 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMusic Emotion Recognition
Papers and Code
Memo2496: Expert-Annotated Dataset and Dual-View Adaptive Framework for Music Emotion Recognition
Dec 17, 2025
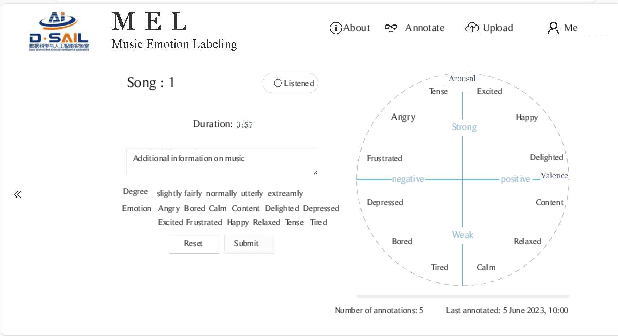
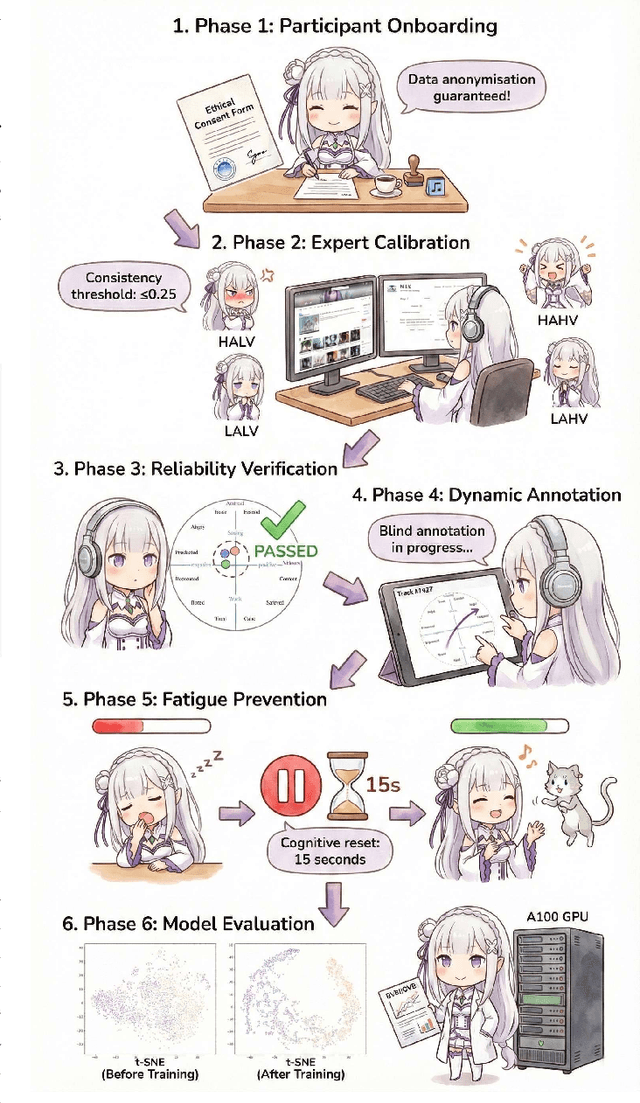
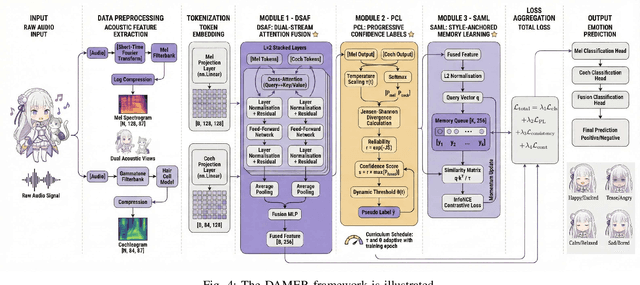
Music Emotion Recogniser (MER) research faces challenges due to limited high-quality annotated datasets and difficulties in addressing cross-track feature drift. This work presents two primary contributions to address these issues. Memo2496, a large-scale dataset, offers 2496 instrumental music tracks with continuous valence arousal labels, annotated by 30 certified music specialists. Annotation quality is ensured through calibration with extreme emotion exemplars and a consistency threshold of 0.25, measured by Euclidean distance in the valence arousal space. Furthermore, the Dual-view Adaptive Music Emotion Recogniser (DAMER) is introduced. DAMER integrates three synergistic modules: Dual Stream Attention Fusion (DSAF) facilitates token-level bidirectional interaction between Mel spectrograms and cochleagrams via cross attention mechanisms; Progressive Confidence Labelling (PCL) generates reliable pseudo labels employing curriculum-based temperature scheduling and consistency quantification using Jensen Shannon divergence; and Style Anchored Memory Learning (SAML) maintains a contrastive memory queue to mitigate cross-track feature drift. Extensive experiments on the Memo2496, 1000songs, and PMEmo datasets demonstrate DAMER's state-of-the-art performance, improving arousal dimension accuracy by 3.43%, 2.25%, and 0.17%, respectively. Ablation studies and visualisation analyses validate each module's contribution. Both the dataset and source code are publicly available.
Let the Model Learn to Feel: Mode-Guided Tonality Injection for Symbolic Music Emotion Recognition
Dec 15, 2025Music emotion recognition is a key task in symbolic music understanding (SMER). Recent approaches have shown promising results by fine-tuning large-scale pre-trained models (e.g., MIDIBERT, a benchmark in symbolic music understanding) to map musical semantics to emotional labels. While these models effectively capture distributional musical semantics, they often overlook tonal structures, particularly musical modes, which play a critical role in emotional perception according to music psychology. In this paper, we investigate the representational capacity of MIDIBERT and identify its limitations in capturing mode-emotion associations. To address this issue, we propose a Mode-Guided Enhancement (MoGE) strategy that incorporates psychological insights on mode into the model. Specifically, we first conduct a mode augmentation analysis, which reveals that MIDIBERT fails to effectively encode emotion-mode correlations. We then identify the least emotion-relevant layer within MIDIBERT and introduce a Mode-guided Feature-wise linear modulation injection (MoFi) framework to inject explicit mode features, thereby enhancing the model's capability in emotional representation and inference. Extensive experiments on the EMOPIA and VGMIDI datasets demonstrate that our mode injection strategy significantly improves SMER performance, achieving accuracies of 75.2% and 59.1%, respectively. These results validate the effectiveness of mode-guided modeling in symbolic music emotion recognition.
MPJudge: Towards Perceptual Assessment of Music-Induced Paintings
Nov 10, 2025Music induced painting is a unique artistic practice, where visual artworks are created under the influence of music. Evaluating whether a painting faithfully reflects the music that inspired it poses a challenging perceptual assessment task. Existing methods primarily rely on emotion recognition models to assess the similarity between music and painting, but such models introduce considerable noise and overlook broader perceptual cues beyond emotion. To address these limitations, we propose a novel framework for music induced painting assessment that directly models perceptual coherence between music and visual art. We introduce MPD, the first large scale dataset of music painting pairs annotated by domain experts based on perceptual coherence. To better handle ambiguous cases, we further collect pairwise preference annotations. Building on this dataset, we present MPJudge, a model that integrates music features into a visual encoder via a modulation based fusion mechanism. To effectively learn from ambiguous cases, we adopt Direct Preference Optimization for training. Extensive experiments demonstrate that our method outperforms existing approaches. Qualitative results further show that our model more accurately identifies music relevant regions in paintings.
A Study on the Data Distribution Gap in Music Emotion Recognition
Oct 06, 2025



Music Emotion Recognition (MER) is a task deeply connected to human perception, relying heavily on subjective annotations collected from contributors. Prior studies tend to focus on specific musical styles rather than incorporating a diverse range of genres, such as rock and classical, within a single framework. In this paper, we address the task of recognizing emotion from audio content by investigating five datasets with dimensional emotion annotations -- EmoMusic, DEAM, PMEmo, WTC, and WCMED -- which span various musical styles. We demonstrate the problem of out-of-distribution generalization in a systematic experiment. By closely looking at multiple data and feature sets, we provide insight into genre-emotion relationships in existing data and examine potential genre dominance and dataset biases in certain feature representations. Based on these experiments, we arrive at a simple yet effective framework that combines embeddings extracted from the Jukebox model with chroma features and demonstrate how, alongside a combination of several diverse training sets, this permits us to train models with substantially improved cross-dataset generalization capabilities.
Preference-Based Learning in Audio Applications: A Systematic Analysis
Nov 17, 2025



Despite the parallel challenges that audio and text domains face in evaluating generative model outputs, preference learning remains remarkably underexplored in audio applications. Through a PRISMA-guided systematic review of approximately 500 papers, we find that only 30 (6%) apply preference learning to audio tasks. Our analysis reveals a field in transition: pre-2021 works focused on emotion recognition using traditional ranking methods (rankSVM), while post-2021 studies have pivoted toward generation tasks employing modern RLHF frameworks. We identify three critical patterns: (1) the emergence of multi-dimensional evaluation strategies combining synthetic, automated, and human preferences; (2) inconsistent alignment between traditional metrics (WER, PESQ) and human judgments across different contexts; and (3) convergence on multi-stage training pipelines that combine reward signals. Our findings suggest that while preference learning shows promise for audio, particularly in capturing subjective qualities like naturalness and musicality, the field requires standardized benchmarks, higher-quality datasets, and systematic investigation of how temporal factors unique to audio impact preference learning frameworks.
EmoHeal: An End-to-End System for Personalized Therapeutic Music Retrieval from Fine-grained Emotions
Sep 19, 2025



Existing digital mental wellness tools often overlook the nuanced emotional states underlying everyday challenges. For example, pre-sleep anxiety affects more than 1.5 billion people worldwide, yet current approaches remain largely static and "one-size-fits-all", failing to adapt to individual needs. In this work, we present EmoHeal, an end-to-end system that delivers personalized, three-stage supportive narratives. EmoHeal detects 27 fine-grained emotions from user text with a fine-tuned XLM-RoBERTa model, mapping them to musical parameters via a knowledge graph grounded in music therapy principles (GEMS, iso-principle). EmoHeal retrieves audiovisual content using the CLAMP3 model to guide users from their current state toward a calmer one ("match-guide-target"). A within-subjects study (N=40) demonstrated significant supportive effects, with participants reporting substantial mood improvement (M=4.12, p<0.001) and high perceived emotion recognition accuracy (M=4.05, p<0.001). A strong correlation between perceived accuracy and therapeutic outcome (r=0.72, p<0.001) validates our fine-grained approach. These findings establish the viability of theory-driven, emotion-aware digital wellness tools and provides a scalable AI blueprint for operationalizing music therapy principles.
A Trustworthy Method for Multimodal Emotion Recognition
Aug 11, 2025Existing emotion recognition methods mainly focus on enhancing performance by employing complex deep models, typically resulting in significantly higher model complexity. Although effective, it is also crucial to ensure the reliability of the final decision, especially for noisy, corrupted and out-of-distribution data. To this end, we propose a novel emotion recognition method called trusted emotion recognition (TER), which utilizes uncertainty estimation to calculate the confidence value of predictions. TER combines the results from multiple modalities based on their confidence values to output the trusted predictions. We also provide a new evaluation criterion to assess the reliability of predictions. Specifically, we incorporate trusted precision and trusted recall to determine the trusted threshold and formulate the trusted Acc. and trusted F1 score to evaluate the model's trusted performance. The proposed framework combines the confidence module that accordingly endows the model with reliability and robustness against possible noise or corruption. The extensive experimental results validate the effectiveness of our proposed model. The TER achieves state-of-the-art performance on the Music-video, achieving 82.40% Acc. In terms of trusted performance, TER outperforms other methods on the IEMOCAP and Music-video, achieving trusted F1 scores of 0.7511 and 0.9035, respectively.
A Survey on Multimodal Music Emotion Recognition
Apr 26, 2025Multimodal music emotion recognition (MMER) is an emerging discipline in music information retrieval that has experienced a surge in interest in recent years. This survey provides a comprehensive overview of the current state-of-the-art in MMER. Discussing the different approaches and techniques used in this field, the paper introduces a four-stage MMER framework, including multimodal data selection, feature extraction, feature processing, and final emotion prediction. The survey further reveals significant advancements in deep learning methods and the increasing importance of feature fusion techniques. Despite these advancements, challenges such as the need for large annotated datasets, datasets with more modalities, and real-time processing capabilities remain. This paper also contributes to the field by identifying critical gaps in current research and suggesting potential directions for future research. The gaps underscore the importance of developing robust, scalable, a interpretable models for MMER, with implications for applications in music recommendation systems, therapeutic tools, and entertainment.
GlobalMood: A cross-cultural benchmark for music emotion recognition
May 14, 2025Human annotations of mood in music are essential for music generation and recommender systems. However, existing datasets predominantly focus on Western songs with mood terms derived from English, which may limit generalizability across diverse linguistic and cultural backgrounds. To address this, we introduce `GlobalMood', a novel cross-cultural benchmark dataset comprising 1,180 songs sampled from 59 countries, with large-scale annotations collected from 2,519 individuals across five culturally and linguistically distinct locations: U.S., France, Mexico, S. Korea, and Egypt. Rather than imposing predefined mood categories, we implement a bottom-up, participant-driven approach to organically elicit culturally specific music-related mood terms. We then recruit another pool of human participants to collect 988,925 ratings for these culture-specific descriptors. Our analysis confirms the presence of a valence-arousal structure shared across cultures, yet also reveals significant divergences in how certain mood terms, despite being dictionary equivalents, are perceived cross-culturally. State-of-the-art multimodal models benefit substantially from fine-tuning on our cross-culturally balanced dataset, as evidenced by improved alignment with human evaluations - particularly in non-English contexts. More broadly, our findings inform the ongoing debate on the universality versus cultural specificity of emotional descriptors, and our methodology can contribute to other multimodal and cross-lingual research.
CMI-Bench: A Comprehensive Benchmark for Evaluating Music Instruction Following
Jun 14, 2025Recent advances in audio-text large language models (LLMs) have opened new possibilities for music understanding and generation. However, existing benchmarks are limited in scope, often relying on simplified tasks or multi-choice evaluations that fail to reflect the complexity of real-world music analysis. We reinterpret a broad range of traditional MIR annotations as instruction-following formats and introduce CMI-Bench, a comprehensive music instruction following benchmark designed to evaluate audio-text LLMs on a diverse set of music information retrieval (MIR) tasks. These include genre classification, emotion regression, emotion tagging, instrument classification, pitch estimation, key detection, lyrics transcription, melody extraction, vocal technique recognition, instrument performance technique detection, music tagging, music captioning, and (down)beat tracking: reflecting core challenges in MIR research. Unlike previous benchmarks, CMI-Bench adopts standardized evaluation metrics consistent with previous state-of-the-art MIR models, ensuring direct comparability with supervised approaches. We provide an evaluation toolkit supporting all open-source audio-textual LLMs, including LTU, Qwen-audio, SALMONN, MusiLingo, etc. Experiment results reveal significant performance gaps between LLMs and supervised models, along with their culture, chronological and gender bias, highlighting the potential and limitations of current models in addressing MIR tasks. CMI-Bench establishes a unified foundation for evaluating music instruction following, driving progress in music-aware LLMs.