 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDvs128 Gesture Dataset
Papers and Code
Surrogates, Spikes, and Sparsity: Performance Analysis and Characterization of SNN Hyperparameters on Hardware
Mar 26, 2026Spiking Neural Networks (SNNs) offer inherent advantages for low-power inference through sparse, event-driven computation. However, the theoretical energy benefits of SNNs are often decoupled from real hardware performance due to the opaque relationship between training-time choices and inference-time sparsity. While prior work has focused on weight pruning and compression, the role of training hyperparameters -- specifically surrogate gradient functions and neuron model configurations -- in shaping hardware-level activation sparsity remains underexplored. This paper presents a workload characterization study quantifying the sensitivity of hardware latency to SNN hyperparameters. We decouple the impact of surrogate gradient functions (e.g., Fast Sigmoid, Spike Rate Escape) and neuron models (LIF, Lapicque) on classification accuracy and inference efficiency across three event-based vision datasets: DVS128-Gesture, N-MNIST, and DVS-CIFAR10. Our analysis reveals that standard accuracy metrics are poor predictors of hardware efficiency. While Fast Sigmoid achieves the highest accuracy on DVS-CIFAR10, Spike Rate Escape reduces inference latency by up to 12.2% on DVS128-Gesture with minimal accuracy trade-offs. We also demonstrate that neuron model selection is as critical as parameter tuning; transitioning from LIF to Lapicque neurons yields up to 28% latency reduction. We validate on a custom cycle-accurate FPGA-based SNN instrumentation platform, showing that sparsity-aware hyperparameter selection can improve accuracy by 9.1% and latency by over 2x compared to baselines. These findings establish a methodology for predicting hardware behavior from training parameters. The RTL and reproducibility artifacts are at https://zenodo.org/records/18893738.
NSPDI-SNN: An efficient lightweight SNN based on nonlinear synaptic pruning and dendritic integration
Aug 29, 2025Spiking neural networks (SNNs) are artificial neural networks based on simulated biological neurons and have attracted much attention in recent artificial intelligence technology studies. The dendrites in biological neurons have efficient information processing ability and computational power; however, the neurons of SNNs rarely match the complex structure of the dendrites. Inspired by the nonlinear structure and highly sparse properties of neuronal dendrites, in this study, we propose an efficient, lightweight SNN method with nonlinear pruning and dendritic integration (NSPDI-SNN). In this method, we introduce nonlinear dendritic integration (NDI) to improve the representation of the spatiotemporal information of neurons. We implement heterogeneous state transition ratios of dendritic spines and construct a new and flexible nonlinear synaptic pruning (NSP) method to achieve the high sparsity of SNN. We conducted systematic experiments on three benchmark datasets (DVS128 Gesture, CIFAR10-DVS, and CIFAR10) and extended the evaluation to two complex tasks (speech recognition and reinforcement learning-based maze navigation task). Across all tasks, NSPDI-SNN consistently achieved high sparsity with minimal performance degradation. In particular, our method achieved the best experimental results on all three event stream datasets. Further analysis showed that NSPDI significantly improved the efficiency of synaptic information transfer as sparsity increased. In conclusion, our results indicate that the complex structure and nonlinear computation of neuronal dendrites provide a promising approach for developing efficient SNN methods.
Optimal Spiking Brain Compression: Improving One-Shot Post-Training Pruning and Quantization for Spiking Neural Networks
Jun 04, 2025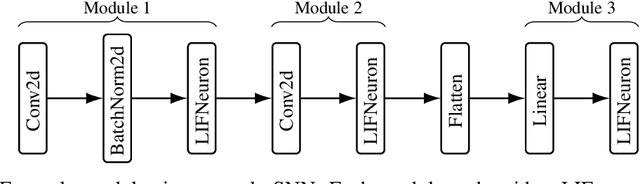
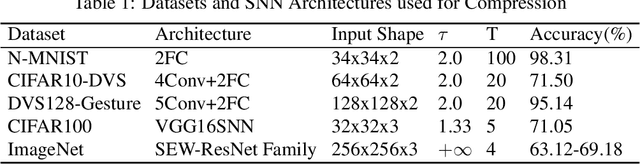
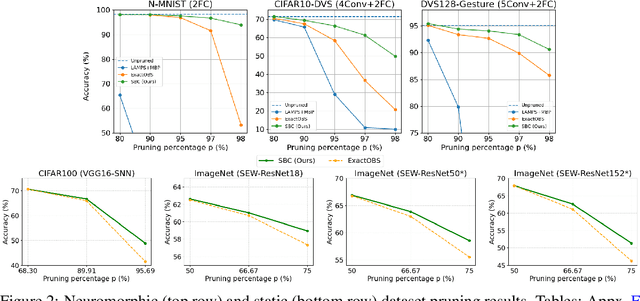
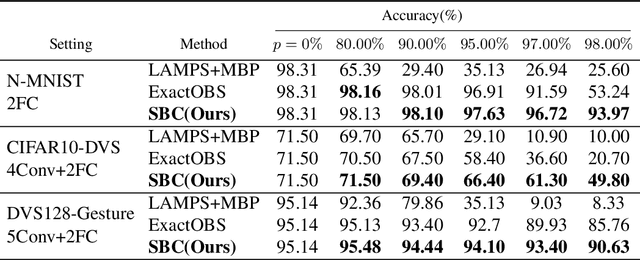
Spiking Neural Networks (SNNs) have emerged as a new generation of energy-efficient neural networks suitable for implementation on neuromorphic hardware. As neuromorphic hardware has limited memory and computing resources, weight pruning and quantization have recently been explored to improve SNNs' efficiency. State-of-the-art SNN pruning/quantization methods employ multiple compression and training iterations, increasing the cost for pre-trained or very large SNNs. In this paper, we propose a new one-shot post-training pruning/quantization framework, Optimal Spiking Brain Compression (OSBC), that adapts the Optimal Brain Compression (OBC) method of [Frantar, Singh, and Alistarh, 2023] for SNNs. Rather than minimizing the loss on neuron input current as OBC does, OSBC achieves more efficient and accurate SNN compression in one pass by minimizing the loss on spiking neuron membrane potential with a small sample dataset. Our experiments on neuromorphic datasets (N-MNIST, CIFAR10-DVS, DVS128-Gesture) demonstrate that OSBC can achieve 97% sparsity through pruning with 1.41%, 10.20%, and 1.74% accuracy loss, or 4-bit symmetric quantization with 0.17%, 1.54%, and 7.71% accuracy loss, respectively. Code will be available on GitHub.
LightSNN: Lightweight Architecture Search for Sparse and Accurate Spiking Neural Networks
Mar 27, 2025Spiking Neural Networks (SNNs) are highly regarded for their energy efficiency, inherent activation sparsity, and suitability for real-time processing in edge devices. However, most current SNN methods adopt architectures resembling traditional artificial neural networks (ANNs), leading to suboptimal performance when applied to SNNs. While SNNs excel in energy efficiency, they have been associated with lower accuracy levels than traditional ANNs when utilizing conventional architectures. In response, in this work we present LightSNN, a rapid and efficient Neural Network Architecture Search (NAS) technique specifically tailored for SNNs that autonomously leverages the most suitable architecture, striking a good balance between accuracy and efficiency by enforcing sparsity. Based on the spiking NAS network (SNASNet) framework, a cell-based search space including backward connections is utilized to build our training-free pruning-based NAS mechanism. Our technique assesses diverse spike activation patterns across different data samples using a sparsity-aware Hamming distance fitness evaluation. Thorough experiments are conducted on both static (CIFAR10 and CIFAR100) and neuromorphic datasets (DVS128-Gesture). Our LightSNN model achieves state-of-the-art results on CIFAR10 and CIFAR100, improves performance on DVS128Gesture by 4.49%, and significantly reduces search time, most notably offering a 98x speedup over SNASNet and running 30% faster than the best existing method on DVS128Gesture.
Maximizing Asynchronicity in Event-based Neural Networks
May 16, 2025Event cameras deliver visual data with high temporal resolution, low latency, and minimal redundancy, yet their asynchronous, sparse sequential nature challenges standard tensor-based machine learning (ML). While the recent asynchronous-to-synchronous (A2S) paradigm aims to bridge this gap by asynchronously encoding events into learned representations for ML pipelines, existing A2S approaches often sacrifice representation expressivity and generalizability compared to dense, synchronous methods. This paper introduces EVA (EVent Asynchronous representation learning), a novel A2S framework to generate highly expressive and generalizable event-by-event representations. Inspired by the analogy between events and language, EVA uniquely adapts advances from language modeling in linear attention and self-supervised learning for its construction. In demonstration, EVA outperforms prior A2S methods on recognition tasks (DVS128-Gesture and N-Cars), and represents the first A2S framework to successfully master demanding detection tasks, achieving a remarkable 47.7 mAP on the Gen1 dataset. These results underscore EVA's transformative potential for advancing real-time event-based vision applications.
EgoEvGesture: Gesture Recognition Based on Egocentric Event Camera
Mar 16, 2025



Egocentric gesture recognition is a pivotal technology for enhancing natural human-computer interaction, yet traditional RGB-based solutions suffer from motion blur and illumination variations in dynamic scenarios. While event cameras show distinct advantages in handling high dynamic range with ultra-low power consumption, existing RGB-based architectures face inherent limitations in processing asynchronous event streams due to their synchronous frame-based nature. Moreover, from an egocentric perspective, event cameras record data that include events generated by both head movements and hand gestures, thereby increasing the complexity of gesture recognition. To address this, we propose a novel network architecture specifically designed for event data processing, incorporating (1) a lightweight CNN with asymmetric depthwise convolutions to reduce parameters while preserving spatiotemporal features, (2) a plug-and-play state-space model as context block that decouples head movement noise from gesture dynamics, and (3) a parameter-free Bins-Temporal Shift Module (BSTM) that shifts features along bins and temporal dimensions to fuse sparse events efficiently. We further build the EgoEvGesture dataset, the first large-scale dataset for egocentric gesture recognition using event cameras. Experimental results demonstrate that our method achieves 62.7% accuracy in heterogeneous testing with only 7M parameters, 3.1% higher than state-of-the-art approaches. Notable misclassifications in freestyle motions stem from high inter-personal variability and unseen test patterns differing from training data. Moreover, our approach achieved a remarkable accuracy of 96.97% on DVS128 Gesture, demonstrating strong cross-dataset generalization capability. The dataset and models are made publicly available at https://github.com/3190105222/EgoEv_Gesture.
STREAM: A Universal State-Space Model for Sparse Geometric Data
Nov 19, 2024Handling sparse and unstructured geometric data, such as point clouds or event-based vision, is a pressing challenge in the field of machine vision. Recently, sequence models such as Transformers and state-space models entered the domain of geometric data. These methods require specialized preprocessing to create a sequential view of a set of points. Furthermore, prior works involving sequence models iterate geometric data with either uniform or learned step sizes, implicitly relying on the model to infer the underlying geometric structure. In this work, we propose to encode geometric structure explicitly into the parameterization of a state-space model. State-space models are based on linear dynamics governed by a one-dimensional variable such as time or a spatial coordinate. We exploit this dynamic variable to inject relative differences of coordinates into the step size of the state-space model. The resulting geometric operation computes interactions between all pairs of N points in O(N) steps. Our model deploys the Mamba selective state-space model with a modified CUDA kernel to efficiently map sparse geometric data to modern hardware. The resulting sequence model, which we call STREAM, achieves competitive results on a range of benchmarks from point-cloud classification to event-based vision and audio classification. STREAM demonstrates a powerful inductive bias for sparse geometric data by improving the PointMamba baseline when trained from scratch on the ModelNet40 and ScanObjectNN point cloud analysis datasets. It further achieves, for the first time, 100% test accuracy on all 11 classes of the DVS128 Gestures dataset.
Fractional-order spike-timing-dependent gradient descent for multi-layer spiking neural networks
Oct 20, 2024



Accumulated detailed knowledge about the neuronal activities in human brains has brought more attention to bio-inspired spiking neural networks (SNNs). In contrast to non-spiking deep neural networks (DNNs), SNNs can encode and transmit spatiotemporal information more efficiently by exploiting biologically realistic and low-power event-driven neuromorphic architectures. However, the supervised learning of SNNs still remains a challenge because the spike-timing-dependent plasticity (STDP) of connected spiking neurons is difficult to implement and interpret in existing backpropagation learning schemes. This paper proposes a fractional-order spike-timing-dependent gradient descent (FO-STDGD) learning model by considering a derived nonlinear activation function that describes the relationship between the quasi-instantaneous firing rate and the temporal membrane potentials of nonleaky integrate-and-fire neurons. The training strategy can be generalized to any fractional orders between 0 and 2 since the FO-STDGD incorporates the fractional gradient descent method into the calculation of spike-timing-dependent loss gradients. The proposed FO-STDGD model is tested on the MNIST and DVS128 Gesture datasets and its accuracy under different network structure and fractional orders is analyzed. It can be found that the classification accuracy increases as the fractional order increases, and specifically, the case of fractional order 1.9 improves by 155% relative to the case of fractional order 1 (traditional gradient descent). In addition, our scheme demonstrates the state-of-the-art computational efficacy for the same SNN structure and training epochs.
* 15 pages, 12 figures
TSkips: Efficiency Through Explicit Temporal Delay Connections in Spiking Neural Networks
Nov 22, 2024



Spiking Neural Networks (SNNs) with their bio-inspired Leaky Integrate-and-Fire (LIF) neurons inherently capture temporal information. This makes them well-suited for sequential tasks like processing event-based data from Dynamic Vision Sensors (DVS) and event-based speech tasks. Harnessing the temporal capabilities of SNNs requires mitigating vanishing spikes during training, capturing spatio-temporal patterns and enhancing precise spike timing. To address these challenges, we propose TSkips, augmenting SNN architectures with forward and backward skip connections that incorporate explicit temporal delays. These connections capture long-term spatio-temporal dependencies and facilitate better spike flow over long sequences. The introduction of TSkips creates a vast search space of possible configurations, encompassing skip positions and time delay values. To efficiently navigate this search space, this work leverages training-free Neural Architecture Search (NAS) to identify optimal network structures and corresponding delays. We demonstrate the effectiveness of our approach on four event-based datasets: DSEC-flow for optical flow estimation, DVS128 Gesture for hand gesture recognition and Spiking Heidelberg Digits (SHD) and Spiking Speech Commands (SSC) for speech recognition. Our method achieves significant improvements across these datasets: up to 18% reduction in Average Endpoint Error (AEE) on DSEC-flow, 8% increase in classification accuracy on DVS128 Gesture, and up to 8% and 16% higher classification accuracy on SHD and SSC, respectively.
Event USKT : U-State Space Model in Knowledge Transfer for Event Cameras
Nov 22, 2024



Event cameras, as an emerging imaging technology, offer distinct advantages over traditional RGB cameras, including reduced energy consumption and higher frame rates. However, the limited quantity of available event data presents a significant challenge, hindering their broader development. To alleviate this issue, we introduce a tailored U-shaped State Space Model Knowledge Transfer (USKT) framework for Event-to-RGB knowledge transfer. This framework generates inputs compatible with RGB frames, enabling event data to effectively reuse pre-trained RGB models and achieve competitive performance with minimal parameter tuning. Within the USKT architecture, we also propose a bidirectional reverse state space model. Unlike conventional bidirectional scanning mechanisms, the proposed Bidirectional Reverse State Space Model (BiR-SSM) leverages a shared weight strategy, which facilitates efficient modeling while conserving computational resources. In terms of effectiveness, integrating USKT with ResNet50 as the backbone improves model performance by 0.95%, 3.57%, and 2.9% on DVS128 Gesture, N-Caltech101, and CIFAR-10-DVS datasets, respectively, underscoring USKT's adaptability and effectiveness. The code will be made available upon acceptance.