 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScitsr
Papers and Code
Rethinking Detection Based Table Structure Recognition for Visually Rich Documents
Dec 01, 2023



Table Structure Recognition (TSR) aims at transforming unstructured table images into structured formats, such as HTML sequences. One type of popular solution is using detection models to detect components of a table, such as columns and rows, then applying a rule-based post-processing method to convert detection results into HTML sequences. However, existing detection-based studies often have the following limitations. First, these studies usually pay more attention to improving the detection performance, which does not necessarily lead to better performance regarding cell-level metrics, such as TEDS. Second, some solutions over-simplify the problem and can miss some critical information. Lastly, even though some studies defined the problem to detect more components to provide as much information as other types of solutions, these studies ignore the fact this problem definition is a multi-label detection because row, projected row header and column header can share identical bounding boxes. Besides, there is often a performance gap between two-stage and transformer-based detection models regarding the structure-only TEDS, even though they have similar performance regarding the COCO metrics. Therefore, we revisit the limitations of existing detection-based solutions, compare two-stage and transformer-based detection models, and identify the key design aspects for the success of a two-stage detection model for the TSR task, including the multi-class problem definition, the aspect ratio for anchor box generation, and the feature generation of the backbone network. We applied simple methods to improve these aspects of the Cascade R-CNN model, achieved state-of-the-art performance, and improved the baseline Cascade R-CNN model by 19.32%, 11.56% and 14.77% regarding the structure-only TEDS on SciTSR, FinTabNet, and PubTables1M datasets.
Robust Table Structure Recognition with Dynamic Queries Enhanced Detection Transformer
Mar 21, 2023



We present a new table structure recognition (TSR) approach, called TSRFormer, to robustly recognizing the structures of complex tables with geometrical distortions from various table images. Unlike previous methods, we formulate table separation line prediction as a line regression problem instead of an image segmentation problem and propose a new two-stage dynamic queries enhanced DETR based separation line regression approach, named DQ-DETR, to predict separation lines from table images directly. Compared to Vallina DETR, we propose three improvements in DQ-DETR to make the two-stage DETR framework work efficiently and effectively for the separation line prediction task: 1) A new query design, named Dynamic Query, to decouple single line query into separable point queries which could intuitively improve the localization accuracy for regression tasks; 2) A dynamic queries based progressive line regression approach to progressively regressing points on the line which further enhances localization accuracy for distorted tables; 3) A prior-enhanced matching strategy to solve the slow convergence issue of DETR. After separation line prediction, a simple relation network based cell merging module is used to recover spanning cells. With these new techniques, our TSRFormer achieves state-of-the-art performance on several benchmark datasets, including SciTSR, PubTabNet, WTW and FinTabNet. Furthermore, we have validated the robustness and high localization accuracy of our approach to tables with complex structures, borderless cells, large blank spaces, empty or spanning cells as well as distorted or even curved shapes on a more challenging real-world in-house dataset.
SEMv2: Table Separation Line Detection Based on Conditional Convolution
Mar 08, 2023



Table structure recognition is an indispensable element for enabling machines to comprehend tables. Its primary purpose is to identify the internal structure of a table. Nevertheless, due to the complexity and diversity of their structure and style, it is highly challenging to parse the tabular data into a structured format that machines can comprehend. In this work, we adhere to the principle of the split-and-merge based methods and propose an accurate table structure recognizer, termed SEMv2 (SEM: Split, Embed and Merge). Unlike the previous works in the ``split'' stage, we aim to address the table separation line instance-level discrimination problem and introduce a table separation line detection strategy based on conditional convolution. Specifically, we design the ``split'' in a top-down manner that detects the table separation line instance first and then dynamically predicts the table separation line mask for each instance. The final table separation line shape can be accurately obtained by processing the table separation line mask in a row-wise/column-wise manner. To comprehensively evaluate the SEMv2, we also present a more challenging dataset for table structure recognition, dubbed iFLYTAB, which encompasses multiple style tables in various scenarios such as photos, scanned documents, etc. Extensive experiments on publicly available datasets (e.g. SciTSR, PubTabNet and iFLYTAB) demonstrate the efficacy of our proposed approach. The code and iFLYTAB dataset will be made publicly available upon acceptance of this paper.
TSRFormer: Table Structure Recognition with Transformers
Aug 09, 2022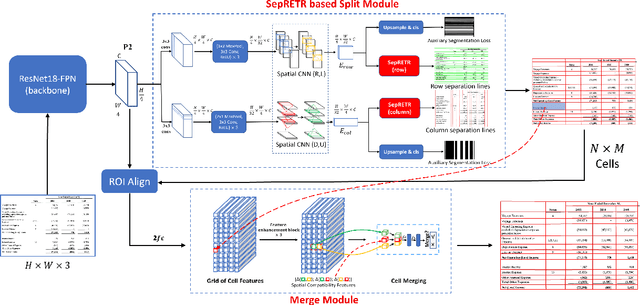
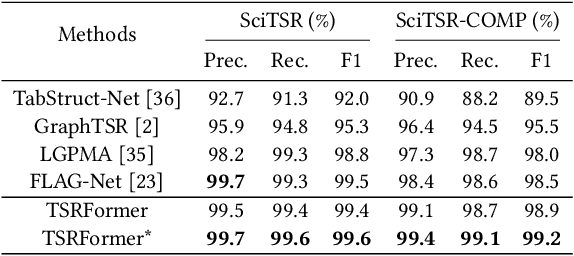
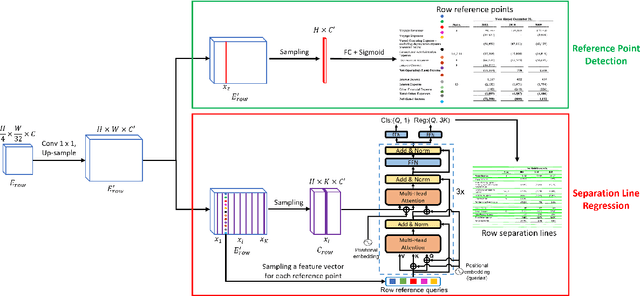
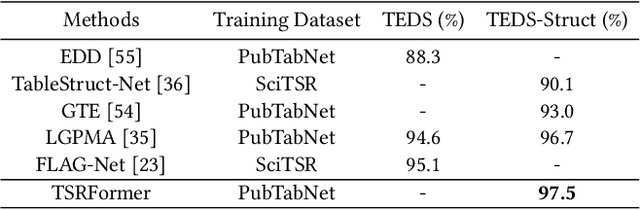
We present a new table structure recognition (TSR) approach, called TSRFormer, to robustly recognizing the structures of complex tables with geometrical distortions from various table images. Unlike previous methods, we formulate table separation line prediction as a line regression problem instead of an image segmentation problem and propose a new two-stage DETR based separator prediction approach, dubbed \textbf{Sep}arator \textbf{RE}gression \textbf{TR}ansformer (SepRETR), to predict separation lines from table images directly. To make the two-stage DETR framework work efficiently and effectively for the separation line prediction task, we propose two improvements: 1) A prior-enhanced matching strategy to solve the slow convergence issue of DETR; 2) A new cross attention module to sample features from a high-resolution convolutional feature map directly so that high localization accuracy is achieved with low computational cost. After separation line prediction, a simple relation network based cell merging module is used to recover spanning cells. With these new techniques, our TSRFormer achieves state-of-the-art performance on several benchmark datasets, including SciTSR, PubTabNet and WTW. Furthermore, we have validated the robustness of our approach to tables with complex structures, borderless cells, large blank spaces, empty or spanning cells as well as distorted or even curved shapes on a more challenging real-world in-house dataset.
Robust Table Detection and Structure Recognition from Heterogeneous Document Images
Mar 17, 2022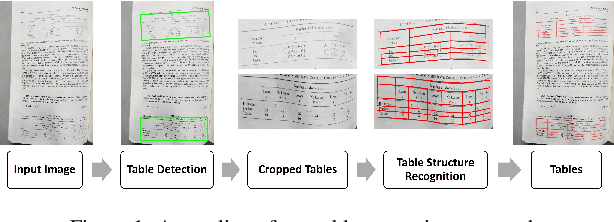
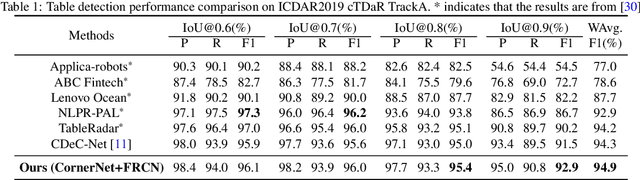
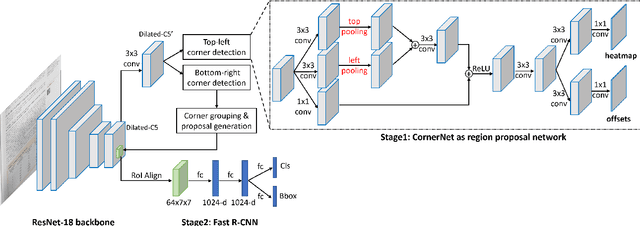

We introduce a new table detection and structure recognition approach named RobusTabNet to detect the boundaries of tables and reconstruct the cellular structure of the table from heterogeneous document images. For table detection, we propose to use CornerNet as a new region proposal network to generate higher quality table proposals for Faster R-CNN, which has significantly improved the localization accuracy of Faster R-CNN for table detection. Consequently, our table detection approach achieves state-of-the-art performance on three public table detection benchmarks, namely cTDaR TrackA, PubLayNet and IIIT-AR-13K, by only using a lightweight ResNet-18 backbone network. Furthermore, we propose a new split-and-merge based table structure recognition approach, in which a novel spatial CNN based separation line prediction module is proposed to split each detected table into a grid of cells, and a Grid CNN based cell merging module is applied to recover the spanning cells. As the spatial CNN module can effectively propagate contextual information across the whole table image, our table structure recognizer can robustly recognize tables with large blank spaces and geometrically distorted (even curved) tables. Thanks to these two techniques, our table structure recognition approach achieves state-of-the-art performance on three public benchmarks, including SciTSR, PubTabNet and cTDaR TrackB. Moreover, we have further demonstrated the advantages of our approach in recognizing tables with complex structures, large blank spaces, empty or spanning cells as well as geometrically distorted or even curved tables on a more challenging in-house dataset.
BROS: A Pre-trained Language Model Focusing on Text and Layout for Better Key Information Extraction from Documents
Sep 10, 2021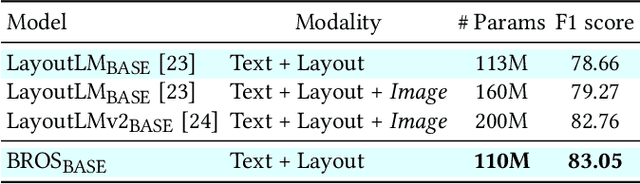
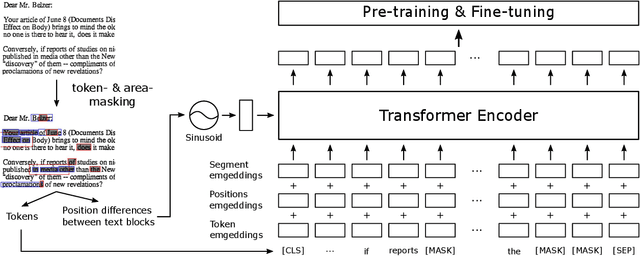

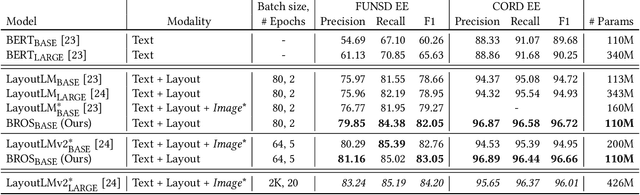
Key information extraction (KIE) from document images requires understanding the contextual and spatial semantics of texts in two-dimensional (2D) space. Many recent studies try to solve the task by developing pre-training language models focusing on combining visual features from document images with texts and their layout. On the other hand, this paper tackles the problem by going back to the basic: effective combination of text and layout. Specifically, we propose a pre-trained language model, named BROS (BERT Relying On Spatiality), that encodes relative positions of texts in 2D space and learns from unlabeled documents with area-masking strategy. With this optimized training scheme for understanding texts in 2D space, BROS shows comparable or better performance compared to previous methods on four KIE benchmarks (FUNSD, SROIE*, CORD, and SciTSR) without relying on visual features. This paper also reveals two real-world challenges in KIE tasks--(1) minimizing the error from incorrect text ordering and (2) efficient learning from fewer downstream examples--and demonstrates the superiority of BROS over previous methods. Our code will be open to the public.
Split, embed and merge: An accurate table structure recognizer
Jul 20, 2021

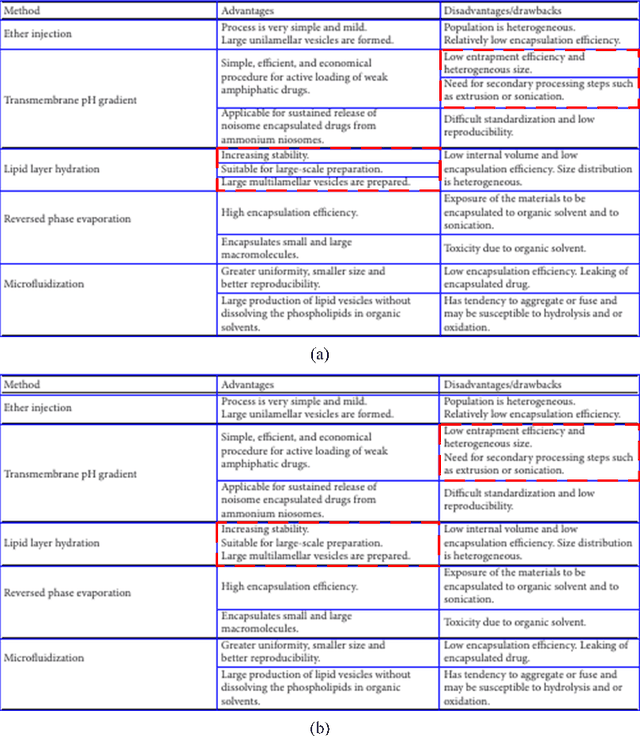
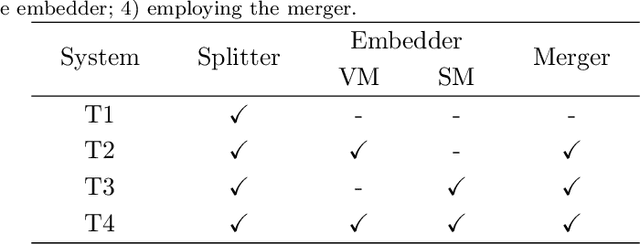
Table structure recognition is an essential part for making machines understand tables. Its main task is to recognize the internal structure of a table. However, due to the complexity and diversity in their structure and style, it is very difficult to parse the tabular data into the structured format which machines can understand easily, especially for complex tables. In this paper, we introduce Split, Embed and Merge (SEM), an accurate table structure recognizer. Our model takes table images as input and can correctly recognize the structure of tables, whether they are simple or a complex tables. SEM is mainly composed of three parts, splitter, embedder and merger. In the first stage, we apply the splitter to predict the potential regions of the table row (column) separators, and obtain the fine grid structure of the table. In the second stage, by taking a full consideration of the textual information in the table, we fuse the output features for each table grid from both vision and language modalities. Moreover, we achieve a higher precision in our experiments through adding additional semantic features. Finally, we process the merging of these basic table grids in a self-regression manner. The correspondent merging results is learned through the attention mechanism. In our experiments, SEM achieves an average F1-Measure of 97.11% on the SciTSR dataset which outperforms other methods by a large margin. We also won the first place in the complex table and third place in all tables in ICDAR 2021 Competition on Scientific Literature Parsing, Task-B. Extensive experiments on other publicly available datasets demonstrate that our model achieves state-of-the-art.
Table Structure Recognition using Top-Down and Bottom-Up Cues
Oct 09, 2020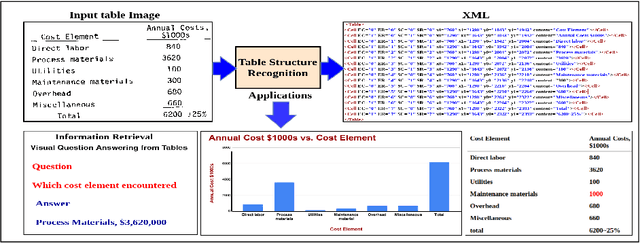

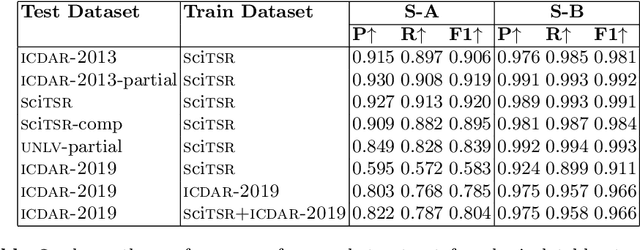
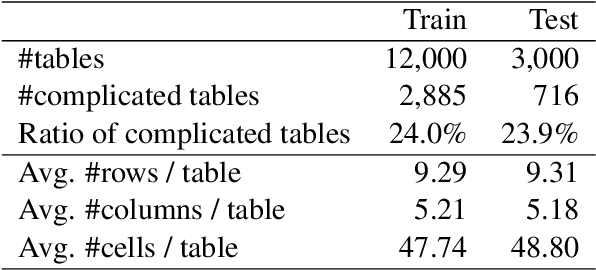
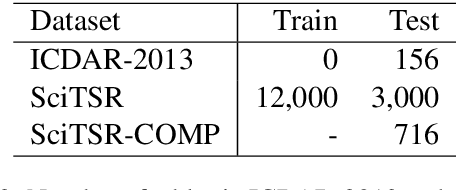
Tables are information-rich structured objects in document images. While significant work has been done in localizing tables as graphic objects in document images, only limited attempts exist on table structure recognition. Most existing literature on structure recognition depends on extraction of meta-features from the PDF document or on the optical character recognition (OCR) models to extract low-level layout features from the image. However, these methods fail to generalize well because of the absence of meta-features or errors made by the OCR when there is a significant variance in table layouts and text organization. In our work, we focus on tables that have complex structures, dense content, and varying layouts with no dependency on meta-features and/or OCR. We present an approach for table structure recognition that combines cell detection and interaction modules to localize the cells and predict their row and column associations with other detected cells. We incorporate structural constraints as additional differential components to the loss function for cell detection. We empirically validate our method on the publicly available real-world datasets - ICDAR-2013, ICDAR-2019 (cTDaR) archival, UNLV, SciTSR, SciTSR-COMP, TableBank, and PubTabNet. Our attempt opens up a new direction for table structure recognition by combining top-down (table cells detection) and bottom-up (structure recognition) cues in visually understanding the tables.
Complicated Table Structure Recognition
Aug 28, 2019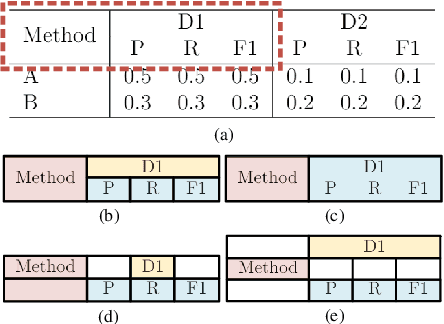
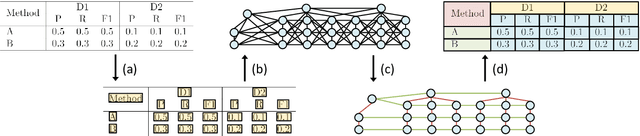
The task of table structure recognition aims to recognize the internal structure of a table, which is a key step to make machines understand tables. Currently, there are lots of studies on this task for different file formats such as ASCII text and HTML. It also attracts lots of attention to recognize the table structures in PDF files. However, it is hard for the existing methods to accurately recognize the structure of complicated tables in PDF files. The complicated tables contain spanning cells which occupy at least two columns or rows. To address the issue, we propose a novel graph neural network for recognizing the table structure in PDF files, named GraphTSR. Specifically, it takes table cells as input, and then recognizes the table structures by predicting relations among cells. Moreover, to evaluate the task better, we construct a large-scale table structure recognition dataset from scientific papers, named SciTSR, which contains 15,000 tables from PDF files and their corresponding structure labels. Extensive experiments demonstrate that our proposed model is highly effective for complicated tables and outperforms state-of-the-art baselines over a benchmark dataset and our new constructed dataset.