 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvoice Data Extraction
Papers and Code
DataCross: A Unified Benchmark and Agent Framework for Cross-Modal Heterogeneous Data Analysis
Jan 29, 2026In real-world data science and enterprise decision-making, critical information is often fragmented across directly queryable structured sources (e.g., SQL, CSV) and "zombie data" locked in unstructured visual documents (e.g., scanned reports, invoice images). Existing data analytics agents are predominantly limited to processing structured data, failing to activate and correlate this high-value visual information, thus creating a significant gap with industrial needs. To bridge this gap, we introduce DataCross, a novel benchmark and collaborative agent framework for unified, insight-driven analysis across heterogeneous data modalities. DataCrossBench comprises 200 end-to-end analysis tasks across finance, healthcare, and other domains. It is constructed via a human-in-the-loop reverse-synthesis pipeline, ensuring realistic complexity, cross-source dependency, and verifiable ground truth. The benchmark categorizes tasks into three difficulty tiers to evaluate agents' capabilities in visual table extraction, cross-modal alignment, and multi-step joint reasoning. We also propose the DataCrossAgent framework, inspired by the "divide-and-conquer" workflow of human analysts. It employs specialized sub-agents, each an expert on a specific data source, which are coordinated via a structured workflow of Intra-source Deep Exploration, Key Source Identification, and Contextual Cross-pollination. A novel reReAct mechanism enables robust code generation and debugging for factual verification. Experimental results show that DataCrossAgent achieves a 29.7% improvement in factuality over GPT-4o and exhibits superior robustness on high-difficulty tasks, effectively activating fragmented "zombie data" for insightful, cross-modal analysis.
A Hybrid Architecture for Multi-Stage Claim Document Understanding: Combining Vision-Language Models and Machine Learning for Real-Time Processing
Jan 05, 2026Claims documents are fundamental to healthcare and insurance operations, serving as the basis for reimbursement, auditing, and compliance. However, these documents are typically not born digital; they often exist as scanned PDFs or photographs captured under uncontrolled conditions. Consequently, they exhibit significant content heterogeneity, ranging from typed invoices to handwritten medical reports, as well as linguistic diversity. This challenge is exemplified by operations at Fullerton Health, which handles tens of millions of claims annually across nine markets, including Singapore, the Philippines, Indonesia, Malaysia, Mainland China, Hong Kong, Vietnam, Papua New Guinea, and Cambodia. Such variability, coupled with inconsistent image quality and diverse layouts, poses a significant obstacle to automated parsing and structured information extraction. This paper presents a robust multi-stage pipeline that integrates the multilingual optical character recognition (OCR) engine PaddleOCR, a traditional Logistic Regression classifier, and a compact Vision-Language Model (VLM), Qwen 2.5-VL-7B, to achieve efficient and accurate field extraction from large-scale claims data. The proposed system achieves a document-type classification accuracy of over 95 percent and a field-level extraction accuracy of approximately 87 percent, while maintaining an average processing latency of under 2 seconds per document. Compared to manual processing, which typically requires around 10 minutes per claim, our system delivers a 300x improvement in efficiency. These results demonstrate that combining traditional machine learning models with modern VLMs enables production-grade accuracy and speed for real-world automation. The solution has been successfully deployed in our mobile application and is currently processing tens of thousands of claims weekly from Vietnam and Singapore.
Towards Analysing Invoices and Receipts with Amazon Textract
Dec 23, 2025This paper presents an evaluation of the AWS Textract in the context of extracting data from receipts. We analyse Textract functionalities using a dataset that includes receipts of varied formats and conditions. Our analysis provided a qualitative view of Textract strengths and limitations. While the receipts totals were consistently detected, we also observed typical issues and irregularities that were often influenced by image quality and layout. Based on the analysis of the observations, we propose mitigation strategies.
Design and Implementation of an OCR-Powered Pipeline for Table Extraction from Invoices
Jul 09, 2025This paper presents the design and development of an OCR-powered pipeline for efficient table extraction from invoices. The system leverages Tesseract OCR for text recognition and custom post-processing logic to detect, align, and extract structured tabular data from scanned invoice documents. Our approach includes dynamic preprocessing, table boundary detection, and row-column mapping, optimized for noisy and non-standard invoice formats. The resulting pipeline significantly improves data extraction accuracy and consistency, supporting real-world use cases such as automated financial workflows and digital archiving.
Qwen2.5-VL Technical Report
Feb 19, 2025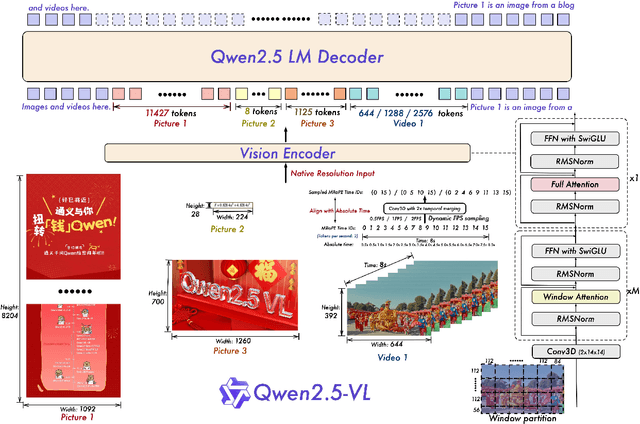
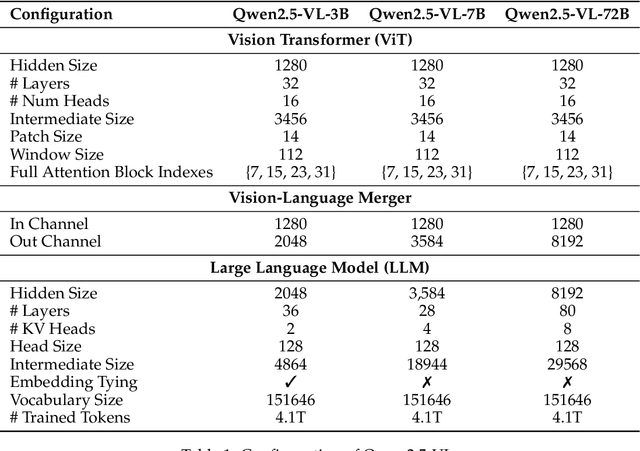
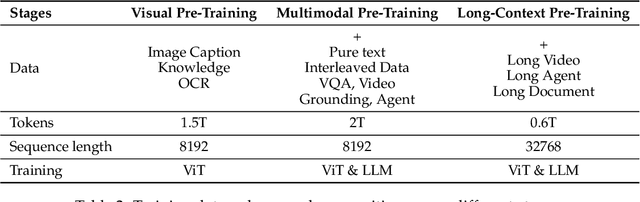
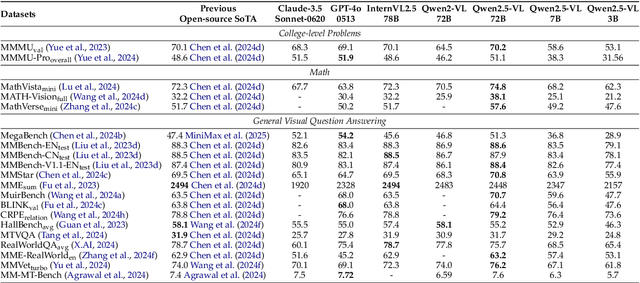
We introduce Qwen2.5-VL, the latest flagship model of Qwen vision-language series, which demonstrates significant advancements in both foundational capabilities and innovative functionalities. Qwen2.5-VL achieves a major leap forward in understanding and interacting with the world through enhanced visual recognition, precise object localization, robust document parsing, and long-video comprehension. A standout feature of Qwen2.5-VL is its ability to localize objects using bounding boxes or points accurately. It provides robust structured data extraction from invoices, forms, and tables, as well as detailed analysis of charts, diagrams, and layouts. To handle complex inputs, Qwen2.5-VL introduces dynamic resolution processing and absolute time encoding, enabling it to process images of varying sizes and videos of extended durations (up to hours) with second-level event localization. This allows the model to natively perceive spatial scales and temporal dynamics without relying on traditional normalization techniques. By training a native dynamic-resolution Vision Transformer (ViT) from scratch and incorporating Window Attention, we reduce computational overhead while maintaining native resolution. As a result, Qwen2.5-VL excels not only in static image and document understanding but also as an interactive visual agent capable of reasoning, tool usage, and task execution in real-world scenarios such as operating computers and mobile devices. Qwen2.5-VL is available in three sizes, addressing diverse use cases from edge AI to high-performance computing. The flagship Qwen2.5-VL-72B model matches state-of-the-art models like GPT-4o and Claude 3.5 Sonnet, particularly excelling in document and diagram understanding. Additionally, Qwen2.5-VL maintains robust linguistic performance, preserving the core language competencies of the Qwen2.5 LLM.
Document Parsing Unveiled: Techniques, Challenges, and Prospects for Structured Information Extraction
Oct 29, 2024



Document parsing is essential for converting unstructured and semi-structured documents-such as contracts, academic papers, and invoices-into structured, machine-readable data. Document parsing extract reliable structured data from unstructured inputs, providing huge convenience for numerous applications. Especially with recent achievements in Large Language Models, document parsing plays an indispensable role in both knowledge base construction and training data generation. This survey presents a comprehensive review of the current state of document parsing, covering key methodologies, from modular pipeline systems to end-to-end models driven by large vision-language models. Core components such as layout detection, content extraction (including text, tables, and mathematical expressions), and multi-modal data integration are examined in detail. Additionally, this paper discusses the challenges faced by modular document parsing systems and vision-language models in handling complex layouts, integrating multiple modules, and recognizing high-density text. It emphasizes the importance of developing larger and more diverse datasets and outlines future research directions.
Optimizing Structured Data Processing through Robotic Process Automation
Aug 27, 2024Robotic Process Automation (RPA) has emerged as a game-changing technology in data extraction, revolutionizing the way organizations process and analyze large volumes of documents such as invoices, purchase orders, and payment advices. This study investigates the use of RPA for structured data extraction and evaluates its advantages over manual processes. By comparing human-performed tasks with those executed by RPA software bots, we assess efficiency and accuracy in data extraction from invoices, focusing on the effectiveness of the RPA system. Through four distinct scenarios involving varying numbers of invoices, we measure efficiency in terms of time and effort required for task completion, as well as accuracy by comparing error rates between manual and RPA processes. Our findings highlight the significant efficiency gains achieved by RPA, with bots completing tasks in significantly less time compared to manual efforts across all cases. Moreover, the RPA system consistently achieves perfect accuracy, mitigating the risk of errors and enhancing process reliability. These results underscore the transformative potential of RPA in optimizing operational efficiency, reducing human labor costs, and improving overall business performance.
Improvement in Semantic Address Matching using Natural Language Processing
Apr 17, 2024Address matching is an important task for many businesses especially delivery and take out companies which help them to take out a certain address from their data warehouse. Existing solution uses similarity of strings, and edit distance algorithms to find out the similar addresses from the address database, but these algorithms could not work effectively with redundant, unstructured, or incomplete address data. This paper discuss semantic Address matching technique, by which we can find out a particular address from a list of possible addresses. We have also reviewed existing practices and their shortcoming. Semantic address matching is an essentially NLP task in the field of deep learning. Through this technique We have the ability to triumph the drawbacks of existing methods like redundant or abbreviated data problems. The solution uses the OCR on invoices to extract the address and create the data pool of addresses. Then this data is fed to the algorithm BM-25 for scoring the best matching entries. Then to observe the best result, this will pass through BERT for giving the best possible result from the similar queries. Our investigation exhibits that our methodology enormously improves both accuracy and review of cutting-edge technology existing techniques.
* 5 pages, 7 tables, 2021 2nd International Conference for Emerging Technology (INCET)
RealKIE: Five Novel Datasets for Enterprise Key Information Extraction
Mar 29, 2024We introduce RealKIE, a benchmark of five challenging datasets aimed at advancing key information extraction methods, with an emphasis on enterprise applications. The datasets include a diverse range of documents including SEC S1 Filings, US Non-disclosure Agreements, UK Charity Reports, FCC Invoices, and Resource Contracts. Each presents unique challenges: poor text serialization, sparse annotations in long documents, and complex tabular layouts. These datasets provide a realistic testing ground for key information extraction tasks like investment analysis and legal data processing. In addition to presenting these datasets, we offer an in-depth description of the annotation process, document processing techniques, and baseline modeling approaches. This contribution facilitates the development of NLP models capable of handling practical challenges and supports further research into information extraction technologies applicable to industry-specific problems. The annotated data and OCR outputs are available to download at https://indicodatasolutions.github.io/RealKIE/ code to reproduce the baselines will be available shortly.
BuDDIE: A Business Document Dataset for Multi-task Information Extraction
Apr 05, 2024The field of visually rich document understanding (VRDU) aims to solve a multitude of well-researched NLP tasks in a multi-modal domain. Several datasets exist for research on specific tasks of VRDU such as document classification (DC), key entity extraction (KEE), entity linking, visual question answering (VQA), inter alia. These datasets cover documents like invoices and receipts with sparse annotations such that they support one or two co-related tasks (e.g., entity extraction and entity linking). Unfortunately, only focusing on a single specific of documents or task is not representative of how documents often need to be processed in the wild - where variety in style and requirements is expected. In this paper, we introduce BuDDIE (Business Document Dataset for Information Extraction), the first multi-task dataset of 1,665 real-world business documents that contains rich and dense annotations for DC, KEE, and VQA. Our dataset consists of publicly available business entity documents from US state government websites. The documents are structured and vary in their style and layout across states and types (e.g., forms, certificates, reports, etc.). We provide data variety and quality metrics for BuDDIE as well as a series of baselines for each task. Our baselines cover traditional textual, multi-modal, and large language model approaches to VRDU.