 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comprehensive Survey on Multi-hop Machine Reading Comprehension Approaches
Dec 08, 2022



Machine reading comprehension (MRC) is a long-standing topic in natural language processing (NLP). The MRC task aims to answer a question based on the given context. Recently studies focus on multi-hop MRC which is a more challenging extension of MRC, which to answer a question some disjoint pieces of information across the context are required. Due to the complexity and importance of multi-hop MRC, a large number of studies have been focused on this topic in recent years, therefore, it is necessary and worth reviewing the related literature. This study aims to investigate recent advances in the multi-hop MRC approaches based on 31 studies from 2018 to 2022. In this regard, first, the multi-hop MRC problem definition will be introduced, then 31 models will be reviewed in detail with a strong focus on their multi-hop aspects. They also will be categorized based on their main techniques. Finally, a fine-grain comprehensive comparison of the models and techniques will be presented.
A Comprehensive Survey on Multi-hop Machine Reading Comprehension Datasets and Metrics
Dec 08, 2022



Multi-hop Machine reading comprehension is a challenging task with aim of answering a question based on disjoint pieces of information across the different passages. The evaluation metrics and datasets are a vital part of multi-hop MRC because it is not possible to train and evaluate models without them, also, the proposed challenges by datasets often are an important motivation for improving the existing models. Due to increasing attention to this field, it is necessary and worth reviewing them in detail. This study aims to present a comprehensive survey on recent advances in multi-hop MRC evaluation metrics and datasets. In this regard, first, the multi-hop MRC problem definition will be presented, then the evaluation metrics based on their multi-hop aspect will be investigated. Also, 15 multi-hop datasets have been reviewed in detail from 2017 to 2022, and a comprehensive analysis has been prepared at the end. Finally, open issues in this field have been discussed.
Improving Persian Document Classification Using Semantic Relations between Words
Dec 28, 2014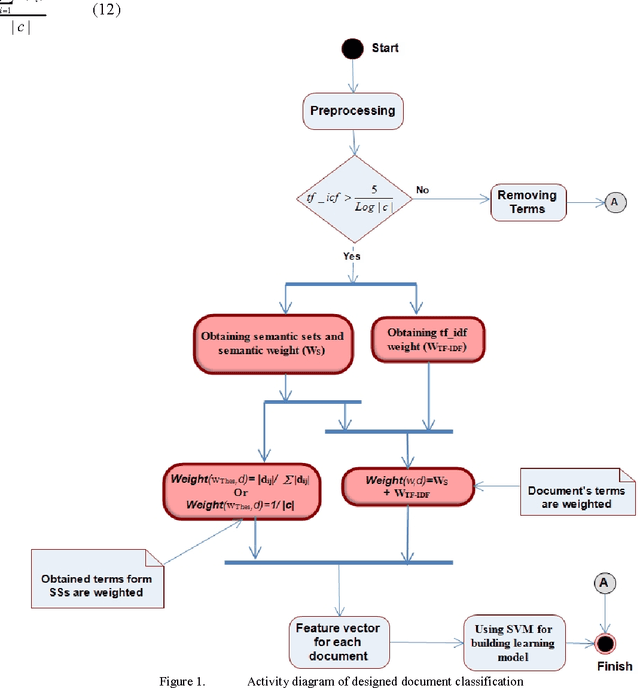
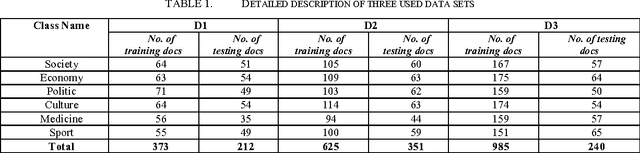

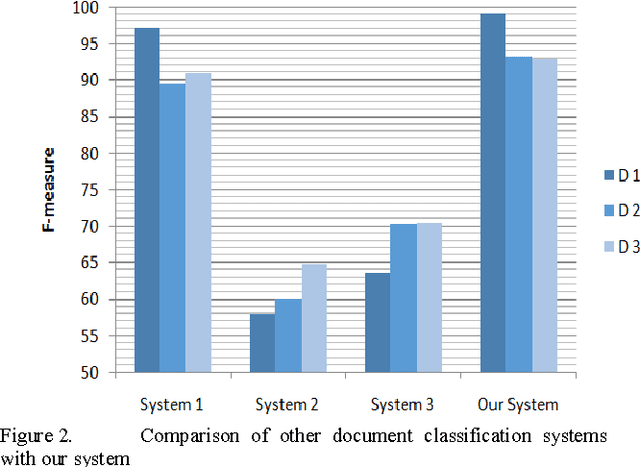
With the increase of information, document classification as one of the methods of text mining, plays vital role in many management and organizing information. Document classification is the process of assigning a document to one or more predefined category labels. Document classification includes different parts such as text processing, term selection, term weighting and final classification. The accuracy of document classification is very important. Thus improvement in each part of classification should lead to better results and higher precision. Term weighting has a great impact on the accuracy of the classification. Most of the existing weighting methods exploit the statistical information of terms in documents and do not consider semantic relations between words. In this paper, an automated document classification system is presented that uses a novel term weighting method based on semantic relations between terms. To evaluate the proposed method, three standard Persian corpuses are used. Experiment results show 2 to 4 percent improvement in classification accuracy compared with the best previous designed system for Persian documents.