 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVeri Wild
Papers and Code
CLIP-SENet: CLIP-based Semantic Enhancement Network for Vehicle Re-identification
Feb 24, 2025Vehicle re-identification (Re-ID) is a crucial task in intelligent transportation systems (ITS), aimed at retrieving and matching the same vehicle across different surveillance cameras. Numerous studies have explored methods to enhance vehicle Re-ID by focusing on semantic enhancement. However, these methods often rely on additional annotated information to enable models to extract effective semantic features, which brings many limitations. In this work, we propose a CLIP-based Semantic Enhancement Network (CLIP-SENet), an end-to-end framework designed to autonomously extract and refine vehicle semantic attributes, facilitating the generation of more robust semantic feature representations. Inspired by zero-shot solutions for downstream tasks presented by large-scale vision-language models, we leverage the powerful cross-modal descriptive capabilities of the CLIP image encoder to initially extract general semantic information. Instead of using a text encoder for semantic alignment, we design an adaptive fine-grained enhancement module (AFEM) to adaptively enhance this general semantic information at a fine-grained level to obtain robust semantic feature representations. These features are then fused with common Re-ID appearance features to further refine the distinctions between vehicles. Our comprehensive evaluation on three benchmark datasets demonstrates the effectiveness of CLIP-SENet. Our approach achieves new state-of-the-art performance, with 92.9% mAP and 98.7% Rank-1 on VeRi-776 dataset, 90.4% Rank-1 and 98.7% Rank-5 on VehicleID dataset, and 89.1% mAP and 97.9% Rank-1 on the more challenging VeRi-Wild dataset.
Strength in Diversity: Multi-Branch Representation Learning for Vehicle Re-Identification
Oct 02, 2023



This paper presents an efficient and lightweight multi-branch deep architecture to improve vehicle re-identification (V-ReID). While most V-ReID work uses a combination of complex multi-branch architectures to extract robust and diversified embeddings towards re-identification, we advocate that simple and lightweight architectures can be designed to fulfill the Re-ID task without compromising performance. We propose a combination of Grouped-convolution and Loss-Branch-Split strategies to design a multi-branch architecture that improve feature diversity and feature discriminability. We combine a ResNet50 global branch architecture with a BotNet self-attention branch architecture, both designed within a Loss-Branch-Split (LBS) strategy. We argue that specialized loss-branch-splitting helps to improve re-identification tasks by generating specialized re-identification features. A lightweight solution using grouped convolution is also proposed to mimic the learning of loss-splitting into multiple embeddings while significantly reducing the model size. In addition, we designed an improved solution to leverage additional metadata, such as camera ID and pose information, that uses 97% less parameters, further improving re-identification performance. In comparison to state-of-the-art (SoTA) methods, our approach outperforms competing solutions in Veri-776 by achieving 85.6% mAP and 97.7% CMC1 and obtains competitive results in Veri-Wild with 88.1% mAP and 96.3% CMC1. Overall, our work provides important insights into improving vehicle re-identification and presents a strong basis for other retrieval tasks. Our code is available at the https://github.com/videturfortuna/vehicle_reid_itsc2023.
Large-scale Fully-Unsupervised Re-Identification
Jul 26, 2023



Fully-unsupervised Person and Vehicle Re-Identification have received increasing attention due to their broad applicability in surveillance, forensics, event understanding, and smart cities, without requiring any manual annotation. However, most of the prior art has been evaluated in datasets that have just a couple thousand samples. Such small-data setups often allow the use of costly techniques in time and memory footprints, such as Re-Ranking, to improve clustering results. Moreover, some previous work even pre-selects the best clustering hyper-parameters for each dataset, which is unrealistic in a large-scale fully-unsupervised scenario. In this context, this work tackles a more realistic scenario and proposes two strategies to learn from large-scale unlabeled data. The first strategy performs a local neighborhood sampling to reduce the dataset size in each iteration without violating neighborhood relationships. A second strategy leverages a novel Re-Ranking technique, which has a lower time upper bound complexity and reduces the memory complexity from O(n^2) to O(kn) with k << n. To avoid the pre-selection of specific hyper-parameter values for the clustering algorithm, we also present a novel scheduling algorithm that adjusts the density parameter during training, to leverage the diversity of samples and keep the learning robust to noisy labeling. Finally, due to the complementary knowledge learned by different models, we also introduce a co-training strategy that relies upon the permutation of predicted pseudo-labels, among the backbones, with no need for any hyper-parameters or weighting optimization. The proposed methodology outperforms the state-of-the-art methods in well-known benchmarks and in the challenging large-scale Veri-Wild dataset, with a faster and memory-efficient Re-Ranking strategy, and a large-scale, noisy-robust, and ensemble-based learning approach.
Negative Samples are at Large: Leveraging Hard-distance Elastic Loss for Re-identification
Jul 20, 2022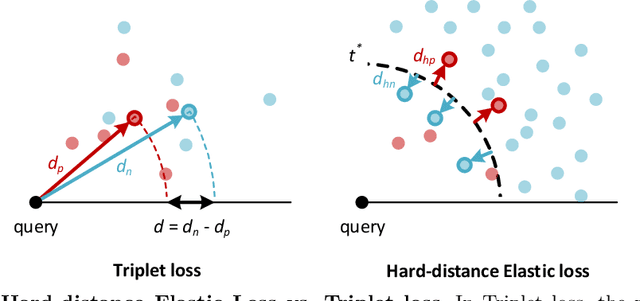
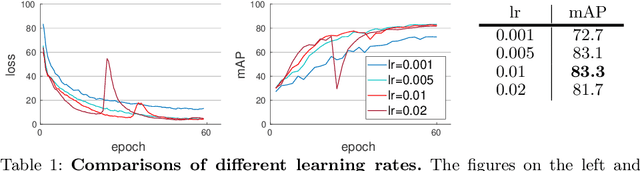
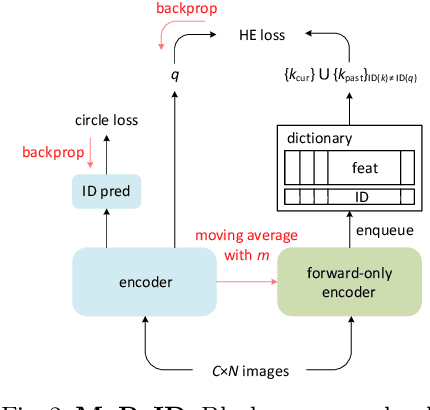
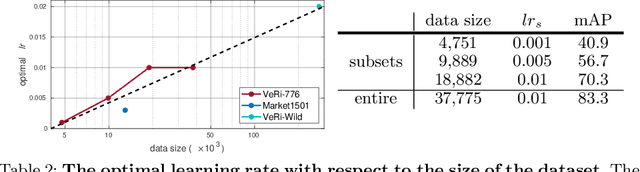
We present a Momentum Re-identification (MoReID) framework that can leverage a very large number of negative samples in training for general re-identification task. The design of this framework is inspired by Momentum Contrast (MoCo), which uses a dictionary to store current and past batches to build a large set of encoded samples. As we find it less effective to use past positive samples which may be highly inconsistent to the encoded feature property formed with the current positive samples, MoReID is designed to use only a large number of negative samples stored in the dictionary. However, if we train the model using the widely used Triplet loss that uses only one sample to represent a set of positive/negative samples, it is hard to effectively leverage the enlarged set of negative samples acquired by the MoReID framework. To maximize the advantage of using the scaled-up negative sample set, we newly introduce Hard-distance Elastic loss (HE loss), which is capable of using more than one hard sample to represent a large number of samples. Our experiments demonstrate that a large number of negative samples provided by MoReID framework can be utilized at full capacity only with the HE loss, achieving the state-of-the-art accuracy on three re-ID benchmarks, VeRi-776, Market-1501, and VeRi-Wild.
Heterogeneous Relational Complement for Vehicle Re-identification
Sep 16, 2021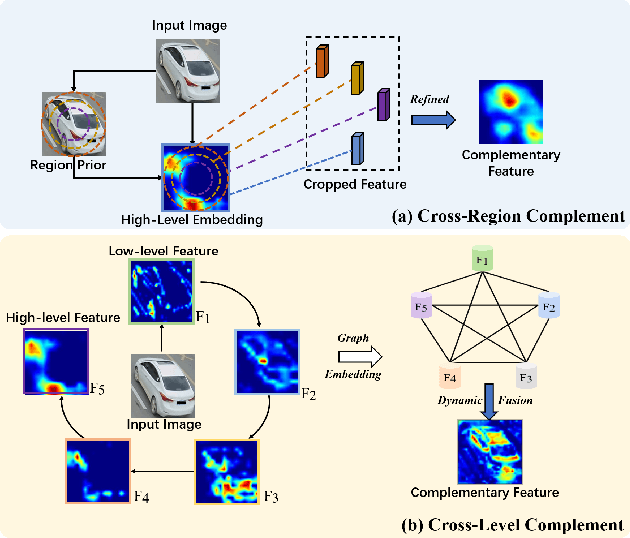
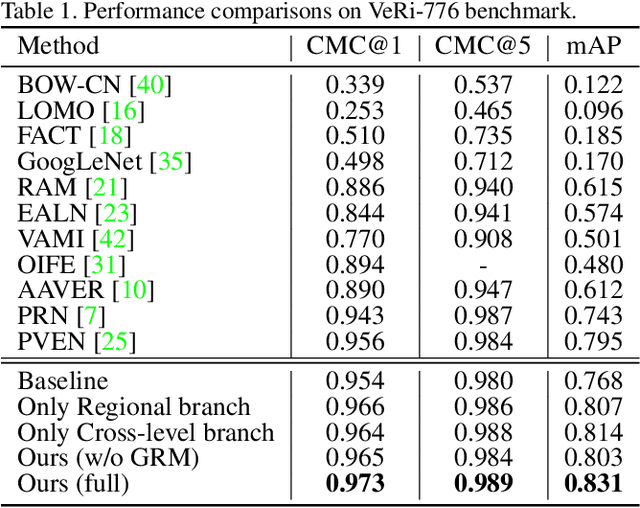
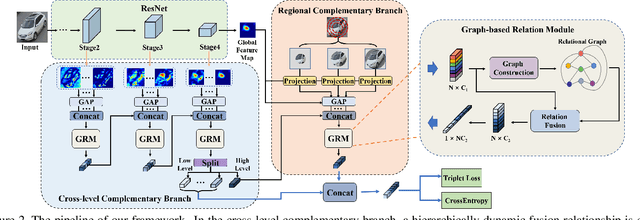
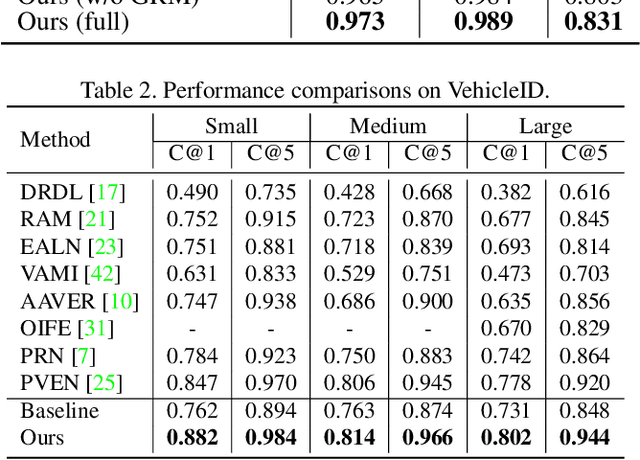
The crucial problem in vehicle re-identification is to find the same vehicle identity when reviewing this object from cross-view cameras, which sets a higher demand for learning viewpoint-invariant representations. In this paper, we propose to solve this problem from two aspects: constructing robust feature representations and proposing camera-sensitive evaluations. We first propose a novel Heterogeneous Relational Complement Network (HRCN) by incorporating region-specific features and cross-level features as complements for the original high-level output. Considering the distributional differences and semantic misalignment, we propose graph-based relation modules to embed these heterogeneous features into one unified high-dimensional space. On the other hand, considering the deficiencies of cross-camera evaluations in existing measures (i.e., CMC and AP), we then propose a Cross-camera Generalization Measure (CGM) to improve the evaluations by introducing position-sensitivity and cross-camera generalization penalties. We further construct a new benchmark of existing models with our proposed CGM and experimental results reveal that our proposed HRCN model achieves new state-of-the-art in VeRi-776, VehicleID, and VERI-Wild.
Multi-Attention-Based Soft Partition Network for Vehicle Re-Identification
Apr 21, 2021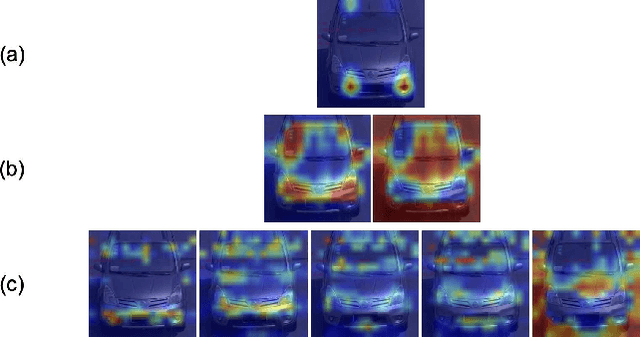
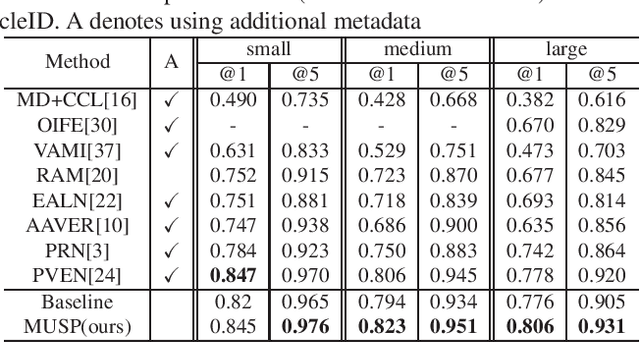
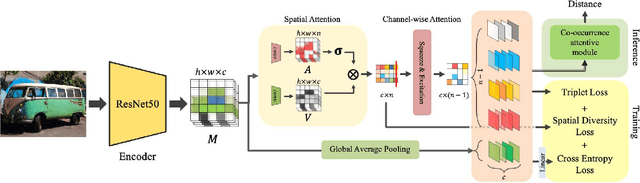
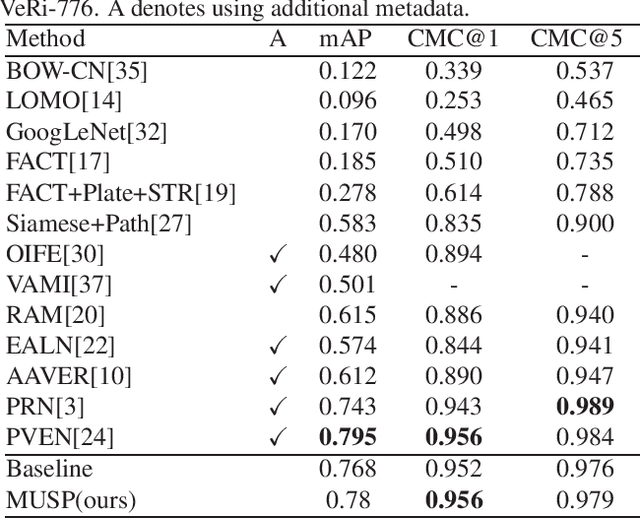
Vehicle re-identification (Re-ID) distinguishes between the same vehicle and other vehicles in images. It is challenging due to significant intra-instance differences between identical vehicles from different views and subtle inter-instance differences of similar vehicles. Researchers have tried to address this problem by extracting features robust to variations of viewpoints and environments. More recently, they tried to improve performance by using additional metadata such as key points, orientation, and temporal information. Although these attempts have been relatively successful, they all require expensive annotations. Therefore, this paper proposes a novel deep neural network called a multi-attention-based soft partition (MUSP) network to solve this problem. This network does not use metadata and only uses multiple soft attentions to identify a specific vehicle area. This function was performed by metadata in previous studies. Experiments verified that MUSP achieved state-of-the-art (SOTA) performance for the VehicleID dataset without any additional annotations and was comparable to VeRi-776 and VERI-Wild.
Moving Towards Centers: Re-ranking with Attention and Memory for Re-identification
May 04, 2021
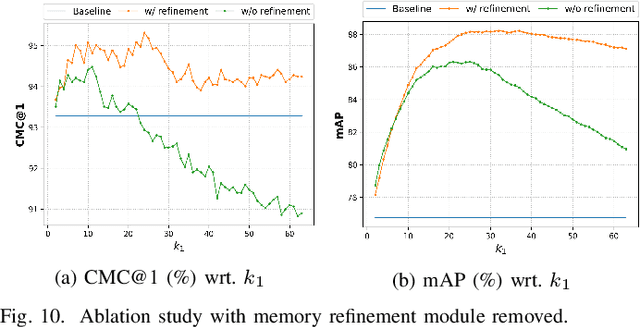
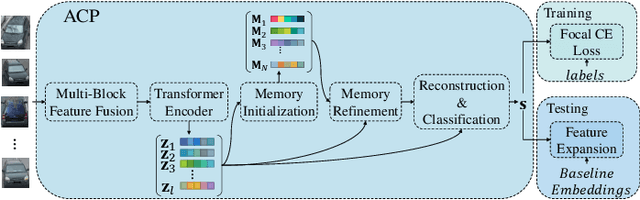
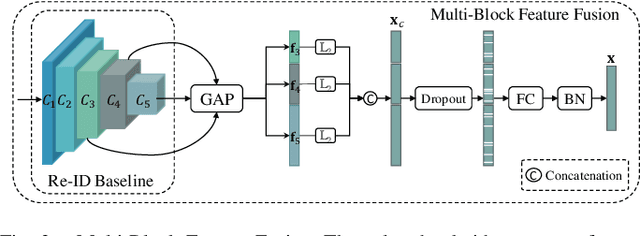
Re-ranking utilizes contextual information to optimize the initial ranking list of person or vehicle re-identification (re-ID), which boosts the retrieval performance at post-processing steps. This paper proposes a re-ranking network to predict the correlations between the probe and top-ranked neighbor samples. Specifically, all the feature embeddings of query and gallery images are expanded and enhanced by a linear combination of their neighbors, with the correlation prediction serves as discriminative combination weights. The combination process is equivalent to moving independent embeddings toward the identity centers, improving cluster compactness. For correlation prediction, we first aggregate the contextual information for probe's k-nearest neighbors via the Transformer encoder. Then, we distill and refine the probe-related features into the Contextual Memory cell via attention mechanism. Like humans that retrieve images by not only considering probe images but also memorizing the retrieved ones, the Contextual Memory produces multi-view descriptions for each instance. Finally, the neighbors are reconstructed with features fetched from the Contextual Memory, and a binary classifier predicts their correlations with the probe. Experiments on six widely-used person and vehicle re-ID benchmarks demonstrate the effectiveness of the proposed method. Especially, our method surpasses the state-of-the-art re-ranking approaches on large-scale datasets by a significant margin, i.e., with an average 3.08% CMC@1 and 7.46% mAP improvements on VERI-Wild, MSMT17, and VehicleID datasets.
Viewpoint-aware Progressive Clustering for Unsupervised Vehicle Re-identification
Nov 18, 2020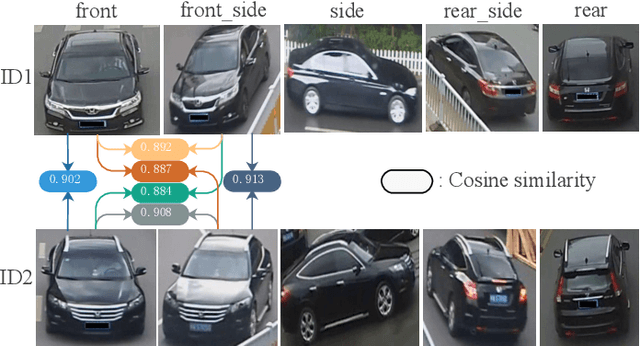
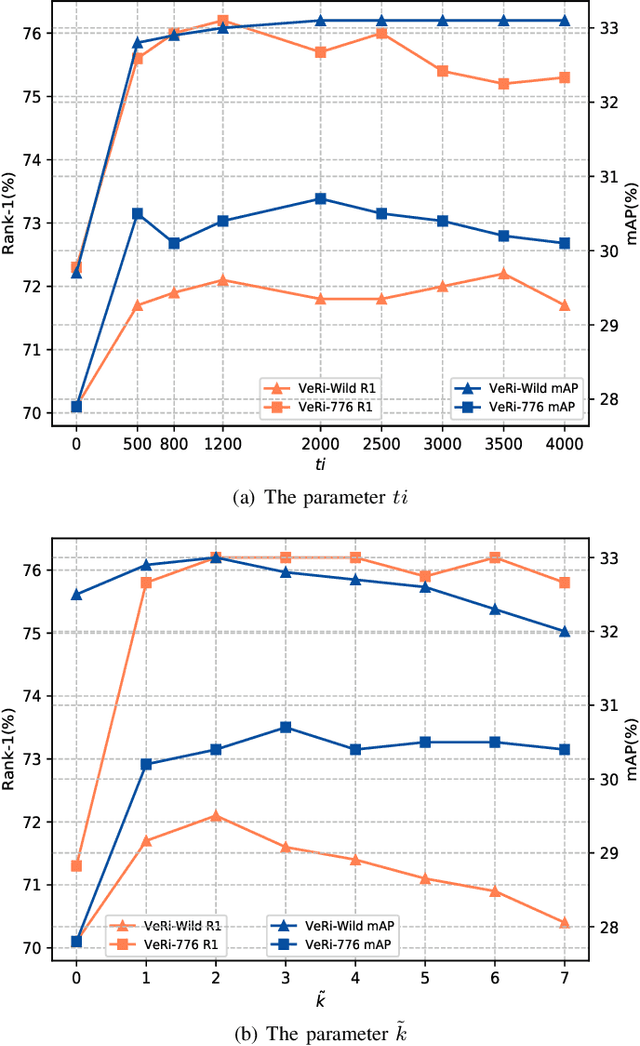
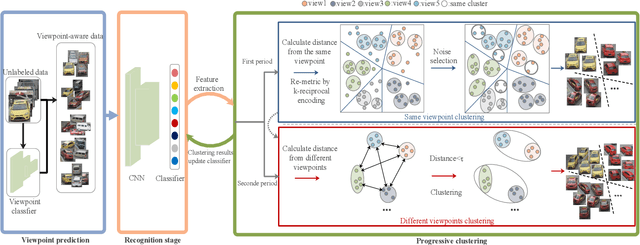
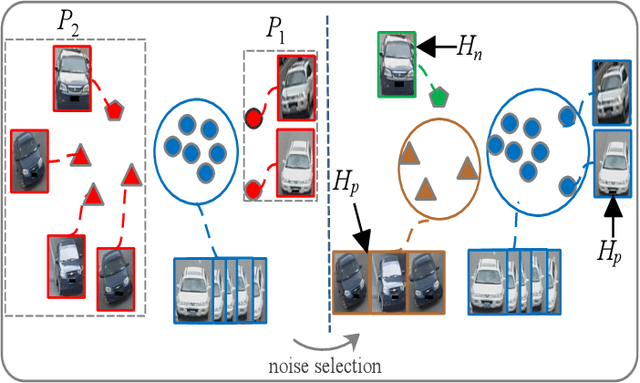
Vehicle re-identification (Re-ID) is an active task due to its importance in large-scale intelligent monitoring in smart cities. Despite the rapid progress in recent years, most existing methods handle vehicle Re-ID task in a supervised manner, which is both time and labor-consuming and limits their application to real-life scenarios. Recently, unsupervised person Re-ID methods achieve impressive performance by exploring domain adaption or clustering-based techniques. However, one cannot directly generalize these methods to vehicle Re-ID since vehicle images present huge appearance variations in different viewpoints. To handle this problem, we propose a novel viewpoint-aware clustering algorithm for unsupervised vehicle Re-ID. In particular, we first divide the entire feature space into different subspaces according to the predicted viewpoints and then perform a progressive clustering to mine the accurate relationship among samples. Comprehensive experiments against the state-of-the-art methods on two multi-viewpoint benchmark datasets VeRi and VeRi-Wild validate the promising performance of the proposed method in both with and without domain adaption scenarios while handling unsupervised vehicle Re-ID.
Exploring Spatial Significance via Hybrid Pyramidal Graph Network for Vehicle Re-identification
Jun 05, 2020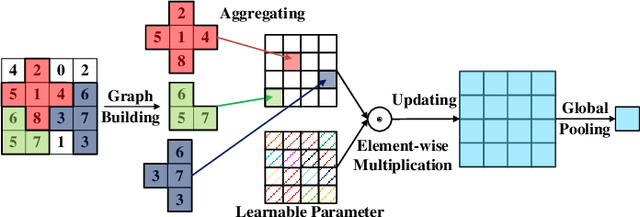
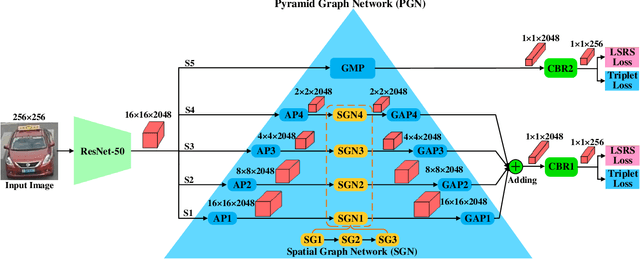
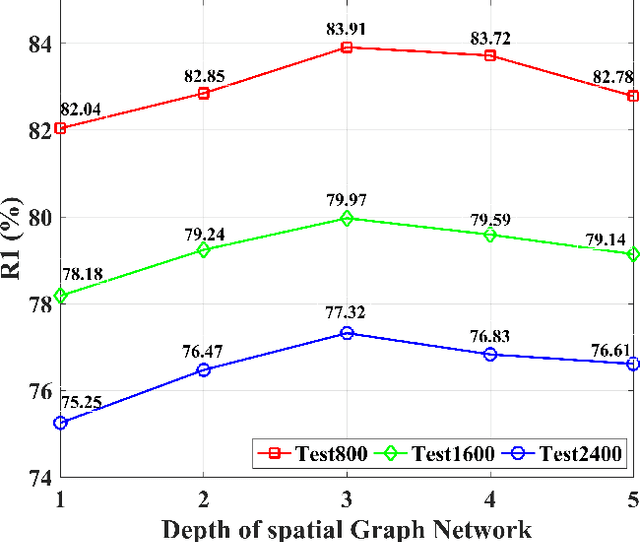
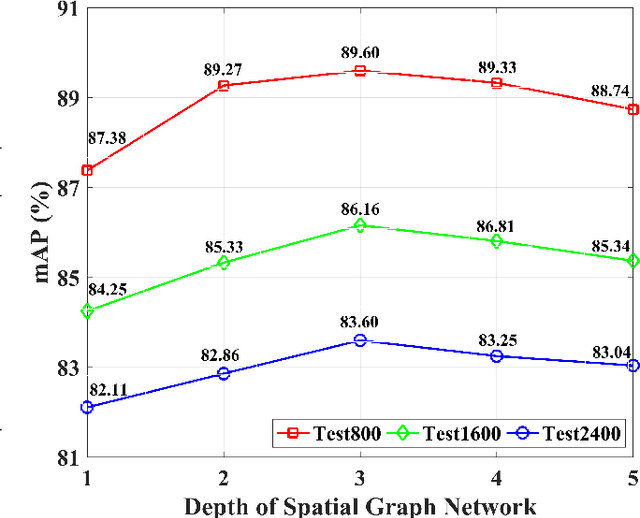
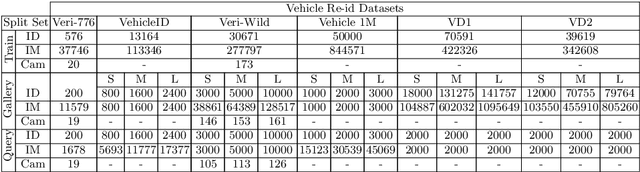
Existing vehicle re-identification methods commonly use spatial pooling operations to aggregate feature maps extracted via off-the-shelf backbone networks. They ignore exploring the spatial significance of feature maps, eventually degrading the vehicle re-identification performance. In this paper, firstly, an innovative spatial graph network (SGN) is proposed to elaborately explore the spatial significance of feature maps. The SGN stacks multiple spatial graphs (SGs). Each SG assigns feature map's elements as nodes and utilizes spatial neighborhood relationships to determine edges among nodes. During the SGN's propagation, each node and its spatial neighbors on an SG are aggregated to the next SG. On the next SG, each aggregated node is re-weighted with a learnable parameter to find the significance at the corresponding location. Secondly, a novel pyramidal graph network (PGN) is designed to comprehensively explore the spatial significance of feature maps at multiple scales. The PGN organizes multiple SGNs in a pyramidal manner and makes each SGN handles feature maps of a specific scale. Finally, a hybrid pyramidal graph network (HPGN) is developed by embedding the PGN behind a ResNet-50 based backbone network. Extensive experiments on three large scale vehicle databases (i.e., VeRi776, VehicleID, and VeRi-Wild) demonstrate that the proposed HPGN is superior to state-of-the-art vehicle re-identification approaches.
The Devil is in the Details: Self-Supervised Attention for Vehicle Re-Identification
Apr 15, 2020
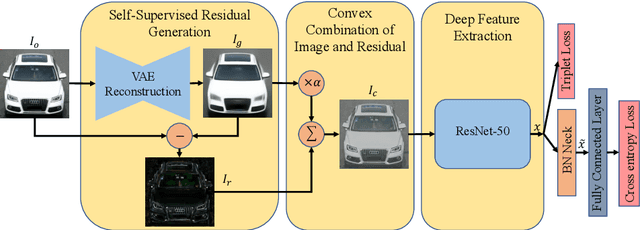

In recent years, the research community has approached the problem of vehicle re-identification (re-id) with attention-based models, specifically focusing on regions of a vehicle containing discriminative information. These re-id methods rely on expensive key-point labels, part annotations, and additional attributes including vehicle make, model, and color. Given the large number of vehicle re-id datasets with various levels of annotations, strongly-supervised methods are unable to scale across different domains. In this paper, we present Self-supervised Attention for Vehicle Re-identification (SAVER), a novel approach to effectively learn vehicle-specific discriminative features. Through extensive experimentation, we show that SAVER improves upon the state-of-the-art on challenging vehicle re-id benchmarks including Veri-776, VehicleID, Vehicle-1M and Veri-Wild. SAVER demonstrates how proper regularization techniques significantly constrain the vehicle re-id task and help generate robust deep features.