 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti Hop Reading Comprehension
Papers and Code
LongTraceRL: Learning Long-Context Reasoning from Search Agent Trajectories with Rubric Rewards
May 29, 2026Long-context reasoning remains a central challenge for large language models, which often fail to locate and integrate key information in extensive distracting content. Reinforcement learning with verifiable rewards (RLVR) has shown promise for this task, yet existing methods are limited by low-confusability distractors and sparse, outcome-only reward signals that cannot supervise intermediate reasoning steps. To address these issues, we introduce \textsc{LongTraceRL}. For data construction, we generate multi-hop questions via knowledge graph random walks and leverage search agent trajectories to build \emph{tiered distractors}: documents the agent read but did not cite (high confusability) and documents that appeared in search results but were never opened (low confusability), producing training contexts that are far more challenging than those built by random sampling or one-shot search. For reward design, we propose a \emph{rubric reward} that uses the gold entities along each reasoning chain as fine-grained, entity-level process supervision. This rubric reward is applied only to responses with correct final answers (positive-only strategy), distinguishing the reasoning quality among correct responses and preventing reward hacking. Experiments on three reasoning LLMs (4B--30B) across five long-context benchmarks demonstrate that \textsc{LongTraceRL} consistently outperforms strong baselines and encourages comprehensive, evidence-grounded reasoning. Codes, datasets and models are available at \href{https://github.com/THU-KEG/LongTraceRL}{https://github.com/THU-KEG/LongTraceRL}.
Automatic Inter-document Multi-hop Scientific QA Generation
Mar 15, 2026Existing automatic scientific question generation studies mainly focus on single-document factoid QA, overlooking the inter-document reasoning crucial for scientific understanding. We present AIM-SciQA, an automated framework for generating multi-document, multi-hop scientific QA datasets. AIM-SciQA extracts single-hop QAs using large language models (LLMs) with machine reading comprehension and constructs cross-document relations based on embedding-based semantic alignment while selectively leveraging citation information. Applied to 8,211 PubMed Central papers, it produced 411,409 single-hop and 13,672 multi-hop QAs, forming the IM-SciQA dataset. Human and automatic validation confirmed high factual consistency, and experimental results demonstrate that IM-SciQA effectively differentiates reasoning capabilities across retrieval and QA stages, providing a realistic and interpretable benchmark for retrieval-augmented scientific reasoning. We further extend this framework to construct CIM-SciQA, a citation-guided variant achieving comparable performance to the Oracle setting, reinforcing the dataset's validity and generality.
T2S-Bench & Structure-of-Thought: Benchmarking and Prompting Comprehensive Text-to-Structure Reasoning
Mar 04, 2026Think about how human handles complex reading tasks: marking key points, inferring their relationships, and structuring information to guide understanding and responses. Likewise, can a large language model benefit from text structure to enhance text-processing performance? To explore it, in this work, we first introduce Structure of Thought (SoT), a prompting technique that explicitly guides models to construct intermediate text structures, consistently boosting performance across eight tasks and three model families. Building upon this insight, we present T2S-Bench, the first benchmark designed to evaluate and improve text-to-structure capabilities of models. T2S-Bench includes 1.8K samples across 6 scientific domains and 32 structural types, rigorously constructed to ensure accuracy, fairness, and quality. Evaluation on 45 mainstream models reveals substantial improvement potential: the average accuracy on the multi-hop reasoning task is only 52.1%, and even the most advanced model achieves 58.1% node accuracy in end-to-end extraction. Furthermore, on Qwen2.5-7B-Instruct, SoT alone yields an average +5.7% improvement across eight diverse text-processing tasks, and fine-tuning on T2S-Bench further increases this gain to +8.6%. These results highlight the value of explicit text structuring and the complementary contributions of SoT and T2S-Bench. Dataset and eval code have been released at https://t2s-bench.github.io/T2S-Bench-Page/.
Synthesize-on-Graph: Knowledgeable Synthetic Data Generation for Continue Pre-training of Large Language Models
May 02, 2025



Large Language Models (LLMs) have achieved remarkable success but remain data-inefficient, especially when learning from small, specialized corpora with limited and proprietary data. Existing synthetic data generation methods for continue pre-training focus on intra-document content and overlook cross-document knowledge associations, limiting content diversity and depth. We propose Synthetic-on-Graph (SoG), a synthetic data generation framework that incorporates cross-document knowledge associations for efficient corpus expansion. SoG constructs a context graph by extracting entities and concepts from the original corpus, representing cross-document associations, and employing a graph walk strategy for knowledge-associated sampling. This enhances synthetic data diversity and coherence, enabling models to learn complex knowledge structures and handle rare knowledge. To further improve synthetic data quality, we integrate Chain-of-Thought (CoT) and Contrastive Clarifying (CC) synthetic, enhancing reasoning processes and discriminative power. Experiments show that SoG outperforms the state-of-the-art (SOTA) method in a multi-hop document Q&A dataset while performing comparably to the SOTA method on the reading comprehension task datasets, which also underscores the better generalization capability of SoG. Our work advances synthetic data generation and provides practical solutions for efficient knowledge acquisition in LLMs, especially in domains with limited data availability.
Zero-Shot Complex Question-Answering on Long Scientific Documents
Mar 04, 2025With the rapid development in Transformer-based language models, the reading comprehension tasks on short documents and simple questions have been largely addressed. Long documents, specifically the scientific documents that are densely packed with knowledge discovered and developed by humans, remain relatively unexplored. These documents often come with a set of complex and more realistic questions, adding to their complexity. We present a zero-shot pipeline framework that enables social science researchers to perform question-answering tasks that are complex yet of predetermined question formats on full-length research papers without requiring machine learning expertise. Our approach integrates pre-trained language models to handle challenging scenarios including multi-span extraction, multi-hop reasoning, and long-answer generation. Evaluating on MLPsych, a novel dataset of social psychology papers with annotated complex questions, we demonstrate that our framework achieves strong performance through combination of extractive and generative models. This work advances document understanding capabilities for social sciences while providing practical tools for researchers.
Seemingly Plausible Distractors in Multi-Hop Reasoning: Are Large Language Models Attentive Readers?
Sep 08, 2024State-of-the-art Large Language Models (LLMs) are accredited with an increasing number of different capabilities, ranging from reading comprehension, over advanced mathematical and reasoning skills to possessing scientific knowledge. In this paper we focus on their multi-hop reasoning capability: the ability to identify and integrate information from multiple textual sources. Given the concerns with the presence of simplifying cues in existing multi-hop reasoning benchmarks, which allow models to circumvent the reasoning requirement, we set out to investigate, whether LLMs are prone to exploiting such simplifying cues. We find evidence that they indeed circumvent the requirement to perform multi-hop reasoning, but they do so in more subtle ways than what was reported about their fine-tuned pre-trained language model (PLM) predecessors. Motivated by this finding, we propose a challenging multi-hop reasoning benchmark, by generating seemingly plausible multi-hop reasoning chains, which ultimately lead to incorrect answers. We evaluate multiple open and proprietary state-of-the-art LLMs, and find that their performance to perform multi-hop reasoning is affected, as indicated by up to 45% relative decrease in F1 score when presented with such seemingly plausible alternatives. We conduct a deeper analysis and find evidence that while LLMs tend to ignore misleading lexical cues, misleading reasoning paths indeed present a significant challenge.
Adaptive Question Answering: Enhancing Language Model Proficiency for Addressing Knowledge Conflicts with Source Citations
Oct 05, 2024



Resolving knowledge conflicts is a crucial challenge in Question Answering (QA) tasks, as the internet contains numerous conflicting facts and opinions. While some research has made progress in tackling ambiguous settings where multiple valid answers exist, these approaches often neglect to provide source citations, leaving users to evaluate the factuality of each answer. On the other hand, existing work on citation generation has focused on unambiguous settings with single answers, failing to address the complexity of real-world scenarios. Despite the importance of both aspects, no prior research has combined them, leaving a significant gap in the development of QA systems. In this work, we bridge this gap by proposing the novel task of QA with source citation in ambiguous settings, where multiple valid answers exist. To facilitate research in this area, we create a comprehensive framework consisting of: (1) five novel datasets, obtained by augmenting three existing reading comprehension datasets with citation meta-data across various ambiguous settings, such as distractors and paraphrasing; (2) the first ambiguous multi-hop QA dataset featuring real-world, naturally occurring contexts; (3) two new metrics to evaluate models' performances; and (4) several strong baselines using rule-based, prompting, and finetuning approaches over five large language models. We hope that this new task, datasets, metrics, and baselines will inspire the community to push the boundaries of QA research and develop more trustworthy and interpretable systems.
A Comprehensive Survey on Multi-hop Machine Reading Comprehension Datasets and Metrics
Dec 08, 2022



Multi-hop Machine reading comprehension is a challenging task with aim of answering a question based on disjoint pieces of information across the different passages. The evaluation metrics and datasets are a vital part of multi-hop MRC because it is not possible to train and evaluate models without them, also, the proposed challenges by datasets often are an important motivation for improving the existing models. Due to increasing attention to this field, it is necessary and worth reviewing them in detail. This study aims to present a comprehensive survey on recent advances in multi-hop MRC evaluation metrics and datasets. In this regard, first, the multi-hop MRC problem definition will be presented, then the evaluation metrics based on their multi-hop aspect will be investigated. Also, 15 multi-hop datasets have been reviewed in detail from 2017 to 2022, and a comprehensive analysis has been prepared at the end. Finally, open issues in this field have been discussed.
A Comprehensive Survey on Multi-hop Machine Reading Comprehension Approaches
Dec 08, 2022



Machine reading comprehension (MRC) is a long-standing topic in natural language processing (NLP). The MRC task aims to answer a question based on the given context. Recently studies focus on multi-hop MRC which is a more challenging extension of MRC, which to answer a question some disjoint pieces of information across the context are required. Due to the complexity and importance of multi-hop MRC, a large number of studies have been focused on this topic in recent years, therefore, it is necessary and worth reviewing the related literature. This study aims to investigate recent advances in the multi-hop MRC approaches based on 31 studies from 2018 to 2022. In this regard, first, the multi-hop MRC problem definition will be introduced, then 31 models will be reviewed in detail with a strong focus on their multi-hop aspects. They also will be categorized based on their main techniques. Finally, a fine-grain comprehensive comparison of the models and techniques will be presented.
How Well Do Multi-hop Reading Comprehension Models Understand Date Information?
Oct 11, 2022

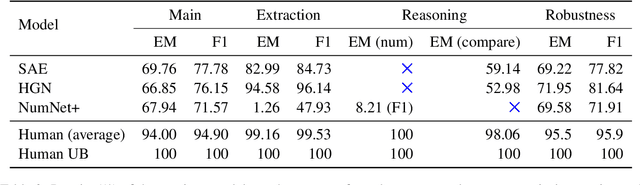

Several multi-hop reading comprehension datasets have been proposed to resolve the issue of reasoning shortcuts by which questions can be answered without performing multi-hop reasoning. However, the ability of multi-hop models to perform step-by-step reasoning when finding an answer to a comparison question remains unclear. It is also unclear how questions about the internal reasoning process are useful for training and evaluating question-answering (QA) systems. To evaluate the model precisely in a hierarchical manner, we first propose a dataset, \textit{HieraDate}, with three probing tasks in addition to the main question: extraction, reasoning, and robustness. Our dataset is created by enhancing two previous multi-hop datasets, HotpotQA and 2WikiMultiHopQA, focusing on multi-hop questions on date information that involve both comparison and numerical reasoning. We then evaluate the ability of existing models to understand date information. Our experimental results reveal that the multi-hop models do not have the ability to subtract two dates even when they perform well in date comparison and number subtraction tasks. Other results reveal that our probing questions can help to improve the performance of the models (e.g., by +10.3 F1) on the main QA task and our dataset can be used for data augmentation to improve the robustness of the models.