 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDrone View Target Localization
Papers and Code
Towards Open-World Referring Expression Comprehension: A Benchmark with Training-free Multi-task Consistency Checker
May 25, 2026Referring expression comprehension (REC) aims to localize a target object within an image based on a given expression. Although recent advances in vision-language models have led to substantial improvements in REC tasks, current REC benchmarks often hold simple scenarios and the assumption that each expression maps to a unique object. These limitations hinder the deployment of REC models in open-world environments. To fill this gap, we introduce OpenRef, a new benchmark for REC in complex visual and linguistic scenarios. OpenRef features three key advancements: 1) Diverse visual scenarios: spanning diverse visual domains, including ground views, drone views, dark scenes and adverse weather conditions; 2) Variable target counts: breaking the single-target limitation with multi-target and none-target samples; 3) Rich vocabulary types: incorporating proper nouns, polysemous words and ordinal terms to fit a wider range of expression needs. Furthermore, as traditional metrics are insufficient for open-world setting, we leverage F1 to measure grounding accuracy and propose N3R (Negative Relative Rejection Reliability) to assess relative rejection reliability against negative expressions. Finally, we introduce Multi-task Consistency Checker (MCC), a training-free but plug-and-play strategy that enhances model performance with one click by enforcing consistency self-verification. Extensive experiments demonstrate that this work significantly advances the performance of existing REC models in complex scenarios, paving the way for open-world REC. Project page: https://zongjianwu.github.io/openref
MMOT: The First Challenging Benchmark for Drone-based Multispectral Multi-Object Tracking
Oct 14, 2025Drone-based multi-object tracking is essential yet highly challenging due to small targets, severe occlusions, and cluttered backgrounds. Existing RGB-based tracking algorithms heavily depend on spatial appearance cues such as color and texture, which often degrade in aerial views, compromising reliability. Multispectral imagery, capturing pixel-level spectral reflectance, provides crucial cues that enhance object discriminability under degraded spatial conditions. However, the lack of dedicated multispectral UAV datasets has hindered progress in this domain. To bridge this gap, we introduce MMOT, the first challenging benchmark for drone-based multispectral multi-object tracking. It features three key characteristics: (i) Large Scale - 125 video sequences with over 488.8K annotations across eight categories; (ii) Comprehensive Challenges - covering diverse conditions such as extreme small targets, high-density scenarios, severe occlusions, and complex motion; and (iii) Precise Oriented Annotations - enabling accurate localization and reduced ambiguity under aerial perspectives. To better extract spectral features and leverage oriented annotations, we further present a multispectral and orientation-aware MOT scheme adapting existing methods, featuring: (i) a lightweight Spectral 3D-Stem integrating spectral features while preserving compatibility with RGB pretraining; (ii) an orientation-aware Kalman filter for precise state estimation; and (iii) an end-to-end orientation-adaptive transformer. Extensive experiments across representative trackers consistently show that multispectral input markedly improves tracking performance over RGB baselines, particularly for small and densely packed objects. We believe our work will advance drone-based multispectral multi-object tracking research. Our MMOT, code, and benchmarks are publicly available at https://github.com/Annzstbl/MMOT.
HCCM: Hierarchical Cross-Granularity Contrastive and Matching Learning for Natural Language-Guided Drones
Aug 29, 2025Natural Language-Guided Drones (NLGD) provide a novel paradigm for tasks such as target matching and navigation. However, the wide field of view and complex compositional semantics in drone scenarios pose challenges for vision-language understanding. Mainstream Vision-Language Models (VLMs) emphasize global alignment while lacking fine-grained semantics, and existing hierarchical methods depend on precise entity partitioning and strict containment, limiting effectiveness in dynamic environments. To address this, we propose the Hierarchical Cross-Granularity Contrastive and Matching learning (HCCM) framework with two components: (1) Region-Global Image-Text Contrastive Learning (RG-ITC), which avoids precise scene partitioning and captures hierarchical local-to-global semantics by contrasting local visual regions with global text and vice versa; (2) Region-Global Image-Text Matching (RG-ITM), which dispenses with rigid constraints and instead evaluates local semantic consistency within global cross-modal representations, enhancing compositional reasoning. Moreover, drone text descriptions are often incomplete or ambiguous, destabilizing alignment. HCCM introduces a Momentum Contrast and Distillation (MCD) mechanism to improve robustness. Experiments on GeoText-1652 show HCCM achieves state-of-the-art Recall@1 of 28.8% (image retrieval) and 14.7% (text retrieval). On the unseen ERA dataset, HCCM demonstrates strong zero-shot generalization with 39.93% mean recall (mR), outperforming fine-tuned baselines.
PAUL: Uncertainty-Guided Partition and Augmentation for Robust Cross-View Geo-Localization under Noisy Correspondence
Aug 27, 2025Cross-view geo-localization is a critical task for UAV navigation, event detection, and aerial surveying, as it enables matching between drone-captured and satellite imagery. Most existing approaches embed multi-modal data into a joint feature space to maximize the similarity of paired images. However, these methods typically assume perfect alignment of image pairs during training, which rarely holds true in real-world scenarios. In practice, factors such as urban canyon effects, electromagnetic interference, and adverse weather frequently induce GPS drift, resulting in systematic alignment shifts where only partial correspondences exist between pairs. Despite its prevalence, this source of noisy correspondence has received limited attention in current research. In this paper, we formally introduce and address the Noisy Correspondence on Cross-View Geo-Localization (NC-CVGL) problem, aiming to bridge the gap between idealized benchmarks and practical applications. To this end, we propose PAUL (Partition and Augmentation by Uncertainty Learning), a novel framework that partitions and augments training data based on estimated data uncertainty through uncertainty-aware co-augmentation and evidential co-training. Specifically, PAUL selectively augments regions with high correspondence confidence and utilizes uncertainty estimation to refine feature learning, effectively suppressing noise from misaligned pairs. Distinct from traditional filtering or label correction, PAUL leverages both data uncertainty and loss discrepancy for targeted partitioning and augmentation, thus providing robust supervision for noisy samples. Comprehensive experiments validate the effectiveness of individual components in PAUL,which consistently achieves superior performance over other competitive noisy-correspondence-driven methods in various noise ratios.
Game4Loc: A UAV Geo-Localization Benchmark from Game Data
Sep 25, 2024



The vision-based geo-localization technology for UAV, serving as a secondary source of GPS information in addition to the global navigation satellite systems (GNSS), can still operate independently in the GPS-denied environment. Recent deep learning based methods attribute this as the task of image matching and retrieval. By retrieving drone-view images in geo-tagged satellite image database, approximate localization information can be obtained. However, due to high costs and privacy concerns, it is usually difficult to obtain large quantities of drone-view images from a continuous area. Existing drone-view datasets are mostly composed of small-scale aerial photography with a strong assumption that there exists a perfect one-to-one aligned reference image for any query, leaving a significant gap from the practical localization scenario. In this work, we construct a large-range contiguous area UAV geo-localization dataset named GTA-UAV, featuring multiple flight altitudes, attitudes, scenes, and targets using modern computer games. Based on this dataset, we introduce a more practical UAV geo-localization task including partial matches of cross-view paired data, and expand the image-level retrieval to the actual localization in terms of distance (meters). For the construction of drone-view and satellite-view pairs, we adopt a weight-based contrastive learning approach, which allows for effective learning while avoiding additional post-processing matching steps. Experiments demonstrate the effectiveness of our data and training method for UAV geo-localization, as well as the generalization capabilities to real-world scenarios.
An Autonomous Drone Swarm for Detecting and Tracking Anomalies among Dense Vegetation
Jul 15, 2024Swarms of drones offer an increased sensing aperture, and having them mimic behaviors of natural swarms enhances sampling by adapting the aperture to local conditions. We demonstrate that such an approach makes detecting and tracking heavily occluded targets practically feasible. While object classification applied to conventional aerial images generalizes poorly the randomness of occlusion and is therefore inefficient even under lightly occluded conditions, anomaly detection applied to synthetic aperture integral images is robust for dense vegetation, such as forests, and is independent of pre-trained classes. Our autonomous swarm searches the environment for occurrences of the unknown or unexpected, tracking them while continuously adapting its sampling pattern to optimize for local viewing conditions. In our real-life field experiments with a swarm of six drones, we achieved an average positional accuracy of 0.39 m with an average precision of 93.2% and an average recall of 95.9%. Here, adapted particle swarm optimization considers detection confidences and predicted target appearance. We show that sensor noise can effectively be included in the synthetic aperture image integration process, removing the need for a computationally costly optimization of high-dimensional parameter spaces. Finally, we present a complete hard- and software framework that supports low-latency transmission (approx. 80 ms round-trip time) and fast processing (approx. 600 ms per formation step) of extensive (70-120 Mbit/s) video and telemetry data, and swarm control for swarms of up to ten drones.
A New Clustering-based View Planning Method for Building Inspection with Drone
Jul 19, 2024



With the rapid development of drone technology, the application of drones equipped with visual sensors for building inspection and surveillance has attracted much attention. View planning aims to find a set of near-optimal viewpoints for vision-related tasks to achieve the vision coverage goal. This paper proposes a new clustering-based two-step computational method using spectral clustering, local potential field method, and hyper-heuristic algorithm to find near-optimal views to cover the target building surface. In the first step, the proposed method generates candidate viewpoints based on spectral clustering and corrects the positions of candidate viewpoints based on our newly proposed local potential field method. In the second step, the optimization problem is converted into a Set Covering Problem (SCP), and the optimal viewpoint subset is solved using our proposed hyper-heuristic algorithm. Experimental results show that the proposed method is able to obtain better solutions with fewer viewpoints and higher coverage.
SDPL: Shifting-Dense Partition Learning for UAV-View Geo-Localization
Mar 07, 2024



Cross-view geo-localization aims to match images of the same target from different platforms, e.g., drone and satellite. It is a challenging task due to the changing both appearance of targets and environmental content from different views. Existing methods mainly focus on digging more comprehensive information through feature maps segmentation, while inevitably destroy the image structure and are sensitive to the shifting and scale of the target in the query. To address the above issues, we introduce a simple yet effective part-based representation learning, called shifting-dense partition learning (SDPL). Specifically, we propose the dense partition strategy (DPS), which divides the image into multiple parts to explore contextual-information while explicitly maintain the global structure. To handle scenarios with non-centered targets, we further propose the shifting-fusion strategy, which generates multiple sets of parts in parallel based on various segmentation centers and then adaptively fuses all features to select the best partitions. Extensive experiments show that our SDPL is robust to position shifting and scale variations, and achieves competitive performance on two prevailing benchmarks, i.e., University-1652 and SUES-200.
Synthetic Aperture Sensing for Occlusion Removal with Drone Swarms
Dec 30, 2022



We demonstrate how efficient autonomous drone swarms can be in detecting and tracking occluded targets in densely forested areas, such as lost people during search and rescue missions. Exploration and optimization of local viewing conditions, such as occlusion density and target view obliqueness, provide much faster and much more reliable results than previous, blind sampling strategies that are based on pre-defined waypoints. An adapted real-time particle swarm optimization and a new objective function are presented that are able to deal with dynamic and highly random through-foliage conditions. Synthetic aperture sensing is our fundamental sampling principle, and drone swarms are employed to approximate the optical signals of extremely wide and adaptable airborne lenses.
A Transformer-Based Feature Segmentation and Region Alignment Method For UAV-View Geo-Localization
Jan 23, 2022
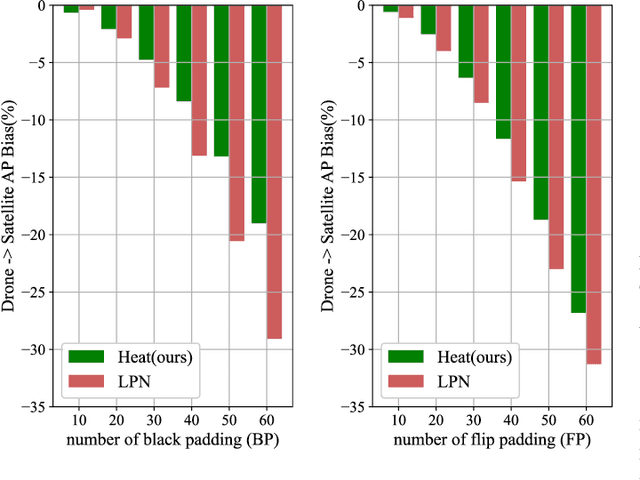
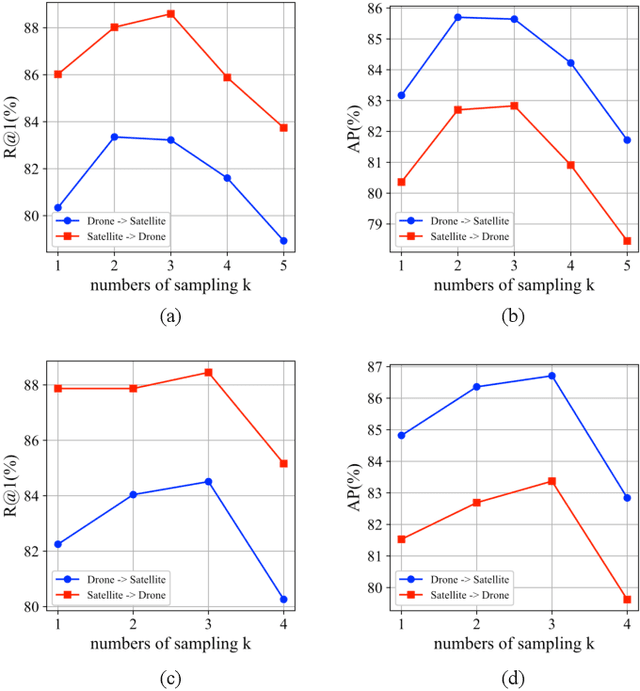
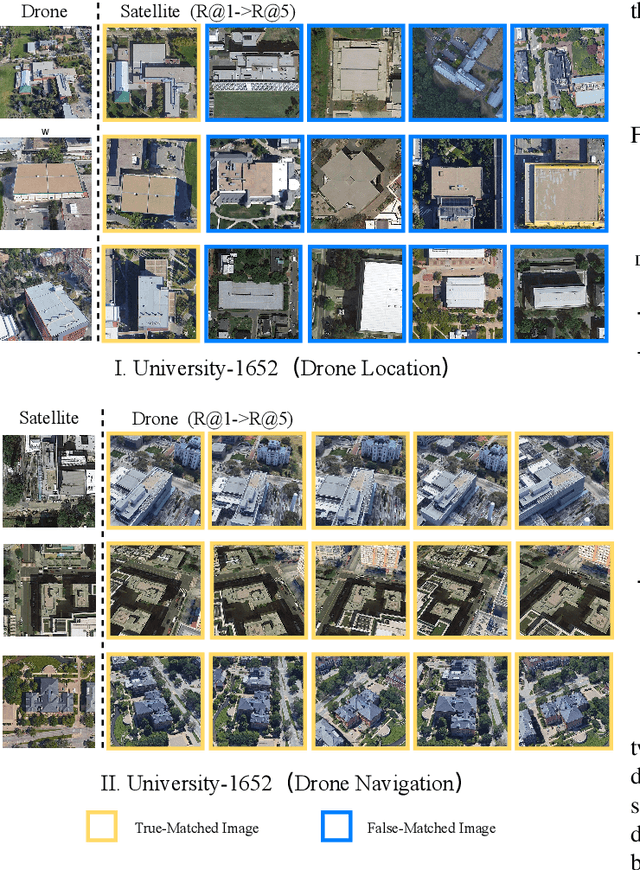
Cross-view geo-localization is a task of matching the same geographic image from different views, e.g., unmanned aerial vehicle (UAV) and satellite. The most difficult challenges are the position shift and the uncertainty of distance and scale. Existing methods are mainly aimed at digging for more comprehensive fine-grained information. However, it underestimates the importance of extracting robust feature representation and the impact of feature alignment. The CNN-based methods have achieved great success in cross-view geo-localization. However it still has some limitations, e.g., it can only extract part of the information in the neighborhood and some scale reduction operations will make some fine-grained information lost. In particular, we introduce a simple and efficient transformer-based structure called Feature Segmentation and Region Alignment (FSRA) to enhance the model's ability to understand contextual information as well as to understand the distribution of instances. Without using additional supervisory information, FSRA divides regions based on the heat distribution of the transformer's feature map, and then aligns multiple specific regions in different views one on one. Finally, FSRA integrates each region into a set of feature representations. The difference is that FSRA does not divide regions manually, but automatically based on the heat distribution of the feature map. So that specific instances can still be divided and aligned when there are significant shifts and scale changes in the image. In addition, a multiple sampling strategy is proposed to overcome the disparity in the number of satellite images and that of images from other sources. Experiments show that the proposed method has superior performance and achieves the state-of-the-art in both tasks of drone view target localization and drone navigation. Code will be released at https://github.com/Dmmm1997/FSRA