselines.
Merging Triggers, Breaking Backdoors: Defensive Poisoning for Instruction-Tuned Language Models
Jan 07, 2026Large Language Models (LLMs) have greatly advanced Natural Language Processing (NLP), particularly through instruction tuning, which enables broad task generalization without additional fine-tuning. However, their reliance on large-scale datasets-often collected from human or web sources-makes them vulnerable to backdoor attacks, where adversaries poison a small subset of data to implant hidden behaviors. Despite this growing risk, defenses for instruction-tuned models remain underexplored. We propose MB-Defense (Merging & Breaking Defense Framework), a novel training pipeline that immunizes instruction-tuned LLMs against diverse backdoor threats. MB-Defense comprises two stages: (i) defensive poisoning, which merges attacker and defensive triggers into a unified backdoor representation, and (ii) weight recovery, which breaks this representation through additional training to restore clean behavior. Extensive experiments across multiple LLMs show that MB-Defense substantially lowers attack success rates while preserving instruction-following ability. Our method offers a generalizable and data-efficient defense strategy, improving the robustness of instruction-tuned LLMs against unseen backdoor attacks.
Why Do Multilingual Reasoning Gaps Emerge in Reasoning Language Models?
Oct 31, 2025Reasoning language models (RLMs) achieve strong performance on complex reasoning tasks, yet they still suffer from a multilingual reasoning gap, performing better in high-resource languages than in low-resource ones. While recent efforts have reduced this gap, its underlying causes remain largely unexplored. In this paper, we address this by showing that the multilingual reasoning gap largely stems from failures in language understanding-the model's inability to represent the multilingual input meaning into the dominant language (i.e., English) within its reasoning trace. This motivates us to examine whether understanding failures can be detected, as this ability could help mitigate the multilingual reasoning gap. To this end, we evaluate a range of detection methods and find that understanding failures can indeed be identified, with supervised approaches performing best. Building on this, we propose Selective Translation, a simple yet effective strategy that translates the multilingual input into English only when an understanding failure is detected. Experimental results show that Selective Translation bridges the multilingual reasoning gap, achieving near full-translation performance while using translation for only about 20% of inputs. Together, our work demonstrates that understanding failures are the primary cause of the multilingual reasoning gap and can be detected and selectively mitigated, providing key insight into its origin and a promising path toward more equitable multilingual reasoning. Our code and data are publicly available at https://github.com/deokhk/RLM_analysis.
DeRAGEC: Denoising Named Entity Candidates with Synthetic Rationale for ASR Error Correction
Jun 09, 2025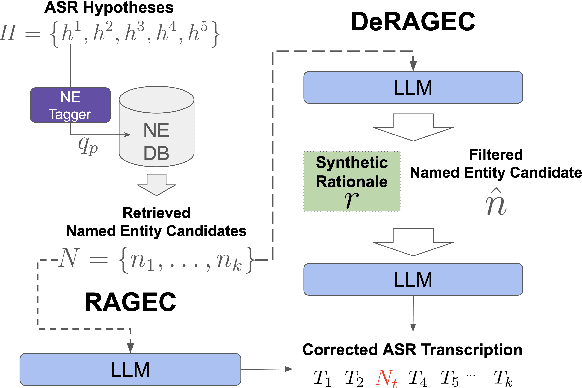
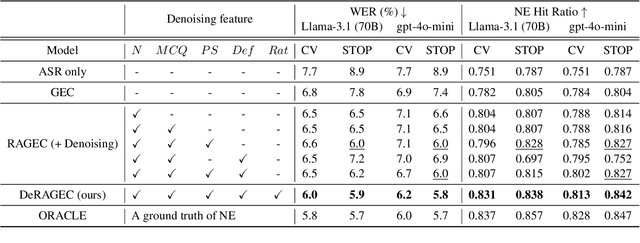
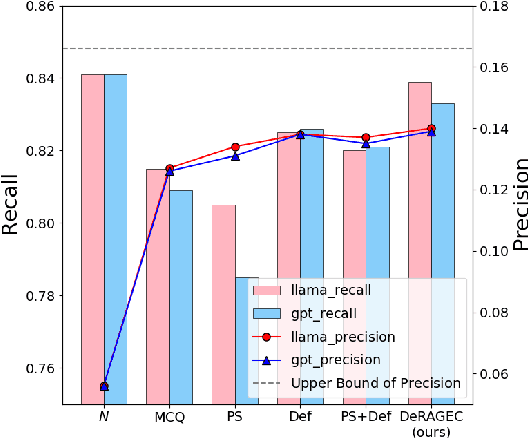
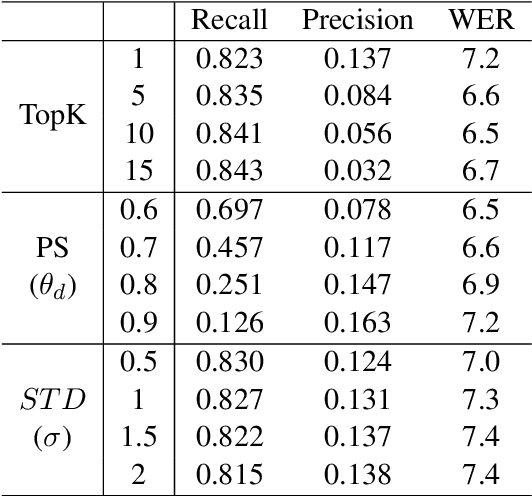
We present DeRAGEC, a method for improving Named Entity (NE) correction in Automatic Speech Recognition (ASR) systems. By extending the Retrieval-Augmented Generative Error Correction (RAGEC) framework, DeRAGEC employs synthetic denoising rationales to filter out noisy NE candidates before correction. By leveraging phonetic similarity and augmented definitions, it refines noisy retrieved NEs using in-context learning, requiring no additional training. Experimental results on CommonVoice and STOP datasets show significant improvements in Word Error Rate (WER) and NE hit ratio, outperforming baseline ASR and RAGEC methods. Specifically, we achieved a 28% relative reduction in WER compared to ASR without postprocessing. Our source code is publicly available at: https://github.com/solee0022/deragec