 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNsfw detection
Papers and Code
Value-Aligned Prompt Moderation via Zero-Shot Agentic Rewriting for Safe Image Generation
Nov 12, 2025



Generative vision-language models like Stable Diffusion demonstrate remarkable capabilities in creative media synthesis, but they also pose substantial risks of producing unsafe, offensive, or culturally inappropriate content when prompted adversarially. Current defenses struggle to align outputs with human values without sacrificing generation quality or incurring high costs. To address these challenges, we introduce VALOR (Value-Aligned LLM-Overseen Rewriter), a modular, zero-shot agentic framework for safer and more helpful text-to-image generation. VALOR integrates layered prompt analysis with human-aligned value reasoning: a multi-level NSFW detector filters lexical and semantic risks; a cultural value alignment module identifies violations of social norms, legality, and representational ethics; and an intention disambiguator detects subtle or indirect unsafe implications. When unsafe content is detected, prompts are selectively rewritten by a large language model under dynamic, role-specific instructions designed to preserve user intent while enforcing alignment. If the generated image still fails a safety check, VALOR optionally performs a stylistic regeneration to steer the output toward a safer visual domain without altering core semantics. Experiments across adversarial, ambiguous, and value-sensitive prompts show that VALOR significantly reduces unsafe outputs by up to 100.00% while preserving prompt usefulness and creativity. These results highlight VALOR as a scalable and effective approach for deploying safe, aligned, and helpful image generation systems in open-world settings.
Wukong Framework for Not Safe For Work Detection in Text-to-Image systems
Aug 01, 2025



Text-to-Image (T2I) generation is a popular AI-generated content (AIGC) technology enabling diverse and creative image synthesis. However, some outputs may contain Not Safe For Work (NSFW) content (e.g., violence), violating community guidelines. Detecting NSFW content efficiently and accurately, known as external safeguarding, is essential. Existing external safeguards fall into two types: text filters, which analyze user prompts but overlook T2I model-specific variations and are prone to adversarial attacks; and image filters, which analyze final generated images but are computationally costly and introduce latency. Diffusion models, the foundation of modern T2I systems like Stable Diffusion, generate images through iterative denoising using a U-Net architecture with ResNet and Transformer blocks. We observe that: (1) early denoising steps define the semantic layout of the image, and (2) cross-attention layers in U-Net are crucial for aligning text and image regions. Based on these insights, we propose Wukong, a transformer-based NSFW detection framework that leverages intermediate outputs from early denoising steps and reuses U-Net's pre-trained cross-attention parameters. Wukong operates within the diffusion process, enabling early detection without waiting for full image generation. We also introduce a new dataset containing prompts, seeds, and image-specific NSFW labels, and evaluate Wukong on this and two public benchmarks. Results show that Wukong significantly outperforms text-based safeguards and achieves comparable accuracy of image filters, while offering much greater efficiency.
VModA: An Effective Framework for Adaptive NSFW Image Moderation
May 29, 2025



Not Safe/Suitable for Work (NSFW) content is rampant on social networks and poses serious harm to citizens, especially minors. Current detection methods mainly rely on deep learning-based image recognition and classification. However, NSFW images are now presented in increasingly sophisticated ways, often using image details and complex semantics to obscure their true nature or attract more views. Although still understandable to humans, these images often evade existing detection methods, posing a significant threat. Further complicating the issue, varying regulations across platforms and regions create additional challenges for effective moderation, leading to detection bias and reduced accuracy. To address this, we propose VModA, a general and effective framework that adapts to diverse moderation rules and handles complex, semantically rich NSFW content across categories. Experimental results show that VModA significantly outperforms existing methods, achieving up to a 54.3% accuracy improvement across NSFW types, including those with complex semantics. Further experiments demonstrate that our method exhibits strong adaptability across categories, scenarios, and base VLMs. We also identified inconsistent and controversial label samples in public NSFW benchmark datasets, re-annotated them, and submitted corrections to the original maintainers. Two datasets have confirmed the updates so far. Additionally, we evaluate VModA in real-world scenarios to demonstrate its practical effectiveness.
Towards Safe Synthetic Image Generation On the Web: A Multimodal Robust NSFW Defense and Million Scale Dataset
Apr 16, 2025In the past years, we have witnessed the remarkable success of Text-to-Image (T2I) models and their widespread use on the web. Extensive research in making T2I models produce hyper-realistic images has led to new concerns, such as generating Not-Safe-For-Work (NSFW) web content and polluting the web society. To help prevent misuse of T2I models and create a safer web environment for users features like NSFW filters and post-hoc security checks are used in these models. However, recent work unveiled how these methods can easily fail to prevent misuse. In particular, adversarial attacks on text and image modalities can easily outplay defensive measures. %Exploiting such leads to the growing concern of preventing adversarial attacks on text and image modalities. Moreover, there is currently no robust multimodal NSFW dataset that includes both prompt and image pairs and adversarial examples. This work proposes a million-scale prompt and image dataset generated using open-source diffusion models. Second, we develop a multimodal defense to distinguish safe and NSFW text and images, which is robust against adversarial attacks and directly alleviates current challenges. Our extensive experiments show that our model performs well against existing SOTA NSFW detection methods in terms of accuracy and recall, drastically reducing the Attack Success Rate (ASR) in multimodal adversarial attack scenarios. Code: https://github.com/shahidmuneer/multimodal-nsfw-defense.
TokenProber: Jailbreaking Text-to-image Models via Fine-grained Word Impact Analysis
May 11, 2025Text-to-image (T2I) models have significantly advanced in producing high-quality images. However, such models have the ability to generate images containing not-safe-for-work (NSFW) content, such as pornography, violence, political content, and discrimination. To mitigate the risk of generating NSFW content, refusal mechanisms, i.e., safety checkers, have been developed to check potential NSFW content. Adversarial prompting techniques have been developed to evaluate the robustness of the refusal mechanisms. The key challenge remains to subtly modify the prompt in a way that preserves its sensitive nature while bypassing the refusal mechanisms. In this paper, we introduce TokenProber, a method designed for sensitivity-aware differential testing, aimed at evaluating the robustness of the refusal mechanisms in T2I models by generating adversarial prompts. Our approach is based on the key observation that adversarial prompts often succeed by exploiting discrepancies in how T2I models and safety checkers interpret sensitive content. Thus, we conduct a fine-grained analysis of the impact of specific words within prompts, distinguishing between dirty words that are essential for NSFW content generation and discrepant words that highlight the different sensitivity assessments between T2I models and safety checkers. Through the sensitivity-aware mutation, TokenProber generates adversarial prompts, striking a balance between maintaining NSFW content generation and evading detection. Our evaluation of TokenProber against 5 safety checkers on 3 popular T2I models, using 324 NSFW prompts, demonstrates its superior effectiveness in bypassing safety filters compared to existing methods (e.g., 54%+ increase on average), highlighting TokenProber's ability to uncover robustness issues in the existing refusal mechanisms.
GhostPrompt: Jailbreaking Text-to-image Generative Models based on Dynamic Optimization
May 25, 2025Text-to-image (T2I) generation models can inadvertently produce not-safe-for-work (NSFW) content, prompting the integration of text and image safety filters. Recent advances employ large language models (LLMs) for semantic-level detection, rendering traditional token-level perturbation attacks largely ineffective. However, our evaluation shows that existing jailbreak methods are ineffective against these modern filters. We introduce GhostPrompt, the first automated jailbreak framework that combines dynamic prompt optimization with multimodal feedback. It consists of two key components: (i) Dynamic Optimization, an iterative process that guides a large language model (LLM) using feedback from text safety filters and CLIP similarity scores to generate semantically aligned adversarial prompts; and (ii) Adaptive Safety Indicator Injection, which formulates the injection of benign visual cues as a reinforcement learning problem to bypass image-level filters. GhostPrompt achieves state-of-the-art performance, increasing the ShieldLM-7B bypass rate from 12.5\% (Sneakyprompt) to 99.0\%, improving CLIP score from 0.2637 to 0.2762, and reducing the time cost by $4.2 \times$. Moreover, it generalizes to unseen filters including GPT-4.1 and successfully jailbreaks DALLE 3 to generate NSFW images in our evaluation, revealing systemic vulnerabilities in current multimodal defenses. To support further research on AI safety and red-teaming, we will release code and adversarial prompts under a controlled-access protocol.
Adversarially Robust CLIP Models Can Induce Better (Robust) Perceptual Metrics
Feb 17, 2025



Measuring perceptual similarity is a key tool in computer vision. In recent years perceptual metrics based on features extracted from neural networks with large and diverse training sets, e.g. CLIP, have become popular. At the same time, the metrics extracted from features of neural networks are not adversarially robust. In this paper we show that adversarially robust CLIP models, called R-CLIP$_\textrm{F}$, obtained by unsupervised adversarial fine-tuning induce a better and adversarially robust perceptual metric that outperforms existing metrics in a zero-shot setting, and further matches the performance of state-of-the-art metrics while being robust after fine-tuning. Moreover, our perceptual metric achieves strong performance on related tasks such as robust image-to-image retrieval, which becomes especially relevant when applied to "Not Safe for Work" (NSFW) content detection and dataset filtering. While standard perceptual metrics can be easily attacked by a small perturbation completely degrading NSFW detection, our robust perceptual metric maintains high accuracy under an attack while having similar performance for unperturbed images. Finally, perceptual metrics induced by robust CLIP models have higher interpretability: feature inversion can show which images are considered similar, while text inversion can find what images are associated to a given prompt. This also allows us to visualize the very rich visual concepts learned by a CLIP model, including memorized persons, paintings and complex queries.
CROPS: Model-Agnostic Training-Free Framework for Safe Image Synthesis with Latent Diffusion Models
Jan 09, 2025With advances in diffusion models, image generation has shown significant performance improvements. This raises concerns about the potential abuse of image generation, such as the creation of explicit or violent images, commonly referred to as Not Safe For Work (NSFW) content. To address this, the Stable Diffusion model includes several safety checkers to censor initial text prompts and final output images generated from the model. However, recent research has shown that these safety checkers have vulnerabilities against adversarial attacks, allowing them to generate NSFW images. In this paper, we find that these adversarial attacks are not robust to small changes in text prompts or input latents. Based on this, we propose CROPS (Circular or RandOm Prompts for Safety), a model-agnostic framework that easily defends against adversarial attacks generating NSFW images without requiring additional training. Moreover, we develop an approach that utilizes one-step diffusion models for efficient NSFW detection (CROPS-1), further reducing computational resources. We demonstrate the superiority of our method in terms of performance and applicability.
AEIOU: A Unified Defense Framework against NSFW Prompts in Text-to-Image Models
Dec 24, 2024



As text-to-image (T2I) models continue to advance and gain widespread adoption, their associated safety issues are becoming increasingly prominent. Malicious users often exploit these models to generate Not-Safe-for-Work (NSFW) images using harmful or adversarial prompts, highlighting the critical need for robust safeguards to ensure the integrity and compliance of model outputs. Current internal safeguards frequently degrade image quality, while external detection methods often suffer from low accuracy and inefficiency. In this paper, we introduce AEIOU, a defense framework that is Adaptable, Efficient, Interpretable, Optimizable, and Unified against NSFW prompts in T2I models. AEIOU extracts NSFW features from the hidden states of the model's text encoder, utilizing the separable nature of these features to detect NSFW prompts. The detection process is efficient, requiring minimal inference time. AEIOU also offers real-time interpretation of results and supports optimization through data augmentation techniques. The framework is versatile, accommodating various T2I architectures. Our extensive experiments show that AEIOU significantly outperforms both commercial and open-source moderation tools, achieving over 95% accuracy across all datasets and improving efficiency by at least tenfold. It effectively counters adaptive attacks and excels in few-shot and multi-label scenarios.
AdvI2I: Adversarial Image Attack on Image-to-Image Diffusion models
Oct 28, 2024
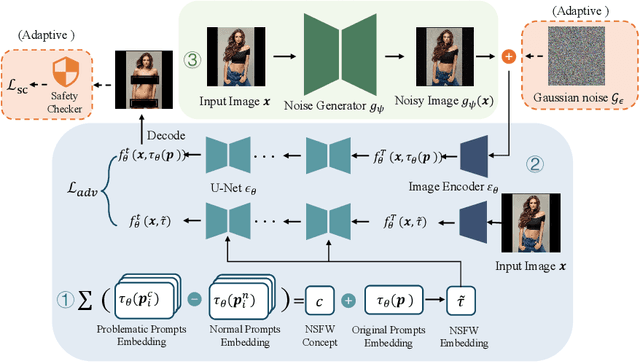


Recent advances in diffusion models have significantly enhanced the quality of image synthesis, yet they have also introduced serious safety concerns, particularly the generation of Not Safe for Work (NSFW) content. Previous research has demonstrated that adversarial prompts can be used to generate NSFW content. However, such adversarial text prompts are often easily detectable by text-based filters, limiting their efficacy. In this paper, we expose a previously overlooked vulnerability: adversarial image attacks targeting Image-to-Image (I2I) diffusion models. We propose AdvI2I, a novel framework that manipulates input images to induce diffusion models to generate NSFW content. By optimizing a generator to craft adversarial images, AdvI2I circumvents existing defense mechanisms, such as Safe Latent Diffusion (SLD), without altering the text prompts. Furthermore, we introduce AdvI2I-Adaptive, an enhanced version that adapts to potential countermeasures and minimizes the resemblance between adversarial images and NSFW concept embeddings, making the attack more resilient against defenses. Through extensive experiments, we demonstrate that both AdvI2I and AdvI2I-Adaptive can effectively bypass current safeguards, highlighting the urgent need for stronger security measures to address the misuse of I2I diffusion models.