 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGun Detection Dataset
Papers and Code
Intelligent Traffic Surveillance for Real-Time Vehicle Detection, License Plate Recognition, and Speed Estimation
Jan 01, 2026Speeding is a major contributor to road fatalities, particularly in developing countries such as Uganda, where road safety infrastructure is limited. This study proposes a real-time intelligent traffic surveillance system tailored to such regions, using computer vision techniques to address vehicle detection, license plate recognition, and speed estimation. The study collected a rich dataset using a speed gun, a Canon Camera, and a mobile phone to train the models. License plate detection using YOLOv8 achieved a mean average precision (mAP) of 97.9%. For character recognition of the detected license plate, the CNN model got a character error rate (CER) of 3.85%, while the transformer model significantly reduced the CER to 1.79%. Speed estimation used source and target regions of interest, yielding a good performance of 10 km/h margin of error. Additionally, a database was established to correlate user information with vehicle detection data, enabling automated ticket issuance via SMS via Africa's Talking API. This system addresses critical traffic management needs in resource-constrained environments and shows potential to reduce road accidents through automated traffic enforcement in developing countries where such interventions are urgently needed.
Brought a Gun to a Knife Fight: Modern VFM Baselines Outgun Specialized Detectors on In-the-Wild AI Image Detection
Sep 16, 2025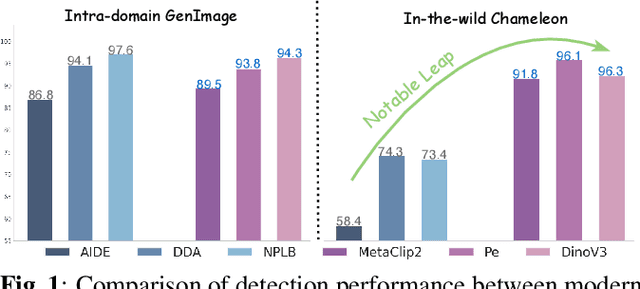
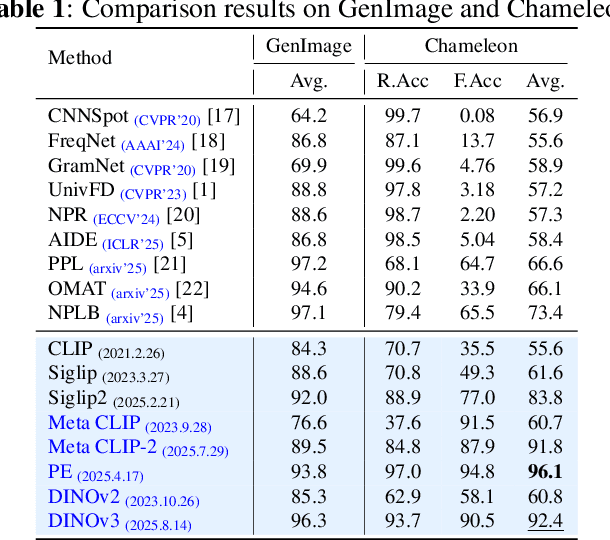
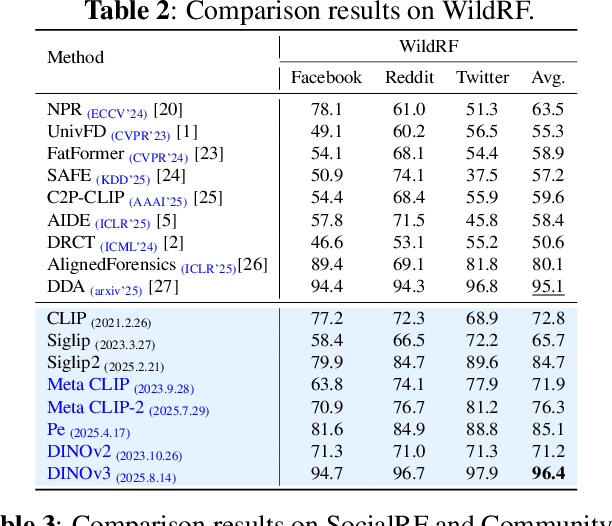
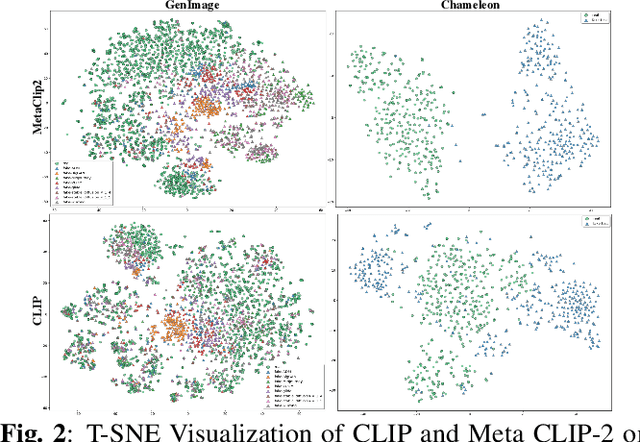
While specialized detectors for AI-generated images excel on curated benchmarks, they fail catastrophically in real-world scenarios, as evidenced by their critically high false-negative rates on `in-the-wild' benchmarks. Instead of crafting another specialized `knife' for this problem, we bring a `gun' to the fight: a simple linear classifier on a modern Vision Foundation Model (VFM). Trained on identical data, this baseline decisively `outguns' bespoke detectors, boosting in-the-wild accuracy by a striking margin of over 20\%. Our analysis pinpoints the source of the VFM's `firepower': First, by probing text-image similarities, we find that recent VLMs (e.g., Perception Encoder, Meta CLIP2) have learned to align synthetic images with forgery-related concepts (e.g., `AI-generated'), unlike previous versions. Second, we speculate that this is due to data exposure, as both this alignment and overall accuracy plummet on a novel dataset scraped after the VFM's pre-training cut-off date, ensuring it was unseen during pre-training. Our findings yield two critical conclusions: 1) For the real-world `gunfight' of AI-generated image detection, the raw `firepower' of an updated VFM is far more effective than the `craftsmanship' of a static detector. 2) True generalization evaluation requires test data to be independent of the model's entire training history, including pre-training.
Deciphering GunType Hierarchy through Acoustic Analysis of Gunshot Recordings
Jun 25, 2025The escalating rates of gun-related violence and mass shootings represent a significant threat to public safety. Timely and accurate information for law enforcement agencies is crucial in mitigating these incidents. Current commercial gunshot detection systems, while effective, often come with prohibitive costs. This research explores a cost-effective alternative by leveraging acoustic analysis of gunshot recordings, potentially obtainable from ubiquitous devices like cell phones, to not only detect gunshots but also classify the type of firearm used. This paper details a study on deciphering gun type hierarchies using a curated dataset of 3459 recordings. We investigate the fundamental acoustic characteristics of gunshots, including muzzle blasts and shockwaves, which vary based on firearm type, ammunition, and shooting direction. We propose and evaluate machine learning frameworks, including Support Vector Machines (SVMs) as a baseline and a more advanced Convolutional Neural Network (CNN) architecture for joint gunshot detection and gun type classification. Results indicate that our deep learning approach achieves a mean average precision (mAP) of 0.58 on clean labeled data, outperforming the SVM baseline (mAP 0.39). Challenges related to data quality, environmental noise, and the generalization capabilities when using noisy web-sourced data (mAP 0.35) are also discussed. The long-term vision is to develop a highly accurate, real-time system deployable on common recording devices, significantly reducing detection costs and providing critical intelligence to first responders.
Accurate and Efficient Two-Stage Gun Detection in Video
Mar 08, 2025Object detection in videos plays a crucial role in advancing applications such as public safety and anomaly detection. Existing methods have explored different techniques, including CNN, deep learning, and Transformers, for object detection and video classification. However, detecting tiny objects, e.g., guns, in videos remains challenging due to their small scale and varying appearances in complex scenes. Moreover, existing video analysis models for classification or detection often perform poorly in real-world gun detection scenarios due to limited labeled video datasets for training. Thus, developing efficient methods for effectively capturing tiny object features and designing models capable of accurate gun detection in real-world videos is imperative. To address these challenges, we make three original contributions in this paper. First, we conduct an empirical study of several existing video classification and object detection methods to identify guns in videos. Our extensive analysis shows that these methods may not accurately detect guns in videos. Second, we propose a novel two-stage gun detection method. In stage 1, we train an image-augmented model to effectively classify ``Gun'' videos. To make the detection more precise and efficient, stage 2 employs an object detection model to locate the exact region of the gun within video frames for videos classified as ``Gun'' by stage 1. Third, our experimental results demonstrate that the proposed domain-specific method achieves significant performance improvements and enhances efficiency compared with existing techniques. We also discuss challenges and future research directions in gun detection tasks in computer vision.
Gun Detection Using Combined Human Pose and Weapon Appearance
Mar 15, 2025



The increasing frequency of firearm-related incidents has necessitated advancements in security and surveillance systems, particularly in firearm detection within public spaces. Traditional gun detection methods rely on manual inspections and continuous human monitoring of CCTV footage, which are labor-intensive and prone to high false positive and negative rates. To address these limitations, we propose a novel approach that integrates human pose estimation with weapon appearance recognition using deep learning techniques. Unlike prior studies that focus on either body pose estimation or firearm detection in isolation, our method jointly analyzes posture and weapon presence to enhance detection accuracy in real-world, dynamic environments. To train our model, we curated a diverse dataset comprising images from open-source repositories such as IMFDB and Monash Guns, supplemented with AI-generated and manually collected images from web sources. This dataset ensures robust generalization and realistic performance evaluation under various surveillance conditions. Our research aims to improve the precision and reliability of firearm detection systems, contributing to enhanced public safety and threat mitigation in high-risk areas.
Framing Social Movements on Social Media: Unpacking Diagnostic, Prognostic, and Motivational Strategies
Jun 19, 2024



Social media enables activists to directly communicate with the public and provides a space for movement leaders, participants, bystanders, and opponents to collectively construct and contest narratives. Focusing on Twitter messages from social movements surrounding three issues in 2018-2019 (guns, immigration, and LGBTQ rights), we create a codebook, annotated dataset, and computational models to detect diagnostic (problem identification and attribution), prognostic (proposed solutions and tactics), and motivational (calls to action) framing strategies. We conduct an in-depth unsupervised linguistic analysis of each framing strategy, and uncover cross-movement similarities in associations between framing and linguistic features such as pronouns and deontic modal verbs. Finally, we compare framing strategies across issues and other social, cultural, and interactional contexts. For example, we show that diagnostic framing is more common in replies than original broadcast posts, and that social movement organizations focus much more on prognostic and motivational framing than journalists and ordinary citizens.
* Published in ICWSM Special Issue of the Journal of Quantitative Description: Digital Media
Detecting Frames in News Headlines and Lead Images in U.S. Gun Violence Coverage
Jun 25, 2024



News media structure their reporting of events or issues using certain perspectives. When describing an incident involving gun violence, for example, some journalists may focus on mental health or gun regulation, while others may emphasize the discussion of gun rights. Such perspectives are called \say{frames} in communication research. We study, for the first time, the value of combining lead images and their contextual information with text to identify the frame of a given news article. We observe that using multiple modes of information(article- and image-derived features) improves prediction of news frames over any single mode of information when the images are relevant to the frames of the headlines. We also observe that frame image relevance is related to the ease of conveying frames via images, which we call frame concreteness. Additionally, we release the first multimodal news framing dataset related to gun violence in the U.S., curated and annotated by communication researchers. The dataset will allow researchers to further examine the use of multiple information modalities for studying media framing.
Decoding News Narratives: A Critical Analysis of Large Language Models in Framing Bias Detection
Feb 23, 2024This work contributes to the expanding research on the applicability of LLMs in social sciences by examining the performance of GPT-3.5 Turbo, GPT-4, and Flan-T5 models in detecting framing bias in news headlines through zero-shot, few-shot, and explainable prompting methods. A key insight from our evaluation is the notable efficacy of explainable prompting in enhancing the reliability of these models, highlighting the importance of explainable settings for social science research on framing bias. GPT-4, in particular, demonstrated enhanced performance in few-shot scenarios when presented with a range of relevant, in-domain examples. FLAN-T5's poor performance indicates that smaller models may require additional task-specific fine-tuning for identifying framing bias detection. Our study also found that models, particularly GPT-4, often misinterpret emotional language as an indicator of framing bias, underscoring the challenge of distinguishing between reporting genuine emotional expression and intentionally use framing bias in news headlines. We further evaluated the models on two subsets of headlines where the presence or absence of framing bias was either clear-cut or more contested, with the results suggesting that these models' can be useful in flagging potential annotation inaccuracies within existing or new datasets. Finally, the study evaluates the models in real-world conditions ("in the wild"), moving beyond the initial dataset focused on U.S. Gun Violence, assessing the models' performance on framed headlines covering a broad range of topics.
Active shooter detection and robust tracking utilizing supplemental synthetic data
Sep 06, 2023



The increasing concern surrounding gun violence in the United States has led to a focus on developing systems to improve public safety. One approach to developing such a system is to detect and track shooters, which would help prevent or mitigate the impact of violent incidents. In this paper, we proposed detecting shooters as a whole, rather than just guns, which would allow for improved tracking robustness, as obscuring the gun would no longer cause the system to lose sight of the threat. However, publicly available data on shooters is much more limited and challenging to create than a gun dataset alone. Therefore, we explore the use of domain randomization and transfer learning to improve the effectiveness of training with synthetic data obtained from Unreal Engine environments. This enables the model to be trained on a wider range of data, increasing its ability to generalize to different situations. Using these techniques with YOLOv8 and Deep OC-SORT, we implemented an initial version of a shooter tracking system capable of running on edge hardware, including both a Raspberry Pi and a Jetson Nano.
CCTV-Gun: Benchmarking Handgun Detection in CCTV Images
Apr 02, 2023



Gun violence is a critical security problem, and it is imperative for the computer vision community to develop effective gun detection algorithms for real-world scenarios, particularly in Closed Circuit Television (CCTV) surveillance data. Despite significant progress in visual object detection, detecting guns in real-world CCTV images remains a challenging and under-explored task. Firearms, especially handguns, are typically very small in size, non-salient in appearance, and often severely occluded or indistinguishable from other small objects. Additionally, the lack of principled benchmarks and difficulty collecting relevant datasets further hinder algorithmic development. In this paper, we present a meticulously crafted and annotated benchmark, called \textbf{CCTV-Gun}, which addresses the challenges of detecting handguns in real-world CCTV images. Our contribution is three-fold. Firstly, we carefully select and analyze real-world CCTV images from three datasets, manually annotate handguns and their holders, and assign each image with relevant challenge factors such as blur and occlusion. Secondly, we propose a new cross-dataset evaluation protocol in addition to the standard intra-dataset protocol, which is vital for gun detection in practical settings. Finally, we comprehensively evaluate both classical and state-of-the-art object detection algorithms, providing an in-depth analysis of their generalizing abilities. The benchmark will facilitate further research and development on this topic and ultimately enhance security. Code, annotations, and trained models are available at https://github.com/srikarym/CCTV-Gun.