 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHarmonicity Plays a Critical Role in DNN Based Versus in Biologically-Inspired Monaural Speech Segregation Systems
Mar 08, 2022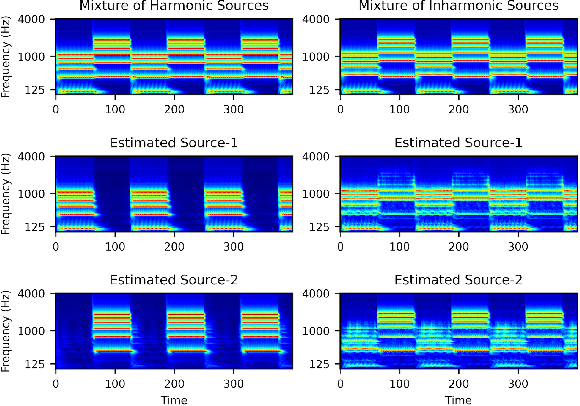
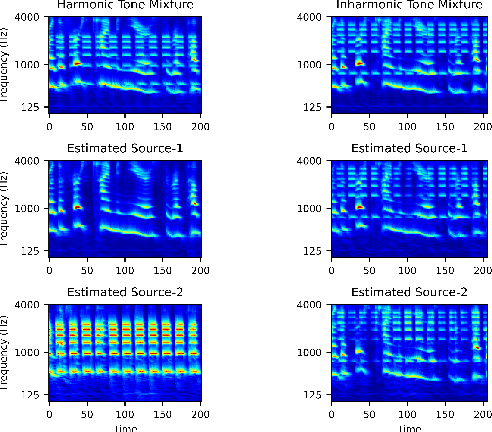
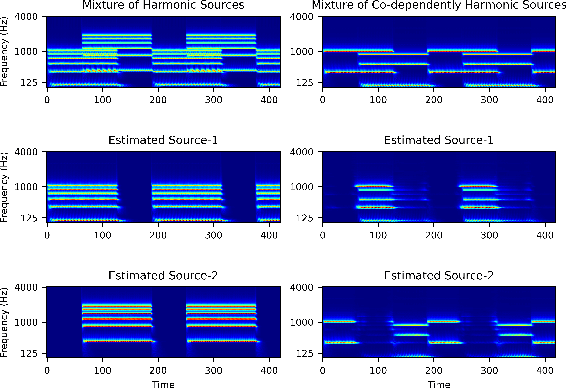
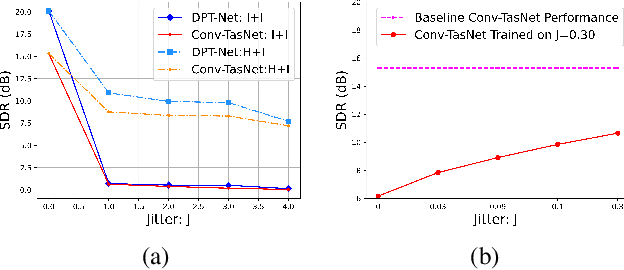
Recent advancements in deep learning have led to drastic improvements in speech segregation models. Despite their success and growing applicability, few efforts have been made to analyze the underlying principles that these networks learn to perform segregation. Here we analyze the role of harmonicity on two state-of-the-art Deep Neural Networks (DNN)-based models- Conv-TasNet and DPT-Net. We evaluate their performance with mixtures of natural speech versus slightly manipulated inharmonic speech, where harmonics are slightly frequency jittered. We find that performance deteriorates significantly if one source is even slightly harmonically jittered, e.g., an imperceptible 3% harmonic jitter degrades performance of Conv-TasNet from 15.4 dB to 0.70 dB. Training the model on inharmonic speech does not remedy this sensitivity, instead resulting in worse performance on natural speech mixtures, making inharmonicity a powerful adversarial factor in DNN models. Furthermore, additional analyses reveal that DNN algorithms deviate markedly from biologically inspired algorithms that rely primarily on timing cues and not harmonicity to segregate speech.
Exploring the high dimensional geometry of HSI features
Mar 01, 2021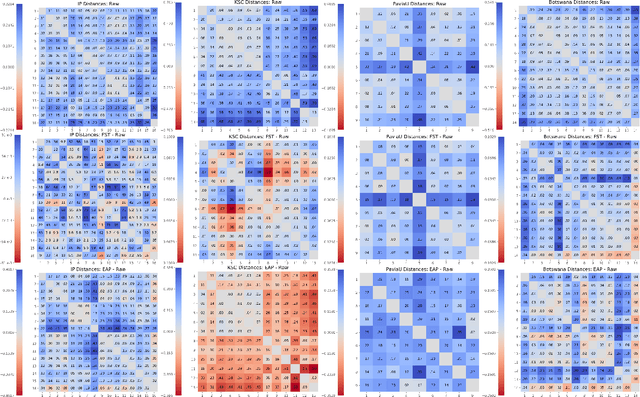

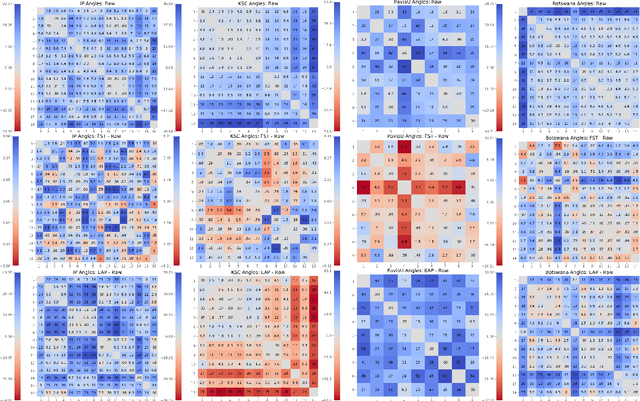

We explore feature space geometries induced by the 3-D Fourier scattering transform and deep neural network with extended attribute profiles on four standard hyperspectral images. We examine the distances and angles of class means, the variability of classes, and their low-dimensional structures. These statistics are compared to that of raw features, and our results provide insight into the vastly different properties of these two methods. We also explore a connection with the newly observed deep learning phenomenon of neural collapse.
Cortical Features for Defense Against Adversarial Audio Attacks
Jan 30, 2021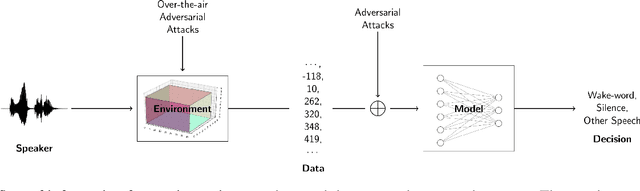
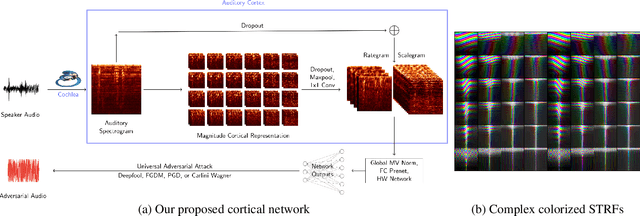

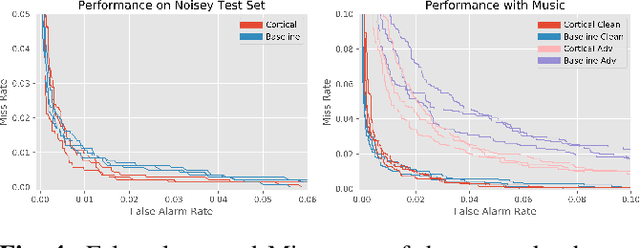
We propose using a computational model of the auditory cortex as a defense against adversarial attacks on audio. We apply several white-box iterative optimization-based adversarial attacks to an implementation of Amazon Alexa's HW network, and a modified version of this network with an integrated cortical representation, and show that the cortical features help defend against universal adversarial examples. At the same level of distortion, the adversarial noises found for the cortical network are always less effective for universal audio attacks. We make our code publicly available at https://github.com/ilyakava/py3fst.
cGANs with Multi-Hinge Loss
Dec 09, 2019
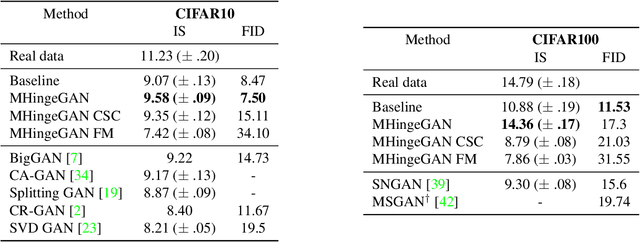
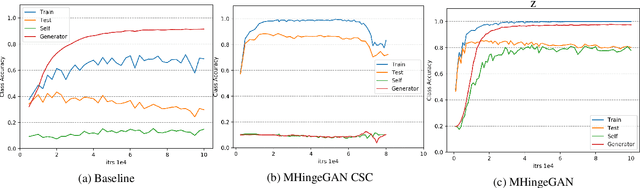

We propose a new algorithm to incorporate class conditional information into the discriminator of GANs via a multi-class generalization of the commonly used Hinge loss. Our approach is in contrast to most GAN frameworks in that we train a single classifier for K+1 classes with one loss function, instead of a real/fake discriminator, or a discriminator classifier pair. We show that learning a single good classifier and a single state of the art generator simultaneously is possible in supervised and semi-supervised settings. With our multi-hinge loss modification we were able to improve the state of the art CIFAR10 IS & FID to 9.58 & 6.40, CIFAR100 IS & FID to 14.36 & 13.32, and STL10 IS & FID to 12.16 & 17.44. The code written with PyTorch is available at https://github.com/ilyakava/BigGAN-PyTorch.
Three-Dimensional Fourier Scattering Transform and Classification of Hyperspectral Images
Jun 17, 2019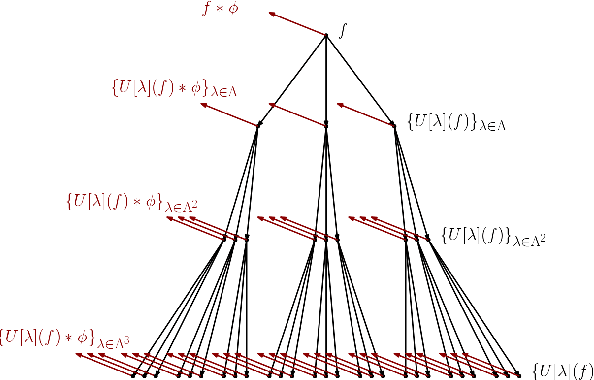

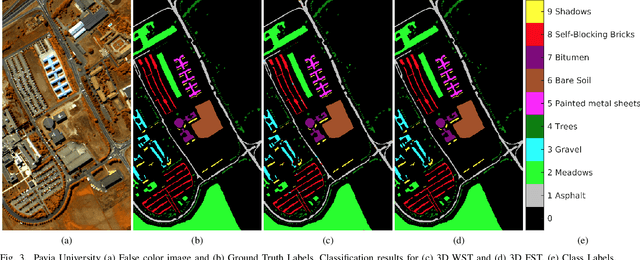
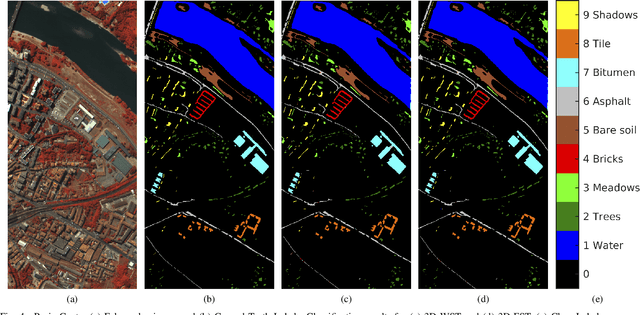
Recent research has resulted in many new techniques that are able to capture the special properties of hyperspectral data for hyperspectral image analysis, with hyperspectral image classification as one of the most active tasks. Time-frequency methods decompose spectra into multi-spectral bands, while hierarchical methods like neural networks incorporate spatial information across scales and model multiple levels of dependencies between spectral features. The Fourier scattering transform is an amalgamation of time-frequency representations with neural network architectures, both of which have recently been proven to provide significant advances in spectral-spatial classification. We test the proposed three dimensional Fourier scattering method on four standard hyperspectral datasets, and present results that indicate that the Fourier scattering transform is highly effective at representing spectral data when compared with other state-of-the-art spectral-spatial classification methods.
Universal Sound Separation
May 08, 2019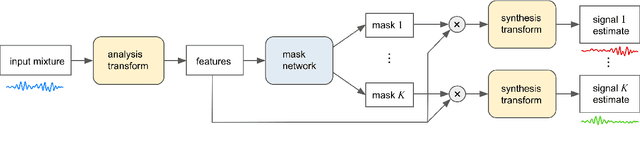
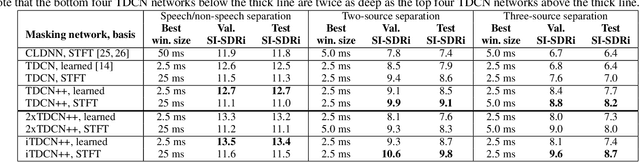
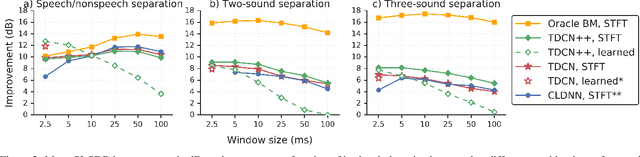
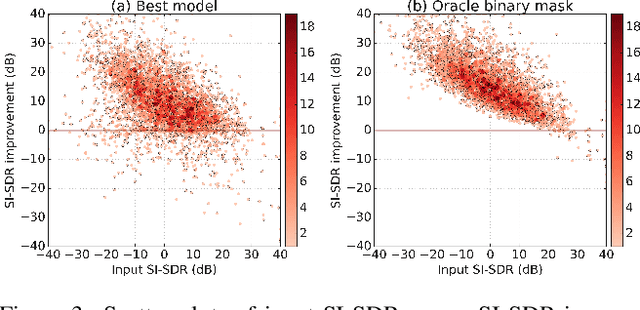
Recent deep learning approaches have achieved impressive performance on speech enhancement and separation tasks. However, these approaches have not been investigated for separating mixtures of arbitrary sounds of different types, a task we refer to as universal sound separation, and it is unknown whether performance on speech tasks carries over to non-speech tasks. To study this question, we develop a universal dataset of mixtures containing arbitrary sounds, and use it to investigate the space of mask-based separation architectures, varying both the overall network architecture and the framewise analysis-synthesis basis for signal transformations. These network architectures include convolutional long short-term memory networks and time-dilated convolution stacks inspired by the recent success of time-domain enhancement networks like ConvTasNet. For the latter architecture, we also propose novel modifications that further improve separation performance. In terms of the framewise analysis-synthesis basis, we explore using either a short-time Fourier transform (STFT) or a learnable basis, as used in ConvTasNet, and for both of these bases, we examine the effect of window size. In particular, for STFTs, we find that longer windows (25-50 ms) work best for speech/non-speech separation, while shorter windows (2.5 ms) work best for arbitrary sounds. For learnable bases, shorter windows (2.5 ms) work best on all tasks. Surprisingly, for universal sound separation, STFTs outperform learnable bases. Our best methods produce an improvement in scale-invariant signal-to-distortion ratio of over 13 dB for speech/non-speech separation and close to 10 dB for universal sound separation.