 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimplequestions
Papers and Code
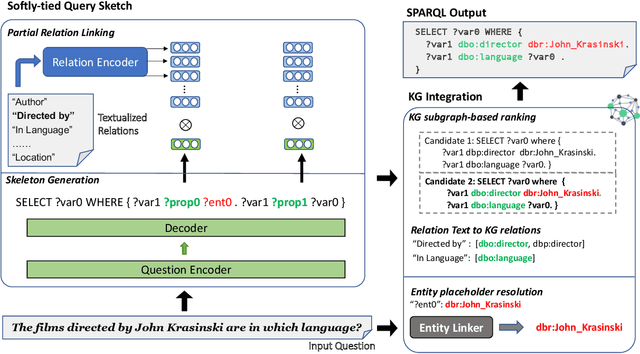
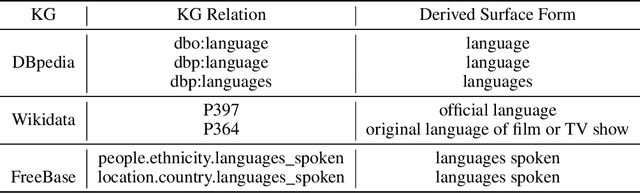
SPARKLE: Enhancing SPARQL Generation with Direct KG Integration in Decoding
Jun 29, 2024



Existing KBQA methods have traditionally relied on multi-stage methodologies, involving tasks such as entity linking, subgraph retrieval and query structure generation. However, multi-stage approaches are dependent on the accuracy of preceding steps, leading to cascading errors and increased inference time. Although a few studies have explored the use of end-to-end models, they often suffer from lower accuracy and generate inoperative query that is not supported by the underlying data. Furthermore, most prior approaches are limited to the static training data, potentially overlooking the evolving nature of knowledge bases over time. To address these challenges, we present a novel end-to-end natural language to SPARQL framework, SPARKLE. Notably SPARKLE leverages the structure of knowledge base directly during the decoding, effectively integrating knowledge into the query generation. Our study reveals that simply referencing knowledge base during inference significantly reduces the occurrence of inexecutable query generations. SPARKLE achieves new state-of-the-art results on SimpleQuestions-Wiki and highest F1 score on LCQuAD 1.0 (among models not using gold entities), while getting slightly lower result on the WebQSP dataset. Finally, we demonstrate SPARKLE's fast inference speed and its ability to adapt when the knowledge base differs between the training and inference stages.
GETT-QA: Graph Embedding based T2T Transformer for Knowledge Graph Question Answering
Mar 28, 2023



In this work, we present an end-to-end Knowledge Graph Question Answering (KGQA) system named GETT-QA. GETT-QA uses T5, a popular text-to-text pre-trained language model. The model takes a question in natural language as input and produces a simpler form of the intended SPARQL query. In the simpler form, the model does not directly produce entity and relation IDs. Instead, it produces corresponding entity and relation labels. The labels are grounded to KG entity and relation IDs in a subsequent step. To further improve the results, we instruct the model to produce a truncated version of the KG embedding for each entity. The truncated KG embedding enables a finer search for disambiguation purposes. We find that T5 is able to learn the truncated KG embeddings without any change of loss function, improving KGQA performance. As a result, we report strong results for LC-QuAD 2.0 and SimpleQuestions-Wikidata datasets on end-to-end KGQA over Wikidata.
An Empirical Study of Pre-trained Language Models in Simple Knowledge Graph Question Answering
Mar 18, 2023Large-scale pre-trained language models (PLMs) such as BERT have recently achieved great success and become a milestone in natural language processing (NLP). It is now the consensus of the NLP community to adopt PLMs as the backbone for downstream tasks. In recent works on knowledge graph question answering (KGQA), BERT or its variants have become necessary in their KGQA models. However, there is still a lack of comprehensive research and comparison of the performance of different PLMs in KGQA. To this end, we summarize two basic KGQA frameworks based on PLMs without additional neural network modules to compare the performance of nine PLMs in terms of accuracy and efficiency. In addition, we present three benchmarks for larger-scale KGs based on the popular SimpleQuestions benchmark to investigate the scalability of PLMs. We carefully analyze the results of all PLMs-based KGQA basic frameworks on these benchmarks and two other popular datasets, WebQuestionSP and FreebaseQA, and find that knowledge distillation techniques and knowledge enhancement methods in PLMs are promising for KGQA. Furthermore, we test ChatGPT, which has drawn a great deal of attention in the NLP community, demonstrating its impressive capabilities and limitations in zero-shot KGQA. We have released the code and benchmarks to promote the use of PLMs on KGQA.
A Two-Stage Approach towards Generalization in Knowledge Base Question Answering
Nov 17, 2021
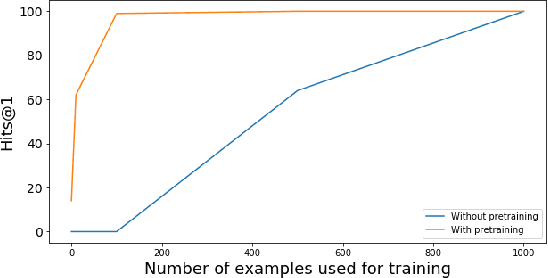
Most existing approaches for Knowledge Base Question Answering (KBQA) focus on a specific underlying knowledge base either because of inherent assumptions in the approach, or because evaluating it on a different knowledge base requires non-trivial changes. However, many popular knowledge bases share similarities in their underlying schemas that can be leveraged to facilitate generalization across knowledge bases. To achieve this generalization, we introduce a KBQA framework based on a 2-stage architecture that explicitly separates semantic parsing from the knowledge base interaction, facilitating transfer learning across datasets and knowledge graphs. We show that pretraining on datasets with a different underlying knowledge base can nevertheless provide significant performance gains and reduce sample complexity. Our approach achieves comparable or state-of-the-art performance for LC-QuAD (DBpedia), WebQSP (Freebase), SimpleQuestions (Wikidata) and MetaQA (Wikimovies-KG).
Incremental Knowledge Based Question Answering
Jan 18, 2021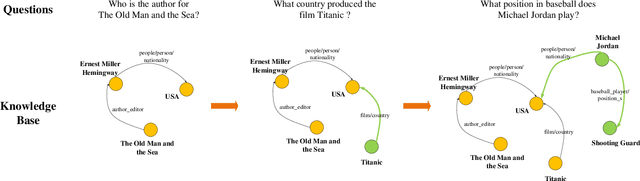
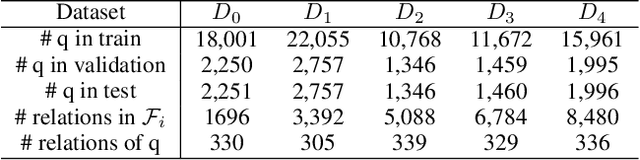

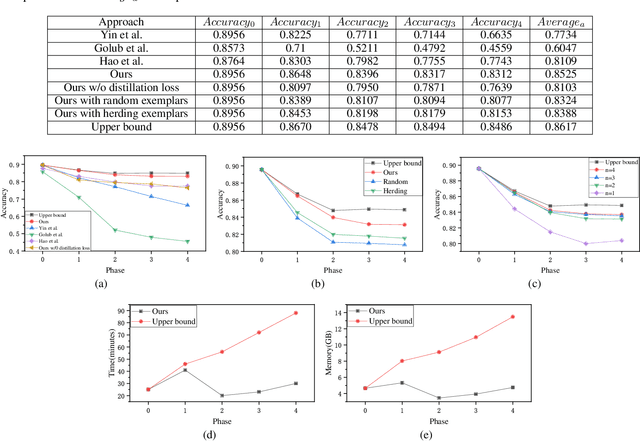
In the past years, Knowledge-Based Question Answering (KBQA), which aims to answer natural language questions using facts in a knowledge base, has been well developed. Existing approaches often assume a static knowledge base. However, the knowledge is evolving over time in the real world. If we directly apply a fine-tuning strategy on an evolving knowledge base, it will suffer from a serious catastrophic forgetting problem. In this paper, we propose a new incremental KBQA learning framework that can progressively expand learning capacity as humans do. Specifically, it comprises a margin-distilled loss and a collaborative exemplar selection method, to overcome the catastrophic forgetting problem by taking advantage of knowledge distillation. We reorganize the SimpleQuestion dataset to evaluate the proposed incremental learning solution to KBQA. The comprehensive experiments demonstrate its effectiveness and efficiency when working with the evolving knowledge base.
Knowledge-enriched, Type-constrained and Grammar-guided Question Generation over Knowledge Bases
Oct 23, 2020
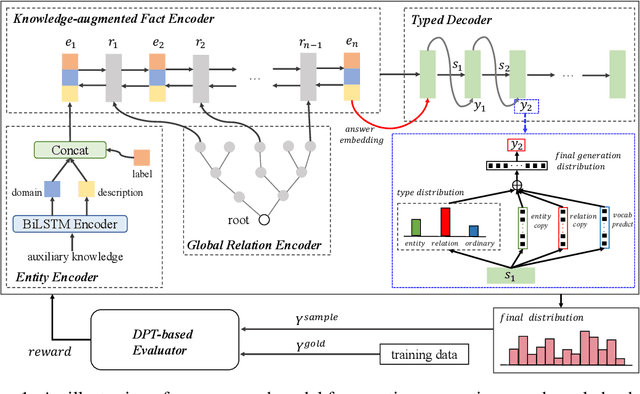
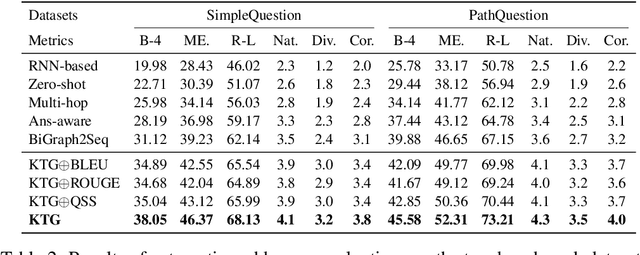
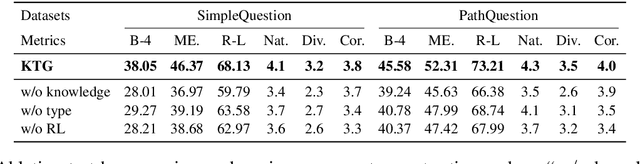
Question generation over knowledge bases (KBQG) aims at generating natural-language questions about a subgraph, i.e. a set of (connected) triples. Two main challenges still face the current crop of encoder-decoder-based methods, especially on small subgraphs: (1) low diversity and poor fluency due to the limited information contained in the subgraphs, and (2) semantic drift due to the decoder's oblivion of the semantics of the answer entity. We propose an innovative knowledge-enriched, type-constrained and grammar-guided KBQG model, named KTG, to addresses the above challenges. In our model, the encoder is equipped with auxiliary information from the KB, and the decoder is constrained with word types during QG. Specifically, entity domain and description, as well as relation hierarchy information are considered to construct question contexts, while a conditional copy mechanism is incorporated to modulate question semantics according to current word types. Besides, a novel reward function featuring grammatical similarity is designed to improve both generative richness and syntactic correctness via reinforcement learning. Extensive experiments show that our proposed model outperforms existing methods by a significant margin on two widely-used benchmark datasets SimpleQuestion and PathQuestion.
Neural Relation Prediction for Simple Question Answering over Knowledge Graph
Feb 18, 2020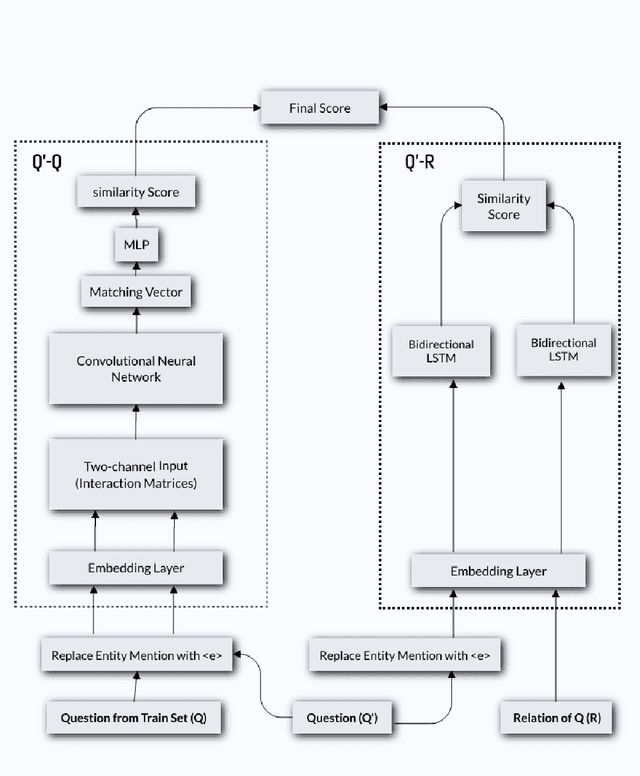
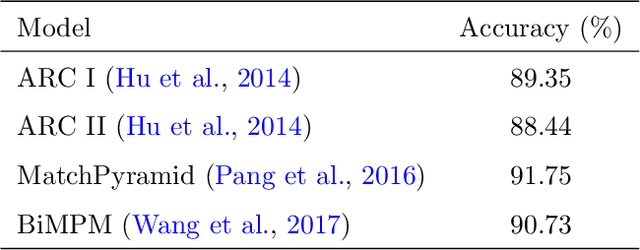


Relation extraction from simple questions aims to capture the relation of a factoid question with one underlying relation from a set of predefined ones ina knowledge base. Most recent methods take advantage of neural networks for matching a question with all relations in order to find the best relation that is expressed by that question. In this paper, we propose an instance-based method to find similar questions of a new question, in the sense of their relations, to predict its mentioned relation. The motivation roots in the fact that a relation can be expressed with different forms of question and these forms mostly share similar terms or concepts. Our experiments on the SimpleQuestions dataset show that the proposed model achieved better accuracy compared to the state-of-the-art relation extraction models.
Pretrained Transformers for Simple Question Answering over Knowledge Graphs
Jan 31, 2020
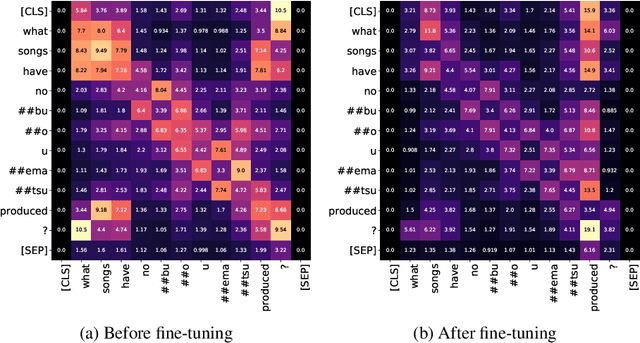

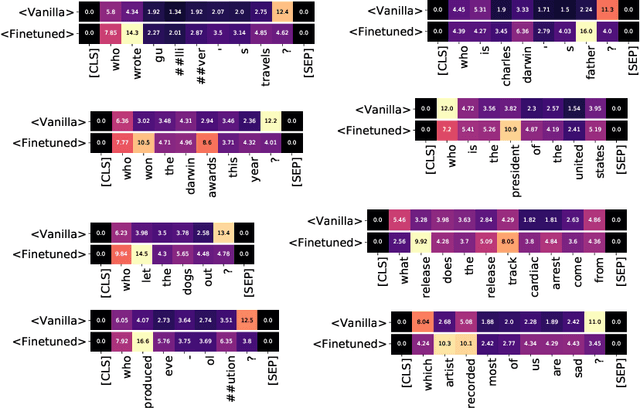
Answering simple questions over knowledge graphs is a well-studied problem in question answering. Previous approaches for this task built on recurrent and convolutional neural network based architectures that use pretrained word embeddings. It was recently shown that finetuning pretrained transformer networks (e.g. BERT) can outperform previous approaches on various natural language processing tasks. In this work, we investigate how well BERT performs on SimpleQuestions and provide an evaluation of both BERT and BiLSTM-based models in datasparse scenarios.
Learning to Answer Ambiguous Questions with Knowledge Graph
Dec 25, 2019
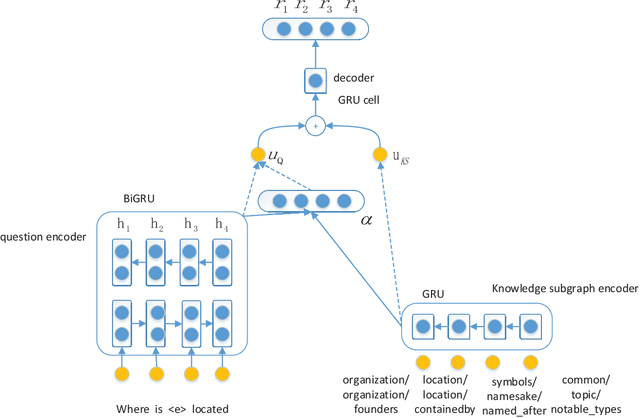

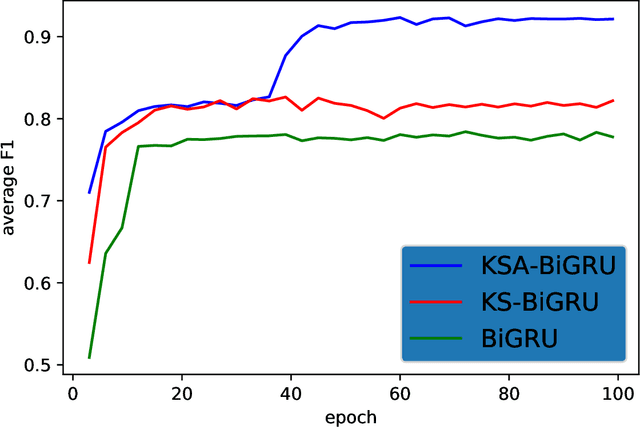
In the task of factoid question answering over knowledge base, many questions have more than one plausible interpretation. Previous works on SimpleQuestions assume only one interpretation as the ground truth for each question, so they lack the ability to answer ambiguous questions correctly. In this paper, we present a new way to utilize the dataset that takes into account the existence of ambiguous questions. Then we introduce a simple and effective model which combines local knowledge subgraph with attention mechanism. Our experimental results show that our approach achieves outstanding performance in this task.
Learning Representation Mapping for Relation Detection in Knowledge Base Question Answering
Jul 17, 2019
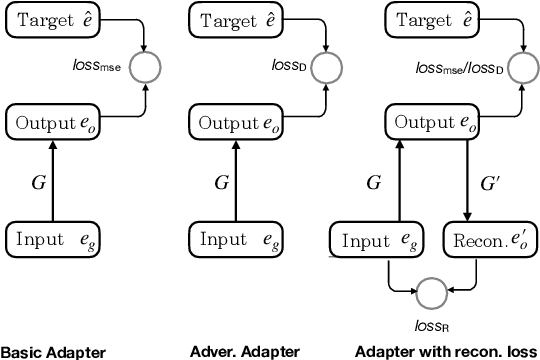
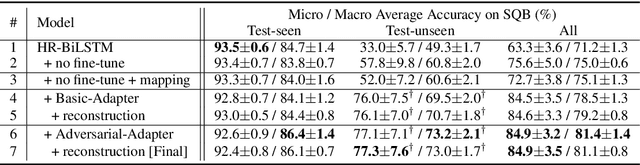
Relation detection is a core step in many natural language process applications including knowledge base question answering. Previous efforts show that single-fact questions could be answered with high accuracy. However, one critical problem is that current approaches only get high accuracy for questions whose relations have been seen in the training data. But for unseen relations, the performance will drop rapidly. The main reason for this problem is that the representations for unseen relations are missing. In this paper, we propose a simple mapping method, named representation adapter, to learn the representation mapping for both seen and unseen relations based on previously learned relation embedding. We employ the adversarial objective and the reconstruction objective to improve the mapping performance. We re-organize the popular SimpleQuestion dataset to reveal and evaluate the problem of detecting unseen relations. Experiments show that our method can greatly improve the performance of unseen relations while the performance for those seen part is kept comparable to the state-of-the-art. Our code and data are available at https://github.com/wudapeng268/KBQA-Adapter.