 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSfew
Papers and Code
Emotion Diffusion Classifier with Adaptive Margin Discrepancy Training for Facial Expression Recognition
Mar 31, 2026Facial Expression Recognition (FER) is essential for human-machine interaction, as it enables machines to interpret human emotions and internal states from facial affective behaviors. Although deep learning has significantly advanced FER performance, most existing deep-learning-based FER methods rely heavily on discriminative classifiers for fast predictions. These models tend to learn shortcuts and are vulnerable to even minor distribution shifts. To address this issue, we adopt a conditional generative diffusion model and introduce the Emotion Diffusion Classifier (EmoDC) for FER, which demonstrates enhanced adversarial robustness. However, retraining EmoDC using standard strategies fails to penalize incorrect categorical descriptions, leading to suboptimal recognition performance. To improve EmoDC, we propose margin-based discrepancy training, which encourages accurate predictions when conditioned on correct categorical descriptions and penalizes predictions conditioned on mismatched ones. This method enforces a minimum margin between noise-prediction errors for correct and incorrect categories, thereby enhancing the model's discriminative capability. Nevertheless, using a fixed margin fails to account for the varying difficulty of noise prediction across different images, limiting its effectiveness. To overcome this limitation, we propose Adaptive Margin Discrepancy Training (AMDiT), which dynamically adjusts the margin for each sample. Extensive experiments show that AMDiT significantly improves the accuracy of EmoDC over the Base model with standard denoising diffusion training on the RAF-DB basic subset, the RAF-DB compound subset, SFEW-2.0, and AffectNet, in 100-step evaluations. Additionally, EmoDC outperforms state-of-the-art discriminative classifiers in terms of robustness against noise and blur.
FER-YOLO-Mamba: Facial Expression Detection and Classification Based on Selective State Space
May 03, 2024



Facial Expression Recognition (FER) plays a pivotal role in understanding human emotional cues. However, traditional FER methods based on visual information have some limitations, such as preprocessing, feature extraction, and multi-stage classification procedures. These not only increase computational complexity but also require a significant amount of computing resources. Considering Convolutional Neural Network (CNN)-based FER schemes frequently prove inadequate in identifying the deep, long-distance dependencies embedded within facial expression images, and the Transformer's inherent quadratic computational complexity, this paper presents the FER-YOLO-Mamba model, which integrates the principles of Mamba and YOLO technologies to facilitate efficient coordination in facial expression image recognition and localization. Within the FER-YOLO-Mamba model, we further devise a FER-YOLO-VSS dual-branch module, which combines the inherent strengths of convolutional layers in local feature extraction with the exceptional capability of State Space Models (SSMs) in revealing long-distance dependencies. To the best of our knowledge, this is the first Vision Mamba model designed for facial expression detection and classification. To evaluate the performance of the proposed FER-YOLO-Mamba model, we conducted experiments on two benchmark datasets, RAF-DB and SFEW. The experimental results indicate that the FER-YOLO-Mamba model achieved better results compared to other models. The code is available from https://github.com/SwjtuMa/FER-YOLO-Mamba.
Ada-DF: An Adaptive Label Distribution Fusion Network For Facial Expression Recognition
Apr 24, 2024Facial expression recognition (FER) plays a significant role in our daily life. However, annotation ambiguity in the datasets could greatly hinder the performance. In this paper, we address FER task via label distribution learning paradigm, and develop a dual-branch Adaptive Distribution Fusion (Ada-DF) framework. One auxiliary branch is constructed to obtain the label distributions of samples. The class distributions of emotions are then computed through the label distributions of each emotion. Finally, those two distributions are adaptively fused according to the attention weights to train the target branch. Extensive experiments are conducted on three real-world datasets, RAF-DB, AffectNet and SFEW, where our Ada-DF shows advantages over the state-of-the-art works.
More comprehensive facial inversion for more effective expression recognition
Nov 24, 2022Facial expression recognition (FER) plays a significant role in the ubiquitous application of computer vision. We revisit this problem with a new perspective on whether it can acquire useful representations that improve FER performance in the image generation process, and propose a novel generative method based on the image inversion mechanism for the FER task, termed Inversion FER (IFER). Particularly, we devise a novel Adversarial Style Inversion Transformer (ASIT) towards IFER to comprehensively extract features of generated facial images. In addition, ASIT is equipped with an image inversion discriminator that measures the cosine similarity of semantic features between source and generated images, constrained by a distribution alignment loss. Finally, we introduce a feature modulation module to fuse the structural code and latent codes from ASIT for the subsequent FER work. We extensively evaluate ASIT on facial datasets such as FFHQ and CelebA-HQ, showing that our approach achieves state-of-the-art facial inversion performance. IFER also achieves competitive results in facial expression recognition datasets such as RAF-DB, SFEW and AffectNet. The code and models are available at https://github.com/Talented-Q/IFER-master.
Dynamic Adaptive Threshold based Learning for Noisy Annotations Robust Facial Expression Recognition
Aug 22, 2022
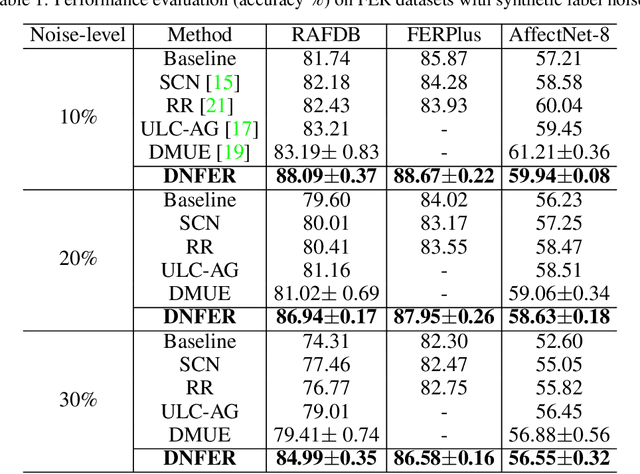
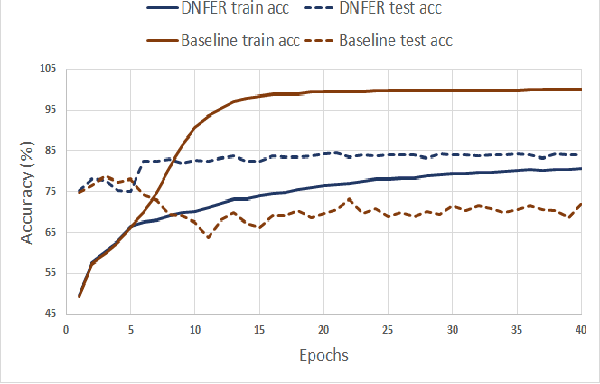
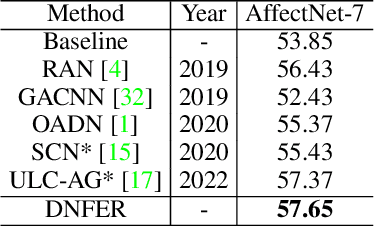
The real-world facial expression recognition (FER) datasets suffer from noisy annotations due to crowd-sourcing, ambiguity in expressions, the subjectivity of annotators and inter-class similarity. However, the recent deep networks have strong capacity to memorize the noisy annotations leading to corrupted feature embedding and poor generalization. To handle noisy annotations, we propose a dynamic FER learning framework (DNFER) in which clean samples are selected based on dynamic class specific threshold during training. Specifically, DNFER is based on supervised training using selected clean samples and unsupervised consistent training using all the samples. During training, the mean posterior class probabilities of each mini-batch is used as dynamic class-specific threshold to select the clean samples for supervised training. This threshold is independent of noise rate and does not need any clean data unlike other methods. In addition, to learn from all samples, the posterior distributions between weakly-augmented image and strongly-augmented image are aligned using an unsupervised consistency loss. We demonstrate the robustness of DNFER on both synthetic as well as on real noisy annotated FER datasets like RAFDB, FERPlus, SFEW and AffectNet.
Distract Your Attention: Multi-head Cross Attention Network for Facial Expression Recognition
Sep 15, 2021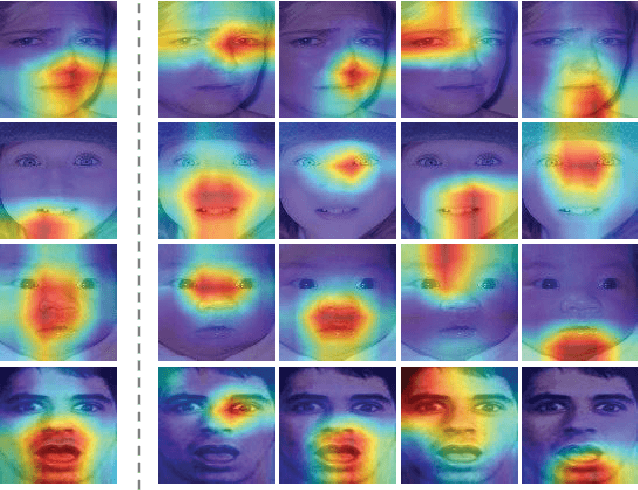
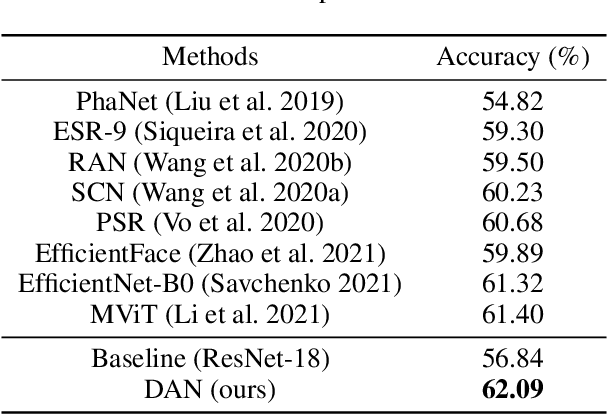
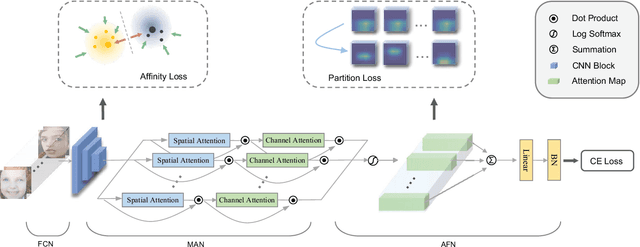
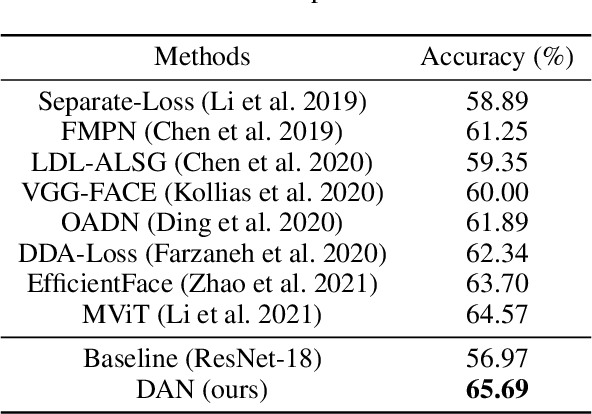
We present a novel facial expression recognition network, called Distract your Attention Network (DAN). Our method is based on two key observations. Firstly, multiple classes share inherently similar underlying facial appearance, and their differences could be subtle. Secondly, facial expressions exhibit themselves through multiple facial regions simultaneously, and the recognition requires a holistic approach by encoding high-order interactions among local features. To address these issues, we propose our DAN with three key components: Feature Clustering Network (FCN), Multi-head cross Attention Network (MAN), and Attention Fusion Network (AFN). The FCN extracts robust features by adopting a large-margin learning objective to maximize class separability. In addition, the MAN instantiates a number of attention heads to simultaneously attend to multiple facial areas and build attention maps on these regions. Further, the AFN distracts these attentions to multiple locations before fusing the attention maps to a comprehensive one. Extensive experiments on three public datasets (including AffectNet, RAF-DB, and SFEW 2.0) verified that the proposed method consistently achieves state-of-the-art facial expression recognition performance. Code will be made available at https://github.com/yaoing/DAN.
Learning Vision Transformer with Squeeze and Excitation for Facial Expression Recognition
Jul 16, 2021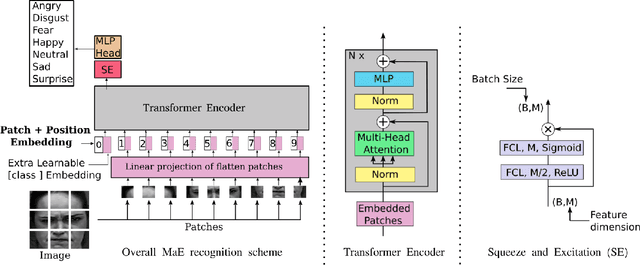
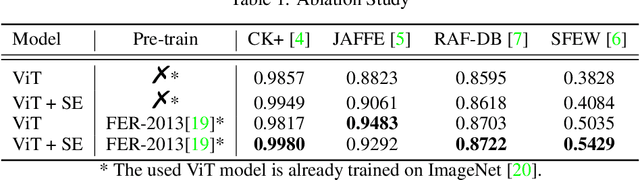
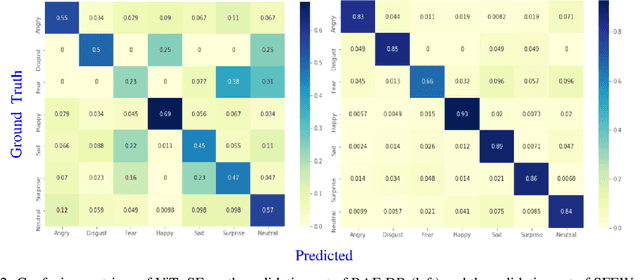
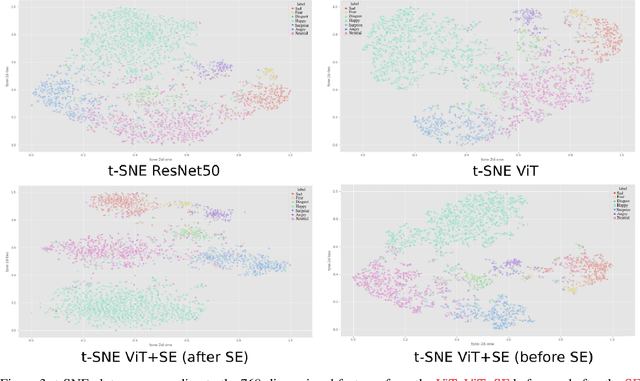
As various databases of facial expressions have been made accessible over the last few decades, the Facial Expression Recognition (FER) task has gotten a lot of interest. The multiple sources of the available databases raised several challenges for facial recognition task. These challenges are usually addressed by Convolution Neural Network (CNN) architectures. Different from CNN models, a Transformer model based on attention mechanism has been presented recently to address vision tasks. One of the major issue with Transformers is the need of a large data for training, while most FER databases are limited compared to other vision applications. Therefore, we propose in this paper to learn a vision Transformer jointly with a Squeeze and Excitation (SE) block for FER task. The proposed method is evaluated on different publicly available FER databases including CK+, JAFFE,RAF-DB and SFEW. Experiments demonstrate that our model outperforms state-of-the-art methods on CK+ and SFEW and achieves competitive results on JAFFE and RAF-DB.
Landmark-Aware and Part-based Ensemble Transfer Learning Network for Facial Expression Recognition from Static images
Apr 22, 2021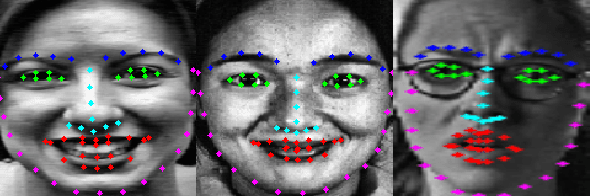
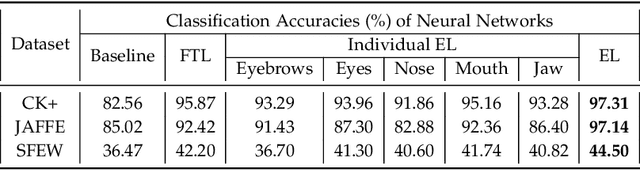

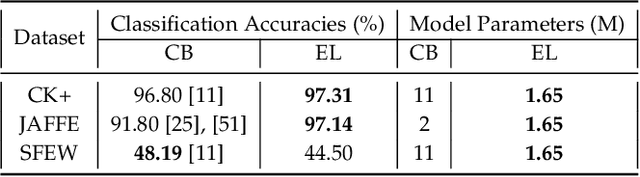
Facial Expression Recognition from static images is a challenging problem in computer vision applications. Convolutional Neural Network (CNN), the state-of-the-art method for various computer vision tasks, has had limited success in predicting expressions from faces having extreme poses, illumination, and occlusion conditions. To mitigate this issue, CNNs are often accompanied by techniques like transfer, multi-task, or ensemble learning that often provide high accuracy at the cost of high computational complexity. In this work, we propose a Part-based Ensemble Transfer Learning network, which models how humans recognize facial expressions by correlating the spatial orientation pattern of the facial features with a specific expression. It consists of 5 sub-networks, in which each sub-network performs transfer learning from one of the five subsets of facial landmarks: eyebrows, eyes, nose, mouth, or jaw to expression classification. We test the proposed network on the CK+, JAFFE, and SFEW datasets, and it outperforms the benchmark for CK+ and JAFFE datasets by 0.51\% and 5.34\%, respectively. Additionally, it consists of a total of 1.65M model parameters and requires only 3.28 $\times$ $10^{6}$ FLOPS, which ensures computational efficiency for real-time deployment. Grad-CAM visualizations of our proposed ensemble highlight the complementary nature of its sub-networks, a key design parameter of an effective ensemble network. Lastly, cross-dataset evaluation results reveal that our proposed ensemble has a high generalization capacity. Our model trained on the SFEW Train dataset achieves an accuracy of 47.53\% on the CK+ dataset, which is higher than what it achieves on the SFEW Valid dataset.
Feature Decomposition and Reconstruction Learning for Effective Facial Expression Recognition
Apr 21, 2021
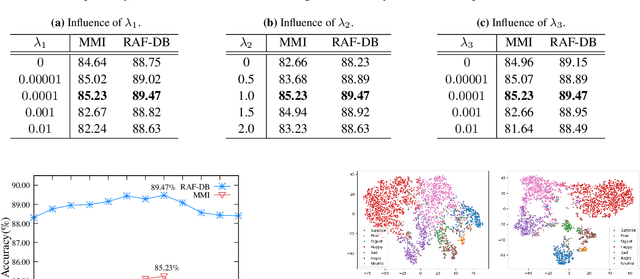
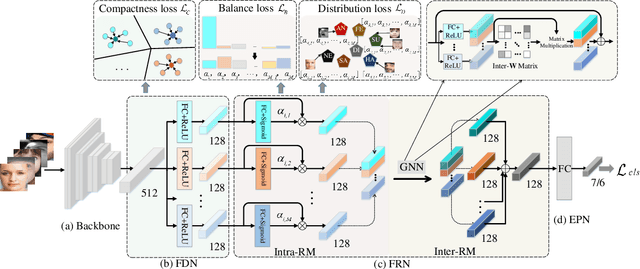
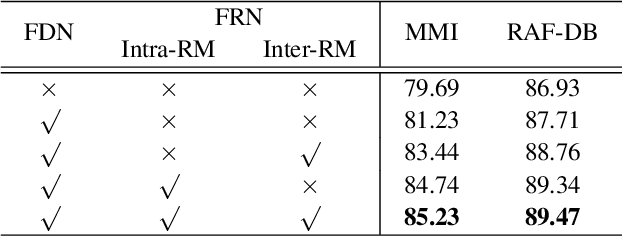
In this paper, we propose a novel Feature Decomposition and Reconstruction Learning (FDRL) method for effective facial expression recognition. We view the expression information as the combination of the shared information (expression similarities) across different expressions and the unique information (expression-specific variations) for each expression. More specifically, FDRL mainly consists of two crucial networks: a Feature Decomposition Network (FDN) and a Feature Reconstruction Network (FRN). In particular, FDN first decomposes the basic features extracted from a backbone network into a set of facial action-aware latent features to model expression similarities. Then, FRN captures the intra-feature and inter-feature relationships for latent features to characterize expression-specific variations, and reconstructs the expression feature. To this end, two modules including an intra-feature relation modeling module and an inter-feature relation modeling module are developed in FRN. Experimental results on both the in-the-lab databases (including CK+, MMI, and Oulu-CASIA) and the in-the-wild databases (including RAF-DB and SFEW) show that the proposed FDRL method consistently achieves higher recognition accuracy than several state-of-the-art methods. This clearly highlights the benefit of feature decomposition and reconstruction for classifying expressions.
Landmark Guidance Independent Spatio-channel Attention and Complementary Context Information based Facial Expression Recognition
Jul 25, 2020



A recent trend to recognize facial expressions in the real-world scenario is to deploy attention based convolutional neural networks (CNNs) locally to signify the importance of facial regions and, combine it with global facial features and/or other complementary context information for performance gain. However, in the presence of occlusions and pose variations, different channels respond differently, and further that the response intensity of a channel differ across spatial locations. Also, modern facial expression recognition(FER) architectures rely on external sources like landmark detectors for defining attention. Failure of landmark detector will have a cascading effect on FER. Additionally, there is no emphasis laid on the relevance of features that are input to compute complementary context information. Leveraging on the aforementioned observations, an end-to-end architecture for FER is proposed in this work that obtains both local and global attention per channel per spatial location through a novel spatio-channel attention net (SCAN), without seeking any information from the landmark detectors. SCAN is complemented by a complementary context information (CCI) branch. Further, using efficient channel attention (ECA), the relevance of features input to CCI is also attended to. The representation learnt by the proposed architecture is robust to occlusions and pose variations. Robustness and superior performance of the proposed model is demonstrated on both in-lab and in-the-wild datasets (AffectNet, FERPlus, RAF-DB, FED-RO, SFEW, CK+, Oulu-CASIA and JAFFE) along with a couple of constructed face mask datasets resembling masked faces in COVID-19 scenario. Codes are publicly available at https://github.com/1980x/SCAN-CCI-FER