 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSandboxAQ's submission to MRL 2024 Shared Task on Multi-lingual Multi-task Information Retrieval
Oct 28, 2024



This paper explores the problems of Question Answering (QA) and Named Entity Recognition (NER) in five diverse languages. We tested five Large Language Models with various prompting methods, including zero-shot, chain-of-thought reasoning, and translation techniques. Our results show that while some models consistently outperform others, their effectiveness varies significantly across tasks and languages. We saw that advanced prompting techniques generally improved QA performance but had mixed results for NER; and we observed that language difficulty patterns differed between tasks. Our findings highlight the need for task-specific approaches in multilingual NLP and suggest that current models may develop different linguistic competencies for different tasks.
Detecting Frames in News Headlines and Lead Images in U.S. Gun Violence Coverage
Jun 25, 2024



News media structure their reporting of events or issues using certain perspectives. When describing an incident involving gun violence, for example, some journalists may focus on mental health or gun regulation, while others may emphasize the discussion of gun rights. Such perspectives are called \say{frames} in communication research. We study, for the first time, the value of combining lead images and their contextual information with text to identify the frame of a given news article. We observe that using multiple modes of information(article- and image-derived features) improves prediction of news frames over any single mode of information when the images are relevant to the frames of the headlines. We also observe that frame image relevance is related to the ease of conveying frames via images, which we call frame concreteness. Additionally, we release the first multimodal news framing dataset related to gun violence in the U.S., curated and annotated by communication researchers. The dataset will allow researchers to further examine the use of multiple information modalities for studying media framing.
An Empirical study of Unsupervised Neural Machine Translation: analyzing NMT output, model's behavior and sentences' contribution
Dec 19, 2023Unsupervised Neural Machine Translation (UNMT) focuses on improving NMT results under the assumption there is no human translated parallel data, yet little work has been done so far in highlighting its advantages compared to supervised methods and analyzing its output in aspects other than translation accuracy. We focus on three very diverse languages, French, Gujarati, and Kazakh, and train bilingual NMT models, to and from English, with various levels of supervision, in high- and low- resource setups, measure quality of the NMT output and compare the generated sequences' word order and semantic similarity to source and reference sentences. We also use Layer-wise Relevance Propagation to evaluate the source and target sentences' contribution to the result, expanding the findings of previous works to the UNMT paradigm.
Relevance-guided Neural Machine Translation
Nov 30, 2023


With the advent of the Transformer architecture, Neural Machine Translation (NMT) results have shown great improvement lately. However, results in low-resource conditions still lag behind in both bilingual and multilingual setups, due to the limited amount of available monolingual and/or parallel data; hence, the need for methods addressing data scarcity in an efficient, and explainable way, is eminent. We propose an explainability-based training approach for NMT, applied in Unsupervised and Supervised model training, for translation of three languages of varying resources, French, Gujarati, Kazakh, to and from English. Our results show our method can be promising, particularly when training in low-resource conditions, outperforming simple training baselines; though the improvement is marginal, it sets the ground for further exploration of the approach and the parameters, and its extension to other languages.
Direct Neural Machine Translation with Task-level Mixture of Experts models
Oct 18, 2023



Direct neural machine translation (direct NMT) is a type of NMT system that translates text between two non-English languages. Direct NMT systems often face limitations due to the scarcity of parallel data between non-English language pairs. Several approaches have been proposed to address this limitation, such as multilingual NMT and pivot NMT (translation between two languages via English). Task-level Mixture of expert models (Task-level MoE), an inference-efficient variation of Transformer-based models, has shown promising NMT performance for a large number of language pairs. In Task-level MoE, different language groups can use different routing strategies to optimize cross-lingual learning and inference speed. In this work, we examine Task-level MoE's applicability in direct NMT and propose a series of high-performing training and evaluation configurations, through which Task-level MoE-based direct NMT systems outperform bilingual and pivot-based models for a large number of low and high-resource direct pairs, and translation directions. Our Task-level MoE with 16 experts outperforms bilingual NMT, Pivot NMT models for 7 language pairs, while pivot-based models still performed better in 9 pairs and directions.
Low-Resource Machine Translation for Low-Resource Languages: Leveraging Comparable Data, Code-Switching and Compute Resources
Mar 24, 2021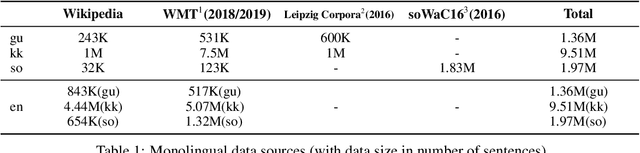

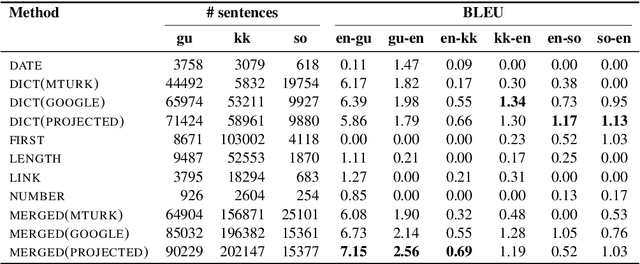
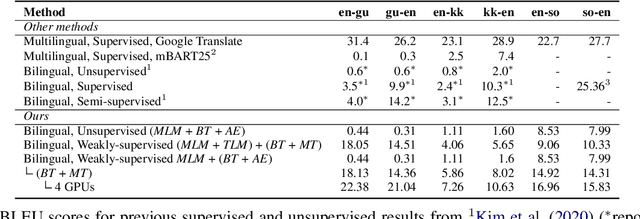
We conduct an empirical study of unsupervised neural machine translation (NMT) for truly low resource languages, exploring the case when both parallel training data and compute resource are lacking, reflecting the reality of most of the world's languages and the researchers working on these languages. We propose a simple and scalable method to improve unsupervised NMT, showing how adding comparable data mined using a bilingual dictionary along with modest additional compute resource to train the model can significantly improve its performance. We also demonstrate how the use of the dictionary to code-switch monolingual data to create more comparable data can further improve performance. With this weak supervision, our best method achieves BLEU scores that improve over supervised results for English$\rightarrow$Gujarati (+18.88), English$\rightarrow$Kazakh (+5.84), and English$\rightarrow$Somali (+1.16), showing the promise of weakly-supervised NMT for many low resource languages with modest compute resource in the world. To the best of our knowledge, our work is the first to quantitatively showcase the impact of different modest compute resource in low resource NMT.