 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Factual Opinions Be Edited (Manipulated) in Large Language Models?
Jun 02, 2026Large Language Models (LLMs) are increasingly integrated into various domains, making knowledge editing techniques crucial yet potentially hazardous. Current editing methods primarily target atomic facts, overlooking the significant risks associated with manipulating factual opinions, e.g., documented stances of public figures on societal issues. Such manipulation could reshape public images, influence elections, and alter societal views. To systematically assess this threat, we introduce the Factual Opinion Editing with Evidence (FOE) benchmark, which encompasses 261 public figures, 19 issue categories, and 2,178 complete opinion records. Our evaluations demonstrate that current editing techniques struggle significantly with factual opinions, often achieving only superficial changes while failing to preserve consistency between the edited opinion and the supporting evidence generated by the model. To address this limitation, we further propose a simple yet effective Self-Generated Evidence-Aligned method that achieves opinion-evidence alignment without relying on explicit instructions. Together, our benchmark and method provide a foundation for understanding the emerging security implications of factual opinion editing in LLMs.
ForecastCompass: Guiding Agentic Forecasting with Adaptive Factor Memory
May 29, 2026Agentic forecasting is important for decision-making in dynamic environments, but it remains challenging because agents must reason from incomplete, time-limited evidence and produce calibrated probabilities before outcomes are resolved. Memory provides a natural mechanism for transferring experience from resolved forecasts to future prediction tasks. However, existing agent-memory methods are not tailored to forecasting, as they typically store past interactions, reflections, or factual associations without explicitly representing reusable predictive factors or calibration knowledge. We propose ForecastCompass (FoCo), an adaptive factor-based memory framework for agentic forecasting. FoCo organizes forecasting experience with a hierarchical forecasting-task taxonomy, enabling retrieval task-relevant forecasting knowledge. It maintains two complementary memory components: factor memory, which captures reusable predictive dimensions, and reasoning memory, which encodes probability updating, uncertainty handling, and calibration principles. Using retrospective analyses as learning signals, FoCo iteratively revises memory through a verbalized memory-revision procedure, enabling the agent to accumulate transferable forecasting knowledge over time. Experiments on Prophet Arena and FutureX with GPT-5-mini and Gemini-2.5-Flash show that FoCo improves both probabilistic accuracy and calibration.
Restoring the Sweet Spot: Pass-Rate Weighted Self-Distillation for LLM Reasoning
May 26, 2026Self-Distillation Policy Optimization (SDPO) provides dense token-level credit assignment for reinforcement learning with large language models by leveraging the model's own feedback-conditioned predictions as a self-teacher. Unlike GRPO, however, whose group-relative advantage naturally concentrates learning on a sweet spot of intermediate-difficulty questions, SDPO's KL-based advantage lacks an implicit notion of difficulty awareness. We analyze this gap through the lens of GRPO's advantage normalization. Extending the learnability framework to normalized rewards, we show that normalization absorbs the variance term $p(1-p)$, equalizing leading-order learnability across questions and leaving $\sqrt{p(1-p)}$ as the sole residual scaling factor in the per-question gradient. This analysis yields a simple prescription: weight each question's SDPO loss by $[\hat{p}(1-\hat{p})]^{1/2}$, resulting in SC-SDPO, a scale-consistent variant of SDPO. The proposed weights are obtained as a zero-cost byproduct of on-policy rollouts with batch-adaptive normalization, inducing an implicit curriculum that dynamically tracks the model's evolving competence. Experiments on scientific reasoning and tool-use benchmarks demonstrate that SC-SDPO consistently improves over SDPO, yielding gains of +3.2/+4.3 (mean@16/maj@16) on Qwen3-8B and +1.8/+3.0 on OLMo-3-7B, while preserving stable training dynamics throughout optimization.
The Illusion of Reasoning: Exposing Evasive Data Contamination in LLMs via Zero-CoT Truncation
May 21, 2026Large language models (LLMs) have demonstrated impressive reasoning abilities across a wide range of tasks, but data contamination undermines the objective evaluation of these capabilities. This problem is further exacerbated by malicious model publishers who use evasive, or indirect, contamination strategies, such as paraphrasing benchmark data to evade existing detection methods and artificially boost leaderboard performance. Current approaches struggle to reliably detect such stealthy contamination. In this work, we uncover a critical phenomenon: a model's generated reasoning steps actively mask its underlying memorization. Inspired by this, we propose the Zero-CoT Probe (ZCP), a novel black-box detection method that deliberately truncates the entire Chain-of-Thought (CoT) process to expose latent shortcut mappings. To further isolate memorization from the model's intrinsic problem-solving capabilities, ZCP compares the model's zero-CoT performance on the original benchmark against an isomorphically perturbed reference dataset. Furthermore, we introduce Contamination Confidence, a metric that quantifies both the likelihood and severity of contamination, moving beyond simple binary classifications. Extensive experiments on both previously identified contaminated models and specially fine-tuned contaminated models demonstrate that ZCP robustly detects both direct and evasive data contamination. The code for ZCP is accessible at https://github.com/Yifan-Lan/zero-cot-probe.
PreFlect: From Retrospective to Prospective Reflection in Large Language Model Agents
Feb 06, 2026Advanced large language model agents typically adopt self-reflection for improving performance, where agents iteratively analyze past actions to correct errors. However, existing reflective approaches are inherently retrospective: agents act, observe failure, and only then attempt to recover. In this work, we introduce PreFlect, a prospective reflection mechanism that shifts the paradigm from post hoc correction to pre-execution foresight by criticizing and refining agent plans before execution. To support grounded prospective reflection, we distill planning errors from historical agent trajectories, capturing recurring success and failure patterns observed across past executions. Furthermore, we complement prospective reflection with a dynamic re-planning mechanism that provides execution-time plan update in case the original plan encounters unexpected deviation. Evaluations on different benchmarks demonstrate that PreFlect significantly improves overall agent utility on complex real-world tasks, outperforming strong reflection-based baselines and several more complex agent architectures. Code will be updated at https://github.com/wwwhy725/PreFlect.
Phi: Preference Hijacking in Multi-modal Large Language Models at Inference Time
Sep 15, 2025



Recently, Multimodal Large Language Models (MLLMs) have gained significant attention across various domains. However, their widespread adoption has also raised serious safety concerns. In this paper, we uncover a new safety risk of MLLMs: the output preference of MLLMs can be arbitrarily manipulated by carefully optimized images. Such attacks often generate contextually relevant yet biased responses that are neither overtly harmful nor unethical, making them difficult to detect. Specifically, we introduce a novel method, Preference Hijacking (Phi), for manipulating the MLLM response preferences using a preference hijacked image. Our method works at inference time and requires no model modifications. Additionally, we introduce a universal hijacking perturbation -- a transferable component that can be embedded into different images to hijack MLLM responses toward any attacker-specified preferences. Experimental results across various tasks demonstrate the effectiveness of our approach. The code for Phi is accessible at https://github.com/Yifan-Lan/Phi.
GuardDoor: Safeguarding Against Malicious Diffusion Editing via Protective Backdoors
Mar 05, 2025



The growing accessibility of diffusion models has revolutionized image editing but also raised significant concerns about unauthorized modifications, such as misinformation and plagiarism. Existing countermeasures largely rely on adversarial perturbations designed to disrupt diffusion model outputs. However, these approaches are found to be easily neutralized by simple image preprocessing techniques, such as compression and noise addition. To address this limitation, we propose GuardDoor, a novel and robust protection mechanism that fosters collaboration between image owners and model providers. Specifically, the model provider participating in the mechanism fine-tunes the image encoder to embed a protective backdoor, allowing image owners to request the attachment of imperceptible triggers to their images. When unauthorized users attempt to edit these protected images with this diffusion model, the model produces meaningless outputs, reducing the risk of malicious image editing. Our method demonstrates enhanced robustness against image preprocessing operations and is scalable for large-scale deployment. This work underscores the potential of cooperative frameworks between model providers and image owners to safeguard digital content in the era of generative AI.
TruthFlow: Truthful LLM Generation via Representation Flow Correction
Feb 06, 2025



Large language models (LLMs) are known to struggle with consistently generating truthful responses. While various representation intervention techniques have been proposed, these methods typically apply a universal representation correction vector to all input queries, limiting their effectiveness against diverse queries in practice. In this study, we introduce TruthFlow, a novel method that leverages the Flow Matching technique for query-specific truthful representation correction. Specifically, TruthFlow first uses a flow model to learn query-specific correction vectors that transition representations from hallucinated to truthful states. Then, during inference, the trained flow model generates these correction vectors to enhance the truthfulness of LLM outputs. Experimental results demonstrate that TruthFlow significantly improves performance on open-ended generation tasks across various advanced LLMs evaluated on TruthfulQA. Moreover, the trained TruthFlow model exhibits strong transferability, performing effectively on other unseen hallucination benchmarks.
AdvI2I: Adversarial Image Attack on Image-to-Image Diffusion models
Oct 28, 2024
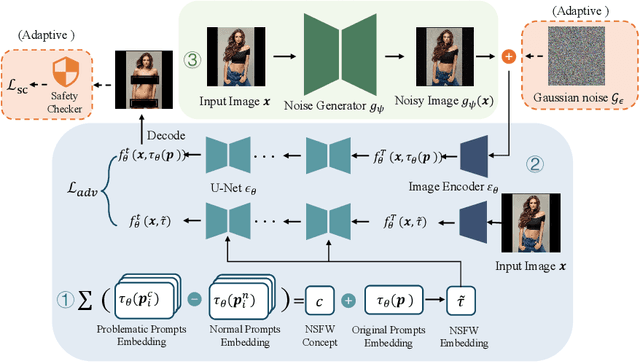


Recent advances in diffusion models have significantly enhanced the quality of image synthesis, yet they have also introduced serious safety concerns, particularly the generation of Not Safe for Work (NSFW) content. Previous research has demonstrated that adversarial prompts can be used to generate NSFW content. However, such adversarial text prompts are often easily detectable by text-based filters, limiting their efficacy. In this paper, we expose a previously overlooked vulnerability: adversarial image attacks targeting Image-to-Image (I2I) diffusion models. We propose AdvI2I, a novel framework that manipulates input images to induce diffusion models to generate NSFW content. By optimizing a generator to craft adversarial images, AdvI2I circumvents existing defense mechanisms, such as Safe Latent Diffusion (SLD), without altering the text prompts. Furthermore, we introduce AdvI2I-Adaptive, an enhanced version that adapts to potential countermeasures and minimizes the resemblance between adversarial images and NSFW concept embeddings, making the attack more resilient against defenses. Through extensive experiments, we demonstrate that both AdvI2I and AdvI2I-Adaptive can effectively bypass current safeguards, highlighting the urgent need for stronger security measures to address the misuse of I2I diffusion models.
Adversarially Robust Industrial Anomaly Detection Through Diffusion Model
Aug 09, 2024



Deep learning-based industrial anomaly detection models have achieved remarkably high accuracy on commonly used benchmark datasets. However, the robustness of those models may not be satisfactory due to the existence of adversarial examples, which pose significant threats to the practical deployment of deep anomaly detectors. Recently, it has been shown that diffusion models can be used to purify the adversarial noises and thus build a robust classifier against adversarial attacks. Unfortunately, we found that naively applying this strategy in anomaly detection (i.e., placing a purifier before an anomaly detector) will suffer from a high anomaly miss rate since the purifying process can easily remove both the anomaly signal and the adversarial perturbations, causing the later anomaly detector failed to detect anomalies. To tackle this issue, we explore the possibility of performing anomaly detection and adversarial purification simultaneously. We propose a simple yet effective adversarially robust anomaly detection method, \textit{AdvRAD}, that allows the diffusion model to act both as an anomaly detector and adversarial purifier. We also extend our proposed method for certified robustness to $l_2$ norm bounded perturbations. Through extensive experiments, we show that our proposed method exhibits outstanding (certified) adversarial robustness while also maintaining equally strong anomaly detection performance on par with the state-of-the-art methods on industrial anomaly detection benchmark datasets.