 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCtspine1k
Papers and Code
SpineContextResUNet: A Computationally Efficient Residual UNet for Spine CT Segmentation
May 20, 2026Automated segmentation of the vertebral column in Computed Tomography (CT) scans is a prerequisite for pathological assessment and surgical planning. However, state-of-the-art methods, particularly those based on Transformers or large-scale ensembles, demand substantial GPU resources, creating a barrier for clinical adoption in resource-constrained environments or on edge devices. To address this, we introduce SpineContextResUNet, a computationally efficient 3D Residual U-Net designed for rapid spinal localization. Our architecture integrates a lightweight Context Block that employs parallel multi-dilated convolutions to capture long-range anatomical dependencies without the high latency of Recurrent Neural Networks (RNNs) or the memory overhead of Self-Attention mechanisms. Extensive validation on two public benchmarks, VerSe2020 and CTSpine1K, demonstrates that our model achieves a Dice score of 88.17% and 88.13% respectively. To evaluate performance under strict hardware constraints, we compared our model against a bottlenecked SwinUNETR scaled to match our ~1.7M hardware footprint. While the constrained Transformer suffers severe performance degradation due to a lack of spatial inductive biases in a limited-data regime, our CNN-based approach successfully maintains high accuracy. Crucially, heavy baselines like TotalSegmentator fail due to memory exhaustion on commodity hardware (Intel Core i5, 8GB RAM), our model performs robust inference, making it a viable solution for point-of-care diagnostics and deployment on edge platforms like the Nvidia Jetson Orin Nano.
Multi-view X-ray Image Synthesis with Multiple Domain Disentanglement from CT Scans
Apr 18, 2024



X-ray images play a vital role in the intraoperative processes due to their high resolution and fast imaging speed and greatly promote the subsequent segmentation, registration and reconstruction. However, over-dosed X-rays superimpose potential risks to human health to some extent. Data-driven algorithms from volume scans to X-ray images are restricted by the scarcity of paired X-ray and volume data. Existing methods are mainly realized by modelling the whole X-ray imaging procedure. In this study, we propose a learning-based approach termed CT2X-GAN to synthesize the X-ray images in an end-to-end manner using the content and style disentanglement from three different image domains. Our method decouples the anatomical structure information from CT scans and style information from unpaired real X-ray images/ digital reconstructed radiography (DRR) images via a series of decoupling encoders. Additionally, we introduce a novel consistency regularization term to improve the stylistic resemblance between synthesized X-ray images and real X-ray images. Meanwhile, we also impose a supervised process by computing the similarity of computed real DRR and synthesized DRR images. We further develop a pose attention module to fully strengthen the comprehensive information in the decoupled content code from CT scans, facilitating high-quality multi-view image synthesis in the lower 2D space. Extensive experiments were conducted on the publicly available CTSpine1K dataset and achieved 97.8350, 0.0842 and 3.0938 in terms of FID, KID and defined user-scored X-ray similarity, respectively. In comparison with 3D-aware methods ($\pi$-GAN, EG3D), CT2X-GAN is superior in improving the synthesis quality and realistic to the real X-ray images.
Med-Query: Steerable Parsing of 9-DoF Medical Anatomies with Query Embedding
Dec 05, 2022



Automatic parsing of human anatomies at instance-level from 3D computed tomography (CT) scans is a prerequisite step for many clinical applications. The presence of pathologies, broken structures or limited field-of-view (FOV) all can make anatomy parsing algorithms vulnerable. In this work, we explore how to exploit and conduct the prosperous detection-then-segmentation paradigm in 3D medical data, and propose a steerable, robust, and efficient computing framework for detection, identification, and segmentation of anatomies in CT scans. Considering complicated shapes, sizes and orientations of anatomies, without lose of generality, we present the nine degrees-of-freedom (9-DoF) pose estimation solution in full 3D space using a novel single-stage, non-hierarchical forward representation. Our whole framework is executed in a steerable manner where any anatomy of interest can be directly retrieved to further boost the inference efficiency. We have validated the proposed method on three medical imaging parsing tasks of ribs, spine, and abdominal organs. For rib parsing, CT scans have been annotated at the rib instance-level for quantitative evaluation, similarly for spine vertebrae and abdominal organs. Extensive experiments on 9-DoF box detection and rib instance segmentation demonstrate the effectiveness of our framework (with the identification rate of 97.0% and the segmentation Dice score of 90.9%) in high efficiency, compared favorably against several strong baselines (e.g., CenterNet, FCOS, and nnU-Net). For spine identification and segmentation, our method achieves a new state-of-the-art result on the public CTSpine1K dataset. Last, we report highly competitive results in multi-organ segmentation at FLARE22 competition. Our annotations, code and models will be made publicly available at: https://github.com/alibaba-damo-academy/Med_Query.
Universal Segmentation of 33 Anatomies
Mar 04, 2022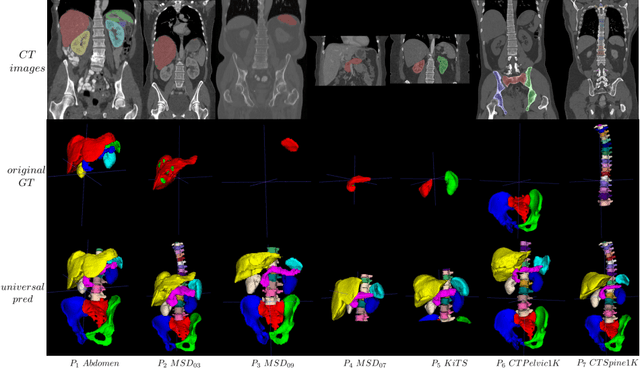
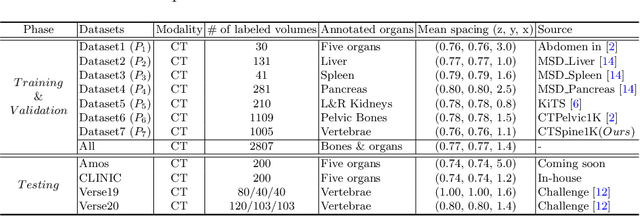
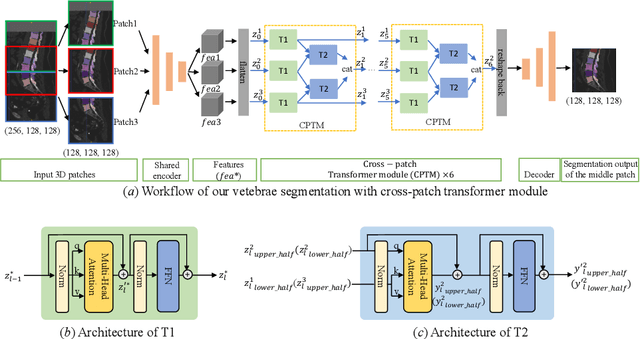
In the paper, we present an approach for learning a single model that universally segments 33 anatomical structures, including vertebrae, pelvic bones, and abdominal organs. Our model building has to address the following challenges. Firstly, while it is ideal to learn such a model from a large-scale, fully-annotated dataset, it is practically hard to curate such a dataset. Thus, we resort to learn from a union of multiple datasets, with each dataset containing the images that are partially labeled. Secondly, along the line of partial labelling, we contribute an open-source, large-scale vertebra segmentation dataset for the benefit of spine analysis community, CTSpine1K, boasting over 1,000 3D volumes and over 11K annotated vertebrae. Thirdly, in a 3D medical image segmentation task, due to the limitation of GPU memory, we always train a model using cropped patches as inputs instead a whole 3D volume, which limits the amount of contextual information to be learned. To this, we propose a cross-patch transformer module to fuse more information in adjacent patches, which enlarges the aggregated receptive field for improved segmentation performance. This is especially important for segmenting, say, the elongated spine. Based on 7 partially labeled datasets that collectively contain about 2,800 3D volumes, we successfully learn such a universal model. Finally, we evaluate the universal model on multiple open-source datasets, proving that our model has a good generalization performance and can potentially serve as a solid foundation for downstream tasks.
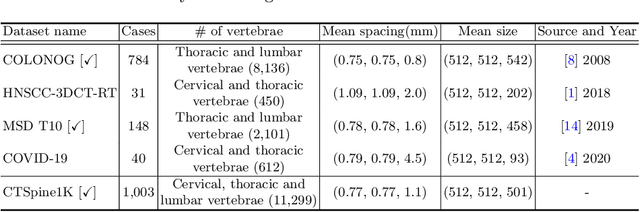
CTSpine1K: A Large-Scale Dataset for Spinal Vertebrae Segmentation in Computed Tomography
Jun 10, 2021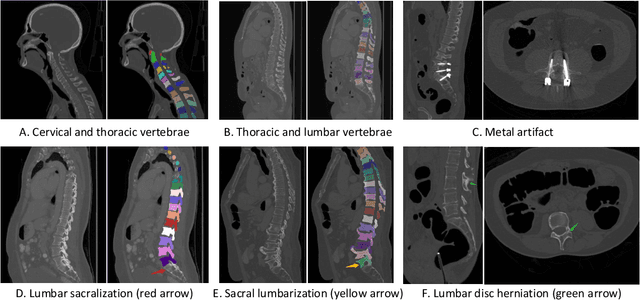

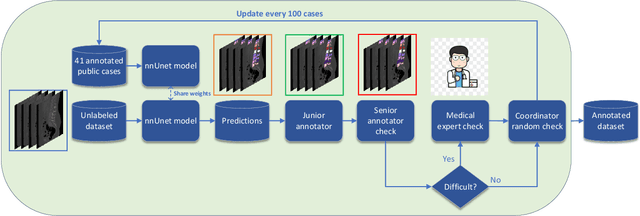
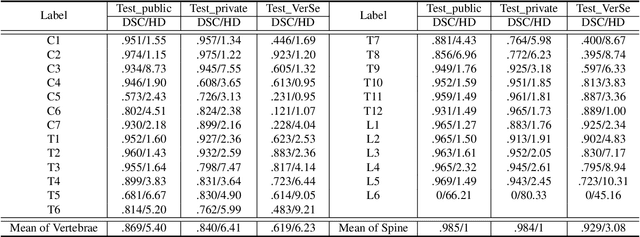
Spine-related diseases have high morbidity and cause a huge burden of social cost. Spine imaging is an essential tool for noninvasively visualizing and assessing spinal pathology. Segmenting vertebrae in computed tomography (CT) images is the basis of quantitative medical image analysis for clinical diagnosis and surgery planning of spine diseases. Current publicly available annotated datasets on spinal vertebrae are small in size. Due to the lack of a large-scale annotated spine image dataset, the mainstream deep learning-based segmentation methods, which are data-driven, are heavily restricted. In this paper, we introduce a large-scale spine CT dataset, called CTSpine1K, curated from multiple sources for vertebra segmentation, which contains 1,005 CT volumes with over 11,100 labeled vertebrae belonging to different spinal conditions. Based on this dataset, we conduct several spinal vertebrae segmentation experiments to set the first benchmark. We believe that this large-scale dataset will facilitate further research in many spine-related image analysis tasks, including but not limited to vertebrae segmentation, labeling, 3D spine reconstruction from biplanar radiographs, image super-resolution, and enhancement.