 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWho can we trust? LLM-as-a-jury for Comparative Assessment
Feb 18, 2026Large language models (LLMs) are increasingly applied as automatic evaluators for natural language generation assessment often using pairwise comparative judgements. Existing approaches typically rely on single judges or aggregate multiple judges assuming equal reliability. In practice, LLM judges vary substantially in performance across tasks and aspects, and their judgment probabilities may be biased and inconsistent. Furthermore, human-labelled supervision for judge calibration may be unavailable. We first empirically demonstrate that inconsistencies in LLM comparison probabilities exist and show that it limits the effectiveness of direct probability-based ranking. To address this, we study the LLM-as-a-jury setting and propose BT-sigma, a judge-aware extension of the Bradley-Terry model that introduces a discriminator parameter for each judge to jointly infer item rankings and judge reliability from pairwise comparisons alone. Experiments on benchmark NLG evaluation datasets show that BT-sigma consistently outperforms averaging-based aggregation methods, and that the learned discriminator strongly correlates with independent measures of the cycle consistency of LLM judgments. Further analysis reveals that BT-sigma can be interpreted as an unsupervised calibration mechanism that improves aggregation by modelling judge reliability.
Assessment of L2 Oral Proficiency using Speech Large Language Models
May 27, 2025



The growing population of L2 English speakers has increased the demand for developing automatic graders for spoken language assessment (SLA). Historically, statistical models, text encoders, and self-supervised speech models have been utilised for this task. However, cascaded systems suffer from the loss of information, while E2E graders also have limitations. With the recent advancements of multi-modal large language models (LLMs), we aim to explore their potential as L2 oral proficiency graders and overcome these issues. In this work, we compare various training strategies using regression and classification targets. Our results show that speech LLMs outperform all previous competitive baselines, achieving superior performance on two datasets. Furthermore, the trained grader demonstrates strong generalisation capabilities in the cross-part or cross-task evaluation, facilitated by the audio understanding knowledge acquired during LLM pre-training.
Scaling and Prompting for Improved End-to-End Spoken Grammatical Error Correction
May 27, 2025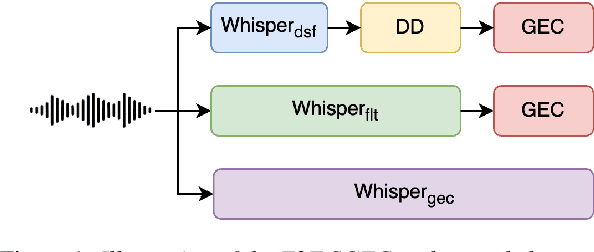
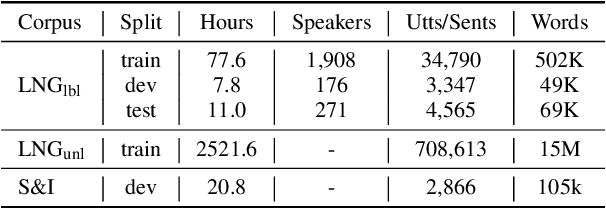
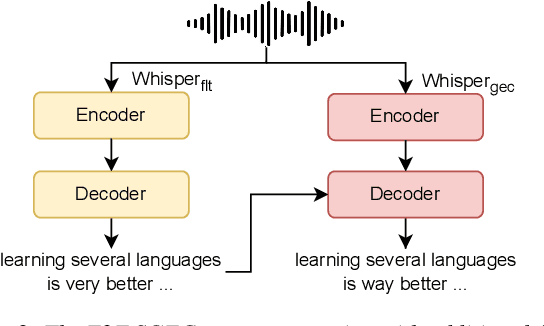
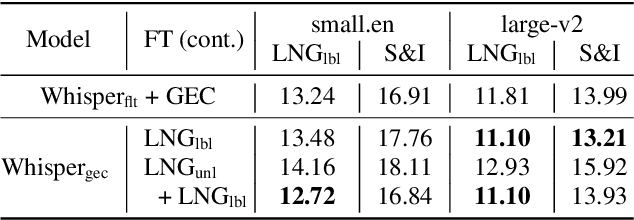
Spoken Grammatical Error Correction (SGEC) and Feedback (SGECF) are crucial for second language learners, teachers and test takers. Traditional SGEC systems rely on a cascaded pipeline consisting of an ASR, a module for disfluency detection (DD) and removal and one for GEC. With the rise of end-to-end (E2E) speech foundation models, we investigate their effectiveness in SGEC and feedback generation. This work introduces a pseudo-labelling process to address the challenge of limited labelled data, expanding the training data size from 77 hours to approximately 2500 hours, leading to improved performance. Additionally, we prompt an E2E Whisper-based SGEC model with fluent transcriptions, showing a slight improvement in SGEC performance, with more significant gains in feedback generation. Finally, we assess the impact of increasing model size, revealing that while pseudo-labelled data does not yield performance gain for a larger Whisper model, training with prompts proves beneficial.
Universal Acoustic Adversarial Attacks for Flexible Control of Speech-LLMs
May 20, 2025The combination of pre-trained speech encoders with large language models has enabled the development of speech LLMs that can handle a wide range of spoken language processing tasks. While these models are powerful and flexible, this very flexibility may make them more vulnerable to adversarial attacks. To examine the extent of this problem, in this work we investigate universal acoustic adversarial attacks on speech LLMs. Here a fixed, universal, adversarial audio segment is prepended to the original input audio. We initially investigate attacks that cause the model to either produce no output or to perform a modified task overriding the original prompt. We then extend the nature of the attack to be selective so that it activates only when specific input attributes, such as a speaker gender or spoken language, are present. Inputs without the targeted attribute should be unaffected, allowing fine-grained control over the model outputs. Our findings reveal critical vulnerabilities in Qwen2-Audio and Granite-Speech and suggest that similar speech LLMs may be susceptible to universal adversarial attacks. This highlights the need for more robust training strategies and improved resistance to adversarial attacks.
Speaker Retrieval in the Wild: Challenges, Effectiveness and Robustness
Apr 29, 2025



There is a growing abundance of publicly available or company-owned audio/video archives, highlighting the increasing importance of efficient access to desired content and information retrieval from these archives. This paper investigates the challenges, solutions, effectiveness, and robustness of speaker retrieval systems developed "in the wild" which involves addressing two primary challenges: extraction of task-relevant labels from limited metadata for system development and evaluation, as well as the unconstrained acoustic conditions encountered in the archive, ranging from quiet studios to adverse noisy environments. While we focus on the publicly-available BBC Rewind archive (spanning 1948 to 1979), our framework addresses the broader issue of speaker retrieval on extensive and possibly aged archives with no control over the content and acoustic conditions. Typically, these archives offer a brief and general file description, mostly inadequate for specific applications like speaker retrieval, and manual annotation of such large-scale archives is unfeasible. We explore various aspects of system development (e.g., speaker diarisation, embedding extraction, query selection) and analyse the challenges, possible solutions, and their functionality. To evaluate the performance, we conduct systematic experiments in both clean setup and against various distortions simulating real-world applications. Our findings demonstrate the effectiveness and robustness of the developed speaker retrieval systems, establishing the versatility and scalability of the proposed framework for a wide range of applications beyond the BBC Rewind corpus.
Fotheidil: an Automatic Transcription System for the Irish Language
Dec 31, 2024



This paper sets out the first web-based transcription system for the Irish language - Fotheidil, a system that utilises speech-related AI technologies as part of the ABAIR initiative. The system includes both off-the-shelf pre-trained voice activity detection and speaker diarisation models and models trained specifically for Irish automatic speech recognition and capitalisation and punctuation restoration. Semi-supervised learning is explored to improve the acoustic model of a modular TDNN-HMM ASR system, yielding substantial improvements for out-of-domain test sets and dialects that are underrepresented in the supervised training set. A novel approach to capitalisation and punctuation restoration involving sequence-to-sequence models is compared with the conventional approach using a classification model. Experimental results show here also substantial improvements in performance. The system will be made freely available for public use, and represents an important resource to researchers and others who transcribe Irish language materials. Human-corrected transcriptions will be collected and included in the training dataset as the system is used, which should lead to incremental improvements to the ASR model in a cyclical, community-driven fashion.
Speak & Improve Corpus 2025: an L2 English Speech Corpus for Language Assessment and Feedback
Dec 17, 2024We introduce the Speak & Improve Corpus 2025, a dataset of L2 learner English data with holistic scores and language error annotation, collected from open (spontaneous) speaking tests on the Speak & Improve learning platform. The aim of the corpus release is to address a major challenge to developing L2 spoken language processing systems, the lack of publicly available data with high-quality annotations. It is being made available for non-commercial use on the ELiT website. In designing this corpus we have sought to make it cover a wide-range of speaker attributes, from their L1 to their speaking ability, as well as providing manual annotations. This enables a range of language-learning tasks to be examined, such as assessing speaking proficiency or providing feedback on grammatical errors in a learner's speech. Additionally the data supports research into the underlying technology required for these tasks including automatic speech recognition (ASR) of low resource L2 learner English, disfluency detection or spoken grammatical error correction (GEC). The corpus consists of around 315 hours of L2 English learners audio with holistic scores, and a subset of audio annotated with transcriptions and error labels.
Speak & Improve Challenge 2025: Tasks and Baseline Systems
Dec 17, 2024



This paper presents the "Speak & Improve Challenge 2025: Spoken Language Assessment and Feedback" -- a challenge associated with the ISCA SLaTE 2025 Workshop. The goal of the challenge is to advance research on spoken language assessment and feedback, with tasks associated with both the underlying technology and language learning feedback. Linked with the challenge, the Speak & Improve (S&I) Corpus 2025 is being pre-released, a dataset of L2 learner English data with holistic scores and language error annotation, collected from open (spontaneous) speaking tests on the Speak & Improve learning platform. The corpus consists of approximately 315 hours of audio data from second language English learners with holistic scores, and a 55-hour subset with manual transcriptions and error labels. The Challenge has four shared tasks: Automatic Speech Recognition (ASR), Spoken Language Assessment (SLA), Spoken Grammatical Error Correction (SGEC), and Spoken Grammatical Error Correction Feedback (SGECF). Each of these tasks has a closed track where a predetermined set of models and data sources are allowed to be used, and an open track where any public resource may be used. Challenge participants may do one or more of the tasks. This paper describes the challenge, the S&I Corpus 2025, and the baseline systems released for the Challenge.
ASR Error Correction using Large Language Models
Sep 14, 2024



Error correction (EC) models play a crucial role in refining Automatic Speech Recognition (ASR) transcriptions, enhancing the readability and quality of transcriptions. Without requiring access to the underlying code or model weights, EC can improve performance and provide domain adaptation for black-box ASR systems. This work investigates the use of large language models (LLMs) for error correction across diverse scenarios. 1-best ASR hypotheses are commonly used as the input to EC models. We propose building high-performance EC models using ASR N-best lists which should provide more contextual information for the correction process. Additionally, the generation process of a standard EC model is unrestricted in the sense that any output sequence can be generated. For some scenarios, such as unseen domains, this flexibility may impact performance. To address this, we introduce a constrained decoding approach based on the N-best list or an ASR lattice. Finally, most EC models are trained for a specific ASR system requiring retraining whenever the underlying ASR system is changed. This paper explores the ability of EC models to operate on the output of different ASR systems. This concept is further extended to zero-shot error correction using LLMs, such as ChatGPT. Experiments on three standard datasets demonstrate the efficacy of our proposed methods for both Transducer and attention-based encoder-decoder ASR systems. In addition, the proposed method can serve as an effective method for model ensembling.
Learn and Don't Forget: Adding a New Language to ASR Foundation Models
Jul 09, 2024



Foundation ASR models often support many languages, e.g. 100 languages in Whisper. However, there has been limited work on integrating an additional, typically low-resource, language, while maintaining performance on the original language set. Fine-tuning, while simple, may degrade the accuracy of the original set. We compare three approaches that exploit adaptation parameters: soft language code tuning, train only the language code; soft prompt tuning, train prepended tokens; and LoRA where a small set of additional parameters are optimised. Elastic Weight Consolidation (EWC) offers an alternative compromise with the potential to maintain performance in specific target languages. Results show that direct fine-tuning yields the best performance for the new language but degrades existing language capabilities. EWC can address this issue for specific languages. If only adaptation parameters are used, the language capabilities are maintained but at the cost of performance in the new language.