 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrammatical Error Detection
Grammatical error detection (GED) is the task of detecting different kinds of errors in text such as spelling, punctuation, grammatical, and word choice errors. Grammatical error detection (GED) is one of the key components in the grammatical error correction (GEC) community.
Papers and Code
Exploiting the English Grammar Profile for L2 grammatical analysis with LLMs
Mar 17, 2026Evaluating the grammatical competence of second language (L2) learners is essential both for providing targeted feedback and for assessing proficiency. To achieve this, we propose a novel framework leveraging the English Grammar Profile (EGP), a taxonomy of grammatical constructs mapped to the proficiency levels of the Common European Framework of Reference (CEFR), to detect learners' attempts at grammatical constructs and classify them as successful or unsuccessful. This detection can then be used to provide fine-grained feedback. Moreover, the grammatical constructs are used as predictors of proficiency assessment by using automatically detected attempts as predictors of holistic CEFR proficiency. For the selection of grammatical constructs derived from the EGP, rule-based and LLM-based classifiers are compared. We show that LLMs outperform rule-based methods on semantically and pragmatically nuanced constructs, while rule-based approaches remain competitive for constructs that rely purely on morphological or syntactic features and do not require semantic interpretation. For proficiency assessment, we evaluate both rule-based and hybrid pipelines and show that a hybrid approach combining a rule-based pre-filter with an LLM consistently yields the strongest performance. Since our framework operates on pairs of original learner sentences and their corrected counterparts, we also evaluate a fully automated pipeline using automatic grammatical error correction. This pipeline closely approaches the performance of semi-automated systems based on manual corrections, particularly for the detection of successful attempts at grammatical constructs. Overall, our framework emphasises learners' successful attempts in addition to unsuccessful ones, enabling positive, formative feedback and providing actionable insights into grammatical development.
Blackbird Language Matrices: A Framework to Investigate the Linguistic Competence of Language Models
Feb 24, 2026This article describes a novel language task, the Blackbird Language Matrices (BLM) task, inspired by intelligence tests, and illustrates the BLM datasets, their construction and benchmarking, and targeted experiments on chunking and systematicity. BLMs are multiple-choice problems, structured at multiple levels: within each sentence, across the input sequence, within each candidate answer. Because of their rich structure, these curated, but naturalistic datasets are key to answer some core questions about current large language models abilities: do LLMs detect linguistic objects and their properties? Do they detect and use systematic patterns across sentences? Are they more prone to linguistic or reasoning errors, and how do these interact? We show that BLMs, while challenging, can be solved at good levels of performance, in more than one language, with simple baseline models or, at better performance levels, with more tailored models. We show that their representations contain the grammatical objects and attributes relevant to solve a linguistic task. We also show that these solutions are reached by detecting systematic patterns across sentences. The paper supports the point of view that curated, structured datasets support multi-faceted investigations of properties of language and large language models. Because they present a curated, articulated structure, because they comprise both learning contexts and expected answers, and because they are partly built by hand, BLMs fall in the category of datasets that can support explainability investigations, and be useful to ask why large language models behave the way they do.
Are Two LLMs Better Than One? A Student-Teacher Dual-Head LLMs Architecture for Pharmaceutical Content Optimization
Feb 12, 2026Large language models (LLMs) are increasingly used to create content in regulated domains such as pharmaceuticals, where outputs must be scientifically accurate and legally compliant. Manual quality control (QC) is slow, error prone, and can become a publication bottleneck. We introduce LRBTC, a modular LLM and vision language model (VLM) driven QC architecture covering Language, Regulatory, Brand, Technical, and Content Structure checks. LRBTC combines a Student-Teacher dual model architecture, human in the loop (HITL) workflow with waterfall rule filtering to enable scalable, verifiable content validation and optimization. On AIReg-Bench, our approach achieves 83.0% F1 and 97.5% recall, reducing missed violations by 5x compared with Gemini 2.5 Pro. On CSpelling, it improves mean accuracy by 26.7%. Error analysis further reveals that while current models are strong at detecting misspellings (92.5 recall), they fail to identify complex medical grammatical (25.0 recall) and punctuation (41.7 recall) errors, highlighting a key area for future work. This work provides a practical, plug and play solution for reliable, transparent quality control of content in high stakes, compliance critical industries. We also provide access to our Demo under MIT Licenses.
IsoSignVid2Aud: Sign Language Video to Audio Conversion without Text Intermediaries
Oct 09, 2025Sign language to spoken language audio translation is important to connect the hearing- and speech-challenged humans with others. We consider sign language videos with isolated sign sequences rather than continuous grammatical signing. Such videos are useful in educational applications and sign prompt interfaces. Towards this, we propose IsoSignVid2Aud, a novel end-to-end framework that translates sign language videos with a sequence of possibly non-grammatic continuous signs to speech without requiring intermediate text representation, providing immediate communication benefits while avoiding the latency and cascading errors inherent in multi-stage translation systems. Our approach combines an I3D-based feature extraction module with a specialized feature transformation network and an audio generation pipeline, utilizing a novel Non-Maximal Suppression (NMS) algorithm for the temporal detection of signs in non-grammatic continuous sequences. Experimental results demonstrate competitive performance on ASL-Citizen-1500 and WLASL-100 datasets with Top-1 accuracies of 72.01\% and 78.67\%, respectively, and audio quality metrics (PESQ: 2.67, STOI: 0.73) indicating intelligible speech output. Code is available at: https://github.com/BheeshmSharma/IsoSignVid2Aud_AIMLsystems-2025.
MetaLogic: Robustness Evaluation of Text-to-Image Models via Logically Equivalent Prompts
Oct 01, 2025Recent advances in text-to-image (T2I) models, especially diffusion-based architectures, have significantly improved the visual quality of generated images. However, these models continue to struggle with a critical limitation: maintaining semantic consistency when input prompts undergo minor linguistic variations. Despite being logically equivalent, such prompt pairs often yield misaligned or semantically inconsistent images, exposing a lack of robustness in reasoning and generalisation. To address this, we propose MetaLogic, a novel evaluation framework that detects T2I misalignment without relying on ground truth images. MetaLogic leverages metamorphic testing, generating image pairs from prompts that differ grammatically but are semantically identical. By directly comparing these image pairs, the framework identifies inconsistencies that signal failures in preserving the intended meaning, effectively diagnosing robustness issues in the model's logic understanding. Unlike existing evaluation methods that compare a generated image to a single prompt, MetaLogic evaluates semantic equivalence between paired images, offering a scalable, ground-truth-free approach to identifying alignment failures. It categorises these alignment errors (e.g., entity omission, duplication, positional misalignment) and surfaces counterexamples that can be used for model debugging and refinement. We evaluate MetaLogic across multiple state-of-the-art T2I models and reveal consistent robustness failures across a range of logical constructs. We find that even the SOTA text-to-image models like Flux.dev and DALLE-3 demonstrate a 59 percent and 71 percent misalignment rate, respectively. Our results show that MetaLogic is not only efficient and scalable, but also effective in uncovering fine-grained logical inconsistencies that are overlooked by existing evaluation metrics.
A Representation Level Analysis of NMT Model Robustness to Grammatical Errors
May 27, 2025



Understanding robustness is essential for building reliable NLP systems. Unfortunately, in the context of machine translation, previous work mainly focused on documenting robustness failures or improving robustness. In contrast, we study robustness from a model representation perspective by looking at internal model representations of ungrammatical inputs and how they evolve through model layers. For this purpose, we perform Grammatical Error Detection (GED) probing and representational similarity analysis. Our findings indicate that the encoder first detects the grammatical error, then corrects it by moving its representation toward the correct form. To understand what contributes to this process, we turn to the attention mechanism where we identify what we term Robustness Heads. We find that Robustness Heads attend to interpretable linguistic units when responding to grammatical errors, and that when we fine-tune models for robustness, they tend to rely more on Robustness Heads for updating the ungrammatical word representation.
Detecting Spelling and Grammatical Anomalies in Russian Poetry Texts
May 07, 2025The quality of natural language texts in fine-tuning datasets plays a critical role in the performance of generative models, particularly in computational creativity tasks such as poem or song lyric generation. Fluency defects in generated poems significantly reduce their value. However, training texts are often sourced from internet-based platforms without stringent quality control, posing a challenge for data engineers to manage defect levels effectively. To address this issue, we propose the use of automated linguistic anomaly detection to identify and filter out low-quality texts from training datasets for creative models. In this paper, we present a comprehensive comparison of unsupervised and supervised text anomaly detection approaches, utilizing both synthetic and human-labeled datasets. We also introduce the RUPOR dataset, a collection of Russian-language human-labeled poems designed for cross-sentence grammatical error detection, and provide the full evaluation code. Our work aims to empower the community with tools and insights to improve the quality of training datasets for generative models in creative domains.
ARWI: Arabic Write and Improve
Apr 16, 2025Although Arabic is spoken by over 400 million people, advanced Arabic writing assistance tools remain limited. To address this gap, we present ARWI, a new writing assistant that helps learners improve essay writing in Modern Standard Arabic. ARWI is the first publicly available Arabic writing assistant to include a prompt database for different proficiency levels, an Arabic text editor, state-of-the-art grammatical error detection and correction, and automated essay scoring aligned with the Common European Framework of Reference standards for language attainment. Moreover, ARWI can be used to gather a growing auto-annotated corpus, facilitating further research on Arabic grammar correction and essay scoring, as well as profiling patterns of errors made by native speakers and non-native learners. A preliminary user study shows that ARWI provides actionable feedback, helping learners identify grammatical gaps, assess language proficiency, and guide improvement.
Scaling and Prompting for Improved End-to-End Spoken Grammatical Error Correction
May 27, 2025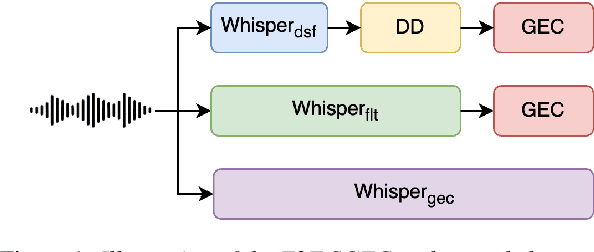
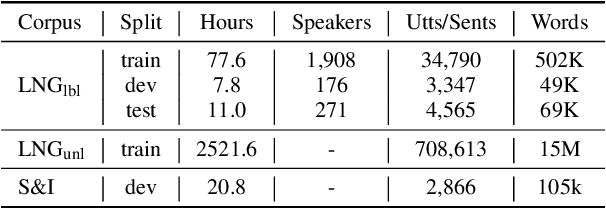
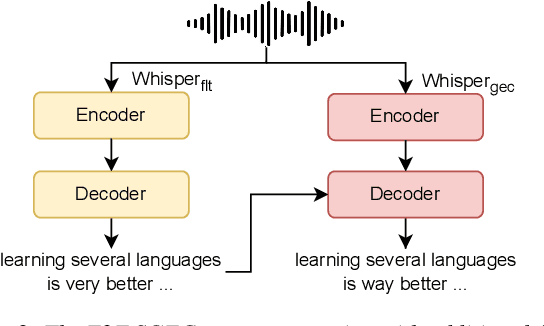
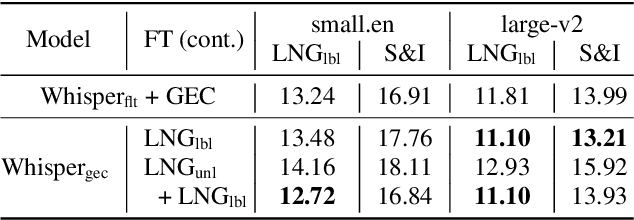
Spoken Grammatical Error Correction (SGEC) and Feedback (SGECF) are crucial for second language learners, teachers and test takers. Traditional SGEC systems rely on a cascaded pipeline consisting of an ASR, a module for disfluency detection (DD) and removal and one for GEC. With the rise of end-to-end (E2E) speech foundation models, we investigate their effectiveness in SGEC and feedback generation. This work introduces a pseudo-labelling process to address the challenge of limited labelled data, expanding the training data size from 77 hours to approximately 2500 hours, leading to improved performance. Additionally, we prompt an E2E Whisper-based SGEC model with fluent transcriptions, showing a slight improvement in SGEC performance, with more significant gains in feedback generation. Finally, we assess the impact of increasing model size, revealing that while pseudo-labelled data does not yield performance gain for a larger Whisper model, training with prompts proves beneficial.
Bangla Grammatical Error Detection Leveraging Transformer-based Token Classification
Nov 13, 2024



Bangla is the seventh most spoken language by a total number of speakers in the world, and yet the development of an automated grammar checker in this language is an understudied problem. Bangla grammatical error detection is a task of detecting sub-strings of a Bangla text that contain grammatical, punctuation, or spelling errors, which is crucial for developing an automated Bangla typing assistant. Our approach involves breaking down the task as a token classification problem and utilizing state-of-the-art transformer-based models. Finally, we combine the output of these models and apply rule-based post-processing to generate a more reliable and comprehensive result. Our system is evaluated on a dataset consisting of over 25,000 texts from various sources. Our best model achieves a Levenshtein distance score of 1.04. Finally, we provide a detailed analysis of different components of our system.