 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf Supervised Person Re Identification
Papers and Code
Person Re-ID in 2025: Supervised, Self-Supervised, and Language-Aligned. What Works?
Jan 28, 2026Person Re-Identification (ReID) remains a challenging problem in computer vision. This work reviews various training paradigm and evaluates the robustness of state-of-the-art ReID models in cross-domain applications and examines the role of foundation models in improving generalization through richer, more transferable visual representations. We compare three training paradigms, supervised, self-supervised, and language-aligned models. Through the study the aim is to answer the following questions: Can supervised models generalize in cross-domain scenarios? How does foundation models like SigLIP2 perform for the ReID tasks? What are the weaknesses of current supervised and foundational models for ReID? We have conducted the analysis across 11 models and 9 datasets. Our results show a clear split: supervised models dominate their training domain but crumble on cross-domain data. Language-aligned models, however, show surprising robustness cross-domain for ReID tasks, even though they are not explicitly trained to do so. Code and data available at: https://github.com/moiiai-tech/object-reid-benchmark.
Generalizable Object Re-Identification via Visual In-Context Prompting
Aug 28, 2025



Current object re-identification (ReID) methods train domain-specific models (e.g., for persons or vehicles), which lack generalization and demand costly labeled data for new categories. While self-supervised learning reduces annotation needs by learning instance-wise invariance, it struggles to capture \textit{identity-sensitive} features critical for ReID. This paper proposes Visual In-Context Prompting~(VICP), a novel framework where models trained on seen categories can directly generalize to unseen novel categories using only \textit{in-context examples} as prompts, without requiring parameter adaptation. VICP synergizes LLMs and vision foundation models~(VFM): LLMs infer semantic identity rules from few-shot positive/negative pairs through task-specific prompting, which then guides a VFM (\eg, DINO) to extract ID-discriminative features via \textit{dynamic visual prompts}. By aligning LLM-derived semantic concepts with the VFM's pre-trained prior, VICP enables generalization to novel categories, eliminating the need for dataset-specific retraining. To support evaluation, we introduce ShopID10K, a dataset of 10K object instances from e-commerce platforms, featuring multi-view images and cross-domain testing. Experiments on ShopID10K and diverse ReID benchmarks demonstrate that VICP outperforms baselines by a clear margin on unseen categories. Code is available at https://github.com/Hzzone/VICP.
Self-Reinforcing Prototype Evolution with Dual-Knowledge Cooperation for Semi-Supervised Lifelong Person Re-Identification
Jul 02, 2025Current lifelong person re-identification (LReID) methods predominantly rely on fully labeled data streams. However, in real-world scenarios where annotation resources are limited, a vast amount of unlabeled data coexists with scarce labeled samples, leading to the Semi-Supervised LReID (Semi-LReID) problem where LReID methods suffer severe performance degradation. Existing LReID methods, even when combined with semi-supervised strategies, suffer from limited long-term adaptation performance due to struggling with the noisy knowledge occurring during unlabeled data utilization. In this paper, we pioneer the investigation of Semi-LReID, introducing a novel Self-Reinforcing Prototype Evolution with Dual-Knowledge Cooperation framework (SPRED). Our key innovation lies in establishing a self-reinforcing cycle between dynamic prototype-guided pseudo-label generation and new-old knowledge collaborative purification to enhance the utilization of unlabeled data. Specifically, learnable identity prototypes are introduced to dynamically capture the identity distributions and generate high-quality pseudo-labels. Then, the dual-knowledge cooperation scheme integrates current model specialization and historical model generalization, refining noisy pseudo-labels. Through this cyclic design, reliable pseudo-labels are progressively mined to improve current-stage learning and ensure positive knowledge propagation over long-term learning. Experiments on the established Semi-LReID benchmarks show that our SPRED achieves state-of-the-art performance. Our source code is available at https://github.com/zhoujiahuan1991/ICCV2025-SPRED
Causality and "In-the-Wild" Video-Based Person Re-ID: A Survey
May 28, 2025



Video-based person re-identification (Re-ID) remains brittle in real-world deployments despite impressive benchmark performance. Most existing models rely on superficial correlations such as clothing, background, or lighting that fail to generalize across domains, viewpoints, and temporal variations. This survey examines the emerging role of causal reasoning as a principled alternative to traditional correlation-based approaches in video-based Re-ID. We provide a structured and critical analysis of methods that leverage structural causal models, interventions, and counterfactual reasoning to isolate identity-specific features from confounding factors. The survey is organized around a novel taxonomy of causal Re-ID methods that spans generative disentanglement, domain-invariant modeling, and causal transformers. We review current evaluation metrics and introduce causal-specific robustness measures. In addition, we assess practical challenges of scalability, fairness, interpretability, and privacy that must be addressed for real-world adoption. Finally, we identify open problems and outline future research directions that integrate causal modeling with efficient architectures and self-supervised learning. This survey aims to establish a coherent foundation for causal video-based person Re-ID and to catalyze the next phase of research in this rapidly evolving domain.
Robust Duality Learning for Unsupervised Visible-Infrared Person Re-Identfication
May 05, 2025
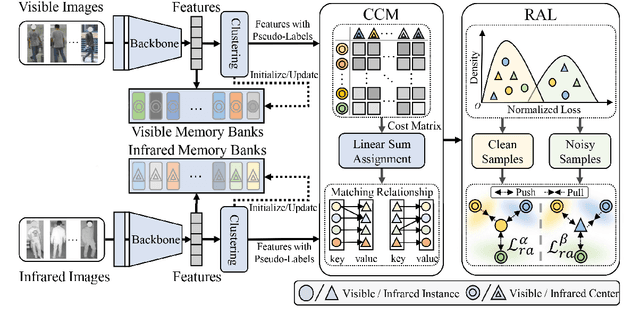


Unsupervised visible-infrared person re-identification (UVI-ReID) aims to retrieve pedestrian images across different modalities without costly annotations, but faces challenges due to the modality gap and lack of supervision. Existing methods often adopt self-training with clustering-generated pseudo-labels but implicitly assume these labels are always correct. In practice, however, this assumption fails due to inevitable pseudo-label noise, which hinders model learning. To address this, we introduce a new learning paradigm that explicitly considers Pseudo-Label Noise (PLN), characterized by three key challenges: noise overfitting, error accumulation, and noisy cluster correspondence. To this end, we propose a novel Robust Duality Learning framework (RoDE) for UVI-ReID to mitigate the effects of noisy pseudo-labels. First, to combat noise overfitting, a Robust Adaptive Learning mechanism (RAL) is proposed to dynamically emphasize clean samples while down-weighting noisy ones. Second, to alleviate error accumulation-where the model reinforces its own mistakes-RoDE employs dual distinct models that are alternately trained using pseudo-labels from each other, encouraging diversity and preventing collapse. However, this dual-model strategy introduces misalignment between clusters across models and modalities, creating noisy cluster correspondence. To resolve this, we introduce Cluster Consistency Matching (CCM), which aligns clusters across models and modalities by measuring cross-cluster similarity. Extensive experiments on three benchmarks demonstrate the effectiveness of RoDE.
Learning from Synchronization: Self-Supervised Uncalibrated Multi-View Person Association in Challenging Scenes
Mar 17, 2025Multi-view person association is a fundamental step towards multi-view analysis of human activities. Although the person re-identification features have been proven effective, they become unreliable in challenging scenes where persons share similar appearances. Therefore, cross-view geometric constraints are required for a more robust association. However, most existing approaches are either fully-supervised using ground-truth identity labels or require calibrated camera parameters that are hard to obtain. In this work, we investigate the potential of learning from synchronization, and propose a self-supervised uncalibrated multi-view person association approach, Self-MVA, without using any annotations. Specifically, we propose a self-supervised learning framework, consisting of an encoder-decoder model and a self-supervised pretext task, cross-view image synchronization, which aims to distinguish whether two images from different views are captured at the same time. The model encodes each person's unified geometric and appearance features, and we train it by utilizing synchronization labels for supervision after applying Hungarian matching to bridge the gap between instance-wise and image-wise distances. To further reduce the solution space, we propose two types of self-supervised linear constraints: multi-view re-projection and pairwise edge association. Extensive experiments on three challenging public benchmark datasets (WILDTRACK, MVOR, and SOLDIERS) show that our approach achieves state-of-the-art results, surpassing existing unsupervised and fully-supervised approaches. Code is available at https://github.com/CAMMA-public/Self-MVA.
A Quantitative Evaluation of the Expressivity of BMI, Pose and Gender in Body Embeddings for Recognition and Identification
Mar 09, 2025Person Re-identification (ReID) systems identify individuals across images or video frames and play a critical role in various real-world applications. However, many ReID methods are influenced by sensitive attributes such as gender, pose, and body mass index (BMI), which vary in uncontrolled environments, leading to biases and reduced generalization. To address this, we extend the concept of expressivity to the body recognition domain to better understand how ReID models encode these attributes. Expressivity, defined as the mutual information between feature vector representations and specific attributes, is computed using a secondary neural network that takes feature and attribute vectors as inputs. This provides a quantitative framework for analyzing the extent to which sensitive attributes are embedded in the model's representations. We apply expressivity analysis to SemReID, a state-of-the-art self-supervised ReID model, and find that BMI consistently exhibits the highest expressivity scores in the model's final layers, underscoring its dominant role in feature encoding. In the final attention layer of the trained network, the expressivity order for body attributes is BMI > Pitch > Yaw > Gender, highlighting their relative importance in learned representations. Additionally, expressivity values evolve progressively across network layers and training epochs, reflecting a dynamic encoding of attributes during feature extraction. These insights emphasize the influence of body-related attributes on ReID models and provide a systematic methodology for identifying and mitigating attribute-driven biases. By leveraging expressivity analysis, we offer valuable tools to enhance the fairness, robustness, and generalization of ReID systems in diverse real-world settings.
Exploring Stronger Transformer Representation Learning for Occluded Person Re-Identificatio
Oct 21, 2024Due to some complex factors (e.g., occlusion, pose variation and diverse camera perspectives), extracting stronger feature representation in person re-identification remains a challenging task. In this paper, we proposed a novel self-supervision and supervision combining transformer-based person re-identification framework, namely SSSC-TransReID. Different from the general transformer-based person re-identification models, we designed a self-supervised contrastive learning branch, which can enhance the feature representation for person re-identification without negative samples or additional pre-training. In order to train the contrastive learning branch, we also proposed a novel random rectangle mask strategy to simulate the occlusion in real scenes, so as to enhance the feature representation for occlusion. Finally, we utilized the joint-training loss function to integrate the advantages of supervised learning with ID tags and self-supervised contrastive learning without negative samples, which can reinforce the ability of our model to excavate stronger discriminative features, especially for occlusion. Extensive experimental results on several benchmark datasets show our proposed model obtains superior Re-ID performance consistently and outperforms the state-of-the-art ReID methods by large margins on the mean average accuracy (mAP) and Rank-1 accuracy.
PersonViT: Large-scale Self-supervised Vision Transformer for Person Re-Identificat
Aug 10, 2024



Person Re-Identification (ReID) aims to retrieve relevant individuals in non-overlapping camera images and has a wide range of applications in the field of public safety. In recent years, with the development of Vision Transformer (ViT) and self-supervised learning techniques, the performance of person ReID based on self-supervised pre-training has been greatly improved. Person ReID requires extracting highly discriminative local fine-grained features of the human body, while traditional ViT is good at extracting context-related global features, making it difficult to focus on local human body features. To this end, this article introduces the recently emerged Masked Image Modeling (MIM) self-supervised learning method into person ReID, and effectively extracts high-quality global and local features through large-scale unsupervised pre-training by combining masked image modeling and discriminative contrastive learning, and then conducts supervised fine-tuning training in the person ReID task. This person feature extraction method based on ViT with masked image modeling (PersonViT) has the good characteristics of unsupervised, scalable, and strong generalization capabilities, overcoming the problem of difficult annotation in supervised person ReID, and achieves state-of-the-art results on publicly available benchmark datasets, including MSMT17, Market1501, DukeMTMC-reID, and Occluded-Duke. The code and pre-trained models of the PersonViT method are released at https://github.com/hustvl/PersonViT to promote further research in the person ReID fie
ReMix: Training Generalized Person Re-identification on a Mixture of Data
Oct 29, 2024



Modern person re-identification (Re-ID) methods have a weak generalization ability and experience a major accuracy drop when capturing environments change. This is because existing multi-camera Re-ID datasets are limited in size and diversity, since such data is difficult to obtain. At the same time, enormous volumes of unlabeled single-camera records are available. Such data can be easily collected, and therefore, it is more diverse. Currently, single-camera data is used only for self-supervised pre-training of Re-ID methods. However, the diversity of single-camera data is suppressed by fine-tuning on limited multi-camera data after pre-training. In this paper, we propose ReMix, a generalized Re-ID method jointly trained on a mixture of limited labeled multi-camera and large unlabeled single-camera data. Effective training of our method is achieved through a novel data sampling strategy and new loss functions that are adapted for joint use with both types of data. Experiments show that ReMix has a high generalization ability and outperforms state-of-the-art methods in generalizable person Re-ID. To the best of our knowledge, this is the first work that explores joint training on a mixture of multi-camera and single-camera data in person Re-ID.