 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGAN Hinge Loss
Papers and Code
HingeRLC-GAN: Combating Mode Collapse with Hinge Loss and RLC Regularization
Mar 24, 2025Recent advances in Generative Adversarial Networks (GANs) have demonstrated their capability for producing high-quality images. However, a significant challenge remains mode collapse, which occurs when the generator produces a limited number of data patterns that do not reflect the diversity of the training dataset. This study addresses this issue by proposing a number of architectural changes aimed at increasing the diversity and stability of GAN models. We start by improving the loss function with Wasserstein loss and Gradient Penalty to better capture the full range of data variations. We also investigate various network architectures and conclude that ResNet significantly contributes to increased diversity. Building on these findings, we introduce HingeRLC-GAN, a novel approach that combines RLC Regularization and the Hinge loss function. With a FID Score of 18 and a KID Score of 0.001, our approach outperforms existing methods by effectively balancing training stability and increased diversity.
Generative Adversarial Learning via Kernel Density Discrimination
Jul 13, 2021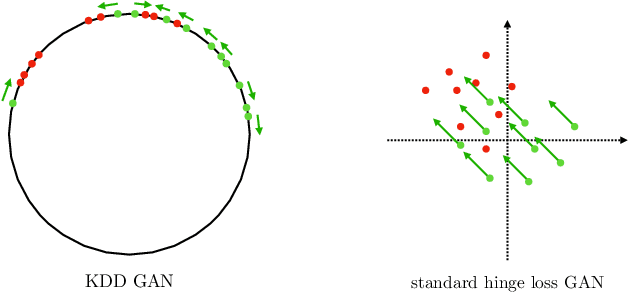
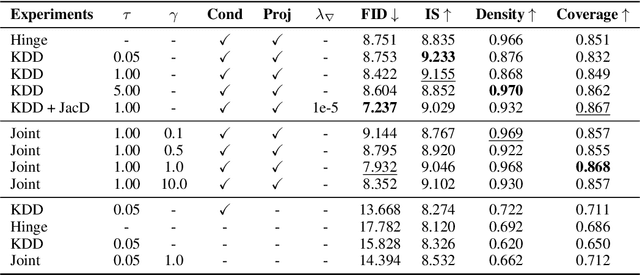

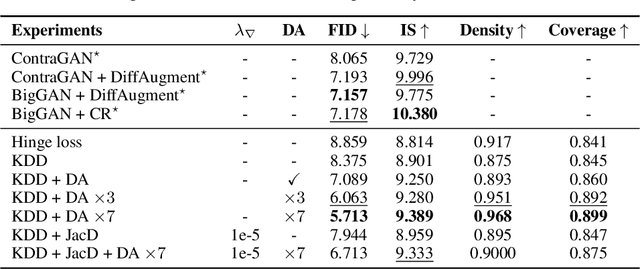
We introduce Kernel Density Discrimination GAN (KDD GAN), a novel method for generative adversarial learning. KDD GAN formulates the training as a likelihood ratio optimization problem where the data distributions are written explicitly via (local) Kernel Density Estimates (KDE). This is inspired by the recent progress in contrastive learning and its relation to KDE. We define the KDEs directly in feature space and forgo the requirement of invertibility of the kernel feature mappings. In our approach, features are no longer optimized for linear separability, as in the original GAN formulation, but for the more general discrimination of distributions in the feature space. We analyze the gradient of our loss with respect to the feature representation and show that it is better behaved than that of the original hinge loss. We perform experiments with the proposed KDE-based loss, used either as a training loss or a regularization term, on both CIFAR10 and scaled versions of ImageNet. We use BigGAN/SA-GAN as a backbone and baseline, since our focus is not to design the architecture of the networks. We show a boost in the quality of generated samples with respect to FID from 10% to 40% compared to the baseline. Code will be made available.
Regularizing Generative Adversarial Networks under Limited Data
Apr 07, 2021
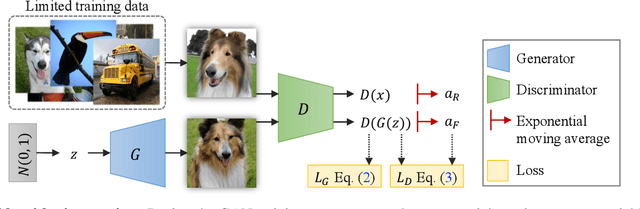
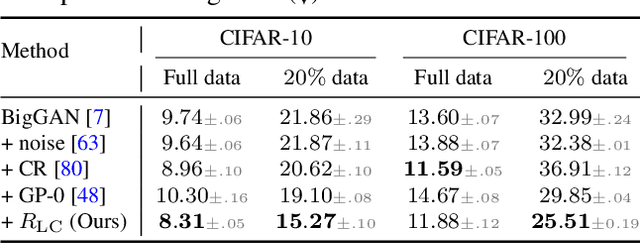
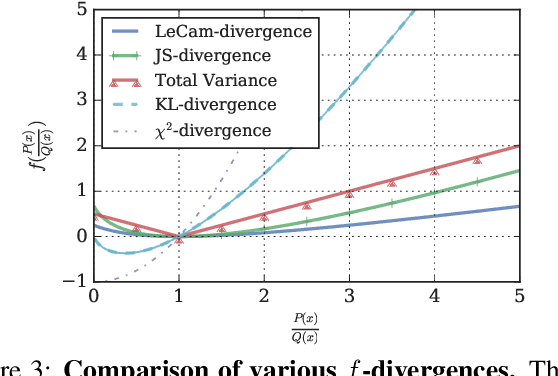
Recent years have witnessed the rapid progress of generative adversarial networks (GANs). However, the success of the GAN models hinges on a large amount of training data. This work proposes a regularization approach for training robust GAN models on limited data. We theoretically show a connection between the regularized loss and an f-divergence called LeCam-divergence, which we find is more robust under limited training data. Extensive experiments on several benchmark datasets demonstrate that the proposed regularization scheme 1) improves the generalization performance and stabilizes the learning dynamics of GAN models under limited training data, and 2) complements the recent data augmentation methods. These properties facilitate training GAN models to achieve state-of-the-art performance when only limited training data of the ImageNet benchmark is available.
cGANs with Multi-Hinge Loss
Dec 09, 2019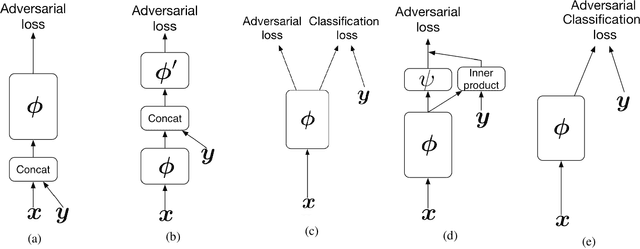
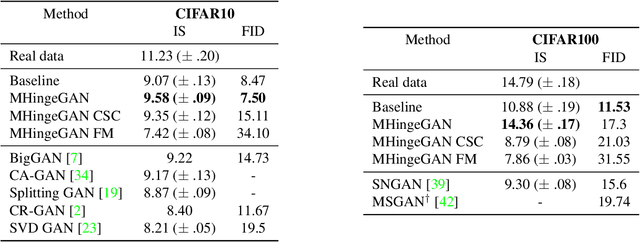
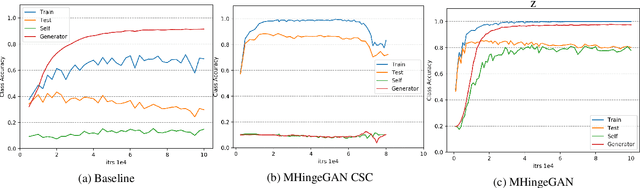

We propose a new algorithm to incorporate class conditional information into the discriminator of GANs via a multi-class generalization of the commonly used Hinge loss. Our approach is in contrast to most GAN frameworks in that we train a single classifier for K+1 classes with one loss function, instead of a real/fake discriminator, or a discriminator classifier pair. We show that learning a single good classifier and a single state of the art generator simultaneously is possible in supervised and semi-supervised settings. With our multi-hinge loss modification we were able to improve the state of the art CIFAR10 IS & FID to 9.58 & 6.40, CIFAR100 IS & FID to 14.36 & 13.32, and STL10 IS & FID to 12.16 & 17.44. The code written with PyTorch is available at https://github.com/ilyakava/BigGAN-PyTorch.
Connections between Support Vector Machines, Wasserstein distance and gradient-penalty GANs
Oct 15, 2019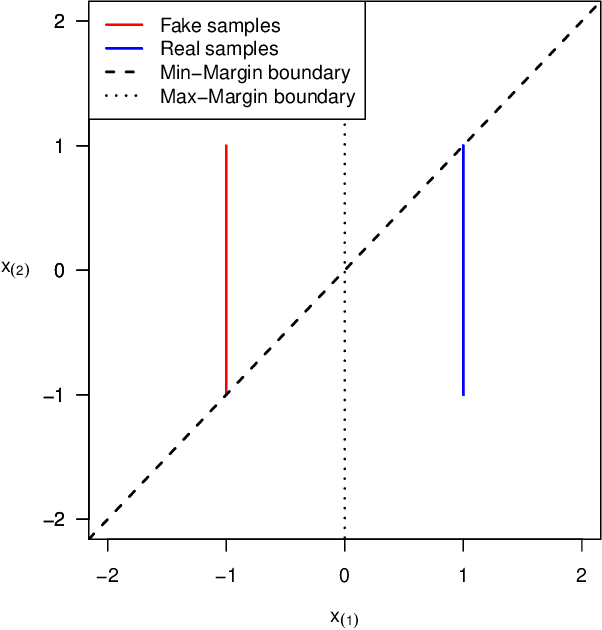

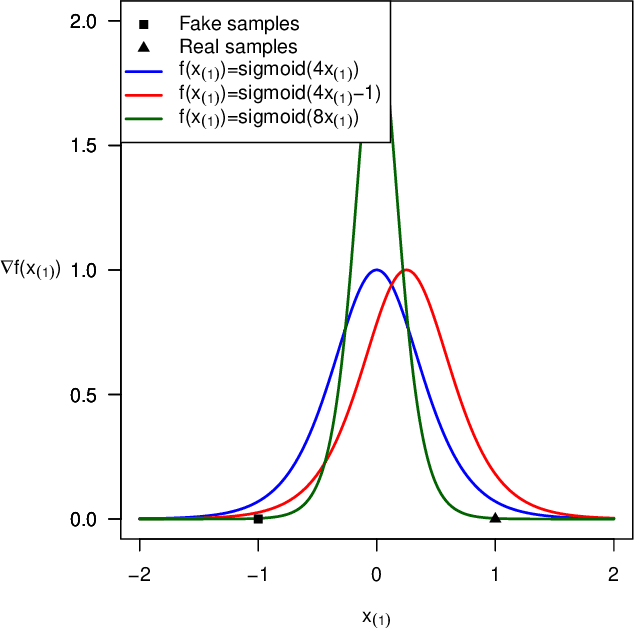
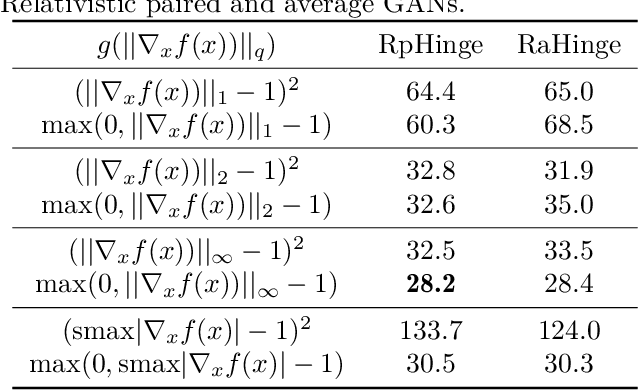
We generalize the concept of maximum-margin classifiers (MMCs) to arbitrary norms and non-linear functions. Support Vector Machines (SVMs) are a special case of MMC. We find that MMCs can be formulated as Integral Probability Metrics (IPMs) or classifiers with some form of gradient norm penalty. This implies a direct link to a class of Generative adversarial networks (GANs) which penalize a gradient norm. We show that the Discriminator in Wasserstein, Standard, Least-Squares, and Hinge GAN with Gradient Penalty is an MMC. We explain why maximizing a margin may be helpful in GANs. We hypothesize and confirm experimentally that $L^\infty$-norm penalties with Hinge loss produce better GANs than $L^2$-norm penalties (based on common evaluation metrics). We derive the margins of Relativistic paired (Rp) and average (Ra) GANs.
Towards Unsupervised Deep Image Enhancement with Generative Adversarial Network
Dec 30, 2020


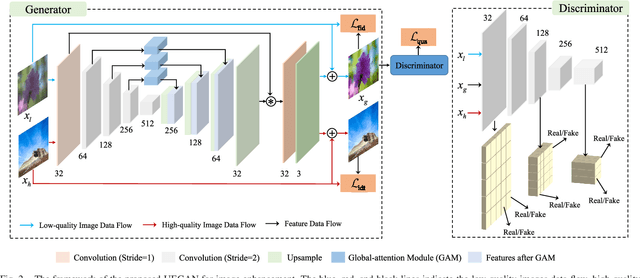
Improving the aesthetic quality of images is challenging and eager for the public. To address this problem, most existing algorithms are based on supervised learning methods to learn an automatic photo enhancer for paired data, which consists of low-quality photos and corresponding expert-retouched versions. However, the style and characteristics of photos retouched by experts may not meet the needs or preferences of general users. In this paper, we present an unsupervised image enhancement generative adversarial network (UEGAN), which learns the corresponding image-to-image mapping from a set of images with desired characteristics in an unsupervised manner, rather than learning on a large number of paired images. The proposed model is based on single deep GAN which embeds the modulation and attention mechanisms to capture richer global and local features. Based on the proposed model, we introduce two losses to deal with the unsupervised image enhancement: (1) fidelity loss, which is defined as a L2 regularization in the feature domain of a pre-trained VGG network to ensure the content between the enhanced image and the input image is the same, and (2) quality loss that is formulated as a relativistic hinge adversarial loss to endow the input image the desired characteristics. Both quantitative and qualitative results show that the proposed model effectively improves the aesthetic quality of images. Our code is available at: https://github.com/eezkni/UEGAN.
RetinaGAN: An Object-aware Approach to Sim-to-Real Transfer
Nov 06, 2020

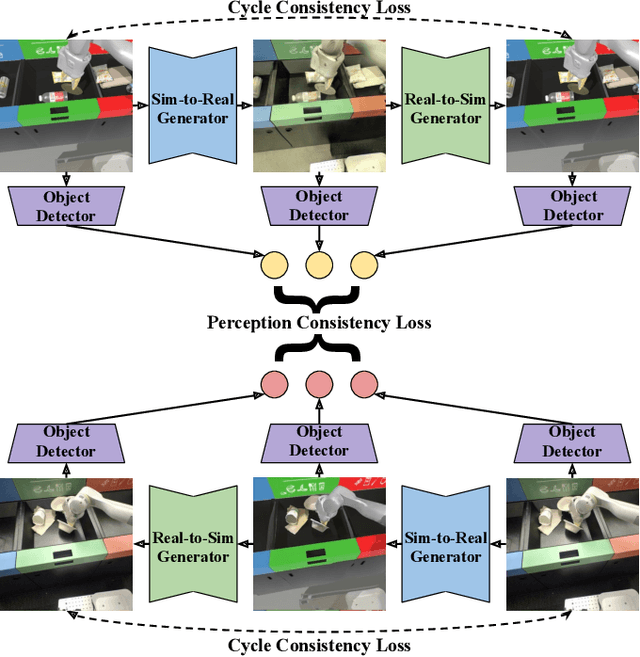
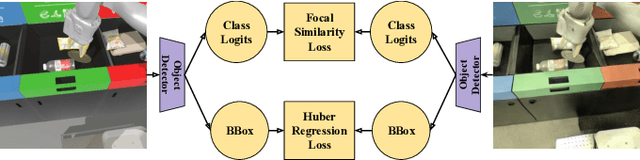
The success of deep reinforcement learning (RL) and imitation learning (IL) in vision-based robotic manipulation typically hinges on the expense of large scale data collection. With simulation, data to train a policy can be collected efficiently at scale, but the visual gap between sim and real makes deployment in the real world difficult. We introduce RetinaGAN, a generative adversarial network (GAN) approach to adapt simulated images to realistic ones with object-detection consistency. RetinaGAN is trained in an unsupervised manner without task loss dependencies, and preserves general object structure and texture in adapted images. We evaluate our method on three real world tasks: grasping, pushing, and door opening. RetinaGAN improves upon the performance of prior sim-to-real methods for RL-based object instance grasping and continues to be effective even in the limited data regime. When applied to a pushing task in a similar visual domain, RetinaGAN demonstrates transfer with no additional real data requirements. We also show our method bridges the visual gap for a novel door opening task using imitation learning in a new visual domain. Visit the project website at https://retinagan.github.io/
Improving MMD-GAN Training with Repulsive Loss Function
Jan 16, 2019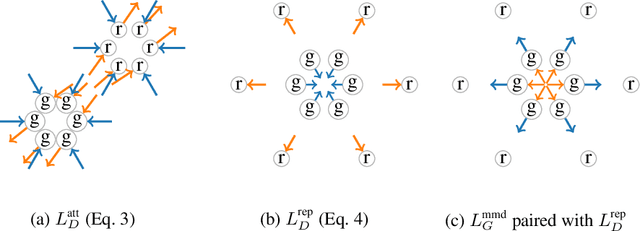
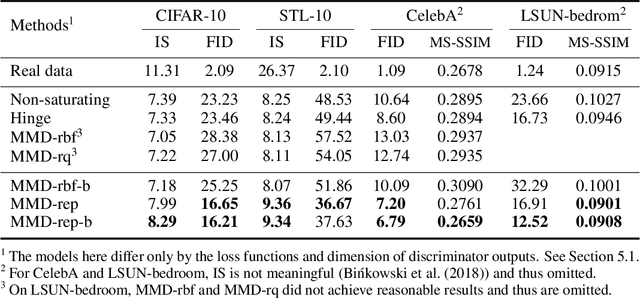
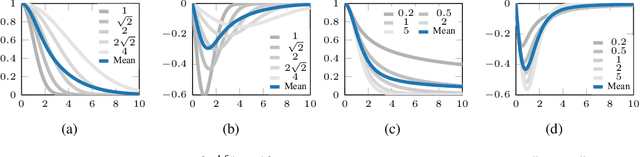
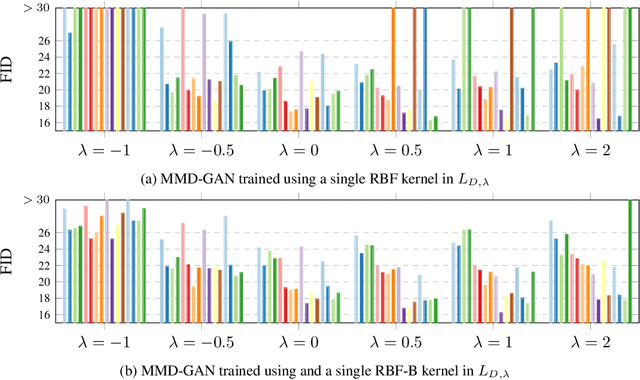
Generative adversarial nets (GANs) are widely used to learn the data sampling process and their performance may heavily depend on the loss functions, given a limited computational budget. This study revisits MMD-GAN that uses the maximum mean discrepancy (MMD) as the loss function for GAN and makes two contributions. First, we argue that the existing MMD loss function may discourage the learning of fine details in data as it attempts to contract the discriminator outputs of real data. To address this issue, we propose a repulsive loss function to actively learn the difference among the real data by simply rearranging the terms in MMD. Second, inspired by the hinge loss, we propose a bounded Gaussian kernel to stabilize the training of MMD-GAN with the repulsive loss function. The proposed methods are applied to the unsupervised image generation tasks on CIFAR-10, STL-10, CelebA, and LSUN bedroom datasets. Results show that the repulsive loss function significantly improves over the MMD loss at no additional computational cost and outperforms other representative loss functions. The proposed methods achieve an FID score of 16.21 on the CIFAR-10 dataset using a single DCGAN network and spectral normalization.
MAGAN: Margin Adaptation for Generative Adversarial Networks
May 23, 2017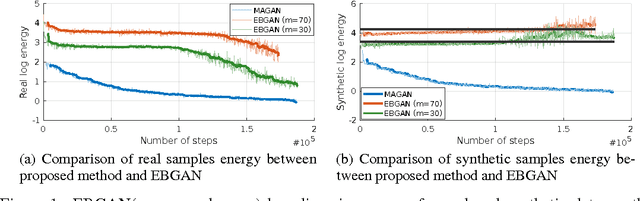
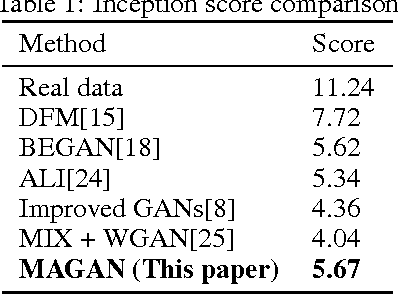


We propose the Margin Adaptation for Generative Adversarial Networks (MAGANs) algorithm, a novel training procedure for GANs to improve stability and performance by using an adaptive hinge loss function. We estimate the appropriate hinge loss margin with the expected energy of the target distribution, and derive principled criteria for when to update the margin. We prove that our method converges to its global optimum under certain assumptions. Evaluated on the task of unsupervised image generation, the proposed training procedure is simple yet robust on a diverse set of data, and achieves qualitative and quantitative improvements compared to the state-of-the-art.