 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlobalMood: A cross-cultural benchmark for music emotion recognition
May 14, 2025


Human annotations of mood in music are essential for music generation and recommender systems. However, existing datasets predominantly focus on Western songs with mood terms derived from English, which may limit generalizability across diverse linguistic and cultural backgrounds. To address this, we introduce `GlobalMood', a novel cross-cultural benchmark dataset comprising 1,180 songs sampled from 59 countries, with large-scale annotations collected from 2,519 individuals across five culturally and linguistically distinct locations: U.S., France, Mexico, S. Korea, and Egypt. Rather than imposing predefined mood categories, we implement a bottom-up, participant-driven approach to organically elicit culturally specific music-related mood terms. We then recruit another pool of human participants to collect 988,925 ratings for these culture-specific descriptors. Our analysis confirms the presence of a valence-arousal structure shared across cultures, yet also reveals significant divergences in how certain mood terms, despite being dictionary equivalents, are perceived cross-culturally. State-of-the-art multimodal models benefit substantially from fine-tuning on our cross-culturally balanced dataset, as evidenced by improved alignment with human evaluations - particularly in non-English contexts. More broadly, our findings inform the ongoing debate on the universality versus cultural specificity of emotional descriptors, and our methodology can contribute to other multimodal and cross-lingual research.
Gibbs Sampling with People
Aug 06, 2020
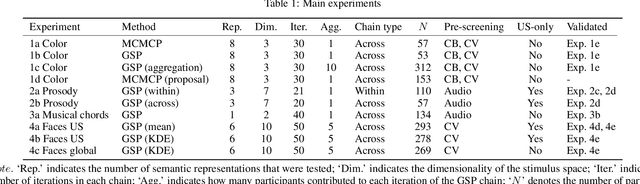
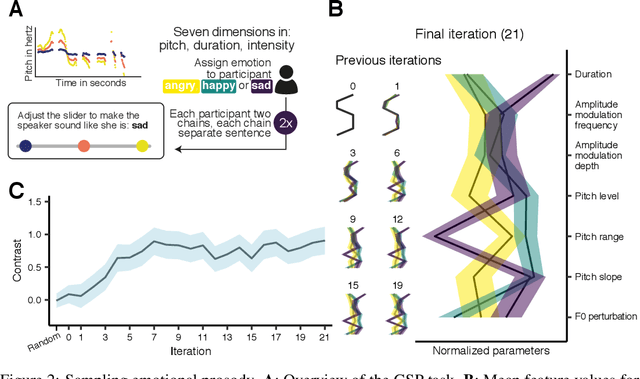
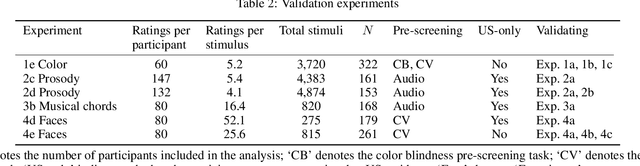
A core problem in cognitive science and machine learning is to understand how humans derive semantic representations from perceptual objects, such as color from an apple, pleasantness from a musical chord, or trustworthiness from a face. Markov Chain Monte Carlo with People (MCMCP) is a prominent method for studying such representations, in which participants are presented with binary choice trials constructed such that the decisions follow a Markov Chain Monte Carlo acceptance rule. However, MCMCP's binary choice paradigm generates relatively little information per trial, and its local proposal function makes it slow to explore the parameter space and find the modes of the distribution. Here we therefore generalize MCMCP to a continuous-sampling paradigm, where in each iteration the participant uses a slider to continuously manipulate a single stimulus dimension to optimize a given criterion such as 'pleasantness'. We formulate both methods from a utility-theory perspective, and show that the new method can be interpreted as 'Gibbs Sampling with People' (GSP). Further, we introduce an aggregation parameter to the transition step, and show that this parameter can be manipulated to flexibly shift between Gibbs sampling and deterministic optimization. In an initial study, we show GSP clearly outperforming MCMCP; we then show that GSP provides novel and interpretable results in three other domains, namely musical chords, vocal emotions, and faces. We validate these results through large-scale perceptual rating experiments. The final experiments combine GSP with a state-of-the-art image synthesis network (StyleGAN) and a recent network interpretability technique (GANSpace), enabling GSP to efficiently explore high-dimensional perceptual spaces, and demonstrating how GSP can be a powerful tool for jointly characterizing semantic representations in humans and machines.